Elspeth Paton
SQL Server Development Team
Microsoft Corporation
April 1996
Today, companies require faster throughput from their databases than ever before. Integral to this increasing need is the necessity for a locking system that maximizes performance.
Locking synchronizes users' access to the database to ensure consistent data and correct query results. While one user locks an area of the database to view or change the data, the data is protected from other users trying to make changes to the same data. One user's changes are committed before another user can see or further change the data.
All modern database management systems use locks to provide concurrency in a multiple-user environment. Some use page-level locks, some use row-level locks, some even allow you to specify, usually at table-creation time, which level of locking (page, row, or table) will be used for an individual table.
Dynamic Locking is a new kind of locking strategy. Rather than require the database administrator to analyze and anticipate which level of locking is best, Dynamic Locking uses the intelligence of the database engine to optimize the granularity of locks depending on the needs of the applications accessing a Microsoft® SQL Server database.
Dynamic Locking, the locking strategy for Microsoft SQL Server is discussed in this document. As Microsoft continues to increase the functionality of Microsoft SQL Server, subsequent versions will build on the Dynamic Locking initiative. Insert row-level locking (IRL), available with Microsoft SQL Server version 6.5, is the first step in Microsoft's Dynamic Locking strategy. The Dynamic Locking strategy includes:
Benefits of Dynamic Locking include:
Microsoft SQL Sever 6.5 continues to support customizable locking when viewing data (using SELECT). The level of visibility can be specified in the SELECT statement or with the transaction isolation level option for the entire session. The transaction isolation level can be set to achieve the following:
Microsoft SQL Server 6.5 further reduces contention by using optimistic concurrency control. With optimistic concurrency control, no locks are held on the rows used to populate a cursor. Transactions that are executing concurrently are not prevented from reading or updating these rows. When a change is made to a row through the cursor, Microsoft SQL Server checks to see if the row has changed since it was read. The update only succeeds if the row has not been changed during the intervening period. Once updated, data is locked until committed. Optimistic concurrency control is ideal for client/server applications that allow users to browse data and make selective changes.
Microsoft SQL Server 6.5 uses the page as both a unit of storage and the area protected by a lock. Page-level locks are fast when several rows are updated per page, because they use less locks and therefore less overhead. In most cases, page-level locking is adequate, although contention can occur on pages that users frequently access. Contention occasionally occurs when a particular row or group of rows is updated frequently. More often, contention occurs when rows are inserted at the end of a table. IRL addresses the latter by allowing multiple users to simultaneously insert new rows on the same page in the table. Microsoft aims to add row-level locking for updates and deletes in future development.
An understanding of how data and indexes are stored is required to appreciate how to implement IRL effectively. The following section provides background information and outlines the process of inserting a row into a table.
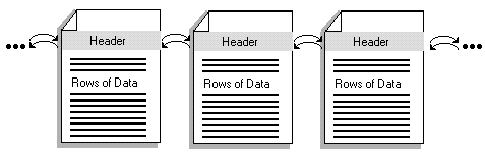
Rows from a table are stored on pages. A table consists of a group of pages linked together in a chain. As a table grows, a new page is added from a pool of available pages that are randomly distributed throughout the file. Available pages are allocated from unused pages in the device or from pages that have been released because of deletions. The pages that make up the table are not in any physical order, though they have been linked together with pointers that point to the physical position of the next or previous page. The pointers are stored in each page header, as illustrated in Figure 1.
Figure 1. Linked pages
The indexes in Microsoft SQL Server 6.5 are made up of pages that form a branching structure known as a B-tree. The starting page contains ranges of values within the table. Each range on the starting page branches to another page that contains a more detailed range of values in the table. In turn, these index pages branch out to more layers, which increase the number of pages in the layer and narrow the range of data on each page.
The branching index pages are called node pages. The final layer in the branching structure is called the leaf layer. In a unique, nonclustered index, the ranges on each leaf layer page point to a specific row of data in the table, and the data is stored separately from the index. In a clustered index, the leaf layer is made up of the data pages themselves because the data is stored with the index, in the physical order specified in the index. Figure 2 illustrates the page structures of clustered and nonclustered indexes.
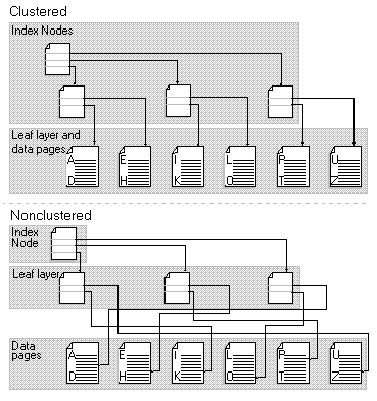
Figure 2. Comparison of clustered and nonclustered index B-trees
Contention occurs when two or more transactions try to access data on the same page at the same time and one must wait for the other to complete before it can proceed. In a real-time transaction-processing environment, contention becomes an important issue. Contention may be particularly evident when multiple users are inserting new rows because often all the new rows are written to the last page in the table's page chain. Similar contention problems can arise when multiple users update or delete rows on the same page. This is not a frequent problem because many applications typically access data that is randomly distributed over many pages, with only occasional contention for a single page.
As described above, a table with a clustered index contains rows stored in the index. When new rows are inserted, new pages are added to the page chain. The position of new pages depends on the key on which the clustered index was created. Consider a clustered index of a table based on the last name of a customer—as new customers are added, rows are inserted into the page chain, occasionally splitting pages. Given a random set of new customers, the insertions will be evenly distributed throughout the page chain. The page chain grows by inserting new rows into partially filled pages and splitting pages that are full. If a page splits, changes must be made to the index layer.
In contrast to this, consider a table that has a clustered index based on a chronological column or on a monotonically increasing key, such as an identity value that increments each time a record is added or an index based on the date and time the record is added. As new rows are inserted they are added to the end of the page chain, and the page chain grows in one direction. Because new pages are added to the end of the chain, the overhead of splitting pages is avoided. In a single-user environment, inserting into a table with an index based on a monotonically increasing key is more efficient than inserting into a table with an index based on a random key. The contention problem arises in multitransaction environments where each new insert must lock the last page exclusively. Other transactions must wait their turn, which causes a bottleneck (hotspot) on the last page.
With careful planning and a good understanding of the type and quantity of transactions that make up the database throughput, database designers can work around most major areas of contention. Now, with IRL, it is easier to achieve excellent performance for multiple-user inserts. Insert row-level locking allows the individual rows on a page to be simultaneously locked by multiple transactions that insert new rows.
Figures 3 to 6 illustrate how the type of index used on a table affects the amount of contention that occurs when new rows are inserted. Tables without clustered indexes, or with clustered indexes on monotonically increasing keys, experience more contention on the last page, and therefore benefit more from IRL. Nonclustered indexes on monotonically increasing keys also experience contention at the leaf level of the index; thus, the index also benefits from IRL.
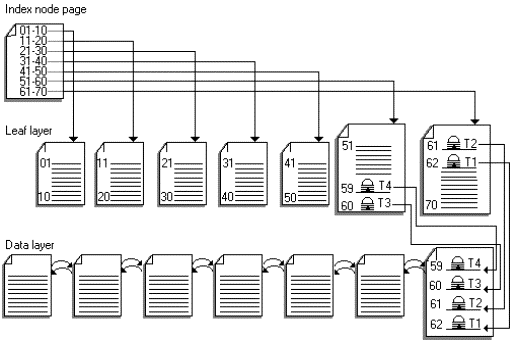
Figure 3. Table with a nonclustered index on a monotonically increasing key
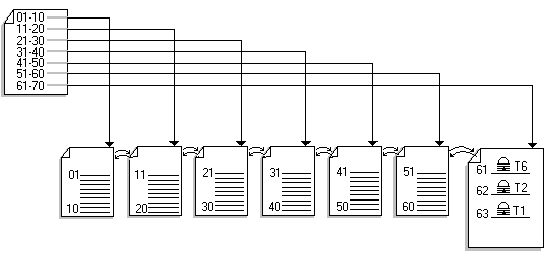
Figure 4. Table with a clustered index on a monotonically increasing key
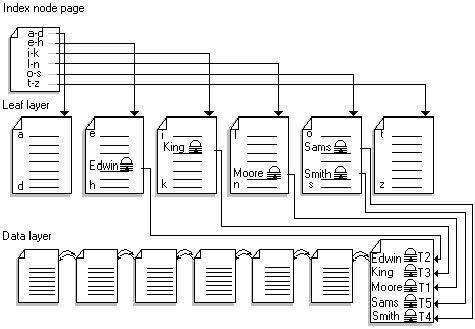
Figure 5. Table with a nonclustered index on a random key
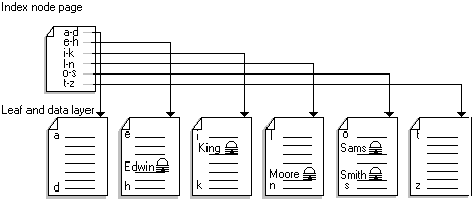
Figure 6. Table with a clustered index on a random key
Page-level locking is used for deletes and updates and is also used for inserts by default, unless IRL has been specified. When a transaction needs to update or delete a row on the locked page, the lock is escalated to an exclusive page-level lock.
The Microsoft SQL Server Dynamic Locking strategy emphasizes performance on multiple-user systems. Future releases of Microsoft SQL Server will continue to build on this strategy with increasingly sophisticated locking support.
Locking is adjustable: a transaction initially locks the page regardless of how many rows the transaction affects. The lock then de-escalates to several row-level locks, but only when there is contention from another transaction that wants to lock the page for an UPDATE, DELETE, INSERT, or SELECT. This scheme automatically minimizes locking overhead by keeping the number of locks to a minimum. Overhead is reduced by having only one page-level lock rather than several row-level locks, where possible. This scheme also reduces the probability of deadlocks, because by de-escalating the locks from page-level to row-level, the initial transaction will yield to the second transaction.
An alternative mechanism for reducing locks is to use a row lock initially, and when several rows on the same page are locked, try to minimize the total number of locks by escalating to a single page-level lock. With escalation from row-level to page-level locks, deadlocks will occur when two transactions attempt to acquire locks in each other's locked area.
Figure 7 illustrates how a page-level lock de-escalates to several row-level locks when there is contention.
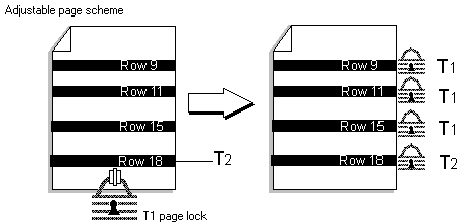
Figure 7. A transaction de-escalating a page-level lock
Transaction T1 must update several rows on the page. Initially, it uses a page-level lock, which requires less overhead than several row-level locks. Another transaction (T2) must update a row on the same page. T1 de-escalates its page-level lock to several row-level locks, and T2 uses a row-level lock. Row-level locks are used only when necessary, thus keeping the locking overhead to a minimum.
In future releases, the range of adjustable de-escalation will be increased to include an entire table range or page ranges within a table. A transaction will be able to lock a table or a range of pages in addition to a single page or row (Figure 8).
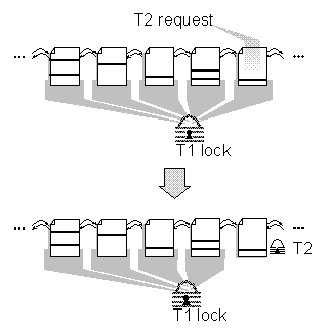
Figure 8. One transaction de-escalating locks and a second transaction acquiring locks
Transaction T1 locks the whole table during a transaction that is updating several rows in the table. T1 uses a table-level lock. Another transaction (T2) must update a record in the table. T1 de-escalates its table-level lock to a page-range-level lock and several page locks, yielding the specific page on which T2 needs to update a row.
The initial granularity of a transaction's lock is a table and it will de-escalate to smaller and smaller ranges of pages, down to an individual row, only when prompted by contention with other transactions (Figure 9).

Figure 9. Granularity of locks
Adjustable de-escalation decreases deadlocks because the first transaction always yields to subsequent transactions, preventing transactions from contending with each other for locks on the same page.
Figure 10 demonstrates how one transaction (T1) takes a page-level lock and then de-escalates the granularity of the lock only when there is contention from another transaction (T2).
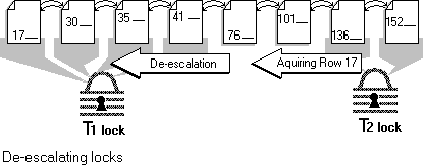
Figure 10. Yielding locks
Figure 11 shows two transactions that are acquiring locks hitting a deadlock when both transactions try to acquire a row locked by the other.
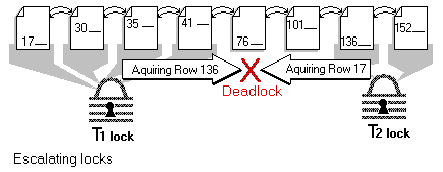
Figure 11. Two transactions hitting a deadlock
Row-level locking will apply to SELECT, DELETE, and UPDATE, as well as to INSERT operations.
In the future, statements will be introduced that will allow database designers to construct pages that store rows from different tables. This is a more object-oriented approach, because rows will be treated as objects. Currently, objects that are associated with one another are often locked by the same transaction. Locking overhead can be reduced if the associated objects are stored on the same page. There are situations where a particular mixture of objects from different tables is more commonly referenced. Joins are proof of this. Therefore, to reduce contention, reduce locking overhead, and improve performance, mixed pages that store objects of different types will be introduced.
Figure 12 illustrates a page with rows of different types of information that relate to the services provided by a financial company for one customer. Each type of row contains different fields and the rows are different lengths. Depending on the type of throughput on the system, using mixed pages in a case like this will reduce contention and improve performance. For example, a transaction accessing all the financial services associated with a particular customer needs to lock only one page, which reduces the locking overhead.
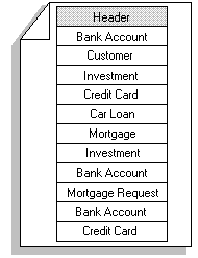
Figure 12. A mixed page used by a financial organization
Microsoft's Dynamic Locking strategy focuses on increasing throughput, reducing contention, avoiding deadlocks, and increasing performance. This combines to offer the best possible performance for transaction processing, with less development time needed and simplified administration.
Dynamic Locking provides the flexibility of row-level locking, the automatic optimization provided by the dynamic de-escalation locking scheme, and the object-oriented approach of mixed pages.