 The first application is called SIMPLE and uses only one DLL called HILEVEL. The HILEVEL DLL uses the other DLL called LOLEVEL to do some of its work.
The first application is called SIMPLE and uses only one DLL called HILEVEL. The HILEVEL DLL uses the other DLL called LOLEVEL to do some of its work.Nigel Thompson
Microsoft Developer Network Technology Group
Created: March 20, 1992
ABSTRACT
The process of developing applications for the MicrosoftÒ WindowsÔ graphical environment sometimes requires a machine that is set up with more than one version of Windows, more than one set of tools (compilers, debuggers, and so on), and both released versions and development versions of several applications. This article describes techniques for establishing a correct development environment for a particular requirement and suggests a directory structure in which a source control system maintains one or more projects.
These suggestions are based on the system we employed at Microsoft to create the multimedia extensions to Windows.
We will begin by taking a look at a directory scheme for developing large projects under some sort of source control system, which has a mechanism for releasing regular builds of the project components. Then we’ll look at how you can create an environment that allows these components to be built with different tool sets and run under different versions of the final system software. Finally, we’ll look at how you can use NMAKE to build both the individual components and the entire project.
To illustrate, we’ll look at a project called NEWAPPS, which consists of two applications and two dynamic link libraries (DLLs):
The first application is called SIMPLE and uses only one DLL called HILEVEL. The HILEVEL DLL uses the other DLL called LOLEVEL to do some of its work.
The second application is called COMPLEX and uses both the HILEVEL and the LOLEVEL DLLs (see Figure 1).
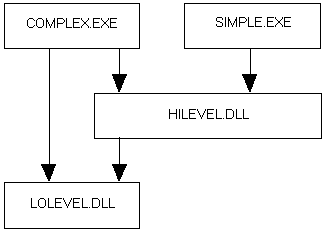
Figure 1.
Each component is created with the medium compiler model, the format that most applications and DLLs use in the MicrosoftÒ WindowsÔ graphical environment. We will have available two compilers, either of which can be used to build the project. We’ll also configure our system to run with two versions of Windows, including software development kit (SDK) components.
When you create large projects under a source control system, each team member must be enlisted1 in the entire project, and the project must be built locally on a regular basis to stay in sync with other team members. On large projects, such as operating systems, the size of the source material can preclude each team member having all of it locally. However, if each team member has individual source components of one part of the project, the remainder of the project must be available in compiled and executable form.
For the purposes of our example, I assume a networked system that has one or more servers holding the project source material and several workstations at which the project components are edited, compiled, and tested.
The project structure suggested here involves creating a main project that has the latest built version of the product checked into it. Each system component is created as a separate project and can be enlisted in separately by any team member.
In an ideal setup, one workstation machine is the build machine and is enlisted in the main project and in every component project. At build time, the source control system is locked so that no changes can take place, and the build machine is synced to the entire set of projects. You can then unlock the source system to allow work to continue while the build machine recompiles the entire set of projects. In some cases, the source system must remain locked until a successful build is completed. If completion takes a long time, you must determine the appropriate course of action.
Once a build is complete and tests satisfactorily, the build machine checks out the entire contents of the main project and checks in all the updated binaries for the system. Each team member can then sync to these changes to get the new binaries.
For this to work, each development machine is given a directory structure and a set of environment paths that allow both the current build binaries and any local build to be present without conflict. A directory tree for the main project of our example can be set up as follows:
\NEWAPPS
\RBIN
\RINC
\RLIB
\BIN
\LIB
\INC
The root directory has the name of the overall project so that it can easily be found on any machine. Under the main directory are six subdirectories:
RBIN contains the current build executables.
RINC contains the current build include files.
RLIB contains the current build link libraries.
BIN, LIB, and INC are empty. Components built on the local machine are put into these empty subdirectories.
Be careful of using long names; the MS-DOSÒ path limit is about 127 characters. You could shorten the root name used here (NEWAPPS) to NA or something similar to allow for including more directories in the path as the environment becomes more complex.
You need to set three environment variables to define how a system executes and how assemblers, compilers, and linkers find include and library files. The example here follows the conventions that Microsoft products use. You may need to modify them according to your own tool’s requirements. MS DOS uses the PATH environment variable to determine the search order for executables. Microsoft tools use the LIB variable to search for libraries and the INCLUDE variable to search for header and include files.
To make this example realistic, we assume that the MS-DOS system files are in a directory called DOS, most tools are in a directory called BIN, headers and include files are in INCLUDE, and libraries are in a LIB directory. Here is how the environment setup might look in an AUTOEXEC.BAT file for our development system:
PATH=c:\NEWAPPS\BIN;c:\NEWAPPS\RBIN;c:\BIN;c:\DOS
SET LIB=c:\NEWAPPS\LIB;c:\NEWAPPS\RLIB;c:\LIB
SET INCLUDE=c:\NEWAPPS\INC;c:\NEWAPPS\RINC;c:\INCLUDE
In each case, the (initially) empty BIN, LIB, and INC directories are in front of those containing the latest build, and normal tools follow these. For clarity, I excluded the Windows and Windows SDK directories that would also normally be a part of these definitions. See the “Working with More Than One Run-Time System” section for an example.
As each part of a project is built, its build products are copied into the main project BIN, INC, and/or LIB directories.
When a program executes, the search order starts with the local project BIN directory. If you just rebuilt a tool that is a part of your project, the search ends when it finds the tool just created. If you don’t have a local tool, the search continues to the project release binaries directory \NEWAPPS\RBIN. If the tool exists here, it executes. If neither of these directories has the tool, the search continues with the local BIN directory and finally the DOS directory. In this way, common tools (such as a compiler) that live in the BIN directory are found and so are any components of the project that have been built recently. The most important feature, though, is that the local binaries built on your development machine and copied to the \NEWAPPS\BIN directory are always found before the latest releases. In this way, you can enlist in individual system components, build them, and be sure that the one you built is executed at test time.
The same mechanism works for header and library files. The normal files that come with your compiler commonly live in directories that the INCLUDE and LIB environment variables define. The files that the build process creates for your own libraries (HILEVEL and LOLEVEL in the example) live in the \NEWAPP\RINC and \NEWAPP\RLIB directories. If you enlist in one of these projects and build it, the libraries and header files are copied to your local \NEWAPP\INC and \NEWAPP\LIB directories. In this way, you can enlist in a library project, add a function, build it so that the include file and library are copied locally, and then rebuild an application to pick up these local changes.
For each component of the total system, a new project is added to the server containing the source files. When a developer wants to enlist in that part of the project, a new subdirectory of the main project is created on the local machine (usually with the same name as the component), and the component is enlisted in the new directory. To continue with our example, assume we want to enlist in the COMPLEX application. Here is the new directory structure:
\NEWAPPS
\RBIN (Build binaries)
\RINC (Build headers)
\RLIB (Build libraries)
\BIN (Locally built binaries)
\LIB (Locally built libraries)
\INC (Locally built headers)
\COMPLEX (Source for the COMPLEX application)
Now we can check out source elements for the COMPLEX application and modify, build, and test them. When the changes are proven, they can be checked back in.
Suppose now that we discover that the low-level library that COMPLEX uses needs a new function. We can enlist in the LOLEVEL project, as we enlisted in COMPLEX, resulting in the following directory structure:
\NEWAPPS
\RBIN (Build binaries)
\RINC (Build headers)
\RLIB (Build libraries)
\BIN (Locally built binaries)
\LIB (Locally built libraries)
\INC (Locally built headers)
\COMPLEX (Source for the COMPLEX application)
\LOLEVEL (Source for the LOLEVEL library)
Now we can check out the components of LOLEVEL, add the application programming interface (API) to the source files and to the header file associated with the library, and rebuild it. We can then modify COMPLEX to use the new API and thus test it. As a part of building our local copy of LOLEVEL, its header file is copied to \NEWAPPS\INC, and its import library file is copied to \NEWAPPS\LIB, so that when we subsequently rebuild COMPLEX, it finds the new API.
Once again, we can test the changes. When we are happy with them, we can check each file back into the source-controlled server. After the next build, the changes to LOLEVEL and COMPLEX are reflected in the new files in RBIN, RINC, and RLIB so that other team members can sync to the main project and use them.
The two examples here show how to build the LOLEVEL library and the COMPLEX application. In both cases, we include a mechanism for creating a debug or retail version of the component. Typically debug versions include diagnostics that use macros, and retail versions are built without these. The technique to determine which will be built is to detect the presence of an environment variable called DEBUG. If found at build time, the DEBUG define is passed to each tool as it is called.
When C6.0 was released, a build tool called NMAKE was included to replace the older MAKE tool. NMAKE provides improved target definition capabilities and enhanced macro support. However, the tool uses significant MS-DOS memory when it executes. Consequently, creating make files that recursively call NMAKE (for example, to build subprojects with their own make files) reduces the amount of memory available to run the compiler, sometimes to the point where it can no longer compile a source module. A second tool, NMK, was supplied to rectify this problem. NMK avoids running multiple copies of NMAKE. Unfortunately, it does not support multiple arguments on the command line, for example:
NMK clean goal
To fix this, you can create a simple batch file to execute the arguments in turn, for example:
@echo off
:loop
nmk %1
if errorlevel 1 goto finish
if "%2." == "." goto finish
shift
goto loop
:finish
We assume that the project directory contains these files:
COMPLEX.C (Source for most of the application)
INIT.C (Initialization code)
COMPLEX.RC (Resource file)
COMPLEX.DEF (Module definition file)
COMPLEX.H (Header file)
COMPLEX.ICO (Icon)
MAKEFILE (The make file used by NMAKE)
The following NMAKE file can be used to create the COMPLEX application:
#
# Constructs a medium model application for Windows.
#
NAME = COMPLEX
!ifdef DEBUG
DDEF = -DDEBUG
CLOPT = -Zid -Od
MOPT = -Zi
LOPT = /CO/LI/MAP/NOPACK
!else
DDEF =
CLOPT = -Ows
MOPT =
LOPT =
!endif
# General defines:
DEF =
# Tools:
ASM = masm -Mx $(MOPT) $(DDEF) $(DEF)
CC = cl -nologo -c -AM -G2sw -Zp -W3 $(CLOPT) $(DDEF) $(DEF)
LINK = link /NOD/NOE $(LOPT)
RC = rc $(DDEF) $(DEF)
HC = hc
# Object list:
OBJ1 = $(NAME).obj init.obj
OBJ2 =
OBJ3 =
OBJ = $(OBJ1) $(OBJ2) $(OBJ3)
# Library list:
LIBS = libw mlibcew
# Inference rules:
.c.obj:
$(CC) $*.c
.asm.obj:
$(ASM) $*;
# Main (default) target:
goal: $(NAME).exe $(NAME).hlp copy
$(NAME).exe: $(OBJ) $(NAME).def $(NAME).res
$(LINK) @<<
$(OBJ1) +
$(OBJ2) +
$(OBJ3)
$(NAME).exe,
$(NAME).map,
$(LIBS),
$(NAME).def
<<
$(RC) -t $(NAME).res
!ifdef DEBUG
cvpack -p $(NAME).exe
mapsym $(NAME).map
!endif
$(NAME).res: $(NAME).rc $(NAME).h $(NAME).ico
$(RC) -r $(NAME).rc
$(NAME).hlp: $(NAME).hpj $(NAME).rtf
$(HC) $(NAME).hpj
copy:
copy $(NAME).exe ..\bin
copy $(NAME).hlp ..\bin
!ifdef DEBUG
copy $(NAME).sym ..\bin
!endif
clean:
del $(NAME).exe
del $(NAME).res
del $(NAME).hlp
del $(NAME).ph
del *.obj
del *.map
del *.sym
# Dependencies:
$(NAME).obj: $(NAME).c $(NAME).h
init.obj: init.c $(NAME).h
NMAKE defaults to building the first target in the file if none is on the command line. Simply calling NMK causes it to build the goal target, which in turn builds the application and copies it to where we need it. You can also create a clean directory by calling:
NMK clean
To try to keep the make file as generic as possible, we define a set of macros starting with the name of the thing we are building. We define compiler and assembler switches to be used to create the debug version (which generates both CodeViewÒ and WDEB386 symbolic information with no code optimization), and we define the switches required to create a final retail2 version, this time optimizing for code size.
Next we define rules that associate a tool with a source code extension for assembly language and C files. Thus, we can simply list the object files, and NMAKE finds a corresponding C or assembly language file of the same name and builds it with the tools we defined.
In our definition of the link command, we use the << operator to redirect the input to NMAKE from the make file itself. Doing so overcomes MS-DOS command-line length limits and is nicer than redirecting the input from another file (such as APPNAME.LNK). We can reuse the macros and keep all the make file definition in one place.
The final section of the file lists various dependencies. The objective of this section is to help NMAKE work out which parts to rebuild when something changes. You can create tools that search through source files looking for .INCLUDE or #include statements and create the dependency list automatically. Usually, doing this by hand is simpler for a small project. This important aid in avoiding unstable or nonrepeatable builds ensures that all dependent modules are always rebuilt whenever something that can affect the way they work changes.
To reuse this file for a different application, change only the Name macro at the start and the list of object files.
Here is an NMAKE file that you can use to create the LOLEVEL library DLL, its import library, and the public header file. We assume that the project directory contains these files:
LOLEVEL.C (Source for most of the library)
INIT.C (Initialization code)
LIBINIT.ASM (The library entry point)
LOLEVEL.RC (Resource file)
LOLEVEL.DEF (Module definition file)
LOLEVEL.H (Public header file)
MAKEFILE (The make file used by NMAKE)
The details of this file are similar to those of the application file above except that the compiler options are changed because DS != SS in a DLL. We generate the LOLEVEL.LIB import library and copy the import library to the main project LIB directory and the public header file (included by other applications) to the main project INC directory.
#
# Constructs a medium model Windows version 3.x DLL.
#
NAME = LOLEVEL
!ifdef DEBUG
DDEF = -DDEBUG
CLOPT = -Zid -Od
MOPT = -Zi
LOPT = /CO/LI/MAP/NOPACK
!else
DDEF =
CLOPT = -Ows
MOPT =
LOPT =
!endif
# General defines:
DEF =
# Tools:
ASM = masm -Mx $(MOPT) $(DDEF) $(DEF)
CC = cl -nologo -c -Alnw -G2sw -Zp -W3 $(CLOPT) $(DDEF) $(DEF)
LINK = link /NOD/NOE $(LOPT)
RC = rc $(DDEF) $(DEF)
# Object list:
OBJ1 = $(NAME).obj init.obj
OBJ2 =
OBJ = $(OBJ1) $(OBJ2)
# Library list:
LIBS = libw mdllcew
# Inference rules:
.c.obj:
$(CC) $*.c
.asm.obj:
$(ASM) $*;
# Main (default) target:
goal: $(NAME).dll copy
$(NAME).dll: libinit.obj $(OBJ) $(NAME).def $(NAME).res
$(LINK) @<<
libinit.obj +
$(OBJ1) +
$(OBJ2)
$(NAME).dll,
$(NAME).map,
$(LIBS),
$(NAME).def
<<
$(RC) $(NAME).res $(NAME).dll
!ifdef DEBUG
cvpack -p $(NAME).dll
mapsym $(NAME)
!endif
implib $(NAME).lib $(NAME).def
$(NAME).res: $(NAME).rc $(NAME).h
$(RC) -r $(NAME).rc
copy:
copy $(NAME).dll ..\bin
!ifdef DEBUG
copy $(NAME).sym ..\bin
!endif
copy $(NAME).lib ..\lib
copy $(NAME).h ..\inc
clean:
del $(NAME).dll
del $(NAME).res
del $(NAME).lib
del *.obj
del *.map
del *.sym
# Dependencies:
$(NAME)i.h: $(NAME).h
$(NAME).obj: $(NAME).c $(NAME)i.h
init.obj: init.c $(NAME)i.h
libinit.obj: libinit.asm
If you create Help files for your application using an application such as Microsoft Word for Windows, which has its own native file format but can also be used to output the RTF format that the Windows Help compiler needs, you might consider keeping both the RTF and the native files as a part of the project source. You need to check out both to make a change, but your editor doesn’t need to read the RTF source back in because it can always work with its own native file format. You simply have to remember to save both the native and RTF forms each time.
A useful addition to the main project root directory is a make file that builds the entire project in the correct order. Most often this is used only when the build machine is used to create a new release. It is useful in any case to define the order in which the projects should be built and thus avoid dependency problems.
We would build the example projects in this order:
LOLEVEL
HILEVEL
SIMPLE, COMPLEX
The LOLEVEL library is built first because both the HILEVEL library and the COMPLEX application use it. HILEVEL is built next because SIMPLE depends on it. Finally, the SIMPLE and COMPLEX applications are built in either order because neither depends on the other.
Sometimes you need more than one tool set on a development machine. For example, you might want to try out Borland’s development tools and compare them with Microsoft’s. We can easily adapt the environment and the make files we created earlier to cope with this.
When each toolkit is installed, we give it a separate directory and create a BIN, LIB, and INC subdirectory. For our example, we might install the files as follows:
\BL
\BIN (Compiler, linker, and so on)
\LIB (Libraries)
\INC (Header files)
\MS
\BIN (Compiler, linker, and so on)
\LIB (Libraries)
\INC (Header files)
Now we create batch files to switch between the two tool sets. We create a batch file to set environment variables for each tool set and another file to create the new final environment.
Here is the batch file to select the Borland tool set:
@echo off
rem SETBL.BAT
set COMPILER=BORLAND
set CBIN=c:\BL\BIN
set CLIB=c:\BL\LIB
set CINC=c:\BL\INC
call NEWPATH
echo Borland tools selected
Here is the batch file to select the Microsoft tool set:
@echo off
rem SETMS.BAT
set COMPILER=MICROSOFT
set CBIN=c:\MS\BIN
set CLIB=c:\MS\LIB
set CINC=c:\MS\INC
call NEWPATH
echo Microsoft tools selected
Here is the batch file to create the new paths:
@echo off
rem NEWPATH.BAT
PATH=c:\NEWAPPS\BIN;c:\NEWAPPS\RBIN;%CBIN%;c:\BIN;c:\DOS
set LIB=c:\NEWAPPS\LIB;c:\NEWAPPS\RLIB;%CLIB%
set INCLUDE=c:\NEWAPPS\INC;c:\NEWAPPS\RINC;%CINC%
The symbols enclosed between the percent signs, such as %CINC%, expand to be the contents of the current environment variable by that name when the batch file runs. To change to the Borland set, use SETBL.BAT; to change back to the Microsoft set, use SETMS.BAT. The make files must be modified to detect the compiler we are using and to execute an appropriate command line. Here is the compiler definition from the application make file above, modified to work with this new switchable environment:
!if "$(COMPILER)" == "MICROSOFT"
CC = cl -nologo -c -AM -G2sw -Zp -W3 $(CLOPT) $(DDEF) $(DEF)
!endif
!if "$(COMPILER)" == "BORLAND"
CC = Mr. Borland's compiler command line and options.
!endif
Because the Borland compiler has a different syntax for command-line arguments, you may have to make other conditional sections in the make file.
The idea of multiple tool environments extends easily to multiple run-time environments. All you need to do is define some environment variables for the executable path and any libraries or header files. You create batch files to configure the variables, as we did above with the tool sets, and to modify the NEWPATH.BAT file to include the new variables you define. For example, we might define an environment for developing under both Windows versions 3.0 and 3.1. Assume that Windows version 3.0 run time is installed in \WIN30 and that the Windows version 3.0 SDK is in \WIN30DEV. Windows version 3.1 run time is in \WIN31, and Windows version 3.1 SDK is in \WIN31DEV. The environment variables to select the Windows 3.0 version might be these:
set WINBIN=c:\WIN30;c:\WIN30DEV
set WININC=c:\WIN30DEV\INCLUDE
set WINLIB=c:\WIN30DEV\LIB
In practice, we might use shorter paths to keep the total path below the MS-DOS limit. The NEWPATH.BAT file now becomes:
@echo off
rem NEWPATH.BAT
PATH=c:\NEWAPPS\BIN;c:\NEWAPPS\RBIN;%WINBIN%;%CBIN%;c:\BIN;c:\DOS
set LIB=c:\NEWAPPS\LIB;c:\NEWAPPS\RLIB;%WINLIB%;%CLIB%
set INCLUDE=c:\NEWAPPS\INC;c:\NEWAPPS\RINC;%WININC%;%CINC%
In your enthusiasm to make everything a part of the environment, be careful not to exceed the MS-DOS path length and avoid creating environment variables that have trailing spaces. Trailing spaces can cause problems when you try to concatenate them with a batch file such as the NEWPATH.BAT example above.
Finally, all this requires a much bigger environment than MS-DOS provides by default. Here is a sample line from CONFIG.SYS that gives you a 2048-character environment:
shell = c:\dos\command.com c:\dos /p /e:2048
Enlist To become a part of the project; usually involves copying the source components of the project from a server to a local machine.
Defect To leave a project.
Sync To update the local elements of a project so that they are identical to the source server.
Check out To create a local copy of a source element in preparation for editing it. Usually this prevents other members of the project from checking out the same element.
Check in To update the source server with a local copy. This is the way new code is added and changes are made. Most source systems keep a history of such changes.
1Please see the glossary at the end of this article for an explanation of source control terms.
2The debug build usually contains debugging code; the retail build is the final clean, optimized version.