As the load on an application grows, not even the fastest multiprocessor machine may be able to accommodate demand, even if your budget can accommodate such a machine. DCOM's location independence makes it easy to distribute components over other computers, offering an easier and less expensive route to scalability.
Redeployment is easiest for stateless components or for those that do not share their state with other components. For components such as these, it is possible to run multiple copies on different machines. The user load can be evenly distributed among the machines, or criteria like machine capacity or even current load can be take into consideration. With DCOM, it is easy to change the way clients connect to components and components connect to each other. The same components can be dynamically redeployed, without any rework or even recompilation. All that is necessary is to update the registry, file system, or database where the location of each component is stored.
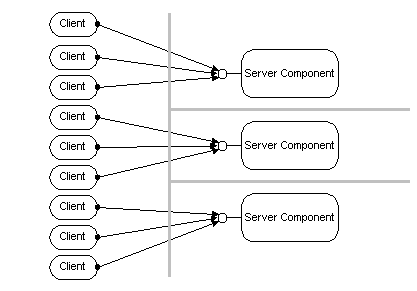
Example: An organization with offices in multiple locations, such as New York, London , San Francisco, and Sydney, Australia, can install the components in its servers. Two hundred users simultaneously access 50 components in a server with the expected performance. As new business applications are delivered to users, applications that use some existing business components and some newer ones, the load on the server grows to 600 users, and the number of business components grows to 70. With these additional applications and users, response times become unacceptable during peak hours. The administrator adds a second server and redeploys 30 of the components exclusively on the new machine. Twenty components remain exclusively on the old server, while the remaining 20 are run on both machines.
Figure 5 - Parallel Deployment
Most real world applications have one or more critical components that are involved in most of the operations. These can be database components or business rule components that need to be accessed serially to enforce "first-come, first served" policies. These kind of components cannot be duplicated, since their sole purpose is to provide a single synchronization point among all users of the application. To improve the overall performance of a distributed application, these "bottleneck" components have to be deployed onto a dedicated, powerful server. Again, DCOM helps by letting you isolate these critical components early in the design process, deploying multiple components on a single machine initially and moving the critical components to dedicated machines later. As explained in Section 0 of this paper, no redesign or even recompilation of the components is needed.
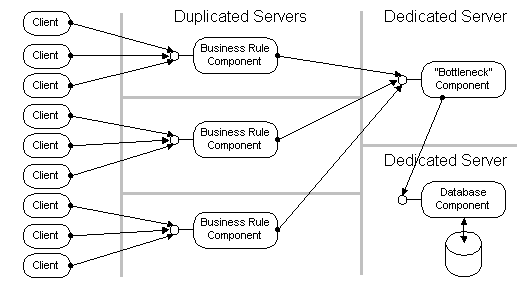
Figure 6 - Isolating Critical Components
For these critical bottleneck components, DCOM can make the overall task go more quickly. Such bottlenecks are usually part of a processing sequence, such as buy or sell orders in an electronic trading system: requests must be processed in the order they are received (first come, first served). One solution is to break the task into smaller components and deploy each component on a different machine. The effect is similar to pipelining as used in modern microprocessors: the first request comes in, the first component processes it (does, for example, consistency checking) and passes the request on to the next component (which might, for example, update the database). As soon as the first component passes the request on to the second component, it is ready to process the next request. In effect, there are two machines working in parallel on multiple requests, while the order in which requests are processed is guaranteed. The same approach is possible using DCOM on a single machine: multiple components can run on different threads or in different processes. This approach simplifies scalability later, when the threads can be distributed on a multiprocessor machine or the processes can be deployed on different machines.
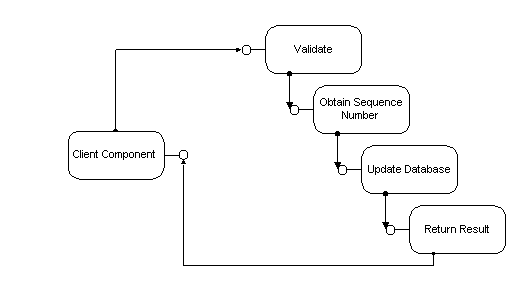
Figure 7 - Pipelining
DCOM's location-independent programming model makes it easy to change deployment schemes as the application grows: a single server machine can host all the components initially, connecting them as very efficient in-process servers. Effectively, the application behaves as a highly tuned monolithic application. As demand grows, other machines can be added, and the components can be distributed among those machines without any code changes.