 Begins at the start of the line
Begins at the start of the lineThe PWB searching capabilities that you have used so far are useful when you know the exact text you are looking for. Sometimes, however, you have only part of the information that you want to match (for example, the beginning or end of the string), or you want to find a wider range of information. In such cases, you can use regular expressions.
Regular expressions are a notation for specifying patterns of text, as opposed to exact strings of characters. The notation uses literal characters and metacharacters. Every character that does not have special meaning in the regular-expression syntax is a literal character and matches an occurrence of that character. For example, letters and numbers are literal characters. A metacharacter is an operator or delimiter in the regular-expression syntax. For example, the backslash (\) and the asterisk (*) are metacharacters.
PWB supports two syntaxes for regular expressions: UNIX and non-UNIX. Each syntax has its own set of metacharacters. The UNIX metacharacters are .\[]*+^$. The non-UNIX metacharacters are ?\[]*+^$@#(){}. Because it uses fewer metacharacters, the UNIX form is a little more verbose. However, it is more familiar to programmers who have experience with UNIX tools such as awk and grep. This book uses the UNIX syntax, but any expression that can be written with this syntax can also be written with the non-UNIX syntax.
The regular-expression syntax used by PWB depends on the setting of the Unixre switch (UNIX is the default). You can change the Unixre switch by using the Editor Settings dialog box.
Note :
PWB switches that take regular expressions always use UNIX syntax. They are independent from the Unixre switch.
In the multifile searching example, you learned how to locate every occurrence of int in the COUNT project. In a large project, finding every int would yield too many matches. To narrow the search, you can use a regular expression.
For this example, you want to match declarations of functions returning int. You can specify this with a regular expression. This expression matches text that:
Begins at the start of the line
Followed by the keyword int
Followed by white space
Followed by an identifier
Followed by any text within parentheses
The syntax for this regular expression is shown in Figure 5.1.
It illustrates the following important features of regular expressions:
1.Regular expressions can contain literal text. In this example, int is literal text and is matched exactly.
2.Regular expressions can contain predefined regular expressions. Here, \:b is shorthand for a pattern that matches one or more spaces or tabs (that is, white space). For a complete list of predefined regular expressions, see Appendix A.
3.You can use classes of characters in regular expressions. A class matches any one character in the class. For example, the class [a-zA-Z0-9_] is the class of characters that contains all lowercase and uppercase letters and all digits plus the underscore. The dash (–) defines a range of characters in a class.
4.The plus sign (+) after the class instructs PWB to look for one or more occurrences of any of the characters in the class. This is the key to regular expressions. You don't have to know exactly what appears between int and the left parenthesis; all you have to do is describe what can be there.
The pattern ^int\:b[a-zA-Z0-9_]+(.*) matches strings such as
int CountWords( void )
int 2BadCIdentifiers()
but not the strings
int ( char *t )
integer(val)
Figure 5.2 shows a more detailed way to write an expression that matches the declaration of a function returning an int.
This expression is close to the C-language definition for the syntax of the declaration. It is more precise than most searches require, but it is useful as an illustration of how to write a complex regular expression.
You can interpret this expression as follows:
1.Start at beginning of line, which is specified by a caret (^) at the beginning of the regular expression.
2.Skip leading optional spaces. To specify optional items, this expression matches zero or more occurrences by using the asterisk (*) operator. The expression “ * ” means “match zero or more spaces.”
3.Look for the int keyword as literal text.
4.Skip white space. There must be at least one space or tab.
5.Look for exactly one alphabetic character or underscore.
6.Look for any characters that are alphabetic, numeric, an underscore (_), or a dollar sign ($). This and the previous part of the expression guarantee that the identifier conforms to the Microsoft C definition of an identifier.
7.Skip optional spaces.
8.Look for a left parenthesis.
9.Skip zero or more of any character.
10.Look for a right parenthesis.
This expression is exact to the point that it takes longer to write than the time it saves. The key to using regular expressions effectively is determining the minimal characteristics that make the text qualify as a match. For example, it's probably not necessary that the text between the space and the left parenthesis be a valid C identifier to qualify as a match. Any sequence of alphanumeric characters or underscores is usually sufficient.
·To find all function declarations that return an int:
1.From the Search menu, choose Find.
2.In the Find Text box, type ^int\:b\:i(.
3.Select the Regular Expression check box.
4.Choose the Files button.
5.Add the pattern CO*.C and the file COUNT.H to the file list.
6.Choose OK to start the search.
When the search is complete, choose View Results. You can see in the Search Results window that PWB matched only the function declarations.
You can use regular expressions when changing text to achieve some extremely powerful results. A regular expression replacement can be a simple one-to-one replacement, or it can use “tagged” expressions. A tagged expression marks part of the matched text so that you can copy it into the replacement text.
For example, you can manipulate lists of files easily using regular expressions. This exercise shows how to get a clean list of files that is stripped of the size and time-stamp information.
·To get a clean list of C files in the current directory:
1.From the File menu, choose New.
This gives you a new file for the directory listing.
2.Execute the function sequence Arg Arg !dir *.c Paste.
The default key sequence for this command is to press ALT+A twice, type
!dir *.c, then press SHIFT+INS.
Arg Arg introduces a text argument to the Paste function with an Arg count
of two. The exclamation point (!) designates the text argument to be run as
an operating-system command. Without the exclamation point, the text is the name of a file to be merged. If only one Arg is used, PWB inserts the text argument.
PWB runs the DIR command and captures the output. When the DIR command is complete, PWB prompts you to press a key. When you press a key, PWB then inserts the results of the command at the cursor. For more information about this and other forms of the Paste function, see “Paste” in Chapter 7, “Programmer's WorkBench Reference.”
3.From the Search menu, choose Replace.
4.In the Find Text box, type \:b\:z \:z-.*$
This pattern means:
White space followed by
A number followed by
Exactly one space followed by
A number followed by
A dash (–) followed by
Any sequence of characters, then
End of the line
This string must be tied to the end of the line to prevent the search from finding anything too close to the beginning of the line.
5.Make sure there are no characters in the Replace Text text box.
6.Choose Replace All.
PWB prompts you to verify that you want to replace text with an empty string.
7.Choose OK to confirm that you want to perform the empty replacement.
All the file-size, date, and time-stamp information is removed. Because you did not reuse any of the original text in the replacement, this is a simple regular expression replacement.
Choose Close from the File menu to discard the text you created in the previous exercise.
A more complicated task is backing up the C files to a directory called LAST, which is assumed to be a subdirectory of the current directory. A batch file makes this easier. You can create such a batch file using regular expressions.
·To create a batch file that copies the C files to a subdirectory:
1.Create a list of C files in the current directory as described in the previous example, but do not remove the file sizes, dates, and times.
2.Delete the heading printed by the DIR command.
3.From the Search menu, choose Replace.
4.In the Find Text text box, type:
^\([^ ]+\)[ ]+\([^ ]+\).*
5.This expression finds a string that starts at the beginning of the line (^). Placing parts of the expression inside the delimiters \( and \) is called “tagging.”
The first tagged expression (\([^ ]+\)) matches one or more characters that are not spaces. A leading caret in a class means “not.”
The pattern then matches one or more spaces ([ ]+), followed by the second tagged expression which matches one or more characters that are not spaces.
The remainder of the line is matched by the wildcard (.), which matches any character, and the repeat operator (*). Matching the rest of the line is important because that is how this pattern removes everything after the filename. It discards these portions of the matched text.
6.In the Replace Text text box, type
COPY \1.\2 .\\LAST
7.Select Replace All and click OK to begin the find-and-replace operation.
PWB transforms each directory entry into a command to copy the file to the LAST subdirectory.
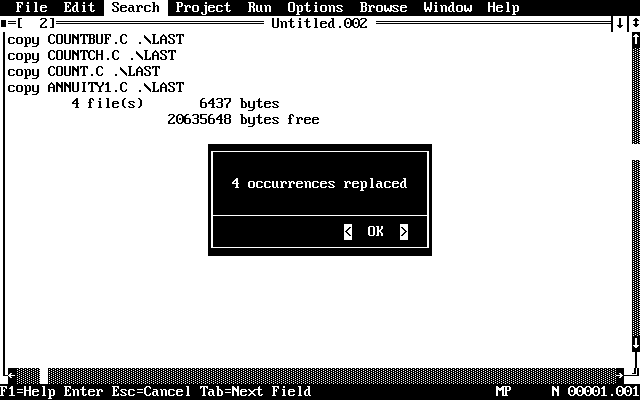
The word COPY is inserted literally. The text matched in the first tagged expression (the base name) replaces the expression \1. The period is inserted literally. The text matched by the second tagged expression (the filename extension) replaces the expression \2. The space is inserted literally. The text .\\LAST is inserted as .\LAST. Be sure to use two backslashes to indicate a literal backslash; otherwise, PWB expects a reference to a tagged expression such as \1 and displays an error message.
You'll notice that the last two lines of the file are not useful in your batch file. They are the remnants of the summary statistics produced by the DIR command. Delete these two lines and you have a finished batch file.