
Presented by: Adam Shapiro
The goal of performance tuning is to provide acceptable response time per query by minimizing network traffic, reducing disk I/O, and minimizing CPU time to allow maximum throughput for the processing of all the users. This goal is achieved through a thorough analysis of the application requirements, an understanding of the logical and physical structure of the data, and the ability to assess and negotiate tradeoffs between conflicting uses of the database, such as online transaction processing (OLTP) versus decision support.
Response time measures the length of time required for the first row of the results set to be returned. Response time is usually referred to as the perceived time for the user to receive visual affirmation that a query is being processed.
Throughput measures the total number of queries that can be handled by the server during a given time frame.
As the number of users increases, contention between users increases, which in turn can cause response time to increase and overall throughput to decrease.
Performance can be measured by the amount of I/O required to process a transaction, the amount of CPU time, and the response time. Performance varies relative to each specific environment and is dependent on the application, the architecture and resources, the server, and the concurrent activities.

Memory: Sufficient RAM is crucial to the performance of SQL Server.
Processor: The number of processors, as well as their speed, directly impacts overall performance.
Disk: The number, speed, and type of disk drives, as well as the types of controllers used, affect performance.
Network: Concurrent network activity can impact the performance of SQL Server. The network bandwidth and data transfer rate are also important.

Threads: Adjusting thread priorities allows SQL Server to balance its needs with the needs of other services and with the needs of the Microsoft Windows NT® operating system itself. The number of threads allocated by SQL Server can have an impact on performance.
Paging file: The size, number, and location of paging files can have a major impact on system performance.
Services: Other services running on Windows NT will compete for resources needed by SQL Server. Shutting down unnecessary services can have a positive impact.
Disk Management: Windows NT has a number of disk management features such as striping and mirroring that can have an impact on performance. The impact might not always be positive.
Concurrent Activities: Other activities such as client programs and compilers can compete with SQL Server for CPU cycles, disk access, and network bandwidth.

Configuration: Many of the SQL Server configuration variables can have a direct impact on the server’s performance.
Locking: Contention for database resources (tables and individual pages) can cause processes to be blocked and have a major impact on overall performance in a multiuser system.
Logging: With the exception of specific non-logged operations, every modification to any database must be logged. The log writing itself can have a performance impact, and the transaction log (syslogs) can become a source of contention.
Concurrent Activities: Maintenance activities, such as backup and restore, DBCC, and building indexes, can interfere with production activities.

Logical and Physical Design: The level of normalization and/or denormalization can affect the performance of queries. Physical design includes the choice of indexes and will be covered in great detail.
Deadlock Avoidance: Repeated deadlocks can slow down an application. There are programming techniques that can reduce the likelihood of deadlocks occurring.
Transaction Control: Transactions, locking, and deadlocks are very closely tied together. The level of transaction control an application uses can have a major impact on the length of time locks are held and the overall throughput of an application.
Queries: The way that individual queries are written, including whether or not they are encapsulated in stored procedures, can determine whether an optimum plan is used for maximum performance.

User Requirements: The user’s requirements for modifications to be made and the queries to be run can have a major influence on the performance of the application.
Deadlock Handling: Client programs can react to SQL Server deadlocks in a variety of ways. The most efficient responses can greatly improve the client system’s performance .
Transaction Control: Transactions can also be controlled from the client application. In addition, some client applications can issue transaction control statements without the programmer or user being aware of it.
Cursors: There are a number of different ways that cursors can be defined and manipulated, each with a different performance impact.

Tuning for performance is more of an art than an exact science. The goal of tuning is to improve performance by removing the bottlenecks - whether they are related to I/O, CPU, or the network. This can be done through reducing the amount of system processing time by tuning the server, tuning the database, tuning the processes, and minimizing contention for data.
Add more hardware
Sometimes useful, although less expensive alternatives can often be found.
Tune SQL Server
Adjust configuration option values.
Tune the database
Resolve contention and concurrency issues
Tune the client application
SQL Server takes advantage of the enhanced capabilities of the Windows NT operating system.
Scaleable architecture
SQL Server can take advantage of Windows NT scaleability from notebook computers to symmetric multiprocessor super servers with support for Intel® and RISC (reduced instruction set computing) processors.
High capacity
SQL Server can address up to 2 gigabytes (GB) of memory, which is what Windows NT allows for user processes. Hard disk partition size can be approximately 17 billion GB (using NTFS).
Symmetric multiprocessing (SMP)
Windows NT is an SMP-capable operating system. It can run both operating system code and user code on any available processor. When there are more threads to run than processors to run them on, the SMP operating system also performs multitasking, dividing each processor’s time among all waiting threads.
SQL Server takes advantage of the multithreading capabilities of Windows NT. Instead of SQL Server implementing its own threading engine, it uses separate Windows NT – based threads to service each client. Windows NT automatically load-balances and schedules the threads among processors.
On SMP computers, you can use SQL Server to dedicate all CPU resources to SQL Server.
Single-process, multithreaded
SQL Server supports SMP at the thread level and benefits from Windows NT threading in the following ways:
Asynchronous I/O
Windows NT uses asynchronous I/O in which an application issues an I/O request and then continues executing while the device transfers the data. This differs from a synchronous I/O system, which does not return control to the application until the I/O request is completed. SQL Server takes advantage of the asynchronous I/O for Windows NT and provides higher throughput.
Uses Windows NT services
SQL Server uses Windows NT services for threading, scheduling, event notification, process synchronization, asynchronous I/O, exception handling, and integrated security.
SQL Server:

This performance tuning methodology provides a starting point to successfully tune a database for better performance. This methodology also serves as the framework for the topics included in this course.

The steps included in this methodology may be performed in a sequence that is different from the one listed here, or some steps can be eliminated, based on the database environment’s stage of production.

Tuning can be approached in two different ways.
In this course, you will learn how SQL Server accesses data, controls concurrent activities by multiple users, and interacts with the operating system. You can use that knowledge to plan your logical and physical design, configure SQL Server, plan your transactions, and write your queries to obtain optimum performance.
Alternatively, you could approach tuning as dealing with a specific problem. A query may be running slowly or throughput may be lower than necessary. You can gather information about the way SQL Server is behaving and make necessary adjustments to your query and the system configuration so that the optimum performance is achieved.
Both approaches are necessary. If you have a thorough knowledge of the server, the users, the data, and the processes, but no performance information, you will be unaware that your theoretically well-designed application is not performing as well as it could. Conversely, if you have all the performance metrics in the world, but no knowledge of the application or the server, you will be aware of your performance problems, but unable to solve them.

Objectives

Most queries fall into one of these two categories. Because their indexing issues can be very different, the two categories will be discussed separately.
Decision support systems
Decision support usually involves multiple search arguments and multiple tables. The queries can be quite complex, using aggregates, grouping, and the CUBE and ROLLUP operations. This is also sometimes referred to as online analytical processing (OLAP).
The queries might be arbitrary and unpredictable and use almost any column for specifying the desired rows.
The speed of retrieval and the return of results are the most critical aspects of these types of queries.
Online transaction processing (OLTP)
OLTP frequently involves only a single table and usually just a small number of rows are affected. For INSERTs, OLTP application transactions may just insert a single row.
With OLTP, the queries are often more predictable than with decision support.
The speed of data modification is the most critical aspect of OLTP queries.

Creating useful indexes
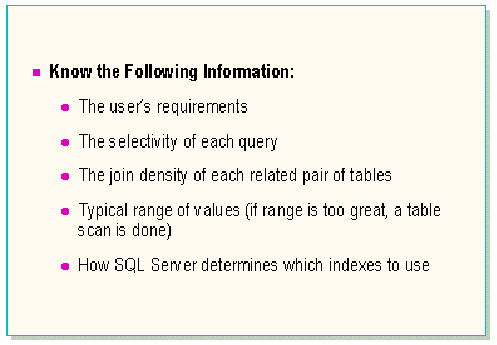
Creating useful indexes is probably the most important thing that can be done to improve performance. The type and number of indexes and the columns to index should be selected carefully based on a thorough understanding of the user’s needs and the data itself. Indexes are useful whether you are simply querying the table or performing data modification. In either case, indexes can provide faster access to data for either read or write purposes.
User analysis
Understand the user’s demands of the data and the types and frequencies of queries that are typically performed. Having a thorough understanding of the user’s needs helps to determine the tradeoffs that you most likely will need to make. In balancing the performance of the most critical queries, you might have to sacrifice some speed on one query to gain better performance on another.
Data analysis
Understand the data and how it is organized in both logical and physical design.
Understand how SQL Server works
The more thoroughly you understand how Microsoft SQL Server works, the better you can design the system and make intelligent decisions. This includes understanding how SQL Server stores and retrieves data and how the query optimizer selects the most efficient execution plan.
General considerations
Selectivity

Estimating the results set is helpful in selecting the types of indexes to create on a table for a given set of transactions.
The selectivity of a query is the percentage of rows in a table that is accessed by a SELECT, UPDATE, or DELETE statement. High selectivity can return one row that meets the search criteria. Low selectivity is not as discriminating and can return a majority of the rows in the table.
A related concept is density, which is the average percentage of duplicate rows in an index. An index with a large number of duplicates has high density. A unique index has low density.
Table scans
Scanning the table is advantageous for queries where the results set includes a high percentage of a table (low selectivity).
Distribution of data
The distribution of data indicates the range of values in a given table and how many rows fall in that range. In many cases, one can approximate the percentage of data to be returned in a results set. For example, if the criterion is male/female, the results set for females can be estimated at 50%.
You can determine the distribution of a column with a query like the following:
SELECT column, count(*) FROM table GROUP BY column
Selectivity: Example
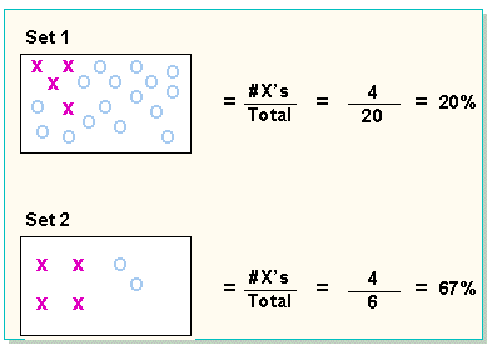
In the above example, both sets have the same number of X’s, yet the percentage of X’s (selectivity) is different.
Estimate the selectivity of these queries (assume there are 10,000 rows in the member table and member numbers are in the range 1 – 10,000, all unique values):
Join density
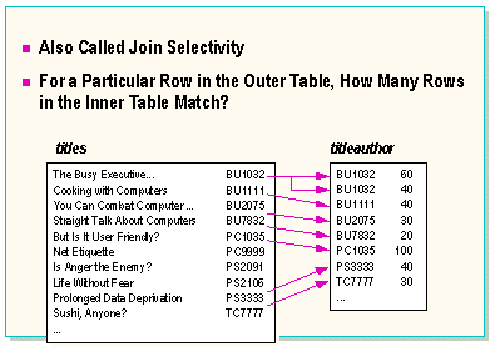
Join density is the average number of rows in the inner table that will match a row in the outer table. Join density can also be thought of as the average number of duplicates.
A column with a unique index would have a low density and a high join selectivity. If the column has a large number of duplicates, it has a high density and is not very selective for joins.
Indexes on the join column will only be useful on the inner table of a join. If the join density were low, either type of index would be useful. If the join density were high, only a clustered index would help.

Good candidates for clustered indexes

Considerations
The column that is used for the clustered index determines the data’s physical order. Place a clustered index on the columns of data that are most often needed in physical order.
Indexes should be chosen based on the types of SELECT statements used.
Clustered indexes are recommended for foreign keys, because foreign keys are generally non-unique.
There can be only one clustered index per table.
Note Placing a clustered index on the primary key (especially if the data is monotonic) is rarely the best choice. The primary key should have a unique index. A nonclustered unique index can be almost as efficient as a clustered unique index in many cases.
Good candidates for nonclustered indexes

Add nonclustered indexes only when they are really helpful, because significant overhead is required to maintain these indexes during data modification.
Do not create an index if it will not be used.
Considerations
Good candidates for composite indexes

A composite index may be an index with a multicolumn sort key. Either a clustered or nonclustered index can have a composite key.
Considerations
For example, an index on (lastname, firstname) is good for selecting lastname and lastname, firstname, but is not good for selecting firstname.
Composite vs. multiple single-column indexes

Note The order in which columns are specified in the WHERE clause doesn’t affect how composite indexes are used. It only matters that the leftmost column in the composite index is contained in the WHERE clause.
A composite index can be used even if the high-order (leftmost) column in the index sort key is not in the WHERE clause. This situation requires that all columns referenced in the SELECT list and WHERE clause are in the index sort key. See covering indexes (next) for details.
Covering indexes

Considerations
Clustered vs. nonclustered indexes


Indexing for a range of data: Example

No index on Table
A table scan (53,000 I/Os) is more efficient than a nonclustered index.
Clustered index on price column
This search requires reading 10,000 pages (190,000/19 rows per page).
Nonclustered index on price column
Covering index on price, title columns
Indexing for ANDs: Example

Walk through the example on the slide. Use the choices listed in the student notes to evaluate the best type of index to create for this statement. Number 4 is the best choice, because all the qualifying rows would be together. Choice number 6 would cover the query. However, the index would be larger, because of the wide key. Choice number 7 is the same as a clustered index on dept, except that the index is much bigger.
A common misconception is that the order in which columns are listed in the WHERE clause affects how composite indexes are used. This is not true. It only matters that the leftmost column in the composite index is in the WHERE clause.
You might also note that we are assuming a relatively normal data distribution. If everyone or no one earned > 50000, or if the whole company was in research, our indexing strategy might be different.
If both of the conditions are met, the row fulfills the search criteria.
Choices to evaluate for the example above
Indexing for ORs
ORs are a very different situation from ANDs.
Multiple conditions ANDed together provide a progressively stricter qualification of the desired data. Given the set of all the rows that satisfy one of the AND conditions, the final result rows will be in that set.
With OR conditions, this is not true. Given the set of all the rows that satisfy one of the OR conditions, there may be rows that satisfy another one of the OR conditions that are not included in this set of results.
ORs will be covered in much more detail later in this course.
Indexing for SELECT *: Example

SELECT * returns information from all of the columns.
The choice of index has nothing to do with what is selected. It is significant only with what is being qualified. The index helps to locate rows. It does not affect what information is selected from a row. A SELECT * cannot be covered by a nonclustered index unless all the columns are in the sort key.
The SELECT * is not the best type of query to use for high performance if it means that you are retrieving more data than you actually need.
Choices to evaluate for the example above
Indexing for multiple queries

In the previous examples, the best type of index was selected based on an individual query. Indexing for multiple queries is more complex, because the optimal index for one query may not be the optimal index for another. The goal is to attain acceptable performance for all the highest priority queries.
Choices to evaluate for the example above
Assumptions: Query 1 is 15% of the table. Query 2 is highly selective; one row is accessed.
Choice 1
Query 1 is very fast. Query 2 is fast, but requires one more I/O than if a clustered index were placed on the title column.
Choice 2
Query 1 is slower than in Choice 1. Query 2 is very fast.
Choice 3
Query 1 runs fast, and Query 2 is very fast.
Choice 4
This is the best option. Query 1 and Query 2 are both very fast.
Update considerations

Online transaction processing (OLTP) queries do include some aspects of data retrieval in that you must first find the rows before you can modify them. However, if your most important queries are OLTP queries, there are some additional issues to consider:
Guidelines

Index maintenance

Clustered indexes
If there is a clustered index on a table, rows must be inserted in the order of the clustered index key. If there is no room on a page, the page may need to be split, generating additional overhead.
Nonclustered indexes
A nonclustered index has a pointer to every row of data. Any time a row is inserted or deleted, every nonclustered index must be adjusted.
If an UPDATE is a full DELETE/INSERT or a deferred UPDATE, every nonclustered index must be adjusted for both the rows deleted and the rows inserted. Even if an UPDATE is in place or on the same page, any indexes on any columns that are changing will need to be adjusted. If you have wide composite indexes, this in itself could be a lot of overhead.
Guidelines for creating indexes

Determine the priorities of all the queries
Determine the selectivity of each query
Chart the activity on each table
Determine the columns that should be indexed
If a column is never referenced in the WHERE clause of a query or data modification statement, there is no reason to create an index on that column.
Creating an index on a column that is used as a join key improves the performance of the join, because it gives the query optimizer the option to use an index rather than performing a table scan.
Choose the best candidate column for a clustered index
Determine what other indexes are necessary
Determine the types of nonclustered indexes to create
Test the performance of the queries
When not to index

There are situations when you will not want to index. These include:
Balancing DSS with OLTP
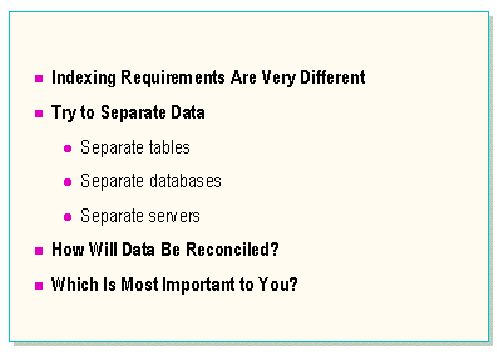
Because the indexing requirements are very different for DSS and OLTP environments, indexing strategies can be very difficult to determine if both environments are necessary.
Separate copies of the data can be kept so that retrieval and modification are not performed on exactly the same data. In this case, a strategy for reconciliation of the data will be necessary. The costs and benefits of being able to index optimally for the two different environments will have to be weighed against the costs of maintaining and reconciling two sets of data.

The SQL Server query optimizer decides if an index truly is a good index, and for any particular query, which index is the best one to use. The optimizer also decides how to process joins of multiple tables, selecting an order of tables and a method. It also determines the best way to carry out update operations.
In the next module, the details of how the SQL Server optimizer takes the information it has available and uses it to determine an optimum execution plan will be discussed.
© 1997 Microsoft Corporation. All rights reserved.
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY.
Microsoft and Windows NT are registered trademarks of Microsoft Corporation. Intel is a registered trademark of Intel Corporation.
Other product and company names listed herein may be the trademarks of their respective owners.