When you begin to implement a distributed application on a real network, several conflicting design constraints become apparent:
With DCOM these critical design constraints are fairly easy to work around, because the details of deployment are not specified in the source code. DCOM completely hides the location of a component, whether it is in the same process as the client or on a machine halfway around the world. In all cases, the way the client connects to a component and calls the component's methods is identical. Not only does DCOM require no changes to the source code, it does not even require that the program be recompiled. A simple reconfiguration changes the way that components connect to each other.
DCOM's location independence greatly simplifies the task of distributing application components for optimum overall performance. Suppose, for example, that certain components must be placed on a specific machine or at a specific location. If the application has numerous small components, you can reduce network loading by deploying them on the same LAN segment, on the same machine, or even in the same process. If the application is composed of a smaller number of large components, network loading is less of a problem, so you can put them on the fastest machines available, wherever those machines are.
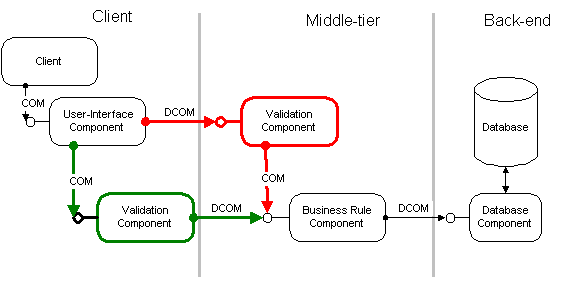
Figure 4 shows how the same "validation component" can be deployed on the client machine, when network-bandwidth between "client" machine and "Middle-tier" machine is sufficient, and on the server machine, when the client is accessing the application through a slow network link.
Figure 4 - Location Independence
With DCOM's location independence, the application can combine related components into machines that are "close" to each other onto a single machine or even into the same process. Even if a larger number of small components implement the functionality of a bigger logical module, they can still interact efficiently among each other. Components can run on the machine where it makes most sense: user interface and validation on or close to the client, database-intensive business rules on the server close to the database.