Chau Vu, Seiichi Satoh, and Matt Grove
Microsoft Visual C++ Business Unit
August 1995
Most of the information detailed here is from past experience within the Microsoft® Visual C++® business unit (VCBU), and it's very much geared toward multibyte character set (MBCS) for the Far East platforms (specifically Japan). Think of it as a guide/reference document instead of depending on it as a "how to" cook book.
Some parts of this document were written by Seiichi Satoh and Matt Grove, which I found very useful to include. Seiichi Satoh's original document was intended as a double-byte character set (DBCS) enabling spec. It is very specific to the Japanese platform but should be applicable to other Far East operating systems as well. Matt Grove's original document was intended to show how to write "internationally aware" code using the TCHAR.H header file. Using this header file and the techniques described in this document, code can be conditionally compiled to:
Actually, the DBCS libraries currently only handle Japanese. However, the techniques described in this document for DBCS should apply to Chinese and Korean as well.
It is assumed that the reader has some familiarity with the concepts of DBCS.
Most traditional C and C++ code makes a number of assumptions about character and string manipulation, which don't work very well (or at all!) for users outside the U.S. This section provides a brief overview of some of the problems involved in writing truly international code.
Our European users use the "U.S." (ANSI-compiled) versions of our products. If the market is big enough, we may translate a given product into (for example) German, but only the strings and resources are translated—the code is still the "U.S." version. Users of our product in smaller countries must use the U.S. version directly, complete with English strings.
The only real problem with writing code that our European users can use is that many characters in the European languages have values >=0x80. In particular, the "funny" characters such as ß, ç, å, ä, and so on all have values >=0x80. European users want to use these characters in their code comments, and in filenames (and potentially in other places where the user is allowed to name something). Since we use mostly signed characters in our code (the char type is signed by default), these characters will get sign-extended when converting to ints.
For example, the following code may behave quite differently from what you expect:
int some_table[256];
int some_func(void)
{
char ch;
int i;
// ch acquires some value here
i = some_table[ch];
}
The problem with this code is that array indexing is always done with ints. While ch <= 0x7F, this code does what's expected (indexing into some_table). But if ch >= 0x80, ch gets sign-extended and becomes a negative int! The above code will index prior to the start of the array in memory if ch >= 0x80. This is likely to cause a GP fault or index into some random data.
Note Beware of sign extension. Beware of code that may explicitly or implicitly be 'promoting' a char to an int, since the char may be sign-extended and become a negative-valued int.
These languages all use DBCS (double-byte character set, sometimes referred to as MBCS, or multibyte character set). In DBCS, a 'character' as the user thinks of it may be one or two bytes. There are two main problems when writing code for DBCS:
char must never point in the middle of a double-byte character. This is a recipe for disaster. All code must use special mechanisms to 'walk' a character string in order to ensure that it is never pointing to the 'trail' byte of a double-byte character.Most of the techniques described in this document are specific to Japanese, but they are also applicable to Chinese (China and Taiwan Region) and Korean.
In the Japanese language, there are four alphabets:
UNICODE really solves the problems described in the previous two subsections. In UNICODE, all characters are uniformly 16 bits. This solves the char -> int promotion problem AND the DBCS problem. Unfortunately, the world isn't quite ready for UNICODE yet.
When writing UNICODE code, the only real difference is that you can't use the C/C++ char type when you are dealing with 'real' characters (it's OK to use the char type if you are dealing with bytes). Instead, both the C and C++ languages define the wchar_t type, which is a 16-bit character.
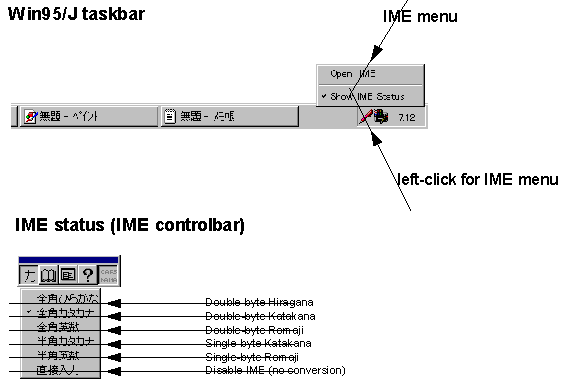
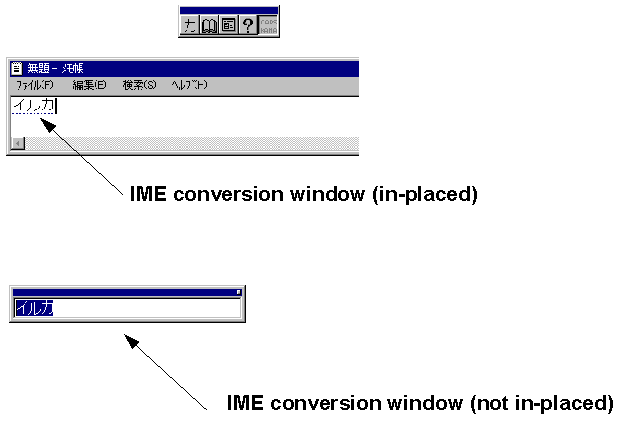
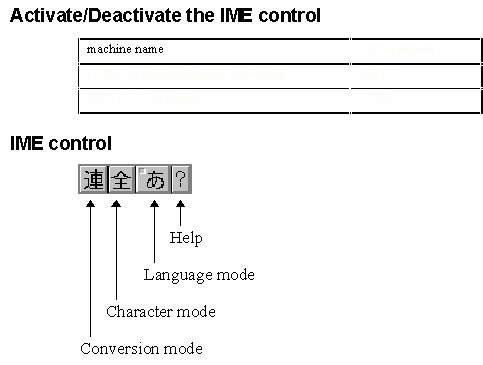
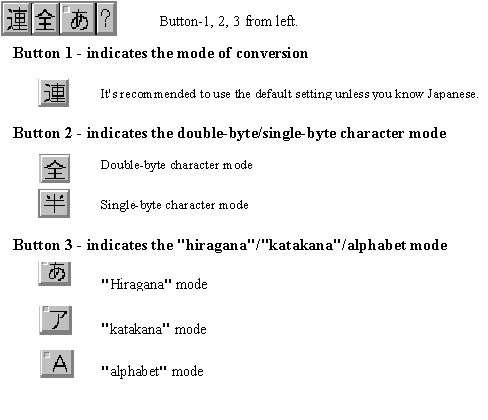
IMEs are applets that allow users to enter the thousands of different characters used in Far East written languages with a standard 101-key keyboard. The basic things you need to know about the IME are its status window and the conversion window.
To type some Japanese characters into an edit field, first activate the IME status (sometimes called IME control panel), then select an IME mode (for example, double-byte Katakana) and start typing Japanese phonetically, like "iruka" for "dolphin." Or, if you don't know Japanese, use those brand names that you are familiar with, such as "toyota," "yamaha," "suzuki," and so on.
There are three levels of IME support:
Visual C++ IDE is an IME-halfaware app. The IDE is fully DBCS-enabled, and it basically handles the IME conversion window correctly for the following situations: focus change, font change, window move, and window resize.
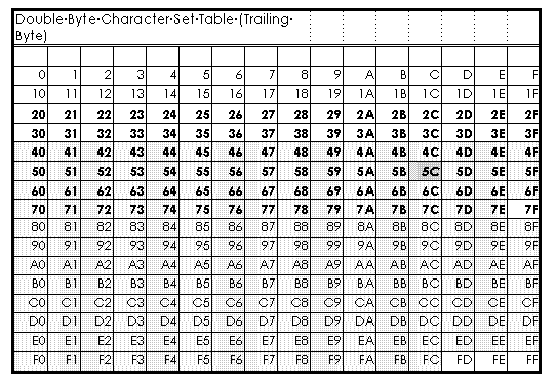
To distinguish DBC from SBC, the code area that is except for SBC characters is used as leading byte character so that applications can recognize that it is a DBC. In Japan, the code area of the trailing byte character partly overlaps. (In Korea, both of leading byte and trailing byte don't overlap with SBC.) The following is a Japanese DBC (Shift JIS) table.
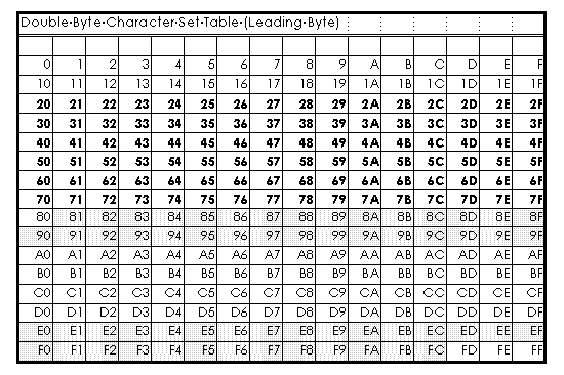
Lead Byte Ranges. Each code page may have different lead byte ranges.
| Japan | 932 | 0x81-0x9F |
| Korea | 949 | 0xA1-0xFE |
| China | 936 | 0xA1-0xFE |
| Taiwan Region | 950 | 0xA1-0xFE, 0x8E-0xA0, 0x81-0x8D |
Basically, an application can recognize 2-byte data in a string as DBC by scanning from the top of the string toward the end. If a string consists of DBC only, it's obvious that even bytes are leading bytes and odd bytes are trailing bytes. But in almost all cases, a string contains both DBC and SBC. In short, if a byte data that is pointed by a pointer has an SBC code, it isn't always an SBC itself.
Example:
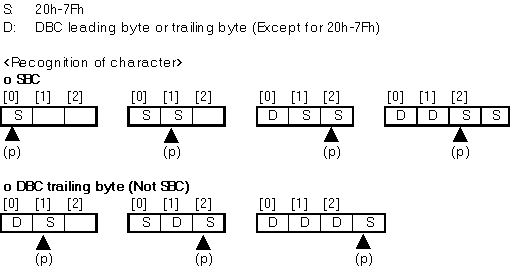
As I described above, SBC code in a string isn't always SBC itself. Then the following issues occur. But these issues are not always caused by DBCS but caused by Japanese DBCS system (Shift JIS). In Korea, these issues may not occur.
Applications must make sure an SBC code in a string is either SBC itself or not. Otherwise, some DBC may convert to another character.
Unfortunately, backslash code (5Ch) is used as a trailing byte of DBC in some characters (see table in section 1.2). When applications manipulate a string text of filename, applications must make sure a backslash code in a string text is either a real backslash or a trailing byte of DBC.
The following is an overview of DBCS enabling for multiline text control.
Caret (edit position on a line) must always be on the border between characters.
Comments (MasaT):
This section is not applied to IDE because IDE supports non-fixed-pitch fonts. However the idea that we locate the caret only between the characters is true for us.
See the following figure.
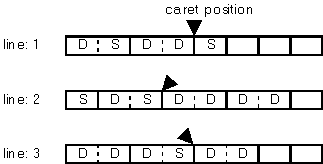
Deleting by delete key and deleting by backspace key must be carried out by each character.
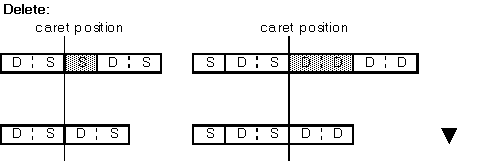
[SBC] on left; [DBC] on right
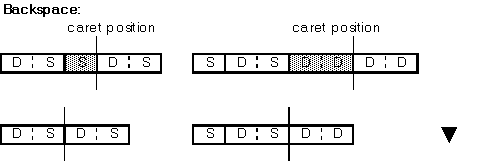
[SBC] on left; [DBC] on right
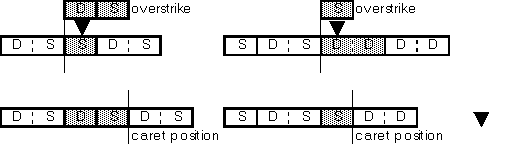
Left: [replace SBC with DBC]; right: [replace DBC with SBC]
Comments (MasaT):
This section is not applied to IDE because of IDE's spec.
If the leftmost character of a displayed line is a trailing byte data, it must be replaced with space (20H).
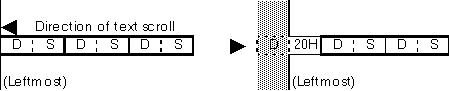
Comments (MasaT):
The key is handling the selection by character.
Characters in a text line must be selected by each character.
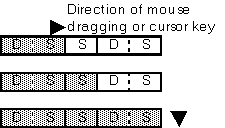
Comments (MasaT):
This section is not applied to IDE because of IDE's spec. We don't change the cursor shape.
Cursor shape must be changed by the character type.
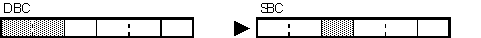
Comments (MasaT):
This section is not applied to IDE because of IDE's spec. See IDE DBCS spec for word detection.
The limit of selection is the following. But this spec cannot apply to all product.

The TCHAR.H header file is intended to help solve some of these problems.
TCHAR.H is an official part of the Windows NT™ Software Development Kit (SDK) header files. As originally defined (by VCBU and picked up by the Windows NT group), it included support for ANSI and UNICODE only. VCBU has extended this file to include support for DBCS (double-byte character set, also sometimes known as MBCS, or multibyte character set). The extended file will ship with Ikura, and represents VCBU's recommended solution for targeting ANSI, DBCS, and UNICODE. Windows NT may at some point pick up the extended file as their "official" header. This document describes the extended version of this file, which the Dolphin project is currently using.
TCHAR.H uses two compiler preprocessor symbols to determine how it behaves:
_UNICODE
_MBCS
If neither symbol is defined, ANSI (U.S., Europe) is assumed. If _UNICODE is defined, the code will be compiled for UNICODE; if _MBCS is defined, the code will be compiled for DBCS (MBCS). The behavior if both symbols are defined is undefined.
#ifdef _UNICODE
// UNICODE specific code
#endif
#ifdef _MBCS
// DBCS specific code
#endif
#if !defined(_UNICODE) && !defined(_MBCS)
// ANSI (single byte) specific code
#endif
// *** NON-SPECIFIC CODE ***
//
// Code not under any #ifs or #ifdefs is NOT specific
// to ANY configuration! It must work for all three!
All code should use these same symbols for consistency. Additionally, code that is Kanji (Japanese) specific should be #ifdef'd with the KANJI symbol. Whenever possible, however, code should be written to handle generic DBCS issues, rather than being Kanji specific.
TCHAR.H defines a new data type, the TCHAR type. (For ANSI conformance, the "official" type is _TCHAR. In practice, either TCHAR or _TCHAR is acceptable.) The exact underlying type that a TCHAR maps to depends on the setting of the _UNICODE and _MBCS symbols:
| Code compiled for | Actual type of TCHAR | Size of TCHAR data type, in bytes |
| ANSI | char |
1 |
| _MBCS | char |
1 |
| _UNICODE | wchar_t |
2 |
Generally speaking, you should not make any assumptions about the size of a TCHAR. You may have sections of code that are specific to ANSI, DBCS, or UNICODE, and assumptions about the size of a TCHAR are acceptable in those sections. Such specific sections of code are not usually necessary, though.
TCHARs don't actually help with DBCS programming at all—if the code is compiled for DBCS, a TCHAR is really just a char, as it is if the code is compiled for ANSI. Where TCHARs help is with UNICODE.
In code compiled for UNICODE, a TCHAR is actually a wchar_t, which is a 16-bit character. In UNICODE, all characters are uniformly 16 bits (two bytes). If the TCHAR type is used consistently in place of the char type, the code will work properly if compiled for UNICODE. Array indexing and pointer arithmetic, for example, is handled automatically by the compiler. Thus, the following code fragments work fine for both ANSI and UNICODE:
TCHAR * pch;
while (*pch == _T(' ')) // See section 8.2 for definition of _T macro
++pch;
TCHAR rgch[80]; // Declare an array of 80 TCHARs--actually
// 160 bytes if compiling for UNICODE
rgchSave[ich] = rgch[ich];
TCHAR * sz1, * sz2;
while (*sz1++ = *sz2++)
;
In fact, most such string manipulation works fine for both ANSI and UNICODE as long as you use TCHARs instead of chars.
One problem that arises trying to write code that works for both ANSI and UNICODE is the problem of character and string literals. In the C and C++ languages, the character literal 'A' has type int. (Strange but true. ANSI says that 'A', which might appear to be of type char, is actually of type int. The value of the constant 'A' depends on whether the char type is signed or unsigned. If it is signed, the value is the value of the character sign-extended to 16 bits. If it is unsigned, the 16-bit value will have a "high byte" value of 0. In particular, if chars are signed, then the expression '\xFF' == (int)-1 is true, and if chars are unsigned, then '\xFF' == (int)0xFF is true instead.) Likewise, the string literal "string" defines a nul-terminated array of chars. To declare a wide character character literal or a wide character string literal, you must use the L prefix, as in L'A' or L"string" (this is a language feature defined by both the C and C++ languages). The L prefix indicates that the character literal is of type wchar_t, and the string literal is an array of wchar_ts (including a wide character nul terminator). To avoid having to write code such as this:
TCHAR * pch;
#ifdef _UNICODE
if (*pch == L'A')
#else
if (*pch == 'A')
#endif
TCHAR.H defines the _T and _TEXT macros. These macros are identical; either one can be used. The remainder of this document will use the _T macro.
The _T macro takes a 'normal' character literal or 'normal' string literal as its argument and prepends the L prefix if compiling for UNICODE. Thus, the following code fragments work for both ANSI and UNICODE:
TCHAR * pch;
if (*pch == _T('A'))
DoSomething();
pch = _T("hello");
ASSERT(pch[0] == _T('h'));
ASSERT(pch[1] == _T('e'));
ASSERT(pch[2] == _T('l'));
// etc.
If you are comparing character literals or string literals against TCHARs or (TCHAR *)s, or are performing assignments between character literals or string literals and TCHARs or (TCHAR *)s, you must use the _T macro to define the character literals and string literals.
Subsections 4.1 and 4.2 showed how using TCHARs allows you to write code that will work properly for either ANSI or UNICODE. So how do they help with writing code that works correctly when compiled for DBCS? Well, they don't, really. TCHARs do succeed in "hiding" some of the UNICODE issues. Since the goal as stated in section 1 is to write code that will successfully work for ANSI, DBCS, and UNICODE, TCHARs are an important part of the system.
As noted earlier, TCHARs are really just chars when the code is compiled for DBCS. This means that all the usual DBCS problems are still present. Fortunately, however, the extended TCHAR.H defines various macros that work with all three environments—ANSI, DBCS, and UNICODE—if you use the TCHAR data type.
One of the most important things to remember when coding for DBCS is that you can't simply increment a character pointer, since it could be pointing to a one-byte or a two-byte character. Using TCHARs doesn't automatically help here, since a TCHAR is just a char when compiling for DBCS. So TCHAR.H provides two important macros to handle incrementing and decrementing character pointers:
pchNext = _tcsinc(pchCur);
pchPrev = _tcsdec(pchStart, pchCur);
Note that the _tcsdec macro requires a pointer to the start of the string as well as the pointer that is to be decremented. This is because in the DBCS case, backing up a character may require backing up all the way to the start of the string to "synchronize" the pointer with a known 'good' character boundary (that is, a byte that is known not to point to the second byte of a double-byte character). In actuality, the first argument to _tcsdec can be a pointer to any known 'good' character boundary inside the string that lies prior to the other pointer argument passed in (that is, pchStart < pchCur).
If you have a pointer to a character that is of unknown size, you must use the _tcsinc and _tcsdec macros to work properly in a DBCS environment.
There are cases where you can safely increment a TCHAR pointer or a TCHAR index—if you have sufficient knowledge that the characters that make up the string are not double-byte characters in DBCS, then you don't need to use _tcsinc and _tcsdec. For example, if you are dealing with a string that is known to be a C or C++ language identifier, then that string should not contain any double-byte characters in DBCS. It is also true that if you are pointing to a character that is known not to be a double-byte character in DBCS, you need not use _tcsinc:
TCHAR * pch;
while (*pch == _T(' '))
++pch;
Beware of making the same assumption about _tcsdec, though—it is only safe to decrement a TCHAR pointer or index if the character previous to the current one is known to be a single-byte character in DBCS.
In general, the "better safe than sorry" rule applies. The _tcsinc and _tcsdec macros are actually just inline functions for the ANSI and UNICODE cases, since they don't need to do anything special (assuming the 'character pointer' arguments are of type (TCHAR *) and not (char *)). So there shouldn't be any loss of efficiency from using these macros and compiling for ANSI or UNICODE.
Section 4 described the TCHAR data type, and various macros that help to write code that can be conditionally compiled to work with ANSI, DBCS, and UNICODE. So far, however, any discussion of the various C run-time library functions, such as strlen, strcpy, strchr, and so forth, has been absent. So an interesting question arises:
What exactly does strlen(szSomeString) return? Does it return:
TCHARs?
The answer is that strlen always returns the length in bytes of the string passed in. In fact, it is true of all the strxxx functions that they 'think' only in bytes and single byte nul-terminated strings.
Calling strlen on a UNICODE string is likely to be quite disastrous. The character L'A' in UNICODE has the value 0x0061. Calling strlen on the string L"ABCDE" will thus return either zero or one, depending on how the CPU arranges 16-bit quantities (80x86 CPUs will store 0x0061 in memory as 0x61 0x00, so strlen() will return 1 in that case).
In general, the strxxx routines can be disastrous, since UNICODE strings are quite likely to contain embedded nul bytes.
Calling strlen on a DBCS string works fine—it returns the length of the string in bytes. In the DBCS system, a single nul byte indicates the end of a string, and it is guaranteed that the second (trail) byte of a double-byte character will never be zero.
ANSI defines a set of wcsxxx functions that work in UNICODE. (Our run-time libraries have extended this notion to encompass non-standard string functions. For example, Microsoft defines the string function _stricmp and the UNICODE equivalent _wcsicmp.) They are analogous to the strxxx functions, except that they 'think' in wchar_ts instead of in bytes. Thus, wcslen returns the length of its string argument (a string composed of wchar_ts!) as a count of wchar_ts. To find the length of a wide character string in bytes, you must multiply by sizeof(wchar_t).
So how do we find the length of a string in bytes in a way that works for U.S., DBCS, and UNICODE? Here's one solution:
TCHAR * sz;
#ifdef _UNICODE
cb = wcslen(sz) * sizeof(TCHAR); // Can't call strlen() on a wide char string!
#else
cb = strlen(sz); // strlen() works fine for U.S. and DBCS
#endif
Fortunately, TCHAR.H provides a better method. In the same way that ANSI defined a set of wcsxxx functions that 'think' in wide characters (wchar_ts), TCHAR.H defines a set of _tcsxxx functions that 'think' in TCHARs. Thus, _tcslen returns the length of a string in TCHARs, and the code above can be rewritten as simply:
TCHAR * sz;
cb = _tcslen(sz) * sizeof(TCHAR);
All _tcsxxx functions work with TCHARs. (This isn't actually quite true. Most _tcsxxx functions behave this way. There are a few exceptions, but they have non-standard names. For example, _tcsclen returns the length of its argument string in logical characters. It is, however, true that every _tcsxxx function that is a direct analogue of a strxxx function will behave as described in the box.) Arguments and return values are TCHARs, (TCHAR *)s, counts of TCHARs, or indices into arrays of TCHARs.
Thus, _tcsspn returns a TCHAR index into the string argument, _tcsncpy copies up to 'n' TCHARs, and so forth.
Generally speaking, the _tcsxxx macros map to either strxxx, _mbsxxx, or wcsxxx. The _mbsxxx are analogues of the strxxx functions that handle DBCS strings. (This is not always true. For historical reasons, _mbslen returns the length of its argument in logical characters. A logical character is a character as the user thinks of it—as a component of a word or other piece of text, and as something that has a single visual representation on the screen. In the DBCS system, a logical character is one or two bytes, while a TCHAR is always one byte. If α, β, and δ are double-byte characters, then the string "αβXYZδ" contains 9 bytes [and thus 9 TCHARs], but only 6 logical characters. Calling _mbslen on that string would return 6. As a result, _tcslen maps to _wcslen for the UNICODE case, but strlen for both U.S. and DBCS, and thus correctly returns the length of the string in TCHARs. Some other _mbsxxx functions behave this way [returning counts of logical characters, or logical character indices, or taking such values as parameters], while others don't. In any event, the _tcsxxx functions take this into account and map to alternate functions when this would present a problem. The _tcsxxx functions always deal only with TCHARs and TCHAR counts or indices.)
See section 7 for examples of how to use the _tcsxxx functions.
A "TCHAR enabled" version of the Microsoft Foundation Class Library (MFC) is available since Visual C++ 2.0. All appropriate MFC methods and functions will change from accepting or returning (char *)s to accepting or returning (TCHAR *)s. All methods of the CString object will observe this behavior. For example, CString::GetLength will return the length of the string in TCHARs. Likewise, CString::Left will return the leftmost N TCHARs of the string.
This section provides tables of common actions, and the proper code for those actions. Unless otherwise noted, all strings are of type TCHAR *, all characters are of type TCHAR, and all character indices are TCHAR indices.
| Action | Non-CString code | CString code | Comments |
| Find the length of a string in bytes | cb = _tcslen(sz) * |
cb = string.GetLength() * |
strlen is dangerous when used on UNICODE strings |
| Find the number of bytes required for a buffer to copy a string into | cb = _tcslen(sz) * |
cb = string.GetLength() * |
strlen is dangerous when used on UNICODE strings |
| Copy a string | _tcscpy(szDst, szSrc); |
stringDst = stringSrc; |
strcpy is dangerous when used on UNICODE strings |
| Increment a TCHAR pointer | pch = _tcsinc(pch); |
// not applicable | Handles DBCS case |
| Decrement a TCHAR pointer | pch = _tcsdec(pchStart, |
// not applicable | Handles DBCS case |
| Obtain a TCHAR pointer to the last "logical character" of a string | pch = _tcsdec(pchStart, |
// not applicable | Technique is to find pointer to nul terminator, then decrement pointer |
| Compare the TCHAR pointed to against a character constant | if (*pch == _T('A')) |
// not applicable | Use _T macro! |
| Skip leading spaces in a string | while (*pch == _T(' ')) |
// not applicable | ++pch is OK since character being skipped is known to not be a double byte character |
| Find the first occurrence of the character '&' in a string | pch = _tcschr(sz, |
ich = string.Find(_T('&')); |
For CString case, ich returned is TCHAR index |
| Find the last occurrence of the character '&' in a string | pch = _tcsrchr(sz, |
ich = string.ReverseFind(_T('&')); |
For CString case, ich returned is TCHAR index |
| Walk a string, examining each character | while (*pch != _T('\0')) |
ich = 0; |
Note that ExamineChar takes a (TCHAR *) parameter rather than a TCHAR parameter. Otherwise, in DBCS, we might be passing the first (lead) byte of a double byte character, which is useless (or worse) to the called function. The CString code is complicated; in general, this sort of thing is done better by setting pch = string (using CString's operator const TCHAR * method) and using the non-CString code. Don't do this if you plan to modify the string, though._tclen is a macro defined in TCHAR.H which returns the length of the character pointed to in TCHARs. |
| Is a character an alphabetic character? | // !! complicated !! |
// !! complicated !! |
This is quite complicated to get right. In general, AVOID using the isxxx and toxxx routines such as isalpha, isupper, toupper, etc. There are _istxxx definitions in TCHAR.H, but there are hidden traps for the unwary. |
| Compare two characters | if (_tccmp(pch1, |
if (_tccmp(string1 + ich1, |
The _tccmp macro defined in TCHAR.H compares two characters given (TCHAR *)s. |
| Make a string uppercase | _tcsupr(szString); |
string.MakeUpper(); |
Easy, for once! |
| Copy a 'source' string into a 'destination' buffer of size cchBuf (count of TCHARs) while there's still space | cchUsed = 0; |
// not applicable | Note use of _tclen to find the length (in TCHARs) of a character (a DBCS character may be one TCHAR long or two TCHARs long), and use of _tccpy to copy a character (copying a character in DBCS may involve copying one or two TCHARs; _tccpy does the right thing automatically and is cheap for ANSI and UNICODE). |
| Watch for buffer overflow after the translation | IDS_STRING1 "Die
|
// not applicable | This is the original code and 25 character buffer is certainly not enough after the translation.
|
| Search for first backslash in path\filename | char * |
// not applicable | This is just to show how the code is done. In reality, use C run-time _tcschr(psz, T('\\')) to find the first occurrence of a backslash in a string. |
| Check if a path ends with a backslash (i.e. c:\path\ ) | pszTemp = _tcsrchr(psz, |
// not applicable | |
| Byte indices | while (rgch[i] != '\\') |
// not applicable | The original code is as shown below and it has the same problems as pointer manipulation.
|
| Character assignment | while (*pszSrc) |
// not applicable | The original un-world-wide enabled code looks like this.
|
| Buffer overflow | -------- incorrect ---
|
// not applicable | The original un-world-wide enabled code looks like this.
|
| Enjoy writing this kind of code | // not likely | // not here either | Try to understand all the issues and remember to THINK. |
The use of TCHAR.H under _MBCS can be confusing.
The basic problem is that when _MBCS is defined, some of the _tcs*() macros map to _mbs*() functions, which expect "unsigned char *" parameters (_tcschr() -> _mbschr()), while others map to _str*() functions, which expect "char *" parameters (_tcscat() -> strcat). A previous version of TCHAR.H type-cast the macro parameters, leading to type safety problems. Now TCHAR.H supplies type-safe function thunks that map _tcs*() functions to _mbs*() functions. For compilers without inlining, these functions now also exist in the run-time libraries. Also, the old method of mapping (via macro) directly from _tcs*() to _mbs*() still exists, but you must either live with "char * != unsigned char *" warnings (in C at least, C++ will error), type cast the parameters yourself, or use _TXCHAR, which maps to "unsigned char *" in the _MBCS case.
So to summarize the options using _tcschr as an example:
The following example is provided courtesy of Chris Weight.
////////////////////// START TCHAR.H EXAMPLE ///////////////////////////
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <direct.h>
#include <errno.h>
#include <tchar.h>
/*
* Generic program.
*/
int __cdecl _tmain(int argc, _TCHAR **argv, _TCHAR *envp)
{
_TCHAR buff[_MAX_PATH];
_TCHAR *str = _T("Astring");
char *amsg = "Reversed";
wchar_t *wmsg = L"Is";
#ifdef _UNICODE
printf("Unicode version\n");
#else /* _UNICODE */
#ifdef _MBCS
printf("MBCS version\n");
#else
printf("SBCS version\n");
#endif
#endif /* _UNICODE */
if (_tgetcwd(buff, _MAX_PATH) == NULL)
printf("Can't Get Current Directory - errno=%d\n", errno);
else
_tprintf(_T("Current Directory is '%s'\n"), buff);
_tprintf(_T("'%s' %hs %ls:\n"), str, amsg, wmsg);
_tprintf(_T("'%s'\n"), _tcsrev(str));
return 0;
}
/*
* Unicode version.
*/
int __cdecl wmain(int argc, wchar_t **argv, wchar_t *envp)
{
wchar_t buff[_MAX_PATH];
wchar_t *str = L"Astring";
char *amsg = "Reversed";
wchar_t *wmsg = L"Is";
printf("Unicode version\n");
if (_wgetcwd(buff, _MAX_PATH) == NULL)
printf("Can't Get Current Directory - errno=%d\n", errno);
else
wprintf(L"Current Directory is '%s'\n", buff);
wprintf(L"'%s' %hs %ls:\n", str, amsg, wmsg);
wprintf(L"'%s'\n", wcsrev(str));
return 0;
}
/*
* SBCS version.
*/
int __cdecl main(int argc, char **argv, char *envp)
{
char buff[_MAX_PATH];
char *str = "Astring";
char *amsg = "Reversed";
wchar_t *wmsg = L"Is";
printf("SBCS version\n");
if (_getcwd(buff, _MAX_PATH) == NULL)
printf("Can't Get Current Directory - errno=%d\n", errno);
else
printf("Current Directory is '%s'\n", buff);
printf("'%s' %hs %ls:\n", str, amsg, wmsg);
printf("'%s'\n", strrev(str));
return 0;
}
/*
* MBCS version.
*/
int __cdecl main(int argc, char **argv, char *envp)
{
char buff[_MAX_PATH];
char *str = "Astring";
char *amsg = "Reversed";
wchar_t *wmsg = L"Is";
printf("MBCS version\n");
if (_getcwd(buff, _MAX_PATH) == NULL)
printf("Can't Get Current Directory - errno=%d\n", errno);
else
printf("Current Directory is '%s'\n", buff);
printf("'%s' %hs %ls:\n", str, amsg, wmsg);
printf("'%s'\n", _mbsrev(str));
return 0;
}
////////////////////// END TCHAR.H EXAMPLE ///////////////////////////
The difference is that Win32 APIs rely on System information, whereas the CRT APIs rely on the user to initialize for the appropriate settings. CRT defaults to ANSI "C" locale.
For example: The following example will fail even if psz really points to a Japanese lead byte and the system is running in a different codepage other than 932.
// **** undefined behaviour ****
setlocale(LC_ALL, "Japanese"); // set run-time to Japanese locale
if (IsDBCSLeadByte(*psz)) // query system locale *** wrong ***
....
// **** correct behaviour ****
if (isleadbyte((_TXCHAR)*psz)) // correct locale is used. Also note that
// (_TXCHAR) casting was used to make sure
// integral conversion is correct
Some TCHAR functions take int as input. If you pass on a TCHAR and it happens to be in the range of 0x80-0xff, the compiler automatically converts it to sign char first and then to int, and this is wrong. The following example makes sure *psz is converted to unsigned char before becoming an int.
if (isleadbyte((_TXCHAR)*psz))
The danger is when a string get translated, the order you expected might get switched around and it's disastrous, especially when the format strings aren't the same (that is, %s %i %c get switched to %i %c %s).
LINETOOLONG_STRING "line %i in file '%s' is too long."
translated string becomes "....'%s'........%i...."
szBuffer.LoadString(LINETOOLONG_STRING);
wsprintf(szTmp, szBuffer, i, filename); // the translated string
// will end up with address of 'i' being used for %s
There are alternative ways to avoid this problem but none are foolproof. When you absolutely have to do this, make sure to notify the translator clearly on how the message should be translated. Alternative ways can be done using AfxFormatString2(), or structure your message and break it off into smaller, self-contained messages.
We deliver an English product that is DBCS-enabled to an external localization site and have them use a tool to do the translation, then ship back to us the translated EXEs and DLLs. It is very likely that the translators will know nothing about the product, so it's hard for them to know what string should or shouldn't be translated. Therefore, it's absolutely critical for us to move all non-localize strings back into code where they belong.
Generalize the font usage and make sure the right character set is being selected accordingly. Most of the time, DEFAULT_CHARSET should be used or, for specific CharSet, query the system for what's available.
From experience, adding 30 percent more for the width is sufficient. This addition really helps when running the English version on non-English platforms because most non-English platforms have bigger font size, especially for the Far East ones.
Commdlg is convenient and saves time, but it's sometimes a headache for the localized versions. When you pass your own template to a commdlg call, it's likely that you get inconsistency in size and font between your template controls and commdlg's controls.
Very often the same English word or string being used in different contexts gets translated into different words or strings for some languages. For this reason, always provide one resource string for each item, even though they are the same string.
For example: Japanese UI guide recommends that only SB Katakana and/or Kanji should be used on main menu and in list box. DB Katakana, Kanji, and/or Hiragana should be used in pop-up menu and dialog control.
It's not unusual for a programmer to build strings out of existing strings by stripping out certain key words/characters. This should be avoided as much as possible, because you can never guarantee that the same method will work after a string has been translated.
For example: sometimes it's convenient to strip out the '&' character from a menu item to build a string such as "F&ind in files..." to become "Find in files...". For Japanese, the menu item is translated as "????????(&I)..." and the output becomes "????????(I)...", which is wrong
Don't assume that this conversion will reduce your buffer size in half, because if there are DB characters in the string, you will overflow the buffer. A safe bet is to keep the buffer size the same as when it was in UNICODE.
By default, all C/C++ programs operate in the "C" locale as defined by the ANSI/ISO C standard, but beware of other locales.
For example: isalpha() returns TRUE for inputs a-z, A-Z, but in French locale, it also returns TRUE for characters such as é.
Don't use these characters when assigning shortcut keys: @ $ { } [ ] \ ~ | ^ ' < >. These keys are often not available on foreign keyboards or sometimes require more than three simultaneous keystrokes, and are very awkward to type.
The text template you are most familiar with in the Font dialog box is "AaBbYyZz". When you use the common font dialog with your own template, make sure you don't change this text template—for different font CharSet, the text is automatically switched to that CharSet. If you use your own text template, it will stay constant no matter what font CharSet is selected.
When converting upper/lower using _toupper/_tolower, don't assume the locale is what you are expecting. If you don't know for sure, use AnsiUpper/AnsiLower instead.
Don't define constants that are related to locale in header files. Put them in a resource table and communicate the constants' definitions to the translator.
For example: the definitions below will require a recompile, which is not desirable:
#define DEFAULT_LEFTMARGIN 1 // left margin default is 1 inch
#define DEFAULT_RIGHTMARGIN 2 // right margin default is 2 inch
Avoid hardcoding the lead byte tables in your code. They rarely get changed, but you never know. Use isleadbyte() or IsDBCSLeadByte() instead.
Don't be surprised to see the above menu item. This is the old Win 3.1/J style that we need to keep in mind when parsing the string.
Don't forget that there will be two messages for every DB character. Always check to see if a lead byte is received, and buffer the characters correctly.
The MFC CString is MBCS-enabled. Use it.
Make the C run time work for you. Use _tcschr(), _tcsrchr(), _splitpath(), _makepath(), _fullpath(), and so on
The best test cases when dealing with file/path name have to do with DB characters with trailing byte being a backslash (\0x5C) or a vertical bar (\0x7C). The best way to generate a DB character like that is to activate the IME control and change it to double-byte Katakana mode (see IME section x.x for more detail), then follow the below examples. The first example generates a DB character with a backslash in the trail byte. The second example generates a DB character with a vertical bar in the trail byte.
It's not unusual for a Japanese localized product to have English text in it, so how do you know if a string has been translated or not. It's easy, because a translated string has this format: "........(&X)" where 'X' is the hotkey.
For example: English menu item "&ClassWizard" becomes "ClassWizard(&C)" in Japanese.
Most often, you will run into a situation where you will have no idea whether it's a by-design or a bug. The best way to determine what it is, is to use either Notepad, Wordpad, or Winword/J and see how those apps handle the situation.
When testing the cursor movement and text selection, move the cursor into a DB character from all directions (left, right, up, down). Also use a good combination of text steam that includes both SB and DB characters intermixed.
When testing the cursor movement and text selection, click the mouse in the middle of a DB character. Also, use a good combination of text steam that includes both SB and DB characters intermixed.
When testing buffer limit on an edit field, try typing a DB character when the cursor position is at second from last, next to last, and last just before the end of line is reached.
For example: if the limit is 10 characters, test a DB character when the cursor is at 7th, 8th, and 9th position.
When possible, run your test on different codepages, especially 437, 850, and 932.
For ASCII, a filename using character 'a' is the same as a filename using character 'A'. However, a filename using DB character 'a' is NOT the same as a filename using DB character 'A'.
Double-byte characters are not case-sensitive. In other words, there is no such thing as upper/lower case for a DB character. Test to see if an app handles this okay by selecting a DB character, and do the opposite case conversion to see if the character changes.
Testing of insert and overstrike modes on DB character should be interesting too.