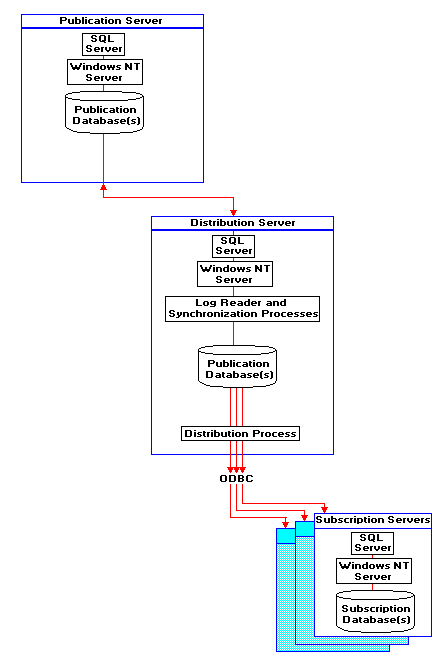
The log reader process, the synchronization process, the distribution database, and the distribution process are the main components of replication.
The log reader process moves transactions marked for replication from the publication server transaction log into the distribution database, where the transactions wait for distribution to subscription servers.
The synchronization process prepares initial synchronization files containing schema and data of published tables, stores the files in the SQL Server working directory on the distribution server, and records synchronization jobs in the distribution database. Synchronization affects new subscribers only.
The distribution database is a store-and-forward database that holds all transactions waiting to be distributed to subscription servers. The distribution database receives transactions sent to it from the publication server by the log reader process and holds them until the distribution process moves them to the subscription servers. The distribution database is used only by replication and does not contain any user tables.
The distribution process moves to subscription servers the transactions and initial synchronization jobs held in the distribution database tables. They are applied at the subscribers to the destination tables in the destination databases.
All three processes (log reader, synchronization, and distribution) exist on the server that performs distribution, are subsystems of SQL Executive, and are not started or directly administered by users.
The following illustration provides a functional overview of the replication components.
Note To best depict functionality, the illustration shows the publication and distribution servers as separate computers. However, any SQL Server 6.0 server can perform both roles. The publication and distribution servers are typically the same physical machine. However, when appropriate, two separate servers can perform those roles. For more information, see Server Roles in Replication, later in this chapter.
SQL Server replication components are implemented by using a modular design. Because of this, if you are running high-activity production systems, you will be able to install components of replication on separate computers, balancing workload and helping to minimize SQL Server replication's impact on the production server's performance.
In a typical replication situation, the log reader process, the synchronization process, the distribution process, and the distribution database are installed on the publication server. However, these components can be installed on a separate server, which in some configurations can improve performance.