Windows includes provisions for specifying a national language. Language, in conjunction with the specification of a country, allows Windows to describe more precisely the characteristics of a given geographical location (for example, Swiss-German as opposed to Swiss-French). The following Windows functions behave differently depending on the language that is selected:
| AnsiLower AnsiLowerBuff AnsiNext AnsiPrev AnsiUpper AnsiUpperBuff | IsCharAlpha IsCharAlphaNumeric IsCharLower IsCharUpper lstrcmp lstrcmpi |
The lstrcmp and lstrcmpi functions allow applications to compare and sort strings based on the language specified by the user. These functions take into account different alphabetic orderings, diacritical marks, and special cases that require character compression or expansion. Note that the lstrcmp and lstrcmpi functions do not act the same way as the C run-time functions strcmp and strcmpi.
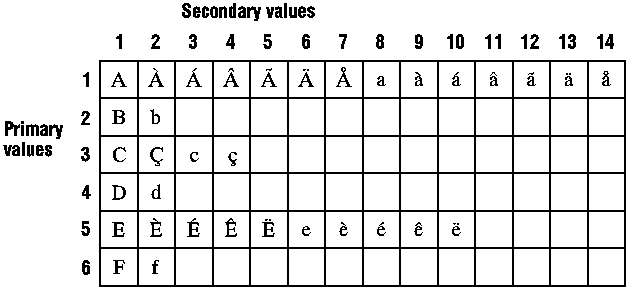
The comparison done by lstrcmp and lstrcmpi is based on a primary value and a secondary value (see the following illustration). Each character has a primary and a secondary value. For example, in the following matrix, the letter d has a primary value of 4 and a secondary value of 2.
When performing the comparison of two strings, the primary value takes precedence over the secondary value. That is, the secondary value is ignored unless a comparison based on primary value shows the strings as equivalent.
The following examples show the effect of primary and secondary values on string comparisons:
| Comparison | Result |
| A = A | Primary values equal |
| A < a | Primary values equal, secondary values unequal (A < a) |
| Ab < ab | Primary values equal, secondary values unequal (A < a) |
| ab < Ac | Primary values unequal (b < c) |
The lstrcmpi function ignores the effect of case in determining secondary value. That is, when lstrcmpi is called to compare AB and ab, the two strings are equivalent. However, lstrcmpi does not ignore diacritical marks, so Ab precedes b regardless of whether the comparison is performed by the lstrcmp or lstrcmpi function.
When strings of different lengths are compared, length takes precedence over secondary values. That is, the shorter string always precedes the longer string as long as the primary values in the shorter string equal the primary values for equivalent characters in the longer string. For example, ab precedes ABC, but ABC precedes AD.
Depending on the language module installed, some characters are treated differently. For example, if the German language module is installed, the β character expands to ss. If the Spanish language module is installed, the characters ch are treated as a single character that sorts between c and d.
Use of the case conversion functions, AnsiLower, AnsiLowerBuff, AnsiUpper, and AnsiUpperBuff, varies depending on the language module installed. The IsCharAlpha, IsCharAlphaNumeric, IsCharLower and IsCharUpper functions are also language-dependent. Different languages treat case conversions differently.
Note:
Do not use the C-language case-conversion functions; they do not handle characters with values greater than 128 properly.
If you are writing international Windows applications, you will handle different character sets. It is especially important in this case to understand the difference between the Windows and OEM character sets.
The Windows character set is essentially equivalent to the ANSI character set.
The OEM character set is defined by the Windows operating system as the character set used by MS-DOS. The term OEM does not refer to a specific character set; instead, it refers to any of the different character sets (code pages) that can be installed and used by MS-DOS.
Because Windows runs on top of MS-DOS, there must be a layer between Windows and MS-DOS that performs translations between Windows and OEM characters. When Windows is first installed, the Windows Setup program looks at the character set that has been installed by MS-DOS and then installs the correct translation tables and Windows OEM fonts.
Windows applications should use the Windows AnsiToOem and OemToAnsi functions when transferring information to and from MS-DOS. Also, applications should use the correct character set when creating filenames. For more information about handling filenames, see the following section.
There is no one-to-one mapping between the Windows and OEM character sets. Applying the AnsiToOem function and then the OemToAnsi function to a given string does not always result in the original string.
Because the Windows and OEM character sets are 8-bit character sets, always use unsigned char values instead of signed char values. Bugs that result from using signed char values are very hard to track.
Applications do file handling differently depending on factors such as speed, size, and programming style. This section describes the most common methods for handling filenames.
The easiest way of handling filenames in Windows is to use the Windows character set for all filenames and to use the _lcreat, _lopen, and OpenFile functions to deal with differences between the MS-DOS and the OEM character sets.
Another way to handle filenames is to use the OpenFile function to obtain a full path, by using the szPathName member from the OFSTRUCT structure. The szPathName member contains characters from the OEM character set and must first be converted to the Windows character set before it is used as a parameter for the OpenFile function, for other Windows functions, or in a dialog box.
The following example shows this conversion:
if (OpenFile("myfile.txt", &of, OF_EXISTS) == -1) {
OemToAnsi(of.szPathName, szAnsiPath);
OpenFile(szAnsiPath, &of, OF_CREATE);
}The third, and maybe most complicated, way of handling files is to call MS-DOS directly (by using the DOS3Call function or an Interrupt 21h instruction). You must ensure that your application always passes OEM characters to MS-DOS.
Differences between the Windows and OEM character sets complicate the handling of filenames. Problems can occur when applications try to create filenames using the Windows character set that have no equivalent characters in the OEM set. For example, the character does not exist in code page 437 (437 is the standard U.S. extended ASCII character set). If the application tries to save the file named .TXT, Windows converts .TXT into E.TXT (by using the AnsiToOem function) and then passes it to MS-DOS.
You can prevent confusion about filenames by using the ES_OEMCONVERT and CBS_OEMCONVERT control styles. These styles (the first for edit controls and the second for combo boxes) read the user's input and convert the typed character to a valid character (one that exists in the OEM character set). This way, the user sees on the screen the actual filename that will be stored at the MS-DOS level.
The most important keyboard issue for international applications is the use of the VK_OEM keys for user input because the locations of these keys change depending on the keyboard layout chosen by the user.
The VkKeyScan function is used to translate characters from the Windows character set into a virtual-key code plus a shift state. This function can be also used when one application has to send text to another application by simulating keyboard input.
Some other useful keyboard functions are the following:
| Function | Purpose |
| ToAscii | Converts a virtual-key code plus a shift state to a character in the Windows character set. This function is the opposite of the VkKeyScan function. |
| GetKeyNameText | Retrieves a string that contains the name of a key (the SHIFT key or the ENTER key, for example). The string is in the language associated with the keyboard. For example, for a French keyboard layout the names of the keys are in French. |
| GetKBCodePage | Returns the code page (OEM character set) that was running at the MS-DOS level at the time Windows was installed. Note that there is no real relationship between the keyboard and the code page installed. |
To type characters that are not on your keyboard, use the ALT key and the numeric keypad. For characters in the Windows character set, hold down ALT and then, using the numeric keypad, type 0 and the three-digit code of the character you want. For an OEM character, type the three-digit code for the character.
The WIN.INI and SYSTEM.INI files use the Windows character set. Usually, however, applications do not access SYSTEM.INI. For WIN.INI as well as for private initialization files, applications should use the following functions:
| GetPrivateProfileInt GetPrivateProfileString GetProfileInt | GetProfileString WritePrivateProfileString WriteProfileString |
The Windows character set should always be used with these functions.
The section names and setting names in WIN.INI and in private initialization files should be independent of the language of the application. Usually, all of these names remain in English. For example, in WIN.INI the section name [Desktop] and the setting name Wallpaper should always remain in English so that applications in different languages can access the same information.