Microsoft Corporation
November 1997
The following white paper focuses on cluster architecture and implementation, which is becoming increasingly important as applications evolve to require an environment of multiple server nodes to run at their best. Microsoft® Cluster Server is designed to keep nodes in a cluster synchronized so that you can always know the configuration or state of the multiple machines.
Clustering is a configuration of a group of independent servers so that they appear on a network as a single machine. This group is managed as a single system, shares a common namespace, and is designed specifically to tolerate component failures and to support the addition or subtraction of components in a way that’s transparent to users.
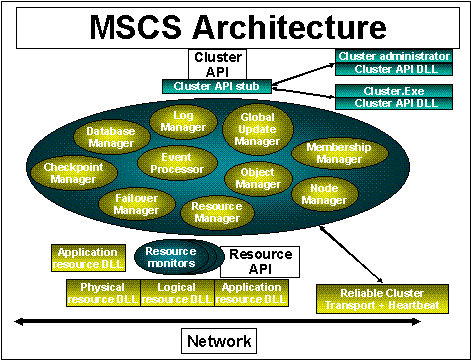
Figure 1. Microsoft Cluster Server comprises nine essential objects designed to ensure high availability, reliability, and manageability. In a cluster, if a certain resource or set of resources goes down, the system intelligently chooses where and how to run applications in the network. With clustering, you can also use one of two nodes to run certain services while doing maintenance on the other node and then return the maintained node to the cluster without affecting services. In short, clustering provides the high availability of a multiple-node network with the management simplicity of a single address space.
The goals driving development of the Microsoft Cluster Server were (1) to extend the Microsoft Windows NT® operating system to seamlessly include cluster features, and (2) to support key applications without modification.
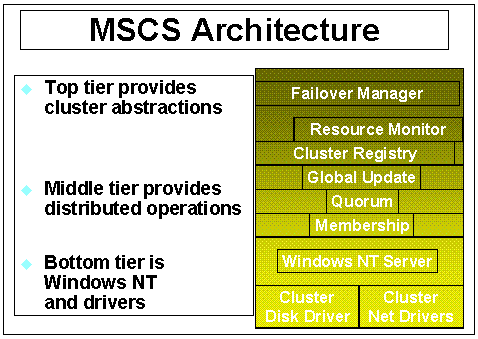
Figure 2. Microsoft Cluster Server is based on a three-tier design. The top tier provides cluster abstractions; the middle tier provides distributed operations, which are used for orderly addition and removal of services from active nodes; and the bottom tier provides Windows NT and drivers. Communications in a cluster are performed primarily through remote procedure calls (rpc ), with universal product code (upd) used for membership messages, and interconnects are based on Ethernet.
The essential features of Microsoft Cluster Server are a simplified hardware configuration, “remotable tools,” the Microsoft BackOffice® family product support, and clustering solutions for all levels of customer requirements. This last feature is designed to eliminate cost and complexity barriers. Remotable tools provide manageability enhancements you can use to have Windows NT 4.0 and Windows NT 5.0, for example, migrate half a cluster at a time. You can implement Windows NT 4.0 on half the cluster, do a regression test once you’re sure your machine is up and running, then roll the other side over to Windows NT 5.0.
This is the kind of mission-criticality necessary for mail and other such services. You must be able to do a certain level of testing before you bring them all over, and clustering provides an effective way to accomplish this testing. In effect, as long as an application has no poorly behaved server-side context, you can install it under Microsoft Cluster Server and it will work fine with very little modification.
The single exception is when a server doesn’t persist its data. For example, a very numerically intensive calculating application that never checkpoints its data would be a poor candidate for a cluster. This is because if it crashes without check-pointing its data and then you move it to the other side of the cluster, you haven’t yet persisted the data, which means you can’t restart the application and you will have lost all calculations.
Note that there are two features specifically excluded from Microsoft Cluster Server. One, the product is not lock-step/fault-tolerant; that is, it does not support the “moving” of running applications. This means that applications within a Microsoft cluster are not necessarily 99.99999 percent available—usually defined as a maximum of three or four seconds of downtime per year.
However, Microsoft Cluster Server does provide very high availability, easily supporting applications that can tolerate 20 to 30 seconds of downtime. This kind of availability stems from the fact that within a cluster you’re not actually moving an application in the event of a failover, even though it may appear so. Instead, you’re just doing a checkpoint restart, where you take the persisted data and use it as a means of reconstituting an application on the other side.
Two, Microsoft Cluster Server is unable to recover a shared state; that is, a file position, between client and server. This characteristic is based on the philosophy that all client/server transactions should be atomic, following the Atomic Consistent Isolated Durable (ACID) rule.
Name abstraction is a central concept in clustering. To understand name abstraction, consider that if you installed Microsoft Exchange Server in the past, you inherited a namespace from that installation—in this case, the host name. So every time you refer to that Exchange Server, you have a dependency host name, and every client that gets to that Exchange Server gets there by using the host name.
Within clustering, you’re taking that namespace and removing the physical link and physical dependency of where the name actually exists. This means that the name no longer exists within the context of a specific node, but instead is “floated” as necessary. The same is true for other types of services and resources. With name abstraction, you can also take an application or service and reinstate it where you need it to run, without clients needing to know of where it exists—the best of distributed computing. With nothing more than a service name, clients can use the service regardless of what happens to be running at any time.
Another concept central to the practice of clustering is the quorum resource. A quorum resource is usually, though not necessarily, a small computer system interface (SCSI) disk that arbitrates for a resource by supporting something known as the challenge/defense protocol (explained later). This resource should be capable of storing the cluster registry and cluster logs. It also is used to persist configuration change logs, tracking changes to the configuration database when any defined cluster member is missing or not active. This prevents configuration partitions in time, also known as “temporal partitions,” which are undesirable, because changed configuration data is not persisted, thereby causing an out-of-sync cluster.
The quorum device drives the practice of cluster ownership. Ideally, in a cluster only one server should know the cluster configuration and be able to make decisions on that part of the cluster service. So, when you build the cluster service, you use a couple of algorithms to determine “who’s in charge.”
One algorithm is a simple majority, which would certainly cancel each other out. To do this, you use a quorum resource by doing the following. Within the cluster administrator, you determine a quorum—usually, but not always, part of a SCSI disk determining who has ownership of the cluster. Recall that only one owner can own a resource at any time. That’s the same mechanism used to ensure that only one person is in charge of the cluster at any time.
This is important, because to implement a cluster server, you must designate a disk to act as the quorum device—which provides arbitration and a knowledge of who’s in charge at any time. A device arbitrates for a resource by supporting the challenge/defense protocol of storing the cluster registry and logs. The quorum resource not only arbitrates, but also provides a place for doing checkpoints. This means it persists configuration-change logs, tracking changes to the configuration database when any defined member is missing (not active).
The quorum device also prevents configuration of partitions in time, also known as temporal partitions. These partitions are considered a negative in clustering. So, if you change one node while a second node is down, you can expect that when the second node comes up, it would have the right configuration information. You don’t want to go from state to state prime on one machine and then bring up another machine and have it come back as state and not state prime. That would mean you had lost some state information.
You use the quorum device as a means of logging those changes so that at any time, you can survive catastrophic failures and bring data back on time in an orderly manner. This is because with configuration data on the quorum device, you can always know where the information is.
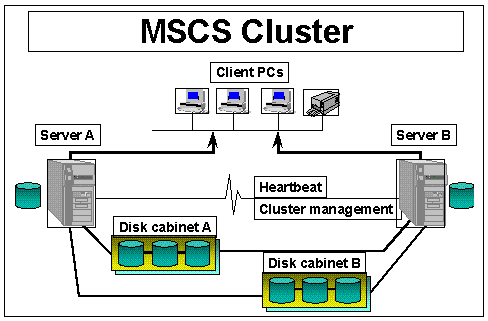
Figure 3. A clustered environment observes the highest possible transactual semantics, with some parts of the registry being entirely transactual-based. In a typical cluster, there’s a kind of “heartbeat” across the clustered nodes to ensure that everything is in synch and so that each node can ensure that the other is functioning.
A third concept central to clustering depends on both the namespace and the quorum device. It’s known as the “heartbeat” of a cluster. Consider the heartbeat in the following context: If a network adapter should accidentally become unplugged, the heartbeat would fail. Consider also if, on the other hand, all network connections should become unplugged. Say, you have a server A that owns a cabinet A, a server B that owns a cabinet B, and so on. Perhaps server A is working on Microsoft Exchange and server B is working on Microsoft SQL Server, so they’re both very active and they’re both servicing client requests.
Moreover, assume that even some of the database functions were part of some of the Exchange-based applications. In any case, if server B can’t see server A, because the networks aren’t available, there’s a problem. The solution is that server B can use the quorum resources to learn whether server A is still functioning. Essentially, it does a low-level bus reset of the SCSI buses between the machines.
But now, with a bus reset, the reservation that server A had been holding on disk cabinet A would be lost. Server A then would have roughly 10 seconds to reestablish that reservation, which would in turn let server B know that A was still functioning—even though B wouldn’t necessarily be able to communicate with server A. So server A “commits suicide,” which is intended so that you don’t have two servers trying to be “in charge.”
With this, you also ensure that, for example, all applications that were on server B then flow to server A, which is still online though no longer visible by Server B. Server A may now be a bit slower, but clients will still get their applications serviced. The IP (Internet protocol) address and network names will move, applications will be reconstituted according to the defined dependencies (as discussed earlier), and clients will still be serviced, without any question as to the state of the cluster.
Now, looking at the cluster view, there’s a namespace that’s used for cluster administration, but the applications never use that namespace. Think of it as being padlocked—the cluster’s IP address, its network name, and its time service. Remember, you can move groups across the cluster, but for your applications, you must create virtual servers with disk resources and at least an IP address and a network name.
You should also avoid referring to applications by the cluster name so that if the cluster name is brought offline, it won’t be the single point of dependency for your application. You can also have more flexibility by giving applications their own namespace. For example, with a virtual server name, you can take that component offline. When you install Exchange as a virtual server, you have no namespace affinity to a specific node. This means you can easily reconstitute Exchange on a new set of servers.
As for node name changes in Exchange services, that’s a bit more complex, but also made relatively easy by clustering, which lets you create such changes wherever you want.
To the external world, the namespace looks like a set of servers passing out resources. The external world sees the nodes, which is why you should avoid using the node name for anything, because it has a physical mapping. Instead, you should use only the virtual server names with IP addresses and network names to represent the services.
Now, the cluster service has numerous mechanisms to ensure that everything is tightly synchronized across the two nodes. For example, a global update—a global atomic broadcast, if you will—means that changes occur on both nodes or no nodes. Exchange is fairly strict about this in that if you use a global update and a node present in the cluster refuses to take the change, you may encounter an event log reporting that a “poison packet”—precipitating the suicide referred to earlier—was sent to that node. That is, Exchange kills the node if it refuses to take an atomic broadcast.
The reason for this is that if the node refuses to take the change, that means that it’s out of synch with the rest of the cluster. Also, note that a database manager persists the cluster changes, and a database manager looks like the registry. You can explore it by going to the registry and opening the H-key local machine hive. There, you find a new “cluster hive” containing all the cluster definitions.
In this hive, Exchange transacts everything in the cluster and keeps this information in synch across both nodes. For example, also in the hive, you find the location of the quorum device and all the new resources you have created. The hive enumerates these resources as “good” to ensure type safeness. This lets you do renames; that is, to modify names of your virtual servers.
The purpose of these registry entries is to ensure that you don’t have any hard dependencies to work with—that once you make a name, it need not be permanent. You can think of this hive as the cluster database, a transactional one at that.
The cluster log is an environmental variable that you define for a filename that provides details of what’s happening in the cluster service. To access the cluster log, you can use primarily your PC sessions, but also UPD for heartbeats. Note that the cluster service exists within several dimensions within Windows NT. You have two low-level device drivers—a cluster-disk driver and a cluster-net driver—and your own transport stack. The disk driver is a filter driver implemented so that you permit one and only one node at a time to access the disk resource. In the middle tier are numerous distributed operations to run, such as a global update, quorum, and membership.
Also parts of the cluster log are several abstractions for application developers to use. They include the cluster registry, a resource monitor, the failover manager, and others. Other applications include a namespace impersonation that provides a computer name that the application can initialize so as to know where it’s running. This is implemented so that if the node fails over, the application gets the right name.
In sum, these services are designed to simplify the movement of most applications to the cluster service.
Several other concepts also come into play in understanding clusters. Membership is a term used for the orderly addition and removal of active nodes to and from the cluster. Regroup is used for failure detection, through heartbeat messages and for the forced eviction of active nodes from the cluster. A defined cluster is simply all the nodes in the cluster, and an active cluster, a subset of a defined cluster, comprises the active nodes and the quorum resource.
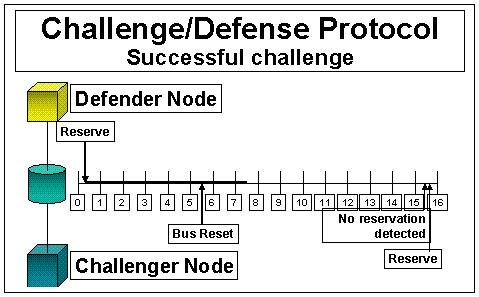
Figure 4. The challenge/defense protocol works as follows: SCSI-2 has reserve/release verbs with a semaphore on the disk controller. The owner of the disk controller gets a “lease” on the semaphore, which it can renew every three seconds. To preempt ownership, a challenger clears the semaphore with a SCSI bus reset, waits ten seconds (three seconds for renewal and two seconds for bus-settle time—twice, to give the current owner two chances to renew). If the semaphore is still clear, the challenger takes the lease from the former owner by issuing a reserve to acquire the semaphore.
Regroup works by recomputing the members of the cluster. Then, each node sends a heartbeat message to a peer, one message per second, by default. If two or more messages are lost, then regroup occurs. This is based on a suspicion that the “sender” node is inactive. Using a five-round protocol, the cluster agrees to regroup after checking communications among the nodes. Finally, the cluster manager informs the cluster’s upper levels (such as the global update) of the regroup event.
The global update, one of the cluster’s key middle-tier operations, propagates global updates to all nodes in cluster. Through it, the cluster maintains the replicated cluster registry. All updates are atomic and totally ordered, and will tolerate all benign failures, depending on cluster membership: If all nodes are up, all can communicate, and thus the update goes through. (For more information on this topic, see R. Carr, Tandem Systems Review. V1.2 1985, Sketches Regroup and Global Update Protocol.)
Here’s how the global update algorithm works: The cluster has a locker node, typically the oldest node in the cluster, that regulates updates. To do a global update, the cluster sends update information to the locker node, which, in turn, updates itself and then other active nodes in seniority order. If the update is a failure on all nodes, then the update does not occur, and updated nodes will roll back on recovery. As for survival of any updated nodes, since the new locker node is the oldest in the cluster and therefore is updated if any are, it restarts the update.
The cluster registry, which is separate from the local Windows NT Registry, maintains updates on members, resources, restart parameters, and other configuration information. It’s important that the registry be maintained on stable storage and that it be replicated at each member through the global update protocol. Note that the Windows NT Registry keeps a local copy of the cluster registry.
The cluster Resource Monitor provides polling functions, checking nodes to determine which are and which are not alive. It detects failures through poll and through a failure event from a particular resource. The cluster Failover Manager informs the Resource Monitor when it is time to restart the cluster.
The Failover Manager assigns groups to nodes based on failover parameters such as available resources or services on the node. Any resource within a cluster, including a logical disk, an IP address, a server application, or a database can fail over; that is, move, from one machine to another.
When failback to the preferred owner node is called for, the group’s preferred owner comes back online. This occurs only during the failback window, however, typically scheduled for night or some other nonactive period.
Within a Microsoft cluster, time must increase monotonically; otherwise, applications can become “confused.” Another cluster rule concerning time is that time is maintained within failover resolution—though not “hard,” because failover occurs on the order of seconds. In addition, time is considered a cluster resource, so one node can “own” all the time, and other nodes can periodically correct the drift from the owner node’s time.
To add a node to the cluster is to create a virtual server. First, consider what defines a server on a network—a network IP address and a network name. Once you have those, you have a server that people can access and use. Then consider what defines a virtual server: also the assignment of an IP address and the network name. By doing this, you can make it appear that there are more servers on a network than there actually are.
A node joins a cluster by following these steps: When a node starts up, it mounts and configures only local, non-cluster devices. Then Windows NT starts the cluster service, which searches the local (stale) registry for cluster members and asks each member in turn to sponsor the new node’s membership. The search stops when it finds a sponsor, which can be any active cluster member. The sponsor authenticates the applicant, broadcasts the applicant name to other cluster members, and sends an updated registry to the applicant. Now the applicant is a cluster member.
To remove a node from a cluster, set Pause in the cluster administrator program. When the node is offline, move all groups off this member, sending a ClusterExit message to all cluster members. This prevents regroup and stalls during departure transitions. Now close the cluster connections so that the node is no longer an active cluster member, and the cluster service stops on the node. Last, evict the node by removing it from the defined-member list.
In the event of a node or communication failure, the cluster triggers a regroup event, which finds out if a node has left the cluster. After regroup, one of two states occur:
Under nonminority rule, the number of new members must be equal to or greater than half the old active cluster. This provision prevents a minority from seizing the quorum device at the expense of a larger potentially surviving cluster. In addition, the quorum guarantees completeness, by preventing a so-called split-brain cluster; that is, a newly forming cluster containing only a single node.
When designing clustering into Exchange, Microsoft sought to fill two primary goals: high availability and protection against hardware failure. Note, however, that Exchange-user load-balancing and data backup are not part of these goals and, therefore, not necessarily supported in Microsoft Cluster Server.
The requirements for using Microsoft Cluster Server are (1) you run symmetric hardware with the same disk, processor, and RAM configuration for every processor, and (2) you establish an Exchange resource group with an IP address, a shared cluster disk drive or drives, and a network name.
Note that in implementing a clustered Exchange environment, you must use one resource dynamic-link library (DLL) for each service. This enables individual services to be brought down without causing complete failover and eases troubleshooting. Note also that Exchange relies on the generic-resource DLLs supplied with Microsoft Cluster Server.
There are two ways you can install Microsoft Cluster Server: a primary-node setup and using a secondary-node setup. The primary-node setup ensures that you do the following: install cluster-aware Exchange on a Windows NT cluster, limit destination drives for data and binary files to shared cluster drives, copy system shared files into your local SYSTEM32 directory, set up resource dependencies, and create and register services. Then, run PerfWiz to optimize your Exchange environment.
Using the secondary-node setup, you copy system shared files into your local SYSTEM32 directory, which sets up resource dependencies, creates and registers servers, and disables PerfWiz. Note that IMS and INS wizards are cluster-aware, requiring that you run the wizards in your primary node and run “update node” on your secondary node before starting the services. Also note that PerfWiz is enabled only on the primary node and limits its analysis to disks within the Exchange resource group. For its part, the Administrator supports server-monitor changes, a service-accounts password, and database paths.
The core services of Microsoft Cluster Server include the System Attendant, Directory Service, Information Store, Message Transfer Agent, Internet Mail Service, and Event Service. In the event of automatic startup on failover, services continue to perform their usual startup-recovery processes. Also on failover, the cluster manager copies the cluster registry data from the primary to the secondary node.
Other services, considered “noncore” include:
When you are using Microsoft Cluster Server, please note the following shortcomings: First, in the event of a failure, resource DLLs can take up to 10 minutes to learn that a service is dead. Second, expect long timeouts on Exchange Server shutdowns. Deliberate failovers, for example, can take up to 10 minutes. Third, note that there is no Exchange-specific failure detection.
Finally, here are a few tips. It’s best to use Cluster Administrator to stop or start services, rather than the Service Control Manager or the NET START command line. Otherwise, you may experience unintended failovers. Also, use another machine on the network instead of a cluster machine to run the Administrator program or to view the Event Log on a failed cluster node.
Microsoft is now working on the next iteration of the Cluster Server for Windows NT 5.0 and supplemental products in terms of the cluster namespace. These products will address the issue of linear scale availability so as to support larger and larger applications.
Of all the information you take away from this White Paper, perhaps the most important is that you review the potential impact of clustering on your applications. To mitigate risk in this area, consider using the cluster registry APIs and think hard about installation on both cluster nodes in your applications. Other services to consider are the Name Service and Registry Replication. One final note: Make it simple and plan before implementing.
For the latest information on Microsoft Exchange, check out our World Wide Web site at http://www.microsoft.com/exchange/default.asp.
For more information on clustering, see the following sources:
Microsoft Windows NT Server home page: http://www.microsoft.com/ntserver/default.asp
In Search of Clusters: The Coming Battle in Lowly Parallel Computing, Gregory Pfister, Prentice Hall, 1995, ISBN: 0134376250
Tandem Global Update Protocol, R. Carr, Tandem Systems Review. V1.2 1985, sketches regroup and global update protocol
VAXclusters: A Closely Coupled Distributed System, Kronenberg, N., Levey, H., Strecker, WITH, ACM TOCS, V4.2 1986. A (the) shared disk cluster
Transaction Processing Concepts and Techniques, Gray, J., Reuter A., Morgan Kaufmann, 1994. ISBN 1558601902, survey of outages, transaction techniques
Inside Windows NT, H. Custer, Microsoft Press, ISBN: 155615481
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This White Paper is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.