Colleen Lambert
ODBC Product Group
Created: March 22, 1994
Open database connectivity (ODBC) is Microsoft’s strategic interface for accessing data in a heterogeneous environment of relational and nonrelational database management systems (DBMS’s). Even though ODBC has enjoyed growing industry support, various reports of poor performance have surfaced among MIS professionals, analysts, and engineers. Most of these reports are based on a lack of understanding of the ODBC architecture, improper use of ODBC within applications, and poorly optimized ODBC drivers.
This article first outlines some of the causes of poor performance, and presents the architecture of ODBC as an overview. A cross-section of applications is discussed with respect to how each utilizes ODBC. Inspection of these applications provides an insight into situations in which performance may suffer.
Finally, the article suggests various techniques for optimizing performance of applications using ODBC and ODBC drivers.
Many MIS decision-makers, analysts, field engineers, and independent software vendors (ISVs) believe that open database connectivity (ODBC) performance is poor. The overall effect of this perception has been that ODBC is being positioned as a low-performance solution for decision support to be used only when connectivity to multiple databases is an absolute requirement. This article will review the architecture of ODBC and applications using ODBC. To adequately explore these topics, it is necessary to discuss the Microsoft® Jet database engine utilized by Microsoft Access® and Visual Basic® version 3.0. The latter part of the article discusses various application and driver optimizations to promote better performance.
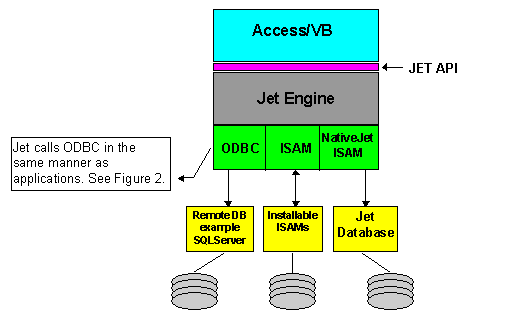
Oddly, the perception of poor ODBC performance was, in part, perpetuated by a lack of understanding of the Jet architecture. Jet, used in Microsoft Access and Visual Basic 3.0, is an advanced database management system (DBMS) technology that provides a means of accessing desktop databases as well as remote client-server databases. As an advanced DBMS, Jet requires a very rich and functional cursor model. Although ODBC does not utilize Jet, Jet makes heavy use of ODBC for accessing remote databases. Figure 1 illustrates the relationship of Jet to ODBC and applications such as Microsoft Access and Visual Basic.
Figure 1. Relationship of Jet to ODBC
Many of the performance issues attributed solely to ODBC were likely caused by:
Further adding to the confusion has been the theorizing of many analysts. They surmise that because ODBC adds more layers, it is therefore slower than using a proprietary interface. While some drivers do add additional layers by mapping to the proprietary interface, other drivers, such as Microsoft SQL Server, bypass the proprietary interface and emit the database protocol directly. However, even with extra layers, the overhead in a client-server application on the network and at the server far exceeds any overhead at the client in terms of overall performance and is therefore insignificant.
Some developers have also suggested that ODBC performance is poor. They cite the lack of static SQL (structured query language) support in ODBC as a cause of poor performance. Without this feature they conclude that the same level of performance cannot be achieved. This argument is not any different from comparing a proprietary, embedded API to a typical call-level interface. Vendors that support both, such as Sybase and Oracle, have moved to using stored procedures to achieve the same performance benefits. Since ODBC supports stored procedures, ODBC can make the same claim.
The assertion that ODBC’s performance is always equal to if not better than all other solutions is false. There are a few instances where ODBC may be slower. For example, depending on the driver's implementation for loading and connecting, ODBC may take longer to connect to the data source than using a proprietary API. This is related to the amount of work done under the covers during connection in order to support ODBC capabilities.
Specifically, there is the time for the Driver Manager to load the driver DLL (dynamic-link library); this time will vary depending on how the driver writer specified that segments should be loaded. Also, some drivers such as the Microsoft SQL Server driver, by default, request information (such as user-defined data type information and system information) from the server at connect time. Usually the driver will expose an option to disable retrieval of such information for applications where those items are not important, which gives equivalent performance to native API connections.
Drivers to non-SQL databases such as dBASE® will, in fact, be slower than going through dBASE directly in certain cases. Some people expect ODBC to have the same performance with this data going through SQL as with using the native interface. This is simply not true in all cases. On the other hand, using SQL as the interface provides operations that are not available in non-SQL databases.
PC databases are built on ISAMs, which have a different data model than SQL. Some things are much easier and faster with ISAMs, such as scrolling, single table operations, and indexed operations. But others are difficult if not impossible, such as joins, aggregations, expressions, and general Boolean queries. Neither model is better; it depends on the features required by the application. For example, when an application looks for all the people in the EMPLOYEE table ordered by an index on NAME, the ISAM interface will have better performance than a SQL engine every time. But if an application needs to calculate the average age of EMPLOYEEs in all the DEPARTMENTs with more than 20 employees, SQL is much easier to program. In this example, you could accomplish the operation with an aggregate and a GROUP BY and a HAVING clause, and would have performance equivalent to the code required in the native interface, such as dBASE.
The goal of this article is to demystify the ODBC architecture and to suggest techniques to tune applications and drivers for optimal performance.
Part of the perception of poor performance is related to a lack of understanding of the architecture of ODBC. Without an understanding of the architecture, performance issues become matters of speculation. By understanding the architecture, applications and drivers may be tuned in very specific ways to enhance performance.
The ODBC architecture has four components:
The Driver Manager and driver appear to an application as one unit that processes ODBC function calls. Figure 2 illustrates the relationship among the four components.
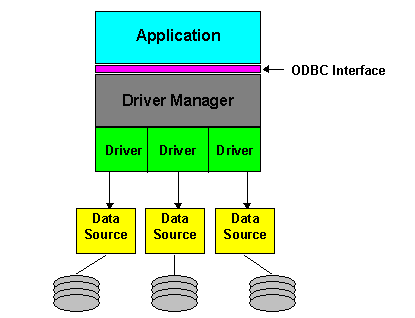
Figure 2. ODBC architecture
To interact with a data source, an application:
The following diagram (Figure 3) lists the ODBC function calls that an application makes to connect to a data source, process SQL statements, and disconnect from the data source. Depending on its needs, an application may call other ODBC functions.
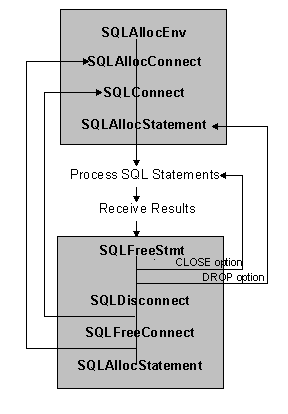
Figure 3. ODBC application function calls
Additionally, an application can provide a variety of features external to the ODBC interface, including mail, spreadsheet capabilities, online transaction processing, and report generation. The application may or may not interact with users.
The Driver Manager exists as a dynamic-link library (DLL). The primary purpose of the Driver Manager is to load ODBC drivers. In addition, the Driver Manager:
The Driver Manager processes all or a large part of many ODBC functions before passing the call to the driver (if ever). This is the case with many of the information and connection functions.
Information functions
SQLDataSources and SQLDrivers are processed exclusively by the Driver Manager. These calls are never passed to the driver. For SQLGetFunctions, the Driver Manager processes the call if the driver does not support SQLGetFunctions.
Connection functions
For SQLAllocEnv, SQLAllocConnect, SQLSetConnectOption, SQLFreeConnect, and SQLFreeEnv, the Driver Manager processes the call. The Driver Manager calls SQLAllocEnv, SQLAllocConnect, and SQLSetConnectOption in the driver when the application calls a function to connect to the data source (SQLConnect, SQLDriverConnect, or SQLBrowseConnect). The Driver Manager calls SQLFreeConnect and SQLFreeEnv in the driver when the application calls SQLFreeConnect.
For SQLConnect, SQLDriverConnect, SQLBrowseConnect, and SQLError, the Driver Manager performs the initial processing, then sends the call to the driver associated with the connection.
For any other ODBC function, the Driver Manager passes the call to the driver associated with the connection.
The Driver Manager also checks function arguments and state transitions, and checks for other error conditions before passing the call to the driver associated with the connection. This reduces the amount of error handling that a driver needs to perform. However, the Driver Manager does not check all arguments, state transitions, or error conditions for a given function. For complete information about what the Driver Manager checks, see the “Diagnostics” section of each function in the ODBC Function Reference and the state transition tables in Appendix B of the ODBC Software Development Kit (SDK).
If requested, the Driver Manager records each called function in a trace file after checking the function call for errors. The name of each function that does not contain errors detectable by the Driver Manager is recorded, along with the values of the input arguments and the names of the output arguments (as listed in the function definitions).
A driver is a DLL that implements ODBC function calls and interacts with a data source.
The Driver Manager loads a driver when the application calls the SQLBrowseConnect, SQLConnect, or SQLDriverConnect function.
A driver performs the following tasks in response to ODBC function calls from an application:
A data source consists of the data a user wants to access, its associated DBMS, the platform on which the DBMS resides, and the network (if any) used to access that platform. Each data source requires that a driver provide certain information in order to connect to it. At the core level, this is defined to be the name of the data source, a user ID, and a password. ODBC extensions allow drivers to specify additional information, such as a network address or additional passwords. The data source is responsible for:
There are two basic types of drivers in ODBC: single tier and multiple tier. With single-tier drivers, the driver processes both ODBC calls and SQL statements. In this case, the driver performs part of the data source functionality. With multiple-tier drivers, the driver processes ODBC calls and passes SQL statements to the data source. One system can contain both types of configurations. Let’s take a more detailed look at the architecture of these drivers.
Single-tier drivers are intended for non-SQL–based databases. The database file is processed directly by the driver. The driver processes SQL statements and retrieves information from the database. SQL statements, once parsed and translated, are passed to the database as basic file operations. A driver that manipulates an Xbase file is an example of a single-tier implementation.
A single-tier driver may limit the set of SQL statements that may be submitted. The minimum set of SQL statements that must be supported by a single-tier driver is defined in the ODBC SDK Programmer’s Reference in Appendix C, “SQL Grammar.”
Single-tier drivers are generally slower than using the native DBMS tools such as Microsoft FoxPro® because they parse and translate the SQL statements into basic file operations. The degree to which they are slower depends on how optimized this process is. Difference in speed between two different single-tier drivers is usually attributed to the method of optimization.
Figure 4 illustrates a typical situation where the data source resides on the same computer as the other components of ODBC. Note that the driver contains logic to access the data source.
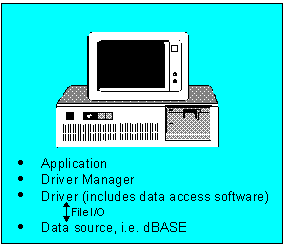
Figure 4. Single-tier driver and data source on same computer
With the use of single-tier drivers, the data source need not be restricted to the same computer. These drivers can also be used in classic file/server configurations, as Figure 5 illustrates.
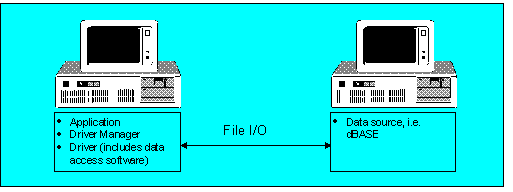
Figure 5. Single-tier driver using a client-server
In a multiple-tier configuration, the driver sends requests to a server that processes these requests. The requests may be SQL or a DBMS-specific format. Although the entire installation may reside on a single system, it is more often divided across platforms. Typically, the application, driver, and Driver Manager reside on one system, called the client. The database and the software that controls access to the database reside on another system, called the server. There are two types of multiple-tier drivers: two-tier and three-tier (or gateway).
Among two-tier drivers, there are two variations. The variations are conveniently defined in terms of SQL functionality, being either SQL-based or non-SQL–based.
Drivers for SQL-based DBMS’s, such as Oracle or Sybase, lend themselves to a fairly straightforward implementation. The ODBC driver on the client side passes SQL statements directly to the server-based DBMS using the database’s data stream. The DBMS handles all processing of the SQL statements. Figure 6 illustrates the relationship of the ODBC driver to the SQL-based DBMS.
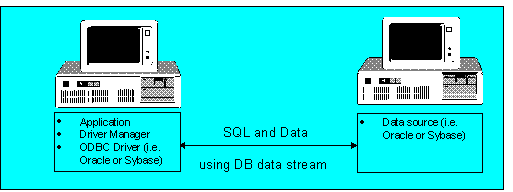
Figure 6. ODBC driver for SQL-based DBMS
Non-SQL–based DBMS’s require extra code on the server side to parse and translate the SQL to the native database format. There are currently two significant implementations of this. In the first (Figure 7), SQL is completely parsed and translated to basic file I/O operations. These file operations act on proprietary data on the client side.
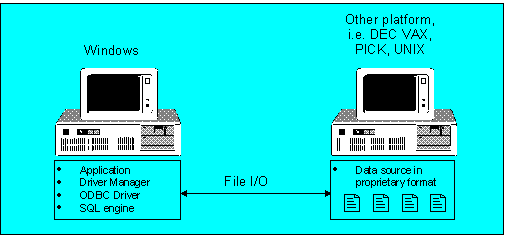
Figure 7. Non-SQL DBMS ODBC implementation using client-side SQL engine
In the second implementation, SQL statements are parsed and translated into the native database format on the server side. There may be some partial parsing on the client side as well. Figure 8 illustrates this implementation.
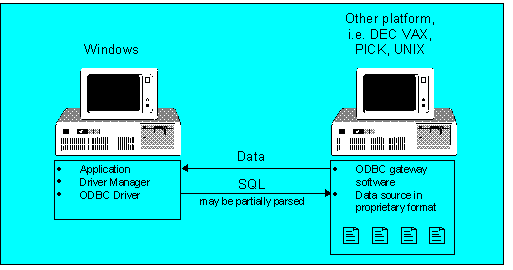
Figure 8. Non-SQL DBMS ODBC implementation using server-side SQL engine
Another type of multiple-tier configuration is a gateway architecture. The driver passes SQL requests to a gateway process, which in turn sends the requests to the data source residing on a host. Gateway drivers may support both SQL-based and non-SQL–based gateways.
Often the gateway is simply a network communications-level gateway such as in Figure 9. In this case, SQL is passed all the way to the host. This is the architecture of the Information Builders Inc. EDA/SERVER product.
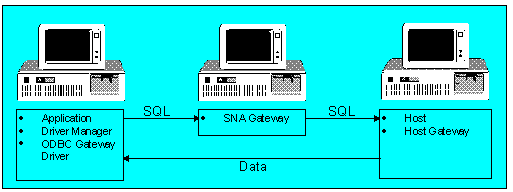
Figure 9. Network communications-level gateway
In other implementations, the gateway parses and translates SQL into DBMS-specific SQL or DBMS-specific format. Gateway code on the host is also typically required. Figure 10 illustrates this architecture. MicroDecisionware provides an ODBC driver based on this architecture.
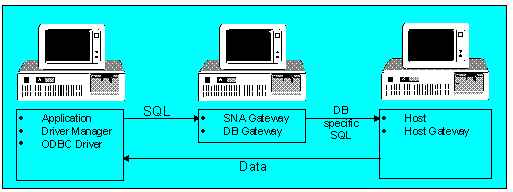
Figure 10. Three-tier driver using database gateway
Yet another architecture is the distributed relational database architecture (DRDA). Wall Data has written an ODBC driver that accommodates DRDA. Figure 11 depicts the implementation.
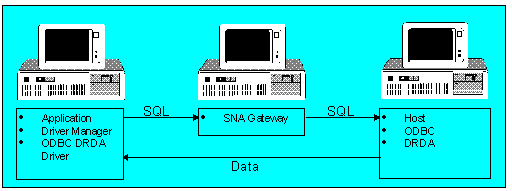
Figure 11. ODBC DRDA implementation
Many Microsoft and third-party applications and libraries exploit ODBC functionality. Understanding how they utilize ODBC is useful when exploring ODBC performance issues related to use of these applications.
These applications call ODBC directly via the ODBC API. Word also uses ODBC for mail merges utilizing data sources. This is transparent to the user.
Microsoft Query is a tool that queries ODBC data sources. It is intended as an end-user application and is written in such a manner that it calls ODBC directly. Performance of Microsoft Query is affected only by the level of optimization of the driver.
The Microsoft Word Developer’s Kit provides ODBC extensions for WordBasic. This permits direct ODBC access to any DBMS that supports ODBC via ODBC drivers. The kit is available from Microsoft Press, and includes a disk that contains the ODBC extensions for WordBasic. When using WordBasic and ODBC, performance will depend on the user’s coding techniques (with respect to ODBC) and the level of optimization within the ODBC driver.
Like ODBC, Jet provides transparent access to any database in your environment, regardless of the data's location and format. Jet is built around a keyset-driven cursor model. This means data is retrieved and updated based on key values. A key value is a value that uniquely identifies each record in a table.
The keyset model introduces complexities in how Jet operates against ODBC data sources. Traditional relational database environments use a dataset-driven model; that is, the data in a result set is thought of as one set of records. A DBMS may provide cursor capability on the set of records within the DBMS itself, enabling the client to scroll around in the data and update specific records, but typically this is not the case. So Jet itself must implement this functionality.
Visual Basic and Microsoft Access both use the Jet engine. Remember Figure 1? It overstated Visual Basic’s use of the Jet engine. The following figure (Figure 12) clarifies the relationship.
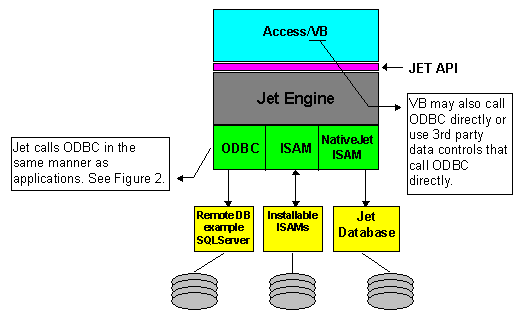
Figure 12. Microsoft Access/Visual Basic relationship to Jet
So what is it that makes Jet different from ODBC? It is helpful to answer this in terms of functionality. One difference is ease of use. The use of Jet is generally transparent to users of Visual Basic and Microsoft Access. Another difference is found in the cursor model. Although the ODBC API provides the same level of functionality that Jet cursors do, not all ODBC drivers support that functionality. The ODBC cursor library in ODBC 2.0 provides a subset of the existing ODBC functionality. The ODBC cursor library supports only the snapshot cursor model with limited update capability. With Jet, both snapshot and keyset cursors are provided, and the update capabilities are more extensive.
When Jet executes a query, the result set returned is either a dynaset or a snapshot. A dynaset is a live, updatable view of the data in the underlying tables. Changes to the data in the underlying tables are reflected in the dynaset as the user scrolls, and changes to the dynaset data are immediately reflected in the underlying tables. A snapshot is a nonupdatable, unchanging view of the data in the underlying tables. The result sets for dynasets and snapshots are populated in different manners.
Result set population
A snapshot is populated by executing a query that pulls back all the selected columns of the rows meeting the query's criteria. A dynaset, on the other hand, is populated by a query that selects only the key columns of each qualifying row; and the actual data is retrieved via a separate query using the key values to select the row data. In both cases, these result sets are stored in memory (overflowing to disk if very large), allowing you to scroll around arbitrarily.
Microsoft Access and Visual Basic populate the result set slightly differently. Microsoft Access is optimized to return answers to you as quickly as possible; as soon as the first screen of result data is available, Microsoft Access paints it. The remainder is fetched as follows:
When the population query reaches the end of the result set, a snapshot does no further data fetching; a dynaset does no more key fetching but will continue to fetch clusters of rows based on those keys, as you scroll around (see below). In addition, if a connection is needed solely for this key-fetching query, it is closed, unless either:
Visual Basic populates the result set in the same manner with the exception that it does not use background cycles to further populate the result set. User scrolling is the only manner in which population proceeds.
Data fetching
When rows of data are needed (for example, to paint a datasheet), a snapshot has the data available locally. A dynaset, on the other hand, has only keys and must use a separate query to ask the server for the data corresponding to those keys. Microsoft Access asks the server for clusters of rows specified by their keys, rather than one at a time, to reduce the querying traffic.
The dynaset behind a Microsoft Access datasheet/form does in fact cache a small window of data (roughly 100 rows). This slightly reduces the "liveness" of the data but greatly speeds moving around within a small area. The data can be refreshed quickly with a single keystroke and is periodically refreshed by Microsoft Access during idle time. This contrasts with a snapshot, which caches the entire result data set and cannot be refreshed except by complete reexecution of the query.
In addition to background key fetching, a dynaset also fills its 100-row data window during idle time. This allows you to page up or down "instantly" once or twice, provided you give Microsoft Access at least a little idle time.
The Jet data access objects (DAO) expose this caching mechanism (the 100 rows of data) in Microsoft Access 2.0 through two new recordset properties (CacheStart and CacheSize) and a new recordset method (FillCache). These apply only to dynasets (not snapshots or pass-through queries), and only when the dynaset contains at least some ODBC data. CacheStart and CacheSize indicate the beginning and length (in rows) of the local cache, while FillCache fills the cache with remote data, fetched in chunks rather than a single row at a time.
Performance implications
Snapshots and dynasets differ in several performance characteristics due to their different methods of retrieving and caching data. Several points are worth noting:
Improvements to client-server data access in Jet version 2
As noted previously, version 2 implements several improvements to enhance access to client-server data. Among these are:
BeginTrans
Set ds = d.CreateDynaset("select * from authors")
ds.Delete
ds.Close
CommitTrans/Rollback
BeginTrans
d.Execute ("UPDATE Accounts1 SET Balance = Balance + 10")
d.Execute ("UPDATE Accounts2 SET Balance = Balance - 10")
CommitTrans/Rollback
This allows development of true client-server transactional applications, and highly modular code.
Connections that have been timed out will automatically be reconnected when needed. This allows developers to write applications that leave datasheets and forms on the screen, without worrying about extensive consumption of server connections.
These two settings have defaults, in case MSysConf doesn't exist: 100 rows are fetched every 10 seconds of idle time. These settings allow a system administrator to trade server locking against network traffic, and not allow ordinary users to override these settings.
SELECT RemoteTable.*
FROM RemoteTable
WHERE RemoteColumn1 = UserDefinedFunc([QueryParameter1]) AND
RemoteColumn2 = IIF([QueryParameter2] = "foo", 1, 2)
to be sent completely to the server for processing. This is useful when the server table contains code but you wish to prompt the user for a string; the user-defined function would translate the user's string into the proper code value.
SELECT RemoteTable.*
FROM RemoteTable
WHERE RemoteColumn LIKE [QueryParameter]
to be sent completely to the server, even if the user types "*" and "?" wildcards.
The professional edition of Visual Basic 3.0 includes ODBC support and a variety of data-aware controls. Visual Basic developers using the data-aware controls are intrinsically bound to the Jet engine to access ODBC. The high-level controls that ship in Visual Basic 3.0 have no way of connecting directly to the ODBC API, but must pass through the Jet engine (see Option 1 of Figure 13). This provides the benefits of enabling distributed/heterogeneous joins, dynaset technology, and so on. It also introduces overhead to Visual Basic applications when remote access via ODBC is required.
Since Visual Basic is such a flexible tool, there are several options available when attempting to access remote databases:
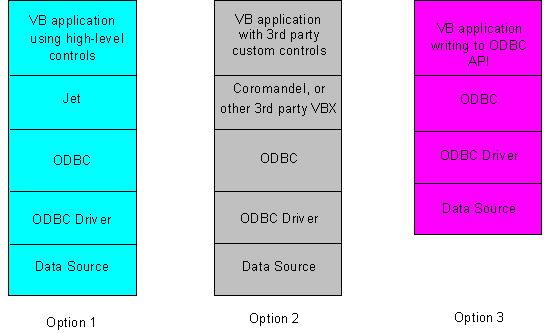
Figure 13. Data management options in Visual Basic 3.0
Visual Basic and Microsoft Access use Jet differently. One notable difference is that Microsoft Access uses Jet exclusively, whereas Visual Basic provides options such as use of Jet through data controls, use of third-party data controls, and direct access to ODBC. Another significant difference is the ability of Microsoft Access to process queries asynchronously. This is in contrast to Visual Basic, where all queries are synchronous.
Asynchronous query execution
Jet executes ODBC queries asynchronously if this is supported by the ODBC driver, the network software, and the server. This allows you to cancel a long-running query in Microsoft Access or to switch to another task in the Windows™ operating system while the query runs on the server. Jet asks the server if the query is finished every m milliseconds, where m is configurable (the default is 500 milliseconds).
When you cancel a query (or simply close a query before all results have been fetched), Jet calls the ODBC SQLCancel function, which discards any pending results and returns control to the user. However, some servers (or their network communication software) do not implement an efficient query-canceling mechanism, so you might still have to wait some time before regaining control.
Asynchronous processing might cause unpredictable results with some network libraries and some servers. These network libraries are often more robust when operating synchronously, owing chiefly to the added complexities of handling multiple asynchronous connections. Client applications are often written to operate fully synchronously, even if interactive; this is simpler to implement and test. You can force Jet to operate synchronously by setting DisableAsync to 1 in the MSACC20.INI file. Also notify your network/server vendor; an upgrade or patch might be available for these problems.
Jet will automatically cancel a long-running query after a configurable amount of time (the default is 60 seconds). If this happens, it does not necessarily mean that the server did not respond during that time or that you have become disconnected. It simply means the query did not return results in the time allotted. If you know a certain query will take a very long time to execute, increase the query's "ODBC Timeout" property. Each query can have its own timeout setting.
When designing a Microsoft Access application that will interact with remote databases, you need to consider potential performance obstacles
Designing with remote databases in mind
Elements of Microsoft Access applications that performed acceptably against local data may be too slow against a server, cause too much network traffic, or use excessive server resources. Examples include:
One key to a good performing ODBC application requires that the application exploit the capabilities of the database driver. In addition, the application should be aware of the capabilities and specifics of each data source. The Q+E Database Library 2 (QELIB) architecture was designed to address these issues. Figure 14 illustrates how QELIB provides data handling and driver leveling features to applications.
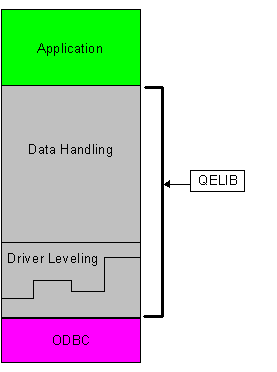
Figure 14. QELIB architecture
QELIB’s data handling capabilities provide the developer with the functions to manage the data access requirements. These include:
Two important issues in ODBC are data-source-specific attributes and ODBC driver compliance. To solve different ODBC driver variances, QELIB queries the capabilities of each driver and provides for missing functionality wherever possible. By using QELIB, applications are isolated from the problems that arise because of limited ODBC driver compliance, as shown in Figure 15.
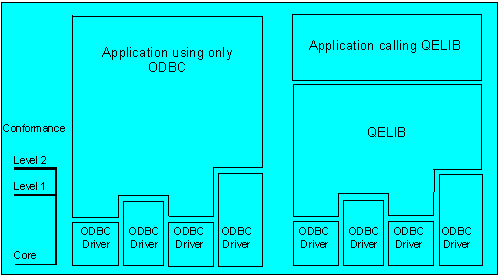
Figure 15. QELIB driver leveling
There is nothing in the Driver Manager that can be “tuned” by the application or driver writer. However, Microsoft has optimized the Driver Manager in two significant ways.
The Driver Manager for ODBC 2.0 does not unload driver DLLs until either the connection handle is dropped or a connection is made to a different driver on a given connection’s handle. This eliminates overhead where frequent connects/disconnects are performed through a given driver. This is in contrast to the Driver Manager for ODBC 1.0, which automatically unloaded driver DLLs on SQLDisconnect.
In the Driver Manager 2.0, the SQLGetFunctions function now uses an array in which to store a map of all driver-supported ODBC functions. This is in contrast to ODBC 1.0, where a call was required for each ODBC function. This was done by the use of a new symbolic constant, SQL_API_ALL_FUNCTIONS. When this argument is passed to SQLGetFunctions, pfExists (the third parameter of the function) is treated as a pointer to an array of 100 elements.
Taken from the ODBC 2.0 Programmer’s Reference, the following two examples show how an application uses SQLGetFunctions. The first example illustrates how the function was used in ODBC 1.0. The second illustrates the use of the array of support driver functions new to ODBC 2.0.
In the first example, SQLGetFunctions is used to determine if a driver supports SQLTables, SQLColumns, and SQLStatistics. If the driver does not support these functions, the application disconnects from the driver. SQLGetFunctions is called once for each function. This is the method that was used for ODBC 1.0.
UWORD TablesExists, ColumnsExists, StatisticsExists;
SQLGetFunctions(hdbc, SQL_API_SQLTABLES, &TablesExists);
SQLGetFunctions(hdbc, SQL_API_SQLCOLUMNS, &ColumnsExists);
SQLGetFunctions(hdbc, SQL_API_SQLSTATISTICS, &StatisticsExists);
if (TablesExists && ColumnsExists && StatisticsExists) {
/* Continue with application. */
}
SQLDisconnect(hdbc);
The next example calls SQLGetFunctions a single time and passes it an array in which SQLGetFunctions returns information about all ODBC functions.
UWORD fExists[100];
SQLGetFunctions(hdbc, SQL_API_ALL_FUNCTIONS, fExists);
if (fExists[SQL_API_SQLTABLES] &&
fExists[SQL_API_SQLCOLUMNS] &&
fExists[SQL_API_SQLSTATISTICS]) {
/* Continue with application. */
}
SQLDisconnect(hdbc);
Overall, the Driver Manager is written for performance by keeping overhead to a minimum. An analysis and benchmarking of the SQLFetch function sheds some light on the overhead associated with the Driver Manager:
Given that the blink of a human eye takes .01 seconds, SQLFetch can be called 10,000 times in the time it takes to blink.
Many things can be done in applications to enhance performance. In general, an application should use all of a given driver’s capabilities. This is done by querying the API and SQL conformance levels of the driver. To check the SQL conformance level, use the SQLGetInfo function with the SQL_ODBC_SQL_CONFORMANCE flag. To test the API conformance level, use the SQLGetFunctions function as described above. The following techniques will help reduce overhead, thereby resulting in enhanced performance:
#define NAME_LEN 30
#define BDAY_LEN 11
UCHAR szName[NAME_LEN], szBirthday[BDAY_LEN];
SWORD sAge;
SDWORD cbName, cbAge, cbBirthday;
retcode = SQLExecDirect(hstmt,
"SELECT NAME, AGE, BIRTHDAY FROM EMPLOYEE ORDER BY 3, 2, 1",
SQL_NTS);
if (retcode == SQL_SUCCESS) {
while (TRUE) {
retcode = SQLFetch(hstmt);
if (retcode == SQL_ERROR || retcode == SQL_SUCCESS_WITH_INFO) {
show_error();
}
if (retcode == SQL_SUCCESS || retcode == SQL_SUCCESS_WITH_INFO){
/* Get data for columns 1, 2, and 3. */
/* Print the row of data. */
SQLGetData(hstmt, 1, SQL_C_CHAR, szName, NAME_LEN, &cbName);
SQLGetData(hstmt, 2, SQL_C_SSHORT, &sAge, 0, &cbAge);
SQLGetData(hstmt, 3, SQL_C_CHAR, szBirthday, BDAY_LEN,
&cbBirthday);
fprintf(out, "%-*s %-2d %*s", NAME_LEN-1, szName, sAge,
BDAY_LEN-1, szBirthday);
} else {
break;
}
}
}
This sample demonstrates the use of SQLBindCol. Notice that it is called once for each column prior to the data fetching loop.
retcode = SQLExecDirect(hstmt,
"SELECT NAME, AGE, BIRTHDAY FROM EMPLOYEE ORDER BY 3, 2, 1",
SQL_NTS);
if (retcode == SQL_SUCCESS) {
/* Bind columns 1, 2, and 3. */
SQLBindCol(hstmt, 1, SQL_C_CHAR, szName, NAME_LEN, &cbName);
SQLBindCol(hstmt, 2, SQL_C_SSHORT, &sAge, 0, &cbAge);
SQLBindCol(hstmt, 3, SQL_C_CHAR, szBirthday, BDAY_LEN, &cbBirthday);
/* Fetch and print each row of data. On */
/* an error, display a message and exit. */
while (TRUE) {
retcode = SQLFetch(hstmt);
if (retcode == SQL_ERROR || retcode == SQL_SUCCESS_WITH_INFO) {
show_error();
}
if (retcode == SQL_SUCCESS || retcode == SQL_SUCCESS_WITH_INFO){
fprintf(out, "%-*s %-2d %*s", NAME_LEN-1, szName,
sAge, BDAY_LEN-1, szBirthday);
} else {
break;
}
}
}
It is easy to write ODBC drivers. Conversely, it is time consuming to write highly optimized drivers. However, there are cases where a non-optimized driver is more than adequate for a particular need. When writing drivers, a general principle is that the driver should make use of all the underlying capabilities of the data source.
Performance tuning a single-tier driver involves three basic techniques. First, make the file I/O as fast and efficient as possible. Second, have a good sort engine. Third, have a good query optimizer.
PageAhead Software Corporation, developers of the Simba ODBC driver tools, provides some insight into the importance of query optimizers in the following excerpt taken from the PageAhead white paper “Introduction to ODBC Driver Development”:
“SQL statements describe the operation to be performed, not how to perform the operation. Effective optimization of a query is crucial. Optimized queries that take seconds or minutes to perform can take hours if left unoptimized. Optimization is more of an art than a science. Cost-based optimization is used in many client-server SQL implementations and is the method discussed here. Essentially, the query planner/optimizer will analyze the query tree created by the parser and will attempt to determine an optimal method of execution. A number of methods are used to do this, including:
A good query planner/optimizer can yield an order of magnitude performance improvements relative to non-optimized access plans. The product of this phase is a detailed list of execution steps, described at the record and index level, that can be executed by a record-oriented process.”
Several points can be made about enhancing performance of multiple-tier drivers. When writing multiple-tier drivers, you need to decide who should be doing the work, the client or the server. What makes sense in your particular situation or market? Consider the following as you write your driver:
SELECT *
FROM table
WHERE column = Date()
If ODBC could not use the canonical syntax for Date, and table referred to a SQL Server table, all records would be pulled back from the server. The Date function would then run locally to find the matching records. Using the canonical function, a query is sent to the SQL Server driver, which translates the canonical into SQL Server syntax. SQL Server processes the request and returns the proper records. No local processing is involved.
ODBC provides a means of accessing data in a heterogeneous environment of relational and nonrelational database management systems. It can do so in an efficient, high-performance manner. However, attaining this performance requires an understanding of the tools that are being used to access the data. Are the tools actually using ODBC? If they are using ODBC, are they doing so in an efficient way? Does the architecture of the tool enhance performance or become and obstacle to it? Should you even be using ODBC? These are just a few of the questions that you need to address when you implement your ODBC projects. As with any client-server application, the application needs to be tuned with the knowledge of the underlying tools, the database, and the user requirements.