Peter Bateman, Digital Information Services, Seattle, WA and Bruce Schatzman, BDS Consulting, Mercer Island, WA
September 1995
Abstract
Database replication is the technology for copying a database so that two or more copies remain synchronized. The original database is converted into a Design Master and each subsequent copy of the database is called a replica. Together, the Design Master and the replicas comprise the replica set. Each member of the replica set contains a common set of replicable objects such as tables, queries, forms, reports, macros, or modules. Each member of the replica set also can contain nonreplicable—or local—objects. Replicas that belong to the same replica set can exchange updates of data or replicable objects. This exchange is called synchronization.
If you design your applications for multiple users, database replication can improve the way your users share data. Using database replication, you can reproduce a database so that two or more users can work on their own replica of the database at the same time. Although replicas can be located on different computers or in different offices, they remain synchronized. This white paper discusses how to create and use replicas of your application database.
The new approach and flexibility that Microsoft® Jet database replication offers can be illustrated by the development of a simple application. Imagine that a client has asked you to develop a contact management application that the company's field sales staff can use to monitor sales and orders. Each sales representative has a laptop computer that can be connected to the company's network.
A traditional approach to building this application is to separate the tables from the other objects in the database so that the data can reside on a network server while the queries, forms, reports, macros, and modules reside on the user's computer. When sales representatives want to retrieve or update information in the database, they each log on to the network, open a ContactForm database on the computer, and open the ContactData database from the server.
Database replication enables you to take a new approach to building this application by creating a single database that contains both the data and objects, and then making replicas of the database for each sales representative. Or you can use attached tables and replicate the data database and application database separately. You can make replicas on each user's computer and synchronize each replica with the replica on a network server. Sales representatives update the replicas on their computers during the course of a work session, and you synchronize their replicas with the replica on the server as needed. You can also create a set of local objects such as tables, forms, or reports that are used at only one replica location.
Database replication is well suited to business applications that need to:
Although database replication can solve many of the problems inherent in distributed database processing, it is important to recognize at least two situations in which replication is less than ideal:
Microsoft provides programmers and users with four ways to use database replication:
The first three replication tools provide an easy-to-use visual interface, while the last enables programmers to build replication directly into their applications.
Replication can be used on a variety of computer networks, including Windows 95 peer-to-peer networks, Windows NT 3.51, and Novell® NetWare® 3.x and 4.x network servers.
Microsoft Access for Windows 95 provides users with replication commands while they are working in their databases. Users can point to Replication on the Tools menu and have a choice of:
Microsoft Access Users: If you have a copy of Microsoft Access for Windows 95, one of the easiest ways to become familiar with the concepts and procedures associated with database replication is to experiment with the Microsoft Access replication commands. Open an existing Microsoft Jet database using Microsoft Access, click on the Tools menu, point to Replication, and then click Create Replica to both convert your database to a Design Master and create a replica. You can then explore the changes made to the design of your database (these are explained in detail in the section "Changes to Your Database" later in this white paper) and the similarities of the replica to the Design Master. Next, make a change to the data in the replica and a change to a table design in the Design Master, and then click Synchronize Now. You can then open the replica and Design Master to confirm that the changes made appear in the other member of the replica set.
Windows 95 enables users to use replication when they drag a database file into their Briefcase. To use Briefcase replication, simply drag the Microsoft Jet database file from Windows 95 Explorer to the My Briefcase icon on your desktop or portable computer. When you are finished working on the files on the portable computer, reconnect to your main computer and click Update All on the Briefcase menu in Briefcase to automatically merge the files on your main computer with the modified files in your Briefcase.
Internally, Briefcase works in the following way. When Briefcase replication is installed through the Custom installation option in Microsoft Access for Windows 95, it registers with the Windows 95 Briefcase a special class ID (CLSID) for Microsoft Jet 3.0 .mdb files. When a file with the .mdb extension is dragged into Briefcase, the Briefcase reconciler code is called to convert the database into a replicable form. Before the conversion takes place, however, the reconciler asks if you want to make a backup copy of the original database file. The backup copy has the same file name as the original, except that it has a .bak file name extension instead of an .mdb file name extension. The copy is kept in the same folder as the original database file.
The reconciler then converts the database into a replicable form, leaves the Design Master at the source, and places a replica in the Briefcase. The reconciler also gives you the option of putting the Design Master into your Briefcase and leaving a replica on the desktop.
You can take your replica with you into the field and then synchronize the changes made to the replica on your laptop with changes made to the Design Master on the desktop or network. When you click Update All or Update Selection on the Briefcase menu, Briefcase calls the Merge Reconciler, which was also registered at Setup, to merge the changes to the two members of the replica set. Unlike Microsoft Replication Manager, Briefcase replication does not provide you with the ability to set a schedule for synchronizing with other members of the replica set. Synchronization occurs only at the time the Update command is clicked and only between the current member and the specified member.
Note: If some users of your database need to continue using it in its nonreplicable form, make a copy of your database before converting it to a replicable database.
You can use Microsoft Replication Manager, which is provided in the Microsoft Access Developer's Toolkit, if you need:
Microsoft Replication Manager provides a visual interface for converting databases, making additional replicas, viewing the relationships between replicas, and setting the properties on replicas. One of the most important features of the Microsoft Replication Manager is that you can use it to schedule synchronizations ahead of time so they occur at anticipated times and can be completed unattended. Microsoft Replication Manager gives you the greatest control over the sequence and timetable for synchronization of any Microsoft Jet database engine tool.
Microsoft Replication Manager also runs under Microsoft Windows NT 3.51.
Microsoft Jet database replication provides extensions to the DAO programming interface to the Microsoft Jet database engine (available through Microsoft Access for Windows 95 or Microsoft Visual Basic® 4.0). These extensions allow programmers and MIS support staff to implement several of the functions of Briefcase replication through DAO coding. You can use the extensions to:
When you're building your replication-based application, you can use either Microsoft Replication Manager, DAO, or both. Deciding which one is best for your application depends on a few factors.
Microsoft Replication Manager offers the fastest way to create a replication system. You can use its graphical interface to quickly define a replication topology and set replication schedules—without programming. If possible, you should use Microsoft Replication Manager to incorporate replication into your application.
In some cases, DAO may be a better solution than Microsoft Replication Manager. Although DAO requires programming, it gives you the ability to customize your replication system. Generally, DAO should be used under the following circumstances:
For more information, see "Distributing Microsoft Replication Manager with Your Application" at the end of this whitepaper.
Microsoft Excel for Windows 95, Visual C++® 4.0, and Visual Basic 4.0 all use Microsoft Jet 3.0 directly or through DAO, and therefore, they can interface with Microsoft Jet database replication. Microsoft Excel for Windows 95 is not equipped to make a database replicable. However, if Microsoft Excel updates a database that has been made replicable by another Microsoft product, any changes made to the database will correctly synchronize with other replicas.
Because organizations differ in which of the four tools they use to implement database replication, the remainder of this white paper addresses the concepts, planning, implementation, and troubleshooting issues that are common across all four sets of tools. The next section begins the discussion by introducing concepts that might be new to or different from the way your organization is currently sharing data.
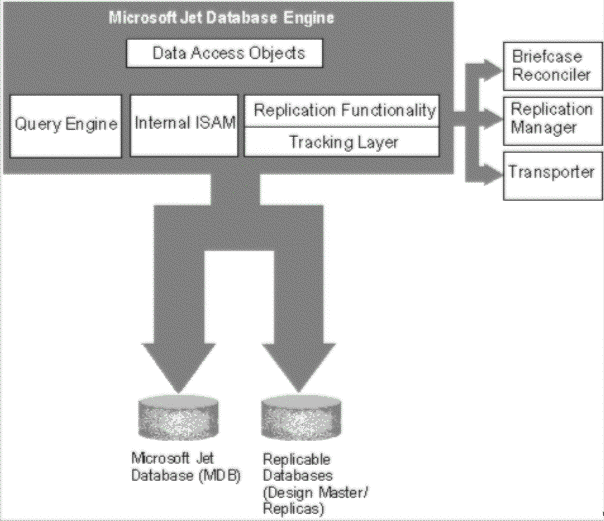
The Microsoft Jet replication engine consists of six major components:
The following diagram shows the relationship among these components and between the components and Microsoft Jet.
Figure 1: The structure of Microsoft Jet database replication
This section describes each of these components and identifies the files associated with each component.
The ability to track changes in the database resides within the Microsoft Jet database engine. As its name implies, every action executed by Microsoft Jet at one replica is tracked and recorded in preparation for its transmission to other replicas. Both data and design changes are replicated. The main replication services, including the creation of replicable databases and replica synchronization are included in files Mswng300.dll, Msjtrclr.dll, and Msjt3032.dll.
As described above, Microsoft Replication Manager provides the management tools necessary to support replicated applications in dispersed locations. It also can be used to generate reports on the synchronization activity between replicas, which can be used to make sure the distributed application is performing as designed. Microsoft Replication Manager is included in files Replman.exe and Msjtrmi30.dll.
For database replication to be useful, it is not enough for there just to be multiple replicas of the same database. The replicas must communicate with one another to remain synchronized. As mentioned earlier, synchronization is the act or process of making the replicas identical, both in terms of the data they contain and how they are designed; changes made to the existing records in one replica are communicated to each of the other replicas that have that same record. Similarly, new records added or old records deleted from one member of the replica set are communicated to each of the other members of the set.
If you use Briefcase or Microsoft Access to synchronize your replicas, Microsoft Jet handles the direct exchange of information between members.
If you use Microsoft Replication Manager, a separate utility called the Transporter monitors the changes to a replica and handles the actual exchange of data between replicas. With Microsoft Replication Manager, each replica must have a Transporter assigned to it.
Note: Although you can have more than one Transporter assigned to the same replica, this approach is not recommended because it can cause undesirable side effects.
The Transporter performs either direct or indirect synchronizations between two members of a replica. Direct synchronization occurs when the two members can be opened simultaneously by either the Transporter or the Briefcase reconciler. If both members are on the same computer or are available over a common network, then the Transporter can apply the changes to one member directly to the other member. Indirect synchronization occurs when the target replica set member is not available because it is involved in another synchronization, the member is not in a shared folder, the other computer is temporarily disconnected from the network, the network itself is down, or in any other situation that prevents a direct connection.
When the Transporter is instructed to initiate a synchronization, it first attempts a direct connection with the target member of the replica set. If it can't establish a direct connection, the Transporter for the first member leaves a message for the Transporter of the second member at a shared folder on the network. The shared folder serves as a dropbox location for the target member and stores all the messages sent by all other Transporters in the replica set while the target member is unavailable.
Direct synchronizations are usually processed faster than indirect synchronizations because direct synchronizations allow the first Transporter to bypass the second Transporter completely. In indirect synchronizations, the return message to the first Transporter may take a few minutes, hours, or days, depending upon how often the second member connects to the network. Because a replica set member's availability can change over time, the Transporter may complete a direct synchronization one time and an indirect synchronization the next time. To determine whether a synchronization was direct or indirect, look at the exchange details in the MSysExchangeLog system table.
Note: The Transporter can run only on a computer running either Microsoft Windows 95 or Microsoft Windows NT 3.51. If a member of the replica set is stored on a non-Windows server, such as a Novell network, the Transporter must be located on a different computer.
You configure the Transporter through the Microsoft Replication Manager user interface. When Microsoft Replication Manager is first configured on a computer running Microsoft Windows 95 or Microsoft Windows NT 3.51, you are asked for the network folders to be used by the Transporter and whether the Transporter should be started automatically each time the computer is started. If you select automatic startup, a shortcut to the Transporter program is placed in the Windows 95 Start menu or the Windows NT Startup group. To change the Transporter startup to manual mode, you should move the Transporter icon to the Microsoft Access folder or program group. The file name for the Transporter is Msjttr.exe.
For information about restarting the Transporter if it stops, see Microsoft Replication Manager online Help.
The status of the Transporter is reported through the Microsoft Replication Manager user interface. At the lower-right corner of the map of the replica set, there is an image of two computers with a connection. The connection between the computers changes as the status of the Transporter changes, and a legend explains the status of the Transporter.
The File System Transport provides messaging services to the Transporter. Later releases may have additional messaging services. The file name for the File System Transport is Msajetfs.dll.
The Briefcase reconciler is a special utility that is automatically executed when Windows 95 Briefcase is used. The reconciler ensures a database is replicable, and manages the merging of updates between the Briefcase replica and the Desktop replica. The Briefcase reconciler is Msjtrclr.dll and Msjrci30.dll.
Parameters for Microsoft Replication Manager, Transporter, and the Briefcase reconciler are stored in the Windows Registry. The registry entries for Microsoft Replication Manager under Windows 95 are:
HKEY_LOCAL_MACHINE\Software\Microsoft\Jet\3.0\Replication Manager\3.0
"Path" c:\Program Files\Common Files\Microsoft Shared\Replication Manager\Replman.exe
The registry entries for the Transporter under Windows 95 are:
HKEY_LOCAL_MACHINE\Software\Microsoft\Jet\3.0\Transporter
"Path" c:\Program Files\Common Files\Microsoft Shared\Replication Manager\Msjttr.exe
The registry entries for Microsoft Replication Manager under Windows NT are:
HKEY_LOCAL_MACHINE\Software\Microsoft\Jet\3.0\Replication Manager\3.0
"Path" c:\WINNT\MSAPPS\Replication Manager\Replman.exe
The registry entries for the Transporter under Windows NT are:
HKEY_LOCAL_MACHINE\Software\Microsoft\Jet\3.0\Transporter
"Path" c:\WINNT\MSAPPS\Replication Manager\msjttr.exe
In addition, there are many minor entries for Transporter log file location, last viewed replica, security database, and so on.
The registry entries for the Briefcase reconciler are:
An important part of incorporating replication into your application is planning the appropriate topology for synchronizing data and design changes. A replication topology defines the communication that exists among members of the replica set, along with the logic that determines how synchronization occurs among the various members of the replica set.
If you're using Microsoft Replication Manager to perform replication, all members ultimately update one another using the topology that you create when you graphically link the replicas in the Replication Manager window. When you create a replication topology with Microsoft Replication Manager, the latency in the chaining can be important. If A and B synchronize, then B and C synchronize, and then A and B synchronize again, the time lag between synchronizations can be important. On the other hand, if A and B synchronize, then A and C synchronize, and then B and C synchronize, A is provided with the more current information sooner. The programmer and database administrator must work together to determine the order in which updates are dispersed throughout the database.
If you're using only DAO programming to implement replication, your code must ensure that all members of the replica set are synchronized. This might involve creating a custom replication schedule and synchronizing each member according to the schedule. One way to do this is by storing a list of all replica set members in a table or initialization file.
The following diagram shows alternative topologies that can be created:
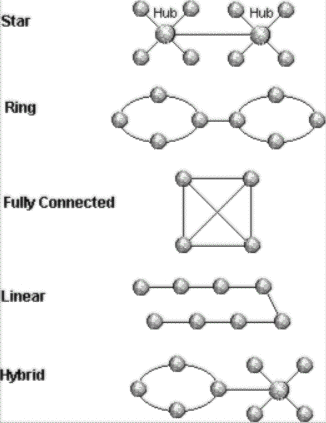
Figure 2. Replica set topologies
Other types of topologies exist. As the hybrid topology in the diagram suggests, there is an almost limitless variety of combinations and configurations. The type of topology you pick usually depends on your application; however, the star topology is usually the best for most applications.
When designing a replication topology, you'll need to decide how synchronization is initiated and which replica set member initiates it. In simple applications, a single replica might be selected as the member that initiates and controls synchronization. This replica is called the controlling replica. For example, in a simple star topology, the replica on the hub workstation may control all synchronization that occurs between members of the replica set. It is possible for a single replica to control all synchronization because the two databases specified in the DAO Synchronize method can be any two replicable databases in the same replica set.
Having a single controlling replica has the primary advantage of simplicity and ease of programming. It is a suitable design for many applications where the reliability of replication is not a critical element of the application's operation.
In some applications, the reliability of replication is critical. That is, if the controlling replica is corrupted or damaged, or if the controlling replica's computer is unavailable, the consequences might be serious. To increase reliability in these cases, you may want to design your replication topology so that more than one replica can control synchronization. There are several ways to do this. For example, your replication code could run on more than one replica, each of which periodically verifies whether the "default" controlling replica is available. One way to do this is to have a replica use the OpenDatabase method to see if the controlling replica and its computer are available. If the default controlling replica is unavailable, one of the other replicas could assume control.
A second way of determining if the controlling replica is available is to have the controlling replica maintain a log of all synchronizations that occur. Periodically, other replicas check the log to verify that a scheduled synchronization has occurred. If a synchronization does not appear in the log, one of the replicas temporarily promotes itself to the status of controlling replica and initiates the synchronization process. For safety, you should replicate the log so you have a backup in case the log at the controlling replica becomes unusable.
Another way to provide redundancy is to always have more than one controlling replica that performs synchronizations. This is the case with the fully connected topology, in which every replica is by definition a controlling replica. Although this can produce significant overhead, it is more reliable.
Note: Because so many different factors are involved, it is difficult to predict which topology will be the best solution for a specific application. You might want to experiment with a few different topologies in your replication scheme to determine which one produces the best results.
If you're implementing your replication topology with more than one controlling replica, consider using staggered schedules at each of the controlling replicas. If two members of the replica set both attempt to synchronize with a third member at approximately the same time, one of the synchronizations will succeed and the other will fail. The member that attempted—but failed—to synchronize continues to attempt to synchronize, thereby generating additional network traffic and overhead. Using a staggered schedule helps make sure that the target member is not "busy" when the synchronization is initiated.
In the star topology, a single hub periodically synchronizes with each of its satellite replicas. In this topology, all data is shared among replicas through a single, centralized database. The star topology reduces data latency time among members of the replica set because data has to travel at most two "hops" to synchronize with any other member of the set. If the average quantity of data to exchange during synchronization is relatively small, the star topology can be a fast and efficient solution.
One of the potential disadvantages of the star, however, is that the first satellite does not receive any new data from the other satellites and the last satellite receives all the new data from all the other satellites. To make sure that all satellites are properly synchronized, you must make two synchronization passes around the star.
A second potential disadvantage of the star is that the hub is involved with every synchronization and therefore must be able to handle a greater load than any of the satellite replicas. As a result, the star topology has a practical limit to the number of satellite replicas it can support because so much activity is centered at the hub. An effective way of handling this is to create additional stars and connect their hubs. Or, you can place the hub on a dedicated high-end computer capable of handling a heavy load. However, if your application exchanges only a small amount of data with each synchronization, the hub might be able to support a relatively large number of workstations.
Another potential disadvantage of the star is that it contains a single point of failure—the hub. If the controlling replica is located at the hub, and the hub fails, synchronization cannot continue among any members of the replica set. This problem can be handled in code by reassigning the controlling replica.
If you use the star topology, consider locating the Design Master at a satellite computer instead of at the hub. This has several advantages. First, you can better protect the Design Master by making it unavailable to users who have permission to modify the design of database objects. Second, you can modify the Design Master and test these modifications off-line. This prevents a set of incomplete changes from being replicated to other workstations during synchronization. When you've completed your design modifications, you can synchronize with the hub, which in turn synchronizes with other members of the replica set.
The star topology is a good starting point for many applications. It is reasonably simple to implement and can be designed to be both efficient and reliable. If you're implementing replication for the first time, the star topology is recommended.
In the ring topology, A synchronizes with B, B synchronizes with C, C synchronizes with D, and D synchronizes with A. The main advantage of the ring is that each computer handles approximately the same load, except when the replica at that computer is used to control synchronization. For more information, see "Synchronizing the Ring Topology" later in this white paper.
Latency times for a ring topology can be greater than latency times for a star topology. This is because data might have to travel multiple "hops" before it disperses to every replica. For a large number of replicas, it might take a while to disperse data throughout the replica set.
Another potential problem with simple ring implementations is that if any of the databases is unavailable, data fails to disperse throughout the application. This can be handled in your code, however, by routing information around the failure point instead of through it.
Ring topologies can be expanded by adding additional rings and connecting two or more of the replicas within each ring.
As its name suggests, the fully connected topology involves a replica set in which each replica synchronizes with every other replica. One way of conceptualizing the fully connected topology is as a star topology where every replica acts as a hub.
The fully connected topology has several benefits. One of the most significant benefits is the low latency time for data propagation. Because each replica synchronizes with every other replica, data is sent directly to all replicas without having to indirectly disperse through a series of replicas.
Another benefit of the fully connected topology is its high degree of redundancy and reliability. In the fully connected topology, each replica is a controlling replica that initiates synchronization. As a result, the impact of computer or replica failure on the entire application is minimized.
The fully connected topology can be useful in applications where data is changed frequently in most or all of the replicas, and it's important to disperse these changes as quickly as possible.
Despite its benefits, the fully connected topology can be inefficient because it involves many more synchronizations than other topologies and therefore requires more overhead and network traffic. If your application involves frequent synchronization among a large number of replicas, the fully connected topology may generate a prohibitive amount of overhead. In a fully connected scenario with n replicas, the number of synchronizations that occur is n times n. For example, 30 replicas would involve 900 separate synchronizations. If you're using a fully connected topology, it may be wise to stagger the replication schedules to reduce the amount of collisions that occur with simultaneous synchronizations.
The linear topology is similar to the ring topology, but a loop through all the replicas is not completed. That is, the first and last replicas do not synchronize with each other.
The linear topology is simple to implement, but it is usually not as efficient as some of the other topologies. The main problem with the linear topology is the long latency time for data dispersion.
To illustrate this, consider four replicas, A, B ,C, and D, that are synchronized using a linear scheme, with A as their controlling replica. If a change is made to data in replica D, but to none of the other replicas, it would take six synchronizations, starting at A, before all other replicas have D's changes. These synchronizations are: A-B, B-C, C-D, A-B, B-C, A-B. If this were set up as a ring topology, A and D would be directly connected, so it would take only four synchronizations for D's changes to be fully dispersed: A-B, B-C, C-D, D-A.
When designing a topology for your application, it is a good idea to count the number of synchronizations that must occur in different situations to fully disperse data throughout the replica set. Although the number of synchronizations is not the only measure of a topology's effectiveness, it can tell you something about the efficiency of your replication architecture.
Microsoft Jet databases are not replicable until they are converted into a replicable form. To make your database replicable, first identify the objects in the database you don't want replicated and set their KeepLocal property to the string "T" (the quotation marks are part of the string). Next, make your database replicable by setting its Replicable property to "T". For more information on making additional replicas of your database, see "Making Additional Replicas" later in this white paper.
Important: The Microsoft Jet database engine does not allow you to protect a replicable database with a database password. Before you begin using replication, remove any database password protection from the database you will be making replicable. Setting user permissions does not interfere with replica synchronization.
When you convert a nonreplicable database to a replicable form, all of the objects in the database are converted to replicable objects. If you don't want all objects in your database dispersed throughout the replica set, you can append and set the KeepLocal property on any objects you don't want replicated. For example, if your database has a table containing confidential salary information, initialization information, or names of users who log on to the database, you might want to keep that information only at your replica. You can set the table's KeepLocal property to "T" to keep it local while all other objects are replicated when the database is replicated.
The following code shows how to determine if a specified table already has the KeepLocal property appended to it:
Public Function IsLocal(strTable As String, strDB As String) As Integer
Dim intMatch As Integer, tbl As TableDef, targetdb As Database
Dim I As Integer, ws As Workspace
On Error GoTo OnErrIsLocal
Set ws = DBEngine(0)
Set targetdb = ws.OpenDatabase(strDB, False)
Set tbl = targetdb.TableDefs(strTable)
' Does the local property exist on the table?
For I = 0 To tbl.Properties.Count - 1
If tbl.Properties(I).Name = "KeepLocal" Then intMatch = True
Debug.Print tbl.Properties(I).Name
Next I
If intMatch = True Then
If tbl.Properties("KeepLocal") = "T" Then
IsLocal = True
Exit Function
End If
End If
IsLocal = False
Exit Function
'======ERROR HANDLER======
OnErrIsLocal:
Select Case Err
Case 0
Exit Function
Case Else
MsgBox "ERROR " & Err & ": " & Error
IsLocal = Err
Exit Function
End Select
End Function
Important: If the object on which you are setting the KeepLocal property has already inherited that property from another object, the value set by the other object has no effect on the behavior of the object you want to keep local. You must directly set the property for each object.
On TableDef and QueryDef objects, you create and append the KeepLocal property to the object's Properties collection. On forms, reports, macros, and modules defined by a host application (such as Microsoft Access for Windows 95), you create and append the KeepLocal property to the Properties collection of the Document object representing the object. For example, the following code appends the KeepLocal property to the Properties collection of a Document object for a module:
Sub SetKeepLocal(dbs As Database)
Dim doc As Document, prp As Property, Cont As Container
Set doc = dbs.Containers!Modules.Documents![Utility Functions]
Set prp = doc.CreateProperty("KeepLocal", dbText, "T")
doc.Properties.Append prp
End Sub
If you set the KeepLocal property and the property has not already been appended or inherited, you will receive an error. In the following example, the program sets the KeepLocal property to "T" and includes an error handler in case Microsoft Jet can't complete the action. If called, the error handler both appends and sets the property.
Sub SetKeepLocalEvenIfInherited(objParent As Object)
Const errPropNotFound = 3270
On Error GoTo KeepLocalPropHndlr
objParent.Properties("KeepLocal").Value = "T"
Exit Sub
KeepLocalPropHndlr:
If (Err = errPropNotFound) Then
objParent.Properties.Append objParent.CreateProperty _
("KeepLocal", dbText, "T")
Else
' User-defined error handler.
End If
Resume Next
End Sub
You cannot apply the KeepLocal property to objects after they have been converted into a replicable form.
If you have set a relationship between two tables in your database, you must set the KeepLocal property the same for both tables—both tables must be local or both must be replicable. If the property is not set the same for both tables, the conversion will fail. However, the KeepLocal property cannot be set while the relationship is in effect. Before setting the property, remove the relationship between the tables. After setting the KeepLocal property, add the relationship back to the two tables and proceed with converting the database.
When you convert your database into a replicable form, the database you convert becomes the Design Master for the new replica set. You can have only one Design Master in a replica set. Any changes to the design of the database, or to any of the replicable tables, queries, forms, reports, macros, and modules in the database can be done only in the Design Master. This prevents users at multiple replicas from making conflicting changes to the database's design and objects.
You can convert your database from a nonreplicable form to a replicable form in one of four ways:
This section describes how to convert your database using DAO.
Before you convert a database, you might want to determine whether the database is already replicable. The following code shows how to determine the replicable status of a database. It returns True if the specified database is replicable; otherwise it returns False:
Public Function IsReplicable(strDB As String) As Integer
Dim intMatch As Integer, targetdb As Database, I As Integer
Dim ws As Workspace
On Error GoTo OnErrIsReplicable
Set ws = DBEngine(0)
Set targetdb = ws.OpenDatabase(strDB, False)
'--- Does the replicable property exist? If not, the database
'--- isn't replicable, so return False.
For I = 0 To targetdb.Properties.Count - 1
If targetdb.Properties(I).Name = "Replicable" Then intMatch = True
Next I
If intMatch = True Then
If targetdb.Properties("Replicable") = "T" Then
IsReplicable = True
Exit Function
End If
End If
IsReplicable = False
Exit Function
'======ERROR HANDLER======
OnErrIsReplicable:
Select Case Err
Case 0
Exit Function
Case Else
MsgBox "ERROR " & Err & ": " & Error
IsReplicable = Err
Exit Function
End Select
End Function
To make a database replicable, set its Replicable property to "T". The following code provides an example of how to do this. If the Replicable property doesn't exist, this code creates it and sets it to the specified value.
Public Function SetReplicable(strDB As String) As Integer
Dim prpReplicable As Property, targetdb As Database
Dim dbtoreplicate As Database, ws As Workspace
On Error GoTo OnErrSetReplicable
Set ws = DBEngine(0)
Set targetdb = ws.OpenDatabase(strDB, True)
'--- If the Replicable property doesn't exist, create it. Turn off
'--- error handling in case the property already exists.
On Error Resume Next
Set prpReplicable = targetdb.CreateProperty("Replicable", dbText, "T")
targetdb.Properties.Append prpReplicable
targetdb.Properties("Replicable") = "T"
SetReplicable = True
Exit Function
'-------ERROR HANDLER------
OnErrSetReplicable:
Select Case Err
Case 0: Exit Function
Case Else
MsgBox "ERROR " & Err & ": " & Error
SetReplicable = Err
Exit Function
End Select
End Function
During the conversion process, Microsoft Jet maintains all the property settings of your original database.
Programmers who are familiar with the use of a single-master database on a server may want to implement the same topology using Microsoft Jet replication. The single-master topology establishes the Design Master as the only member of the replica set that accepts changes to either the design of a database or the contents of the database. All other replicas in the set are read-only.
The only way to create a single-master replica set is to use Microsoft Replication Manager; you cannot implement the topology through DAO programming.
When you convert a nonreplicable database into a replicable database, Microsoft Jet:
The conversion process adds several new system fields to each existing table in a database. Among these fields are a unique identifier, a generation indicator, and a lineage indicator.
During the conversion of a database, Microsoft Jet first looks at the existing fields in a table to determine if any field uses both the AutoNumber data type and ReplicationID field size. If no field uses that data type and field size, Microsoft Jet adds the s_Guid field, which stores the ReplicationID AutoNumber that uniquely identifies each record. The ReplicationID AutoNumber for a specific record is identical across all replicas.
The ReplicationID AutoNumber is a 16-byte GUID (Globally Unique Identifier, sometimes referred to as an UUID, or Universally Unique Identifier) that appears in the following format:
{2FAC1234-31F8-11B4-A222-08002B34C003}
The hyphens and braces are used in display only and do not form part of the GUID.
Autogenerated GUID fields are identified by the coltypeGUID and JET_bitColumnAutogenerate, or JET_bitPreventDelete (System field). There can be more than one field in a table with coltypeGUID, but there can be only one autogenerated field of coltypeGUID in a table (regardless of whether it is replicable). If an autogenerated GUID field is added to a table, GUID values are generated for all records in the table. The value of an autogenerated GUID cannot be changed or deleted.
If you are concerned that the GUID is actually not unique and therefore not any better than your own random number scheme, the following description of how the GUID is generated should remove any doubt.
GUIDs are created from the network NodeID, a time value, a clock sequence value, and a version value. For example, the GUID
{2FAC1234-31F8-11B4-A222-08002B34C003}
is created from
<time_low>-<time_mid>-<time_hi_and_version>-<clock_seq_and_reserved>-<clock_seq_low>-<node>
Time, version, and clock sequence, and so on, are described in more detail in the following paragraphs.
The timestamp is a 60-bit value equivalent to the number of 100ns ticks since Oct. 15, 1582 AD. This means time values are valid until approximately AD 3400. The time_low field is set to the least significant 32 bits of the timestamp. The time_mid is set to bits 32 to 47 of the timestamp.
GUID generation algorithms are available in different versions. The version field defines which is used. The time_hi_and_version component has the 12 least significant bits set to timestamp bits 48 to 59. The four most significant bits are set to the 4-bit version number of the GUID version being used.
The clock sequence component accounts for loss of monoticity of the clock —for example, when a clock is reset. The clock_seq_low is set to the eight least significant bits of the clock sequence. The clock_seq_hi_and_reserved least significant 6 bits are set to the six most significant bits of the clock sequence. The clock_seq_hi_and_reserved most significant 2 bits are set to 0 and 1.
The NodeID is constructed in one of two ways depending upon the presence or absence of a network card. If a network card is present, the NodeID is retrieved from NetBIOS. The first 6 bytes are extracted from the synchronous adapter status network control block. This is the IEEE 802 48-bit node address.
If a network card is not installed, a 47-bit random number (plus 1 bit for local), is generated. The random number is composed of:
It is unlikely that this number will be duplicated on this or any other machine.
The NodeID returned is explicitly made into a Multicast IEEE 802 address so that it will not conflict with a real IEEE 802based node address. The LocalOnly bit contains 1 if the address was made up, 0 if it's a real IEEE 802 address.
During the conversion process, Microsoft Jet also adds a field called s_Generation to each table in the database. The s_Generation field is used to expedite incremental synchronization by allowing the sending replica to avoid sending records that have not been updated since the last synchronization. Whenever a record is modified, its generation is set to 0.
In general, during a synchronization all records with generation 0 are sent, and then the generation for the record is incremented to one more than the last generation, which now becomes the new highest generation. The sending replica knows the last generation sent to that specific receiving replica, and sends only records with generation 0 and generations higher than the previous generations.
The receiving replica does not apply generations received out of sequence.
In some cases, Microsoft Jet replication may determine that there are too many records to be sent in a single message. In these situations, the first set of records is of one generation and the following sets of records are of higher generations. Therefore, it is possible that a single message may contain records with different generations.
Generally, there is a single generation field per record. To optimize synchronizations for databases that contain Memo or OLE Object fields (sometimes referred to as a BLOBs, or binary large objects), an extra generation field is associated with each BLOB. If the BLOB is modified, this generation value is set to 0 so that the BLOB is sent during the next synchronization. If a record modifies other fields, but not the BLOB, the BLOB generation is not set to 0 and the BLOB is not sent.
This extra generation field is named Gen_xxxx, where xxxx is the comment field name (truncated, if necessary). If this name duplicates an existing field name, the prefix is changed, one character at a time, until a unique name is found. A ColGeneration property is set on the comment field to identify the added Gen_xxxx field. One of these fields is set for each comment field.
During the conversion process, Microsoft Jet also adds a field named s_Lineage to each table in the database. The s_Lineage field contains a list of nicknames for replicas that have updated the record and the last version created by each of those replicas. The version is an integral field that is incremented when the record is changed. The first pair of values in the lineage reflects the current version and the name of the last member of the replica set to update the record. This is a binary field and is not usually readable by users.
Microsoft Jet adds several system tables to the database during the conversion process. Most of these tables are system tables, which are not normally visible to users and cannot be manipulated by programmers. The following table describes the major tables.
Name |
Description |
MSysRepInfo |
Stores information relevant to the entire replica set, including the identity of the Design Master. It contains a single record. This table appears in all members of the replica set. |
MSysReplicas |
Stores information on all replicas in the replica set. This table appears in all members of the replica set. |
MSysTableGuids |
Relates table names to GUIDs. TableGuids are used in tables such as MSysTombstones as a reference to a table name stored in this table. This allows efficient renaming of tables. In addition, this table includes the level number used for ordering tables so that updates can be processed efficiently. This is a local table that is updated by the tracking layer at the Design Master and, as part of the processing of design, changes at all other members of the replica set. |
MSysSchemaProb |
Identifies errors that occurred while synchronizing the design of the replica. This table exists only if a design conflict has occurred between the user's replica and another member of the replica set. |
MSysErrors |
Identifies where and why errors occurred during data synchronization. This table appears in all members of the replica set. |
MSysExchangeLog |
Stores information about synchronizations that have taken place between this member and other members of the replica set. This is a local table. |
MSysSidetables |
Identifies the tables that experienced a conflict and the name of the conflict table that contains the conflicting records. This table exists only if a conflict occurs between the user's replica and another member of the set. |
MSysSchChange |
Stores design changes that have occurred at the Design Master so that they can be dispersed to any member of the replica set. The records in this table are deleted periodically to minimize the size of the table. |
MSysTombstone |
Stores information on deleted records, and allows deletes to be dispersed to other replicas. This table appears in all members of the replica set. |
MSysTranspAddress |
Stores addressing information for Transporters and defines the set of Transporters known to this replica set. This table appears in all members of the replica set. |
MSysSchedule |
Stores information for scheduled synchronization. The Transporter for a local replica set member uses this table to determine when the next synchronization with another Transporter should take place, and how to synchronize data and design changes with the other Transporter. |
MSysGenHistory |
Stores a history of generations. It contains a record for each generation that a replica knows about. It is used to avoid sending common generations during synchronizations and to resynchronize replicas that are restored from backups. This table appears in all members of the replica set, but it is merged by a process slightly different from that used with normal replicated tables. |
MSysOthersHistory |
Stores a record of generations received from other replicas. It contains one generation from every message seen from other replicas. |
Microsoft Jet adds new properties to your database when it becomes replicable: Replicable, ReplicaID, and DesignMasterID. The Replicable property is set to "T", indicating the database is now replicable. Once the property is set to "T", however, it cannot be changed. Setting the property to "F" (or any value other than "T") returns an error message. The ReplicaID is a 16-byte value that provides the Design Master or replica with a unique identification.
The DesignMasterID property can be used to make a replica the new Design Master for the replica set. This property should be set only at the current Design Master. Under extreme circumstances—for example, the loss of the original Design Master—you can set the property at the current replica. However, setting this property at a replica, when there is already another Design Master, might partition your replica set into two irreconcilable sets and prevent any further synchronization of data. If you determine that it is necessary to set this property at a replica, first synchronize the replica with all other replicas in the set.
Warning: Never create a second Design Master in a replica set. The existence of a second Design Master can result in the loss of data.
There are two new properties that you can append and set on the individual tables, queries, forms, reports, macros, and modules in your database: KeepLocal and Replicable. To prevent an object from being copied to other replicas in a replica set, you can set the KeepLocal property of the object to "T" prior to converting the database into a replicable form. After the database is converted, you can set the Replicable property to "T" to make a local object replicable. For more information on these two properties, see "Making Objects Replicable" later in this white paper.
The addition of three new fields during the conversion process imposes two limitations on your tables. First, Microsoft Jet allows a maximum of 2048 bytes (not counting Memo or OLE Object fields) in a record. Replication uses a minimum of 28 bytes to store unique identifiers and information about changes to the record. If the record contains either Memo or OLE Object fields, replication uses an additional 4 bytes for each of those fields. The total number of bytes available in a record in a replicated table can be calculated as follows:
2048 bytes
28 bytes for replication overhead
(4 bytes * the number of Memo fields)
(4 bytes * the number of OLE Object fields)
= the maximum number of bytes available
Second, Microsoft Jet allows a maximum of 255 fields in a table, of which at least three fields are used by replication. The total number of fields available in a replicated table can be calculated as follows:
255 fields
3 system fields
the number of Memo and OLE Object fields
= the number of fields available
Few well-designed applications use all the available fields in a table or characters in a record. However, if you have a large number of Memo fields or OLE Object fields in your table, you should be aware of your remaining resources.
In addition to decreasing the available number of characters and fields, Microsoft Jet replication also imposes a limitation on the number of nested transactions allowed. You can have a maximum of seven nested transactions in a nonreplicable database, but a replicated database can have a maximum of six nested transactions.
Just as the addition of three new fields to your tables adds to the size of each record, the addition of new system tables adds to the size of your database. Many of these new tables contain only a few records, but some of the new tables can grow significantly depending upon the frequency of synchronization between replicas.
The size of your database file is significant for three reasons:
When you convert a nonreplicable database to a replicated database, the AutoNumber fields in your tables change from incremental to random. All existing AutoNumber fields in existing records retain their values, but new values for inserted records are random numbers. Random AutoNumber fields are not meaningful because they aren't in any particular order and the highest value isn't on the record inserted last. When you open a table with a random AutoNumber key, the records appear in the order of ascending random numbers, not in chronological order. With random AutoNumber fields it is possible—although highly unlikely—for records inserted at different replicas to be assigned the same value. If this happens, updates could be made in the wrong records. If you experience such problems, consider using the s_Guid field as the primary key. Because all numbers in the s_Guid field are unique, each record has a different ID.
Before you convert your nonreplicable database into a replicated database, determine if any of your applications or users rely on the order and incremental nature of the AutoNumber field. If so, you can use an additional Date/Time field to provide sequential ordering information.
Replicable databases use the same security model as nonreplicable databases: Users' permissions on the database are determined at the time they start Microsoft Access and log on. As a programmer, it's up to you to make sure the same security information is available at each location where a replica is used. You can do this by making the identical system database (the file that stores security information) available to users at each location where a replica is used. The default security system database is called System.mdw. The System.mdw cannot be replicated, but can be manually copied to each location. Another way to make the same system database available to all your users is to re-create the entries for users and groups at each location in the local system database by entering the same user and group names with their associated PIDs at each location. Modifications to permissions is a design change and can only be made in the Design Master.
Security permissions control certain aspects of database replication. For example, a user must have Administer permission on the database to:
By default, Administer permission is granted to the Users group, the Admins group, and the creator of the database. If security is to be maintained, you must restrict this permission to selected users.
Care should be taken to ensure there is always at least one user with the Administer permission on the database. It is possible that a site with a replicable database, which is the Design Master, and its associated System.mdw could be destroyed through a hard disk failure. While it is possible to use another replica to retain access to the data, you will need to make one of the replicas the Design Master. This can be done only by a user with Administer permission on the database. Therefore, you must make sure the System.mdw at the remote site provides Administer permission on the database to one of the users.
Although changes to the design of the database can be made only in the Design Master, additional replicas can be made from any member of the set. In fact, the only way for new copies of the database to be included in the replica set is for them to be created from an existing member. Once created, all new replicas become part of the replica set. All the members of a replica set have a unique identity and can communicate and synchronize with one another. Each replica set is independent from all other replica sets, and replicas in different sets cannot communicate or synchronize with each other.
Important: Never try to make additional replicas from the original, nonreplicable database. The result would not be an additional replica, but rather a new replicable database and replica set.
When you convert your database by setting its Replicable property to "T", you have only one member (the Design Master) in the replica set, and you make your first replica from it. You can make your first replica, and subsequent replicas, by using the MakeReplica method. For example, to make a replica, you can use the following code:
Sub MakeAdditionalReplica(strReplicableDB, strNewReplica) Dim dbs As Database, ws As Workspace Set ws = DBEngine(0) Set dbs = ws.OpenDatabase(strReplicableDB) dbs.MakeReplica strNewReplica, "First Replica of" & _ strReplicableDB, dbRepMakeReadOnly dbs.Close End Sub
If you include the dbRepMakeReadOnly constant, the replicable elements of the newly created replica cannot be modified. Otherwise, users are able to make changes to the data in the new replica. As Microsoft Jet creates the new replica, all data definition language property settings of the source replica are included in the new replica. You can make subsequent replicas from either the Design Master or any replica in the set.
When using the MakeReplica method, be sure that the objects you are replicating are not locked, or the method will fail. Microsoft Jet locks objects while they are open in design mode or being updated during a synchronization. Programmers might easily overlook this requirement and attempt to make a replica from the database that has locked objects.
Note: When you make a new replica, you copy all of the replicable objects and properties from the source replica to the new replica. Although you copy all attached tables, the path to an attached table might no longer be accurate because of the new replica's location on the network. Be sure to test the new replica to determine if you need to establish a new path for any of the attached tables.
If users have Microsoft Access installed on their computers, they can replicate any database if they have permission to open it. Users can simply use Microsoft Access menu commands to perform the replication. Although this might be acceptable in some applications, other applications might want to control the creation of new replicas.
If you want to control creation of replicas, you can provide a custom user interface designed for that purpose. Providing a custom user interface for creating new replicas enables the application to track new members of the replica set as they are created. If a user creates a replica outside the control of your application, it won't be possible to synchronize with that replica using DAO because your application won't know about the new replica.
To prevent users from creating a replica of a database using Microsoft Access menu commands, you can grant them Open privileges for the database when they start your application and then revoke that privilege when they exit your application. This prevents them from opening the database using Microsoft Access when they are not running your application. Although this is not an infallible system, it discourages the majority of users from creating replicas.
The following code sample grants or revokes the currently logged on user's privileges to open the specified database. This function can be called when the application starts and closes.
Function SetDBAccess(dbs As Database, intGrantAccess As Integer) _
As Integer Dim Cont As Container, doc As Document On Error GoTo OnErrSetDBAccess Set Cont = dbs.Containers("Databases") ' Documents(0) is the document representing the entire database. Set doc = Cont.Documents(0) Doc.UserName = currentuser() ' Get the currently logged on user. This ' is supported only in Microsoft Access. If intGrantAccess = True Then doc.Permissions = dbSecFullAccess ' Grant Open privileges. Else doc.Permissions = dbSecNoAccess ' Revoke Open privileges. End If dbs.Containers.Refresh Exit Function '----Error Handler---- OnErrSetDBAccess: SetDBAccess = Err Exit Function End Function
With database replication, it is no longer necessary to make a separate backup copy of your database. Each member of the replica set serves as a backup of the replicable portion of the database. In fact, you are strongly advised not to back up and restore members of the replica set as you would ordinary files. If you back up and restore the Design Master, you could lose critical information about changes to the design of the database as well as the ability of the Design Master to synchronize with the other replicas in the set. If the Design Master is corrupted or unusable, do not copy or restore an older version of the Design Master; instead, make another member of the replica set the Design Master. To make a replica the Design Master, use the DesignMasterID property as described in "Moving the Design Master" later in this white paper.
Important: A copy of the Design Master created with a backup and restore program might not be able to synchronize with the rest of the replica set.
For database replication to be useful, the members of the replica set must communicate with one another to remain up-to-date. Synchronization is the process of making the design and data in all the members identical. Changes made to the existing records in one member are periodically communicated to each of the other members that have that same record. Similarly, new records added or old records deleted from one member are communicated to the other members of the replica set.
You can synchronize one member with another by using either Microsoft Access for Windows 95, Briefcase, Microsoft Replication Manager, or DAO.
You can keep the members of the replica set synchronized using the Synchronize method. By specifying the target database file name, you can synchronize one user's replica with another member of the set. You can also perform one-way or two-way exchanges . For example, you might use the following code to perform a two-way exchange between members:
Sub SynchronizeDBs(strDBName, strSyncTargetDB) Dim dbs As Database, ws As Workspace Set ws = DBEngine(0) Set dbs = ws.OpenDatabase(strDBName) ' Synchronize replicas (bidirectional exchange). dbs.Synchronize strSyncTargetDB, dbRepImpExpChanges dbs.Close End Sub
If you do not provide an exchange argument, the synchronization is bidirectional (import and export).
When Microsoft Jet synchronizes two members of the replica set, it always synchronizes design changes before it synchronizes changes to data. The design of both members must be at the same version level before data can be synchronized. For example, even if you use dbRepExportChanges to specify that data changes flow only from the current members to the designated target, design changes could be made to the current member if it has a lower version number than the target member.
If you want to prevent users from making changes to the design of your database, do not put the Design Master on the network server. Instead, keep the Design Master at a network location that is accessible only to you. As you make changes to your application, you can synchronize with the replica on the server and rely on it to pass these changes on to other replicas in the replica set.
As described in the "Replica Set Topology" section earlier in this whitepaper, you can implement a variety of topologies for synchronizing members of the replica set. The following code examples show how to implement the star and the ring topologies.
The following code provides a simple example of implementing synchronization using a star topology. In this sample, the hub is specified as an input parameter. The list of replica paths is stored in a table whose name is specified in the parameter strReplicas. The table itself is stored in a database whose name is specified in the parameter strDb. The table must have a field named Path that contains the replica paths. The name of the replica acting as the hub is specified in strHub.
Function StarSync(strDB As String, strReplicas As String, strHub As _
String) As Integer Dim ws As Workspace, db As Database, dbsHub As Database, dbPaths As _ Database Dim rstReplicas As Recordset On Error GoTo OnErrStarSync Set ws = DBEngine(0) Set dbPaths = ws.OpenDatabase(strDB) Set rstReplicas = dbPaths.OpenRecordset(strReplicas, dbOpenSnapshot) On Error Resume Next Set dbsHub = ws.OpenDatabase(strHub) ' Open the hub database. ' If the hub specified in strHub is unavailable, return an application-
' defined error so the caller can reassign a new hub and call the
' function again. If Err <> 0 Then StarSync = False Exit Function End If ' Synchronize all members of the replica set with the hub. ' Since error trapping is turned off, the program continues to sync ' with other replicas if the Synchronize method fails for any replica. Err = 0 Do Until rstReplicas.EOF If rstReplicas!Path <> strHub Then ' Hub can't sync with itself. Debug.Print rstReplicas!Path dbsHub.Synchronize rstReplicas!Path End If ' If an error occurred while synchronizing with the current replica, ' log an error that stores which replica failed to synchronize. The ' procedure LogError is a custom, programmer-written procedure for ' logging errors to a text file. If Err <> 0 Then MsgBox ("Synchronization failure at " & rstReplicas!Path) Err = 0 End If rstReplicas.MoveNext Loop dbsHub.Close rstReplicas.Close dbPaths.Close Exit Function '--- ERROR HANDLER --- OnErrStarSync: dbsHub.Close rstReplicas.Close dbPaths.Close StarSync = Err Exit Function End Function
The following code provides a simple example of implementing synchronization using a ring topology. The list of replicas is stored in a table with a name specified by strReplicas. Each replica listed in the table is synchronized with the replica specified in the next record of the table. The last replica in the list is synchronized with the first.
Function RingSync(strDB As String, strReplicas As String) As Integer
Dim ws As Workspace, db As Database, dbsHub As Database, dbPaths As Database
Dim rstReplicas As Recordset
On Error GoTo OnErrRingSync
Set ws = DBEngine(0)
Set dbPaths = ws.OpenDatabase(strDB)
Set rstReplicas = dbPaths.OpenRecordset(strReplicas, dbOpenSnapshot)
On Error Resume Next
Do Until rstReplicas.EOF
Set dbsSyncSource = ws.OpenDatabase(rstReplicas!Path)
' If an error occurred while opening the database, log an error.
If Err <> 0 Then
MsgBox ("Synchronize failure at " & rstReplicas!Path)
Err = 0
End If
rstReplicas.MoveNext
If rstReplicas.EOF Then Exit Do
' If an error occurs during synchronization, keep moving around
' the ring.
On Error Resume Next
dbsSyncSource.Synchronize rstReplicas!Path
dbsSyncSource.Close
dbPaths.Close
Loop
'--- Synchronize the last member in the list with the first member to
'--- complete the ring.
rstReplicas.MoveFirst
dbsSyncSource.Synchronize rstReplicas!Path
dbsSyncSource.Close
rstReplicas.Close
Exit Function
'--- ERROR HANDLER ---
OnErrRingSync:
dbsSyncSource.Close
rstReplicas.Close
RingSync = Err
Exit Function
End Function
The way in which you manage synchronization within your application can depend on your network. Synchronization strategies for computers connected by a single local area network (LAN) are usually quite different from synchronization strategies for computers connected using wide area networks (WANs) and modems. For computers connected through a single LAN, synchronization can occur frequently because telecommunication overhead does not have to be considered.
With WANs, telecommunication overhead can be a major factor because of longer data transmission times and higher transmission rates. In this section, two different WAN topologies are discussed, along with possible ways to handle synchronization.
The following diagram shows a company that has an order entry department in Denver and headquarters in Boston. Each day, customers call an 800 number to order products from the company's catalog, and these orders are entered into a custom Microsoft Jet database application.

Figure 3. Ring topology synchronization over a WAN
Once a day, sales transactions entered in Denver must be transferred to headquarters, where managers can run queries against the data to track sales totals, geographic sales distribution, and other statistics. Conversely, updated product information such as new products and discounts on existing products must be sent from headquarters to the sales office as soon as it is available. Computers in the order entry department comprise a single LAN, and computers at headquarters comprise another LAN. The two LANs are connected through a modem.
In this environment, how can replication be configured efficiently to meet the company's requirements? Configuring replication within each LAN is a fairly straightforward task. For example, the databases in Denver could be configured to synchronize data every 30 minutes using a ring topology. In a ring topology, computer A updates computer B, which updates computer C, and so on. This update chain occurs repeatedly at specified intervals and can be set using Microsoft Replication Manager or in code using DAO methods and the Timer event. The databases in Boston can be configured to regularly synchronize data in a similar manner.
The main concern is the bottleneck created by the modem link between Denver and Boston. For a large number of sales transactions, the telecommunications overhead of frequently synchronizing data between the two cities would be high. But because headquarters needs information only once a day, a good strategy would be to wait until night to synchronize one of the computers in Denver with one of the computers in Boston. The computer in Boston and the computer in Denver must be fully synchronized within their respective rings before they synchronize between the two rings. Once the information is synchronized between the two computers, the periodic synchronization that occurs between computers in the same city disperses the information to all computers.
Because product information in Boston must be sent to Denver only when new information is available, replication can be configured to occur only when necessary. This might occur once or twice a week. To handle this, a user could click a button on a form to synchronize the databases in Denver and Boston whenever product information changes. A more sophisticated solution would be to set a value in a table each time information in one of the product tables changes. A procedure linked to a Timer event would periodically check this value and invoke the Synchronize method whenever the value is set.
Note: Networks have topologies too, and these should not be confused with replication topologies. For example, a network topology can be a ring, a star, or a straight line. Although the diagram shows a ring (circle), this refers to the replication topology. The underlying network topology is not shown and can be of almost any type.
In some applications, a certain percentage of records are discarded because of bad or missing information. For example, in an application where information on hard copy forms is entered into a database, a certain percentage of these records must be discarded because they are incomplete. In other applications, some data may need "fixing" before it can be used. For example, a field in a table may be designed to hold a string of comma-separated numbers, but may instead contain non-comma separators, letters, or other mistakes.
When data is synchronized, all updated data is dispersed, regardless of whether it is useful to a particular application. Bad data in one database becomes bad data in multiple databases when synchronization occurs. Therefore, when building a replication system for your application, you may want to consider writing procedures that either purge or fix data before it is replicated to other systems.
When you convert a nonreplicable database to a replicable form, you convert all of the objects in the database to replicable objects unless you set their KeepLocal properties to "T". After you make a database replicable, however, all new objects created in the Design Master, or in any other replicas in the set, are treated as local objects. Local objects remain in the replica in which they're created and are not copied throughout the replica set. Each time you make a new replica in the set, all the replicable objects in the source replica are included in that new replica, but none of the local objects are included.
If you create a new object in a replica and want to change it from local to replicable so that all users can use it, you can either create the object in or import it into the Design Master. Be sure to delete the local object from any replicas; otherwise, you will encounter a design error. After the object is part of the Design Master, set the object's Replicable property to "T".
Important: If the object on which you are setting the Replicable property has already inherited that property from another object, the value set by the other object has no effect on the behavior of the object you want to make replicable. You must directly set the property for each object.
On Database, TableDef, and QueryDef objects, you create and append the Replicable property to the object's Properties collection.
On forms, reports, macros, and modules defined by a host application (such as Microsoft Access for Windows 95), you create and append the Replicable property to the Properties collection of the Document object representing the object. For example, the following code appends the Replicable property to the Properties collection of a Document object for a module:
Sub CreateReplicableProperty(dbs As Database)
Dim doc As Document, prp As Property
Set doc = dbs.Containers!Modules.Documents![Utility Functions]
Set prp = doc.CreateProperty("Replicable", dbText, "T")
doc.Properties.Append prp
End Sub
If you set the Replicable property and the property has not already been appended or inherited, you will receive an error. In the following example, the program sets the Replicable property to "T" and includes an error handler in case Microsoft Jet can't complete the action. If called, the error handler both appends and sets the property.
Sub SetReplicableEvenIfInherited(objParent As Object)
Const errPropNotFound = 3270
On Error GoTo ReplicablePropHndlr
objParent.Properties("Replicable").Value = "T"
Exit Sub
ReplicablePropHndlr:
If (Err = errPropNotFound) Then
objParent.Properties.Append objParent.CreateProperty _
("Replicable", dbText, "T")
Else
' User-defined error handler.
End If
Resume Next
End Sub
The next time you synchronize, the newly replicable object will appear in the other replicas in the set. Similarly, if there is a replicable object that you want to make local, set its Replicable property to "F". You can also set the Replicable property by selecting or clearing the Replicable check box in the object's property sheet in Microsoft Access.
Warning: When you change the status of an object from replicable to local by setting the value of the object's Replicable property from "T" to "F", the object is deleted from all members of the replica set except the Design Master. Extra care should be taken when you change the replicable status of a table. Even if you temporarily make a replicable table local at the Design Master and then make it replicable again, the table will be deleted and re-created at each replica during the next synchronization. Any data entered in the table at a replica since the last synchronization will be lost unless you synchronize all replicas before making the design change.
A database that can have replicas containing both replicable and local objects is much more useful because users can share corporate, division, or workgroup data that is common to all their tasks, while maintaining location-specific data and customized queries and reports.
When using database replication, you might occasionally encounter synchronization conflicts, synchronization errors, or design errors. Synchronization conflicts occur when the same record is updated at two members of the replica set, and Microsoft Jet attempts to synchronize the two versions. The synchronization succeeds, but the changes at only one of the members are applied to the other. Synchronization errors occur when a data change at one replica set member cannot be applied to another member because it would violate a constraint such as a referential integrity rule or uniqueness assertion. The synchronization succeeds, but the contents of the database at different members is different. Finally, design errors occur when a design change at the Design Master conflicts with a design change at a replica. The synchronization fails and the content of the databases at different members starts to diverge.
Synchronization errors and design errors are much more significant problems than synchronization conflicts because the replica set members no longer share a common design or identical data. This section describes the factors contributing to conflicts and errors, and suggests ways to prevent or resolve them.
Whenever you synchronize two members of a replica set, there is always the possibility of conflict between versions because the same record might have been updated at both locations. During synchronization, if Microsoft Jet detects that the same record was changed at both members, Jet treats it as a synchronization conflict. Even if the changes made at one replica set member were in different fields than the changes made at the other member, Microsoft Jet treats it as a synchronization conflict.
When a synchronization conflict occurs, Microsoft Jet does not attempt to resolve the conflict based on the content of the records or the changes made to the data. Instead, it uses a simple algorithm to select one of the record versions to be the official change and writes the data from the other record version into a conflict table. It is then the responsibility of the programmer, database administrator, user, or a custom resolution program to review each conflict to determine that the correct information was applied to the database.
The algorithm Microsoft Jet uses to select one record version over the other is based on the record's version number, which is stored in the table's s_Lineage field. Each time a change is made to the data in a record, the version number increases by one. For example, a record with no changes has a version number of 0. A change to data updates the version number to 1. A second change to the same data, or a change to different data in the record, changes the version number to 2. If the record at one replica set member has been changed once and the same record at the second member has been changed three times, then the record at the second member has a higher version number than the record at the first member. When Microsoft Jet compares the version numbers for the same record, it assumes that the version that has changed the most is the more correct of the two versions. If both records have the same version number, Microsoft Jet examines the ReplicaID and selects the replica set member with the lowest ReplicaID.
While this algorithm and its underlying assumption may not be the most appropriate in all applications, it allows Microsoft Jet to quickly and consistently complete the synchronization process and preserves all the information from both versions for later review. The data from the record version that Microsoft Jet did not select is stored in a conflict table in the member where the change was made. Conflict tables derive both their names and fields from the underlying tables. Conflict table names are in the form table_Conflict, where table is the original table name. For example, if the original table name is Customers, the conflict table name is Customers_Conflict. Because conflicts are reported only to the replica set member that originated the losing update, conflict tables are not replicated.
After synchronizing two replicas, you should review each conflict to determine that the correct information was applied to the database. You can determine if a conflict has occurred for a specific table by using the ConflictTable property. This property returns the name of the conflict table containing the database records that conflicted during synchronization. For example, to find the name of the conflict table, examine each record conflict, and take action to resolve each conflict, you can use the following code:
Sub Resolve(dbs As Database)
Dim tdfTest As TableDef, rstConflict As Recordset
For Each tdfTest In dbs.TableDefs
If (tdfTest.ConflictTable <> "") Then
Set rstConflict = dbs.OpenRecordset(tdfTest.ConflictTable)
' Process each record.
rstConflict.MoveFirst
While Not rstConflict.EOF
' Do conflict resolution.
' Remove conflicting record when finished.
rstConflict.Delete
rstConflict.MoveNext
Wend
rstConflict.Close
End If
Next tdfTest
End Sub
If there is no conflict table, or if the database is nonreplicable, the property returns a zero-length string.
As you review each conflict in the conflict table, you should take the appropriate action. If the record version selected by Microsoft Jet was the correct version and no further action is necessary, you can delete the record from the conflict table. If the record version selected by Microsoft Jet was not the correct version, you might want to:
If you handle replication through the Microsoft Access for Windows 95 user interface, Microsoft Access automatically notifies you of a synchronization conflict each time you open a database with conflicts. Microsoft Access ships with a default conflict resolver to assist you in displaying a list of all tables having synchronization conflicts and choosing whether to apply the data from the conflict table after all. You run the default conflict resolver by clicking Yes when asked if you want assistance resolving the conflicts. You can also launch the conflict resolver at any time by pointing to Replication on the Microsoft Access Tools menu and clicking Resolve Conflicts.
You can replace the default conflict resolver with a custom function for reviewing and processing the records in a conflict table. If you want to use a custom function instead of the default conflict resolver, create the ReplicationConflictFunction property and set the value to the text string name of the custom function. The custom function must be stored in a module at the Design Master (not as a separate dynamic-link library), and the module must be replicated.
If you want to return to using the default conflict resolver after using a custom function, set the property's value to " " (an empty string).
You need be aware of at least four sources of potential synchronization errors when building your application:
Microsoft Jet allows you to establish table-level validation (TLV) rules to restrict the value or type of data entered into a table. However, if you implement TLV without determining that any existing data does not violate the validation rule, you may encounter a synchronization error in the future. For example, assume that you apply a TLV rule to a field that already contains data and test to make sure that the existing values meet the rule. There might be new or updated records at other replica set members that do not satisfy the new rule. If you do not test the existing values at the other members and change the values that fail the rule, the next synchronization will fail to correctly update the records. When Microsoft Jet applies the new or updated records from the other member to the member on which you set the TLV rule, Microsoft Jet tests each insertion or update against the rule. If the value fails, the update fails and an error is written to the MSysErrors table at the receiving member. To correct the error, you must correct the invalid values at the sending replica set member. You can avoid the error by synchronizing all members of the replica set before applying a TLV rule.
Duplicate keys can occur when two users at different replicas either simultaneously insert a new record and use the same primary key for their respective records or change the key on two different records when both happen to use the same value. When the replicas are synchronized, the synchronization succeeds, but Microsoft Jet writes a duplicate key error to the MSysErrors table for each of the records that could not be inserted or updated. To correct a duplicate key error, change the value of one of the keys or delete the duplicate record.
Referential integrity preserves the relationship between tables when adding or deleting records. Enforced referential integrity prevents you from adding or deleting a record to a related table if there is no corresponding record in the primary table. In some situations, enforced referential integrity may result in synchronization errors. For example, if a user at the Design Master deletes a record with a primary key from a table and a user at a replica inserts a record that references that key, the next synchronization of the two members generates two errors. During synchronization, Microsoft Jet attempts to delete the primary key record at the replica but cannot. The reference to a record or records in a related table at the replica prevents the deletion from succeeding. Microsoft Jet also attempts to add the referencing record at the Design Master but cannot. The new record references a primary key that no longer exists at the Design Master. To correct the two errors you must delete from the replica the record that references the deleted primary key.
The outcome of the preceding scenario changes if you enforce cascading deletes in your application. With cascading deletes in effect, Microsoft Jet deletes both the primary key record and all referencing records at the Design Master. When the Design Master is synchronized with the replica, the referencing record fails to synchronize because there is no longer a valid primary key; Microsoft Jet records the error in the MSysErrors table. In this situation, however, the error will correct itself during the next synchronization when the replica is notified that the primary key has been deleted from the record.
If a record is locked when Microsoft Jet attempts to update it during a synchronization, Microsoft Jet retries the update several times. If the record remains locked after repeated attempts, the synchronization fails and Microsoft Jet records an error in the MSysErrors system table. Although this type of error is exceedingly rare, it might occur in certain multiuser applications. Errors caused by locked records can be ignored because Microsoft Jet will retry updating the records during the next synchronization. Because it is unlikely that the same record will be locked during the next synchronization, the record is updated and the error is removed from the MSysError table.
Synchronization errors are recorded in the MSysErrors table and replicated to all members of the replica set. This table includes information about the:
Errors must be corrected as soon as possible, because they indicate that the data in different replicas may be diverging. You should be especially careful to correct synchronization errors before moving or renaming your database, because the error is recorded against the ReplicaID at the time the error occurred. If the ReplicaID is changed it will not be possible for Microsoft Jet to automatically remove the error records during a subsequent synchronization. If the error record is not removed, you will continue to receive notification of the error each time you open the database in Microsoft Access even if you have corrected the problem.
In many circumstances, errors are self-correcting during the next synchronization. For example, during an attempted synchronization, an update would be rejected if another user has the record locked. Microsoft Jet records an error and attempts to reapply the update at a later time. If the subsequent update succeeds, the error record is removed. As a general rule, always synchronize all members of the replica set before manually correcting synchronization errors. Due to the nature of bidirectional synchronizations, it may take more than one synchronization to clear the error record from MSysErrors after the error is corrected. However, all corrected errors should be cleared from the MSysErrors table after two bidirectional synchronizations.
Just as Microsoft Access for Windows 95 automatically notifies you of a synchronization conflict each time you open a database with conflicts, it also notifies you of any synchronization errors. The default conflict resolver that ships with Microsoft Access first displays a list of all the tables with synchronization errors. After you select a table, the conflict resolver displays the following information for each error: the replica set member, path, table name, record ID, attempted operation, and the reason the operation failed. You can review each error individually and take the appropriate action for correcting the error.
The order in which you make design or data changes to the database has important implications for synchronizing members of the replica set. As you make changes in the design of your database, Microsoft Jet records each change in the MSysSchChange system table. Each change is recorded as a separate record in the table, and each record contains all the information about the design change. When Microsoft Jet synchronizes two members of the replica set, it compares the MSysSchChange table at the initiating member with the MSysSchChange table at the target member. If the two members are not at the same design level, Microsoft Jet applies all the design changes from the most current (highest number of levels) member to the design of the less current member. For example, if the Design Master has been changed six times, each replica must receive all six changes to make its design identical to that of the Design Master. Because of the latency in the synchronization process, one replica may have received only four of the design changes, while another replica may have received all six changes. When the replica having only four changes synchronizes with a replica that has all six changes (or with the Design Master), Microsoft Jet applies the remaining two changes to the design of the less current replica.
When Microsoft Jet applies all the design changes from one replica set member to another, it applies the changes in the exact order that the changes were made in the Design Master, and, consequently, the order in which the changes were recorded as records in the MSysSchChange table. Microsoft Jet does not examine later records in the table to determine if a design change was undone or further modified by a later change. For example, if you add a table to your database and then make the table replicable, Microsoft Jet records the creation of the table as one design change and makes the table replicable as a second design change. If you then delete the replicable table, Microsoft Jet records that as a third design change. At the next synchronization, Jet applies each change in order, even though the table doesn't exist when the synchronization is complete.
Applying design changes to replicas in the exact order the changes were made at the Design Master is a strength of Microsoft Jet database replication that ensures all replicas become identical to the Design Master. However, changes that you or a user make at a replica can cause design errors. For example, if a user at a replica creates a local table and gives it the default name table1, and you create a replicable table at the Design Master and also give it the default name table1, Microsoft Jet will fail when it attempts to synchronize the replica with the Design Master because the replica already has a table with that name. The design error is recorded in the MSysSchemaProb system table and is available for your review.
The MSysSchemaProb table is a local table and is present only when an error occurs when updating the structure of a replica. The table provides details about the cause of the error, including:
The rows in the MSysSchemaProb table are automatically deleted when the corresponding design change is successfully applied during synchronization.
To solve design errors, you should carefully review the MSysSchemaProb table to identify the action that failed and then manually remove the element at the replica that is blocking the change. The blocking element must always be removed at the replica even if the design change at the Design Master was the instigator of the error. For example, to correct the error of the two tables named table1, you must delete the table from the replica even though the table was in existence prior to the creation of the table at the Design Master. Removing the blocking element at the Design Master has no effect on correcting the error because the information about the design change is already stored as a record in the MSysSchChange table. Deleting table1 at the Design Master simply adds a new record to the MSysSchChange table (recording that table 1 was deleted) instead of removing the record that created table1 in the first place. Because Microsoft Jet does not allow programmers to change the contents of the MSysSchChange table, you cannot correct the error except by removing the blocking element at the replica.
Although Microsoft Jet makes database replication easy to implement through DAO programming or through Microsoft Access in combination with Microsoft Replication Manager and Briefcase, replication can be complicated by a number of special considerations. These considerations include:
This section presents these additional factors that must be included in your planning, design, and implementation of database replication.
The Design Master is the most important member of a replica set because it is the only member in which you can make changes to the structure of the database. Under certain circumstances, you might have to move the Design Master to a replica. For example, you might have the Design Master on your computer while another member of your development team has a replica on his or her computer. While you are on vacation, you want the other programmer to be able to make changes to the database. You can use the DesignMasterID property to accomplish the transfer and synchronize the old and new Design Masters, as shown in the following code:
Sub SetNewDesignMaster(stroldDM, strNewDM) Dim dbs As Database, newdmdb As Database Dim ws As Workspace Set ws = DBEngine(0) ' Open current Design Master in exclusive mode. Set dbs = ws.OpenDatabase(stroldDM, True) ' Open database that will become the new Design Master. Set newdmdb = ws.OpenDatabase(strNewDM) dbs.DesignMasterID = newdmdb.ReplicaID dbs.Synchronize strNewDM, dbRepImpExpChanges dbs.Close newdmdb.Close End Sub
You must have the Design Master open to make another replica the new Design Master. The Design Master is, by definition, read-write. If you make a replica that is designated read-only into the Design Master, the target replica is made read-write; the old Design Master also remains read-write.
If the Design Master is erased or corrupted, you can designate a replica to become the new Design Master. However, remember that you can have only one Design Master at a time.
If you decide to make your own replica the new Design Master for the set, synchronize it with all the replicas in the replica set before setting the DesignMasterID property in your replica. You must have your replica open in exclusive mode to make it the Design Master.
Each time you change the design of your replicable database, Microsoft Jet stores information about the change in the MSysSchemaChg system table. If you change the same object more than once before synchronizing, Microsoft Jet continues to store the newest design in preparation for the synchronization. Frequent compacting of the database after you make design changes helps to reduce the overhead required for storing changes and reduces the information sent to the replicas. You might find it most efficient to compact your database daily and again just before synchronization.
When two members of a replica set are synchronized, Microsoft Jet applies the design changes to each member before applying the data changes. You can reduce the amount of processing during synchronization and reduce the potential for conflicts if you synchronize all the replicas in the set before making design changes in the database.
Microsoft Jet must open tables exclusively before design changes are applied to them. If you are using a table in a database at the time you want to synchronize, Microsoft Jet suggests that you first close the table. If you use a Synchronize Now button on a form so users can easily click the button whenever they need to synchronize, be sure the button does not have an associated table open—either directly or through a query—in the database that is being synchronized.
If you tie list boxes to replicable tables, under certain circumstances the list box might display system fields in addition to your regular data fields. If the option to display system objects is turned on, then the system fields in the replication system tables are also displayed. Once they are visible, they may appear in the related list box.
To avoid displaying system tables, either clear the System Objects check box on the View tab of the Microsoft Access Options dialog box (Tools menu), or base the list box on a query that selects only the fields you want displayed.
You can distribute your Microsoft Access database application to others by including Microsoft Replication Manager. Setting up replicated databases with Microsoft Replication Manager is a cooperative effort involving the programmer and the site administrator. To prepare your database for replication and distribution, you need information from the site administrator, and you need to assist the administrator—preferably in person at the customer's site.
The recommended topology for using Microsoft Replication Manager with your application is a star topology, shown in Figure 4. You should place the Design Master on a satellite computer along with Microsoft Replication Manager, but you should not have it on a synchronization schedule. (You, or the administrator at the site, can synchronize it with the hub replica when a structural change to the database is needed.) The replica on the hub becomes the synchronization partner for each of the other replicas in the organization. In addition to the Design Master and the hub replica, a base replica is used with the setup program to copy subsequent replicas to users' machines. After a copy is made on a user's computer and it is synchronized with the hub, the copy becomes a true replica with its own unique identification.
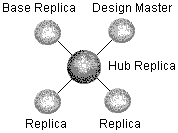
Figure 4: Star topology for distributing your application
For more information about setting up a customer site with replicated databases, see Microsoft Replication Manager online Help.
After you've converted a database into a replicable database, you can't convert it back to its former status as a nonreplicable database. However, if you no longer want to use replication and want to decrease the size of a replicated database, you can create a new, nonreplicable database that contains all of the objects and data in your replicated database without the additional system fields, tables, and properties associated with replication.
To make a nonreplicable database from a replicable one using Microsoft Access
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. Microsoft makes no warranties, express or implied, in this document.