Desktop and Business Systems Division
Microsoft Corporation
April 1996
Introduction
Scalability
Scalable Hardware Architectures
Scalable Software and Applications Architectures
Microsoft SQL Server Scalability on SMP Hardware Systems
Clusters: Horizontal Growth
Microsoft SQL Server and Windows NT Server Manageability
Examples of Scalable SMP Applications
Summary
The Microsoft® SQL Server and BackOffice™ products running on Windows NT® Server have evolved to support huge databases and applications. This paper outlines the history and current power of Microsoft SQL Server, showing that it scales down to small 1-megabyte (MB) personal databases and scales up to giant 100-gigabyte (GB) databases used by thousands of people. SQL Server achieves this scalability today by supporting symmetric multiprocessing (SMP). In the future, Microsoft SQL Server will scale out by partitioning a huge database into a cluster of servers, each storing part of the whole database, and each doing a part of the work. This clustering approach dovetails with the Windows NT Server cluster architecture. Today, Windows NT Server and Microsoft SQL Server clusters provide high availability—but we are still in the early stages of this product evolution. Microsoft intends to extend its cluster architecture to accommodate modular growth, as well as to automate configuration, maintenance, and programming.
Today, downsizing computer systems to client/server computing is a common phenomenon. Yet many successful companies face the opposite problem: they are upsizing their client/server applications. With every Internet and intranet user a potential client, applications face huge user and transaction loads. With the price of disk storage at $100/GB, application systems are encouraged to store huge online databases.
Scalable systems solve the upsizing problem by giving the designer a way to grow the network, servers, database, and applications by just adding more hardware. Scalable computer systems can grow an application's client base, data base, and throughput without application reprogramming. The scaled-up server should be as easy to manage as the smaller system—at least on a per-user basis.
Traditionally, most scale-up has been done thorough symmetric multiprocessing (SMP): adding more processors, memory, disks, and network cards to a single server. Several vendors have shown that SMP servers can offer a ten fold scale-up over uniprocessor systems on commercial workloads.
However, at some point a single node hits a bottleneck. This results in diminishing returns or a need for prohibitively expensive hardware. To grow much beyond a factor of 10, application designers have gravitated to a cluster architecture in which the workload and database are partitioned among an array of networks, processors, memories, and database systems. All the truly large systems are built this way. The IBM MVS Sysplex, the Digital Equipment Corporation (DEC) VMScluster, the Teradata DBC 1024, and the Tandem Himalaya series are all clustered systems. Ideally, this partitioning is transparent to the clients and to the application. The cluster is programmed and managed as a single system, but it is in fact an array of nodes.
Cluster technology dovetails with and leverages distributed system technologies such as replication, remote procedure call, distributed systems management, distributed security, and distributed transactions. The cluster approach has two advantages over increasingly larger SMP systems: (1) clusters can be built from commodity components and can grow in small increments, and (2) the relative independence of cluster nodes allows a natural fail-over and high availability design.
Microsoft® Windows NT® Server and Microsoft SQL Server support both SMP and cluster architectures. SQL Server delivers impressive peak performance for both client-server and data warehouse applications. Microsoft SQL Server and Microsoft Windows NT Server run on two-way to 32-way SMP hardware systems, although the most common SMP hardware systems are two-way and four-way. Microsoft SQL Server has demonstrated excellent SMP scalability, both on audited benchmarks and in real applications.
Today, a single four-processor node can support up to 5,000 concurrent users accessing a Microsoft SQL Server, storing billions of records on a 200-GB disk array (Table 1). These servers are capable of processing more than 10 million business transactions per day. The combination of faster processors, more processors, and software improvements could more than double the rated performance of Microsoft SQL Server on SMP hardware systems. Microsoft plans to publish audited benchmarks in 1996 that demonstrate Microsoft SQL Server scalability to eight-processor SMP hardware systems. Larger SMP hardware systems will be supported as the technology matures.
Table 1. Microsoft SQL Server Scalability Today (April 1996)
| Technologies | Active Users | Throughput | DB Size |
| SMP, fail-over, parallel query, distributed transactions, SQL Enterprise Manager | 5,000 per SMP | 3,600 transactions per minute (tpm) 10 million transactions per day (tpd) |
200 GB |
Microsoft plans to evolve Windows NT Server to support large processor and disk clusters. These plans are outlined in the paper "Microsoft Windows NT Server Cluster Strategy," in the MSDN Library. Today, Windows NT Server offers many clusterwide services, including: security, naming, performance monitor, software asset management (Systems Management Server), transactions (Distributed Transaction Coordinator), distributed objects (Distributed Component Object Model), node and resource fail-over, and automatic Internet Protocol (IP) address assignment (Dynamic Host Interface Protocol). Companies such as Compaq, Digital Equipment Corporation, Hewlett-Packard, Intel, NCR, Tandem, and SGI are building on Windows NT Server and are working with Microsoft to make Windows NT Server clusters even more powerful. Many additional services are planned, including an industry standard cluster application programming interface.
Microsoft SQL Server version 6.5 clustering and fail-over
Microsoft SQL Server is an early user of clusters for fail-over support. Microsoft SQL Server 6.5, in cooperation with various hardware vendors, supports high-availability databases via fail-over from one node to another. Microsoft SQL Server also adds support for OLE Transactions through the Microsoft Distributed Transaction Coordinator (MS DTC). OLE Transactions allow Microsoft SQL Server databases to be partitioned among multiple Windows NT Servers. MS DTC automatically manages the work of transactions that span these nodes. In addition, the Microsoft SQL Enterprise Manager allows an operator to monitor and manage multiple SQL Servers from a single console.
Goals for the future
Fail-over and OLE Transactions are the most recent steps toward Microsoft's vision of superservers built from clusters of Windows NT Servers. Windows NT Server clusters will provide modular growth, allowing customers to buy only what they need and to grow the system by adding processing, storage, and network modules to the server as demand rises. Microsoft aims to make it easy to build and manage these superservers—indeed, we want to bring the ease of plug-and-play to enterprise clusters. We hope to automate much of the work of configuring and managing a cluster. The clusters will offer high-availability services by automatically reconfiguring to mask system failures.
As seen in Table 2, Microsoft's goal for 1998 is to support 16-node Windows NT Server clusters, where each node is a four-way SMP with one hundred discs (800 GB). In 1998, Microsoft SQL Server will offer transparent access to data partitioned in this cluster. This 16-node cluster is potentially a 10-terabyte database. Such a system should be big enough for most application problems. Whether current price trends continue, in 1998 such a cluster could be built from commodity components for about 1 million dollars.
Table 2. Microsoft SQL Server Scalability Goals
| By year end | Technologies | Active Users | Throughput | DB Size |
| 1996 | SMP, fail-over, parallel input/output (I/O), distributed transactions, SQL Enterprise Manager | 5,000–7,000 per SMP | 5,000–7,000 tpm 5 M tpd |
500 GB–1 terabyte |
| 1997 | SMP, fail-over Distributed Server management |
10,000 per SMP | 10,000 tpm | 1–5 terabytes |
| 1998 | 16-node clusters of N-way SMP machines Transparent partitioning Parallel query 64-bit support |
15,000 per SMP with clusters, up to 200,000 | 18,000 tpm | 10 terabytes/cluster |
Once the clustering and transparent partitioning are in place, Microsoft SQL Server will implement automatic parallel access to the database.
As organizations grow and acquire more and more data, they must deal with increased transaction workloads and larger databases. Each major increment presents new challenges.
Scalability covers several kinds of growth, including:
An ideal system improves linearly: that is, whether you double the number of processors and disks, throughput doubles (linear scale-up) or response time is cut in half (linear speed-up). Linear scaling is rarely achieved in practice because it requires that all aspects of the system be perfectly scalable. The overall architecture includes hardware, operating system, database, network software, and the application software.
It is tempting to simplify scalability to a single metric such as the number of processors a system can support. It may seem obvious but many database applications are very I/O-intensive; adding central processing units (CPUs) to an I/O-bound system will not make it faster. Microsoft SQL Server running on today's typical four-processor servers can achieve performance comparable with systems running on hardware with 20 processors! Is the second system more scalable because it requires 20 CPUs to achieve the same throughput? Obviously not. Table 3 shows some benchmarks using many processors. It shows that a four-processor Compaq running Windows NT Server and Microsoft SQL Server outperforms many eight-processor and some 20-processor systems.
Table 3. Windows NT Server and Microsoft SQL Server vs. SMP UNIX Solutions on the TPC-C Benchmark
| Database | Hardware | CPUs | tpmC | $/tpmC | System Cost |
| Microsoft SQL Server 6.5 | Compaq Proliant 4500/133 | 4 | 3643 | $148 | $537,508 |
| DB2 for Solaris V2 | Sun SPARCServer1000E | 8 | 3256 | $199 | $646,820 |
| Informix Online 7.1 | Sun SPARCCenter 2000E | 20 | 3534 | $495 | $1,751,004 |
| Oracle 7.3 | IBM RS6000 / j30 | 8 | 3631 | $ 289 | $1,049,656 |
The best metric is how well the system scales for your application. That is impossible to know in advance. But, you can estimate scalability by examining standard benchmarks and by looking at applications in related industries.
Performance is only a small part of the cost of ownership. System management and operation is often more expensive than the hardware and software. Larger systems can be difficult to design, program, administer, and operate. The following issues are important for small systems, but they become very important when the systems scale up.
Customer experience, magazine reviews, and independent studies have all shown that Windows NT Server and Microsoft SQL Server can dramatically help reduce support and management costs when compared with non-Microsoft systems.
Technology advances and the wide adoption of computing have had some surprising results. Today, commodity components are the fastest and most reliable computers, networks, and storage devices. The intense competition among microprocessor vendors has created incredibly fast processing chips. Indeed, the most powerful supercomputers are built from such chips. Conventional water-cooled mainframes are moving to this higher-speed technology.
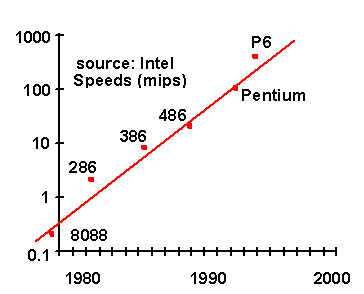
Commodity workstations and servers rival and often outstrip the performance of mainframes. The pace of change in this commodity market is so rapid that the "low end" is years ahead of the installed base of conventional mainframe and minicomputer architectures. Figure 1 shows the astonishing increase in microprocessor speed over time.
Figure 1. Intel microprocessor speed vs. time
Commodity computer interconnects are also making extraordinary progress. Ethernet has graduated to 100 megabits per second (Mbps). Switched 100 Mbps Ethernet gives a hundred fold speed-up in local networks at commodity prices. Asynchronous Transfer Mode (ATM) hardware will soon be ubiquitous for both local and wide area networks. ATM offers a tenfold increase over switched Ethernet.
The entire computer industry uses the same basic 16-MB dynamic RAM (DRAM) chips that go into PCs. Memory prices for commodity machines are often three to ten times less than the price of the same memory for a proprietary machine.
The highest performance and most reliable disks are 3.5" small computer system interface (SCSI) discs. They have doubled in capacity every year and are rated at a 50-year mean time to hardware failure. Today, the 4-gigabyte disk is standard. Next year, it will be replaced by the 8-gigabyte drive for approximately the same price. Figure 2 shows that in 1995 one thousand dollars bought 4 GB of disks. This is a thousandfold improvement over the disks of 15 years ago. These low prices explain why typical servers are configured with 10 GB to 100 GB of disk capacity today. Such disks cost $2,000 to $20,000.
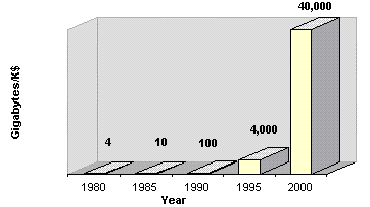
Figure 2. Megabytes per $1000 vs. time
The proliferation of many processors, disks, and networks poses an architectural challenge. What hardware architecture best exploits these commodity components? No single architecture has emerged as a winner, but there is broad agreement that three generic architectures can provide scalability: shared memory, shared disk, and shared nothing. Windows NT Server supports all these architectures and will evolve in parallel as these architectures evolve.
SMP grows a server by adding multiple processors to a single shared memory. The system grows by adding memory, disks, network interfaces, and processors. SMP is the most popular way to scale beyond a single processor. The SMP software model, often called the shared memory model, runs a single copy of the operating system with application processes running as if they were on a single processor system. Microsoft Windows NT Server and Microsoft SQL Server are designed to scale well on SMP systems. They can scale to 32 nodes for some applications, but the practical limits for general purpose use today are:
These are the maximum sizes we have seen. Typical large servers are half this size or less. With time, Microsoft SQL Server, Windows NT Server, and hardware technology will improve to support even larger configurations.
SMP systems are relatively easy to program. They also leverage the benefits of industry standard software and hardware components.
Today, SMP is by far the most popular parallel hardware architecture. SMP servers based on industry-standard Intel and Alpha AXP microprocessors deliver astonishing performance and price/performance for database platforms. Intel markets a four-way SMP board based on the Pentium Pro (P6) processor. This SMP board is being incorporated in servers from almost every hardware vendor. It appears that the 4xP6 SMP servers will be the workhorse of client-server computing for the next few years.
As microprocessor speeds increase, SMP systems become increasingly expensive to build. Today, there are modest price steps as a customer needs to scale from one processor to four processors. Going from four to eight processors in an SMP is comparatively expensive. Beyond eight processors, prices rise very steeply and the returns diminish.
For example, as can be seen in Table 4, Compaq can deliver astonishing performance on a standard, widely available four-processor SMP machine. It is designed using commodity hardware and delivers very cost effective database support. A 16-processor machine, designed around that same 133-MHz Pentium chip, delivers only 50 percent more performance, at over four times the cost.
Table 4. Diminishing Returns on SMP Performance
| Database | Hardware | CPUs | tpmC | $/tpmC | System Cost |
| Microsoft SQL Server 6.5 | Compaq Proliant 4500/133 | 4 Pentium 133 MHz | 3643 | $148 | $537,508 |
| Oracle 7 v 7.3.2 | NCR WorldMark 5100S c/s | 16 Pentium 133 MHz | 5607 | $394 | $2,206,688 |
At the software level, multiple processors concurrently accessing shared resources must be serialized. This serialization limits the practical scalability for individual applications in shared memory SMP systems. These software bottlenecks in operating systems, database systems, and applications are as significant as the hardware limitations.
Nonetheless, SMP systems are the most common form of scalability. They will be the dominant form of server for many years to come. The appearance of Intel Pentium Pro, DEC Alpha, IBM PowerPC, and SGI MIPS SMP hardware systems gives very powerful and inexpensive SMP nodes.
Microsoft provides excellent support for these commodity SMP hardware systems today and continues to invest in this technology.
A cluster is a set of loosely coupled, independent computer systems that behave as a single system. The nodes of a cluster may be single-processor systems, or they can be SMP hardware systems. The nodes may be connected by a commodity network or by a proprietary very highspeed communications bus. The computers in a cluster cooperate so that clients see the cluster as if it were a single very high performance, highly reliable server. Because the cluster is modular, it can be scaled incrementally and at low cost by adding servers, disks, and networking.
Windows NT Server clusters provide horizontal growth, or scale-out, allowing customers to add processing, storage, and network services to a pre-existing configuration. Figure 3 shows the growth from a one-node cluster to a six-node cluster by adding one node at a time. A cluster can also be grown using superserver SMP nodes, but usually it is built with commodity components and commodity interconnects. Two interconnects are used for fault tolerance.
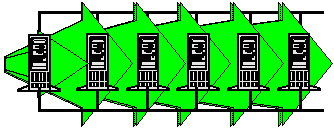
Figure 3. Cluster growth, one node at a time
Cluster architectures allow you to scale up to problems larger than a single SMP node. Microsoft believes that the cluster is the most economical way to achieve scalability beyond eight processors. When demand exceeds the ability of commodity SMP nodes, or when fault tolerance demands a second fail-over server, it is very attractive to use multiple nodes to form a cluster.
Figure 4 shows the two basic software models for clusters: shared-disk and shared-nothing. In a shared-disk cluster, all processors have direct access to all disks (and data), but they do not share main memory. An extra layer of software, called a distributed cache or lock manager, is required to globally manage cache concurrency among processors. The Digital VMS cluster and the Oracle Parallel Query Option are the most common examples of a shared-disk parallel database architecture. Since access to data is serialized by the lock or cache manager, the shared-disk cluster has some of the same scalability limitations as shared-memory SMP systems.

Figure 4. Shared-disk and shared-nothing clusters
The shared-nothing cluster architecture avoids the exotic interconnects and packaging of a scalable shared-disk cluster by connecting each disk to one or two servers. In a shared-nothing cluster, each node has its own memory and disk storage. Nodes communicate with one another by exchanging messages across a shared interconnect. Each node in a shared-nothing cluster is a freestanding computer, with its own resources and operating system. Each node is a unit of service and availability. Each node owns and provides services for some disks, tapes, network links, database partitions or other resources. In case of node failure, the disks of one node may fail over to an adjacent node—but at any instant, only one node is accessing the disks.
Proprietary shared-nothing cluster solutions have been available for several years from Tandem, Teradata, and IBM Sysplex. These solutions all depend on exotic hardware and software, and therefore are expensive.
Microsoft SQL Server and Windows NT Server clusters will bring scalability and fault tolerance to the commodity marketplace. Microsoft is building clustering technology directly into the Windows NT Server operating system. This technology will work well with commodity servers and interconnects, and it will be able to leverage special hardware accelerators from vendors such as Compaq, Digital, and Tandem. Microsoft BackOffice products, such as Microsoft SQL Server, Internet Information Server, and Exchange, will be enhanced to take advantage of this clustering support. Many third-party products are also being ported to this architecture. Later, this whitepaper discusses Microsoft's strategy to support clustering in both Windows NT Server and Microsoft SQL Server.
Software and applications running on an SMP or a cluster must use parallelism to benefit from the many disks and processors that these scalable architectures provide. Figure 5 depicts the two generic kinds of parallelism.
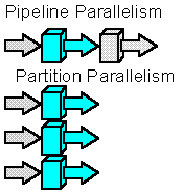
Figure 5. Pipeline and partition parallelism
Pipeline parallelism breaks a big task into a sequence of steps. Each step of the sequence is done in parallel. The result of one step is passed to the next step. An industrial assembly line is a good example of pipeline parallelism.
Partition parallelism breaks a big task into many little independent tasks that can be done in parallel. Having multiple harvesters collect grain from several fields is a typical example of partition parallelism.
Microsoft SQL Server provides a good example of both partition and pipeline parallelism when reading disks. By striping data across many disks, each disk can deliver a part of a large data read—this is partition parallelism. Microsoft SQL Server exploits three-deep pipeline parallelism by having one task issue pre-fetch reads to the disks, while another Microsoft SQL Server task processes the data and passes it back to the application task.
Windows NT Server was designed for SMP hardware systems. Windows NT Server is a fully threaded operating system that provides a rich set of synchronization primitives. The shrink-wrapped version of Windows NT Server is enabled for four-way SMP. Larger SMP hardware systems are not yet a commodity product, so the operating system is generally packaged with the hardware. Companies such as Digital, Intergraph, NCR, Sequent, and SGI, who build 8-way and 32-way Windows NT Server multiprocessors, modify Windows NT Server for their hardware and ship it with the hardware package.
Windows NT Server also has built-in disk partitioning. It allows logical volumes to be spread across multiple physical volumes. Each logical volume can be a redundant array of inexpensive disks (RAID) or it can be an individual disk. Windows NT Server has software support for RAID 0 (striping a logical volume across multiple physical volumes), RAID 1 (disk mirroring or shadowing in which data is replicated on multiple disks), and RAID 5 (a fault-tolerant storage strategy in which disks are organized so that one stores parity for data on the others). RAID 5 is more space efficient than RAID 1. This software support lets Windows NT Server customers build reliable storage with commodity controllers and disks. RAID also offers partition parallelism because it spreads the data among multiple disks that can be read in parallel.
Windows NT Server can read individual commodity SCSI disks at their rated speed of 8 MB/second and can drive SCSI controllers at speeds of 18 MB/second. By using a Peripheral Component Interconnect–based (PCI-based) machine and by striping data across four SCSI controllers, a single-commodity Pentium processor running Windows NT Server has been clocked reading a disk array at 60 MB/s. This means that a single Pentium processor can read or write data at 200 gigabytes per hour. These rates are important for data intensive operations such as data loading, backup, data indexing, and data mining.
These are impressive numbers for any computer, but they are especially impressive when using commodity single-processor systems. By using multiple processors and multiple PCI busses, SMP systems can read and write data at even higher speeds and still have power left over to analyze and process the data.
Microsoft SQL Server is designed to make full use of the Windows NT SMP capabilities: threads and the Windows NT Server scheduler. Each Windows NT Server node typically has a single Microsoft SQL Server address space managing all the SQL databases at that node. SQL Server runs as a main address space with several pools of threads. Some threads are dedicated to housekeeping tasks such as logging, buffer pool management, servicing operations requests, and monitoring the system. A second larger pool of threads performs user requests. These threads execute stored procedures or SQL statements requested by the clients.
Microsoft SQL Server is typically used in a client/server environment where clients on other machines attach to the server and either issue SQL requests, or more typically, issue stored procedures usually written in the Transact-SQL language. Clients may also be co-located at the server node. Microsoft SQL Server uses a built-in transaction processing (TP) monitor facility, Open Data Services, to support large numbers of clients. In practice, this has scaled to 5,000 concurrent clients. Beyond that size, it makes sense to either partition the application into a cluster of nodes or use a TP monitor to connect clients to SQL Server. All common TP monitors, such as IBM CICS, Transarc Encina, Novell Tuxedo, and Top End from AT&T Global Information Solutions, have been ported to Windows NT Server and interface with Microsoft SQL Server.
Microsoft SQL Server has devoted considerable effort to achieving near-linear speed-up on SMP machines. Many benchmarks have demonstrated this. Two notable examples are the DEC Alpha TPC-C Benchmark and the Intergraph benchmark.
There is no universally accepted way to measure scalability. However, useful information can be gained from Transaction Processing Performance Council (TPC) benchmarks. The TPC is a nonprofit organization that defines industry standard transaction processing and database benchmarks. Members of the council today include all major database vendors and suppliers of server hardware systems. They have defined a series of benchmarks: TPC-A, TPC-B, TPC-C, and TPC-D.
TPC-C is the current industry standard benchmark for measuring the performance and scalability of online transaction processing (OLTP) systems. It exercises a broad cross section of database functionality including inquiry, update, and queued mini-batch transactions. The specification is strict in critical areas such as database transparency and transaction isolation. Many consider TPC-C to be a good indicator of real-world OLTP system performance. The benchmark results are audited by independent auditors and a full disclosure report is filed with the TPC. These reports are a gold mine of information about how easy it is to use the various systems and how much the systems cost.
Several vendors have reported scale-up results that demonstrate scalability from one CPU to a multiple-CPU SMP. Figure 6 shows the reported SMP scalability data as of March 1, 1996. At present, IBM DB2, ORACLE, and SYBASE have not reported scale-up numbers that give a series from one CPU up to multiple-CPU SMP hardware systems. Only Informix and Microsoft SQL Server have reported such results. The chart shows two interesting things. First, the DEC Alpha and Microsoft SQL Server absolute performance on small SMP hardware systems is excellent. Indeed, a three-processor DEC Alpha has twice the throughput of a six-processor NEC MIPS platform. Microsoft SQL Server also has more throughput than Informix running on an eight-processor 166-MHz PowerPC from Bull. One must go to an eight-processor 200-MHz SNI MIPS system running Informix to beat the three-processor DEC Alpha number in these scale-up measurements. It also shows that a three-processor DEC Alpha running Microsoft SQL Server 6.5 and Windows NT Server version 3.51 gives 92 percent scalability (that is, three processors give 2.76 times the single-processor throughput). The SNI/Informix scale-up gives less than 55 percent at eight processors and less than 45 percent at 16 processors. These audited results clearly show that Microsoft SQL Server 6.5 and Windows NT Server 3.51 deliver excellent SMP scalability for up to four nodes.
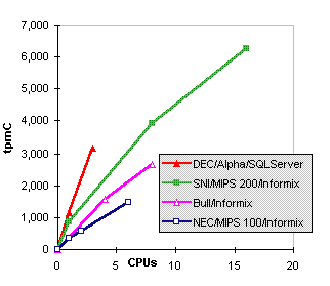
Figure 6. TPC-C throughput vs. number of CPUs
In laboratory tests, Intergraph Corporation demonstrated the scalability of Microsoft SQL Server 6.0 running on Intergraph's high-end InterServe Multiprocessor 6 (ISMP6) server (six 100-MHz Pentium processors with 1-MB secondary caches). Compared to Microsoft SQL Server 4.21a, SQL Server 6.0 achieved greater than 80 percent scalability on the debit/credit transaction processing benchmark (Figure 7).
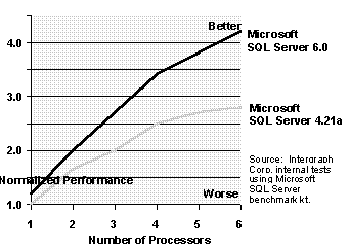
Figure 7. Scalability: Microsoft SQL Server 6.0 vs. Microsoft SQL Server 4.21a
The Intergraph study concludes that "Microsoft SQL Server 6.0 gained much more performance from the additional processors than Microsoft SQL Server 4.21a, even though both were running the same benchmark, on the same hardware, and on the same operating system. The differences are especially noticeable as the number of processors increases over four, since the effect is geometric. This result supports Microsoft's claim that vendors must optimize their applications to take full advantage of the underlying operating system. Obviously, the application has a considerable affect on scalability, and Microsoft SQL Server 6.0 on Windows NT Server 3.51 scales well beyond 4 processors." Microsoft SQL Server 6.0 was the 1995 release. It has been replaced by Microsoft SQL Server 6.5 running on Windows NT Server 4.0. As the newest TPC-C results show, both Microsoft SQL Server 6.5 and Windows NT Server 4.0 have even better SMP scalability.
Figure 8 gives a sense of how much Microsoft SQL Server and Windows NT Server have improved over the last three years on commodity processors. It shows that on the debit/credit benchmark throughput increased from 94 ticks per second (tps) to over 1,400 tps on a single processor—this represents a 120 percent annual growth rate for each of the last three years. In part, this 15-fold improvement comes from hardware advances: the processor speed-ups, larger memory, and improved disks. A major component of these improvements came from Microsoft SQL Server and Windows NT Server. New SMP and database algorithms in Windows NT Server and Microsoft SQL Server exploit these hardware advances. The result is a huge improvement in just three years. We expect these software and hardware improvements to continue for several more years.
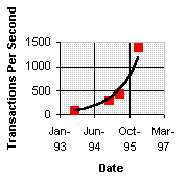
Figure 8. Debit/Credit throughput of Microsoft SQL Server and Windows NT
A single Microsoft SQL Server and Windows NT Server can support thousands of users accessing a database containing billions of records. Such systems are capable of supporting a user community exceeding 20,000 or a much larger community of Internet users who are occasionally connected to the server. Just to give a sense of scale, the largest banks have less than 10,000 tellers and the largest telemarketing organizations have less than 10,000 active agents. So, in theory, these systems could support the traditional front office of huge corporations.
Every SMP system has a maximum size: a maximum number of nodes, memory, disks, and network interfaces that can be attached to the system. To go beyond these limits, the software architecture must support a cluster or network of computers cooperating to perform the common task.
All the largest computer systems are structured as clusters. The largest known database, the Wal-mart system, runs on a NCR/Teradata cluster of 500 Intel processors accessing approximately 1,500 disks. Other large databases are supported by IBM MVS/Sysplex systems, Tandem Himalaya systems, or Digital VMScluster systems.
Clusters work by partitioning the database and application among several different nodes (computers). Each node stores a part of the database and each performs a part of the workload. The cluster grows by adding nodes and redistributing the storage and work to the new nodes. This growth and redistribution should be automatic and require no changes to application programs.
Partitioned data is used in centralized systems to scale-up capacity or bandwidth. When one disk is too small for a database, the database system partitions it over many disks. This same technique is used if traffic on a file or database exceeds the capacity of one disk. This partitioning is transparent to the application. The application accesses all data on all the disks as though it were on a single disk. Similarly, clients are partitioned among networks to scale up network bandwidth. Clusters generalize this partitioning to spread the computation among cluster nodes. The key challenge is to make this partitioning transparent to the customer so that a cluster is as easy to manage and program as a single system.
Clusters have several advantages. The most obvious is that they can grow to huge sizes. By building clusters from SMP nodes, one can scale up an application by a factor of ten or a hundred. Indeed, Digital, Tandem, and Teradata have many 100-node clusters in production today.
Clusters can be built with high-volume components that are relatively inexpensive. Relatively few high-end SMP machines are sold—relatively few customers will buy a 20-way SMP. So, 20-way SMP hardware systems are expensive because the engineering cost is amortized over relatively few units. Inexpensive clusters can be built with commodity four-way SMP hardware systems. This means they have superior price/performance. In addition, because they are built from commodity components, commodity clusters can grow in smaller increments. You can add disks or nodes or network cards as needed rather than having to buy a huge new box each time you grow.
By partitioning data and work, clusters provide firewalls that limit the scope of failures. When a node fails, the other cluster nodes continue to deliver service. By replicating data or by allowing storage and network devices to fail over to surviving nodes, the cluster can provide uninterrupted service.
In summary, clusters have substantial advantages. Microsoft believes that commodity SMP hardware systems will be the building blocks for clusters. Availability, scalability, and economics will demand that large systems be built as arrays of these commodity components. SMP hardware systems will provide vertical growth of nodes from single-processor systems to large SMP hardware systems. Clusters will provide horizontal growth by combining these SMP hardware systems into Windows NT Server clusters.
Distributed systems techniques are the key to building transparency into clusters. By structuring applications and systems as modules that interact via remote procedure calls, applications become more modular, and they can be distributed among nodes of the cluster. The client calls upon a service by name. The procedure call either invokes the service locally or uses a remote procedure call if the service is remote.
Microsoft has invested heavily in structuring its software as components that interact via remote procedure calls. The resulting infrastructure is variously called OLE, component object model (COM), and distributed COM (DCOM). Many aspects of COM are in place today and more are coming soon. In particular, with Windows NT Server 4.0 and Microsoft SQL Server 6.5, Microsoft is delivering the following:
Windows NT Server already supports these features along with many other cluster facilities, including cluster security (domains), cluster software management (SMS), cluster naming (Distributed Name Service), and cluster performance monitor (Perfmon). Microsoft SQL Server complements these facilities with management tools built into the Microsoft SQL Server Enterprise Manager that allow it to manage and monitor an array of Microsoft SQL Servers.
In 1997, Windows NT Server and SQL Server will extend many of these interfaces and will incorporate facilities to manage and balance application servers across a cluster of 16 nodes. The cluster will have a common console and a simple management model for all the components. Microsoft's goal for Windows NT Server and Microsoft SQL Server is to make the cluster as easy to manage and use as a single large system. Clusters will have the added benefit of fault tolerance, masking many system faults and providing highly available services.
Microsoft SQL Server 6.5 offers fault tolerance and high availability by providing fail-over from one server to another when the first server fails or needs to be taken out of service for maintenance (Figure 9). The fail-over mechanism works as follows: Two Windows NT Server servers can be configured as dual servers. The pair must have shared access to a SQL Server database stored on shared disks. One of the Microsoft SQL Servers is the primary server. It accepts requests from clients and both reads and writes the database. The other (fail-over) Microsoft SQL Server node may be providing access to other databases, but it is not accessing the database being managed by the primary. If the primary Microsoft SQL Server node fails, the Windows NT Server at the fail-over node takes ownership of the disks holding the database. It then informs the fail-over Microsoft SQL Server that it is now primary. The fail-over SQL Server recovers the database and begins accepting client connections. For their part, clients reconnect to the backup server when the primary server fails.
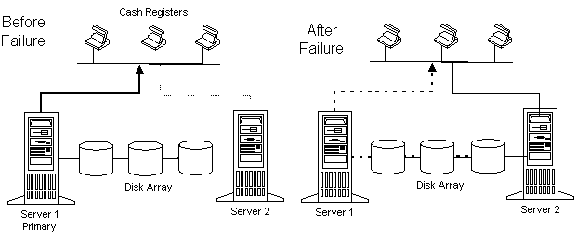
Figure 9. Fail-over with Microsoft SQL Server 6.5
The dual-server fail-over is completely automatic. The whole process of detecting and recovering from failure takes only a few minutes. When the primary is repaired, it is restarted and it becomes the new backup server. If desired, the Microsoft SQL Server can fall back to the original server when it is repaired.
Microsoft SQL Server and Windows NT Server provide fail-over by using specialized disk hardware today. This solution will be generalized to use commodity hardware in 1997.
Data replication helps configure and manage partitioned applications. Many applications naturally partition into disjointed sections. For example, hotel, retail, and warehouse systems have strong geographic locality. The applications and databases can be broken into servers for geographic areas. Similarly, customer-care and telemarketing applications often have this strong partitioning. Nonetheless, all these applications need some shared global data. They also need periodic reporting and disaster recovery via electronic vaulting.
Data replication helps solve these problems by automatically propagating changes from one database to another. The replication can propagate changes to a Microsoft SQL Server system at a remote site for disaster recovery. Then, in case the primary site fails, the backup site can recover and offer service.
The same mechanism can be used to allow one site to act as a data warehouse for data capture OLTP systems. The data warehouse, in turn, may publish its data to many data marts that provide decision support data to analysts. Some applications dispense with the data warehouse and have the operational systems publish updates directly to the data marts.
The Microsoft SQL Server data replication system is both powerful and simple to use. A graphical user interface in SQL Enterprise Manager allows the administrator to tell operational databases to publish their updates and allows other nodes to subscribe to these updates. This publish-distribute-subscribe metaphor allows one-to-one and one-to-many publication. By cascading distributors, the replication mechanism can be scaled to huge numbers of subscribers. Replication is in transaction units, so each subscriber sees a point-in-time consistent view of the database.
Microsoft SQL Server applications routinely publish tens of megabytes of updates per hour. Publication can be immediate, periodic, or on demand. Replication is fully automatic and very easy to administer.
Microsoft SQL Server has always allowed customers to partition their database and applications among SQL servers running on several nodes. Clients connect to an application at one of the servers. If a client's request needs to access data at another node, the application can either access the data through Transact SQL or make a remote procedure call to the Microsoft SQL Server at the other node.
For example, each warehouse of a distributed application might store all the local orders, invoices, and inventory. When an item is backordered or when a new shipment arrives from the factory, the local system has to perform transactions that involve both the warehouse and the factory SQL servers. In this case, the application running on an Microsoft SQL Server at the warehouse can access the factory data directly or it can invoke a stored procedure at the factory Microsoft SQL Server. OLE Transactions and Microsoft SQL Server will automatically manage the data integrity between the factory and the warehouse.
Once data and applications are partitioned among multiple Microsoft SQL Servers in a cluster, there needs to be a convenient and high-performance way to move data among these servers. Data pipes make it easy to ship data between servers by capturing result sets returned by remote procedure calls directly in node-local tables. This approach can be used by many applications as an alternative to distributed query.
Prior to Windows NT Server 4.0, partitioned Microsoft SQL Server applications had to explicitly manage distributed transactions by calling the Microsoft SQL Server prepare and commit verbs of the two-phase commit protocol. With the new OLE Transactions, applications just declare BEGIN DISTRIBUTED TRANSACTION, and from then on the Distributed Transaction Coordinator (DTC) automatically manages the transaction. DTC is an integral part of Windows NT Server and is one more step toward a full Windows NT Server cluster facility.
The Distributed Transaction Coordinator also connects Microsoft SQL Server to the open transaction standard X/Open XA. Clients can connect to transaction processing monitors such as IBM CICS, Transarc Encina, Novell Tuxedo, and Top End from AT&T Global Information Solutions, which in turn route requests to the Microsoft SQL Servers. The use of transaction processing monitors is another approach to distributing the application by using the TP Monitor to route transactions to the appropriate servers. The TP Monitor also allows Microsoft SQL Server to participate in transactions distributed across many nodes.
Microsoft SQL Server has a companion product, Open Data Services, that is often used as a front-end process to Microsoft SQL Server, either for protocol translation (from foreign protocols to open database connectivity [ODBC] or the database library), or as a simple message dispatcher among multiple SQL servers at multiple nodes.
All these approaches make it relatively easy to partition data and applications among multiple SQL servers in a cluster.
Everything described so far exists. You can acquire and use it today. Indeed, many customers are installing Microsoft SQL Servers, scaling up to four-way SMP hardware systems, and then scaling beyond that by partitioning their databases and applications. Often, these partitions are placed close to the actual data users; data collection is placed in the retail outlets, a data mart of recent activity is placed in the accounting group, and a data warehouse is placed in the planning and marketing group. Each of these applications is fairly separate and partitions naturally. In addition, the data flows among the groups are well defined. Replication and data pipes make it easy to move data among servers. The systems are very scalable. The graphical and operations interfaces combined with Microsoft Visual Basic® Scripting Edition are used to automate the operation of many SQL servers.
Over the next few years, Microsoft SQL Server expects to add transparent partitioning of data among SQL servers. This would allow partitioned data without having the application aware of the partitioning—often called partition transparency.
After partition transparency is in place, the Microsoft SQL Server group expects to provide parallel query decomposition. That is, large data queries typical of decision support applications will be decomposed into components that can be independently executed by multiple nodes of a partitioned database.
It is relatively easy to build huge systems. Microsoft provides easy installation of the operating system and database using graphical tools and wizards. Microsoft SQL Server also includes wizards to set up operational procedures.
But, because these systems involve thousands of client systems and huge databases, manageability is the real challenge. Managing and operating a computer system has always been a major part of the cost of ownership. When hardware and software prices plummet, the residual management cost becomes even more significant. Loading, dumping, and reorganizing 100-GB databases is a challenge. At the 3-MB/second data rate of most tape drives, it takes a day and a half just to dump a 100-GB database with one tape drive. Defining and managing the security attributes of 5,000 different users is a daunting task. Configuring the hardware and software for 5,000 clients is another time-consuming task.
Microsoft recognizes that manageability is the largest barrier to scalability. Details of Microsoft's solution to these problems are described in an Enterprise Manager white paper (available in November 1996) that describes Microsoft's Enterprise Manager, and in the product documentation. This section summarizes Windows NT Server and Microsoft SQL Server administrative facilities.
Managing the software and hardware configurations of thousands of clients is probably the most challenging task of operating large client-server systems. Windows NT Server and Microsoft's System Management Server automate many of these tasks. First, Windows NT Server Security provides a domain concept and a single logon for each application running on Windows NT Server. Windows NT Server security provides user groups. Large user populations can be managed by authorizing groups and adding users to groups. The Windows NT Server security mechanism works as a collection of security servers (domain controllers) spread among the network nodes. This distribution provides both scalability and availability. Individual domains have been scaled to over 40,000 users. Windows NT Server security scales beyond that size by partitioning into a multidomain architecture with trust relationships among domains. The security system has both a programmatic and an intuitive graphical interface that allows any node to manage the network security.
Microsoft SMS (System Management Server) allows a single administrator to manage the software configuration, licensing, and upgrades of tens of thousands of clients. SMS automates most tasks and tries to minimize exception situations that only an expert can solve. To give another example, Windows NT DHCP protocol automatically assigns TPC/IP addresses to nodes on demand, thereby eliminating time-consuming and error-prone tasks, allowing node mobility, and conserving the address pool.
Windows NT Server has built-in tools to log errors, manage disk space, set priorities, and monitor system performance. All of these tools can manage a cluster of client and server nodes. Figure 10 shows the performance monitor at one node tracking the CPU and network utilization of several nodes. Each Windows NT Server node has over 500 performance counters for its internal behavior. Microsoft SQL Server, Exchange, and many other products ported to Windows NT Server integrate with the Windows NT performance monitor. Indeed, Microsoft SQL Server adds over 75 performance counters and integrates with the Windows NT Server event log to announce events.
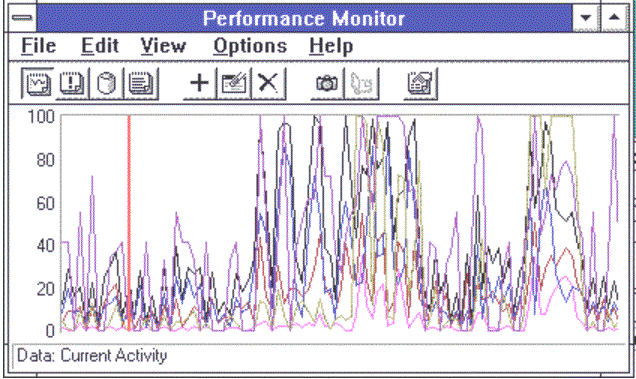
Figure 10. Windows NT performance monitor
Microsoft SQL Enterprise Manager is a breakthrough in managing database servers. It gives administrators a visual way to manage and operate many SQL systems from a single console. The graphical interface has several wizards built in to help set up and automate standard tasks. The key features of the SQL Enterprise Manager are:
SQL Enterprise Manager includes wizards to set up routine operations, a wizard to routinely publish Web pages from the database to an Internet or intranet, wizards to help set up a data replication strategy, and answer wizards that guide the operator through the online manuals.
Utilities to load, dump, recover, check, and reorganize large databases are key to operating a system with huge databases. Backing up a 100-GB database using a single high-performance tape drive will take over 33 hours. By using multiple disks and tapes in parallel, Microsoft SQL Server and Windows NT Server have shown a sustained dump rate of 20 GB per hour. This benchmark was I/O limited; with more tapes and disks, the dump rate could have been even faster. The actual management of the dumps can be controlled by the SQL Enterprise Manager job scheduler working with commodity tape robots. These dumps either can be done at full speed or they can be done in the background at a slower rate. By doing incremental dumps and by increasing the degree of parallelism, huge databases can be dumped in a few hours.
Looking at specific examples helps illustrate how Microsoft SQL Server is used in practice.
AIM Management Group is a large mutual fund manager with over 1,000 employees managing more than $40 billion of assets. AIM uses SQL for both online transaction processing and for data warehousing. The data warehouse stores shareholder account data and mutual fund transaction data. It is growing from 20 GB to 50 GB. The data warehouse receives up to 500 MB of new data each day within a two-hour window. The application runs on a four-way Intel Pentium SMP.
Aristotle Publishing provides a 125 million-record Microsoft SQL Server database containing public voter registration data for the United States. This 90-GB data warehouse application runs on Microsoft SQL Server 6.0 and Windows NT Server 3.51. The server is a dual Intel Pentium 90-MHz server. Over a thousand clients access this database to find voter patterns and preferences. Aristotle is now using Microsoft SQL Server to develop a second application involving 60 million state automobile driver's license records.
Microsoft CITS is a mission-critical OLTP application key to our product and customer support. It is based on Microsoft SQL Server 6.5 and Windows NT Server 3.51. CITS supports more than 3,600 concurrent users connected via the Microsoft network from all over North America. It has been lab-tested with over 5,000 concurrent users. The database size is about 10 GB, containing customer and product data. It is supported by a 4x100-MHz Pentium Compaq server with 1 GB of RAM and a 52-GB RAID5 disk array. The system is replicated on a hot standby machine in a second building by sending the database log to the standby machine. The standby can take over within 5 minutes. The system provides better than 99.5 percent uptime.
The Potomac Group provides Medicaid eligibility verification services to doctors and hospitals in 20 states. The system consists of two 150 MHz DEC Alpha 2100s running Windows NT Server 3.51 and Microsoft SQL Server 6.0. A StorageWorks RAID array stores the 10-GB database. The application software, in combination with DECmessageQ, allows one of the servers to fail over to the other server in a matter of seconds, routing all new transactions to the surviving server. The system has been benchmarked at over 4,000 transactions per minute.
The large TPC-C benchmarks have about 3,500 clients accessing a database of about 80 disks that hold over 300 GB. This includes log space, index information, and metadata. The largest table in a 4,000 tpmC benchmark is the 160-GB OrderLine table with about 3.4 billion 54-byte records. The other tables increase the core database size to about 200 GB. Indices, fragmentation, slack for database growth, and the recovery log increases this to over 300 GB. More details can be found on http://www.tpc.org/. Figure 11 summarizes the current status of TPC-C benchmarks on Windows NT Server platforms.
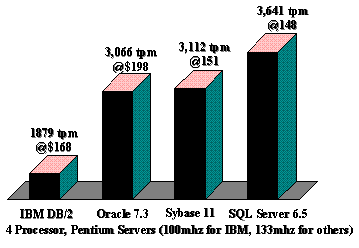
Figure 11. TPC Results On Windows NT Server
Windows NT Server and Microsoft SQL Server scale up to huge databases on a single SMP and scale out to multiple servers, each executing a part of the application and storing a partition of the database. SQL Enterprise Manager makes it easy to configure and manage these servers. OLE Transactions, replication, and data pipes make it easy to move data and requests among them.
Today, a single Microsoft SQL Server can support up to 5,000 active users connected to a single server via ODBC. These servers can process several million transactions in an eight-hour day. They support databases with billions of records spread across one hundred disks, holding hundreds of gigabytes.
Microsoft SQL Server performs these tasks with unrivaled price, performance, and ease of use. The performance of Microsoft SQL Server, Windows NT Server, and the underlying hardware have more than doubled each year for the last three years. We expect this trend to continue for several more years.
The recent additions of OLE Transactions and automatic fail-over are the most recent steps in progress toward Windows NT Server Clusters of Microsoft SQL Servers that can scale both vertically and horizontally.
For the latest information on Microsoft SQL Server, check out our World Wide Web site at http://www.microsoft.com/sql/ or the Microsoft SQL Server Forum on the Microsoft Network (GO WORD: MSSQL).