Presented by: Yair Alan Griver
Yair Alan Griver is Chief Information Officer at Flash Creative Management, a database development and management consulting firm based in Hackensack, NJ. Flash, a Microsoft Solution Provider Partner and Authorized Technical Education Center, is a three time Inc. 500 company, that specializes in client/server database development, designs and installs custom software solutions and offers training classes in Microsoft® Visual FoxPro®, Microsoft® SQL Server™ and Microsoft® Visual Basic®.
A Contributing Editor to Data Based Advisor and FoxPro Advisor magazines, Alan has written articles and been quoted in many industry journals. He has spoken at the Fox Developers Conference, Borland Database Conference, DB/Expo, Business Software Solutions, Windows & OS/2 Conference and Database World in addition to providing training around the world
Alan is author of The Visual FoxPro 3.0 Codebook, published by Sybex. This book discusses a methodology for developing robust applications, and provides an object oriented framework for these applications.
Phone: (201) 489-2500
Email via CompuServe: 71541,3150
Ubiquitous and fast connectivity is just around the corner. As a result, database systems are shifting from single-server, two-tier, local area network (LAN)-based, departmental systems to a new form of client/server where every machine on the Internet can be both a client and a server. As a response to this, many of today’s developers are implementing three-tier type applications using OLE services. These are generally comprised of user interface (UI), business and data services, each of which is applied along logical boundaries. A critical component of this three-tier architecture is the business services that consists of reusable business objects which define the corporations processes and rules. This session focuses on this aspect of three-tier development, including various approaches to developing and deploying business objects in Visual FoxPro.
In a word, scalability. A multi-tiered logical model allows you to scale your application as needed, going from single machine to multiple machines communicating over the internet. Let’s look at how this works:
In a two-tier system, you place the interface on one machine, the data on another, and then decide where to place the business rules: on the front end or the back end. Fat client systems, in which you place the rules on the front end, use field level validation functions. Fat server systems use the back end’s stored procedures and triggers in order to validate the data as it is being saved.
There are problems with both approaches. A fat client requires a very robust machine, and makes updating the software difficult, since every business change requires shipping new software to each client machine. A fat server, on the other hand, has to be upgraded regularly as new users come on line, stressing the limits of the hardware.
A logically three-tiered design is one in which an application’s implementation is divided into three logical areas-user, business and data. This segmentation allows developers to introduce flexible layers between databases and the applications that use them. Each tier is responsible for a different task, and when put together, they form a cooperating system that is flexible and robust.
Items in the data layer are primarily responsible for the locating and storing of data. Typical examples of these items would be a relational database, any stored procedures contained in it, and anything that deals primarily with data access, like a customer searching component. The data layer worries about things like data persistence, recovery, and consistency, and is not involved in implementing any business-specific rules.
Object ins the business layer, on the other hand, are responsible for implementing business-specific rules. They interact with data services to retrieve and store data, but they add the functionality of applying business rules. Typical examples of business objects include components that do tax calculation, validation of customer information, and automation of a business process (when a customer is saved, e-mail a certain manager). Business services are non-visual, and are updated as frequently as a business changes.
The UI layer includes objects that are the visual part of an information system. These objects are responsible for displaying data to the user, allowing the user to manipulate that data, and communicating with business services to validate data that is dependent on business rules. Examples of objects in this layer are the controls and forms used by an application as well as any calls to the Windows MESSAGEBOX function.
A three-tier system is more scalable, robust and flexible. Once you have your logical separation, you can place each layer on one machine or multiple machines, as your company grows. In a physically partitioned system, the client machine contains a thin graphical user interface (GUI) layer, which can run on lower end machines (for instance, using a Web Browser), the database resides on its server, worrying only about serving data and handling backups, and the business logic resides on either of these machines, or on their own server. The front end and the database talk only with the business layer, which mediates between the two. In this way, you can integrate data from multiple sources, change business rules as needed, and use the Web, without having to change hardware at the client.
In fact, with a three-tier model, we no longer create applications, we model our business, with front ends that provide entry points into our business. This is how we end the application backlog-we stop writing applications.
In focusing on the business layer of our three tiers, we need to look at what this layer contains. In simple terms: the business layer contains an object model of our business. In other words, if we have an invoicing process, that process should be available as objects and methods in our business layer. It should match what we do. If an aspect of our business changes, it should be easily traced to the code that matches that aspect, allowing us to quickly implement that change across all of our systems.
Let’s look at an approach to modeling our business processes, finding the classes and ensuring traceability from the initial model to the code. We’ll use Use Cases to begin our analysis and move to CRC cards to design our classes.
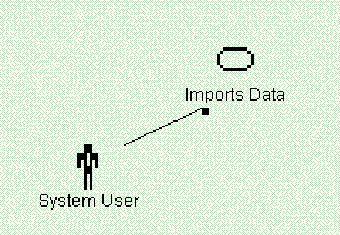
During discussions with the client, we build “use cases.” These are drawings and text that allow us to formally define what is to occur. A use case is composed of an “actor” (the person or thing that causes the chain of events to occur) and a “use case” (the process that occurs). In fact, a use case is very similar to a cause and effect diagram or a process chart. Something happens, which causes some process to occur that has an output.
We draw the use case and under it place a description of the output. I recommend placing the usual output first as the primary use case. Secondary occurrences can go underneath it. In this way, you can optimize the User Interface of your dialogs to work most cleanly with the primary occurrence.
In our case, we have one use case:
Primary case
In showing this to the user, we can ask them questions like:
We discover that if any data is bad, we want to print the bad data and cancel the entire import. We also learn that the import may be from other file types due to the upcoming merger possibilities. Finally, the users mention that they’d love to be able to add expense information in the future. Our use case description now looks like this:
Primary case
Secondary cases
If the data is incorrect, cancel the import and print an “incorrect data report.”
The use case allows us to focus in on the interface requirements of the system. In our case, our design may look like this:
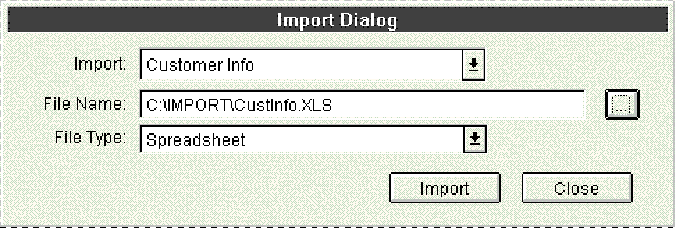
Notice that the design falls immediately out of the use case-we can optimize for the usual occurrences. In an order entry system, for instance, the use case description may be:
Primary case
Secondary cases
Add the customer name and address
Modify the customer address
Select another payment type
Note how this can be used to streamline UI design. It doesn’t matter if we’re talking about a paper system, computer front end, a web page, or an automated phone ordering system. The steps are standardized for all methods of entry. In designing a computer front end, we would focus on the primary case, using the secondary cases as alternates.
I’ve seen systems of this sort that make the customer address “live” in order entry. This is wonderful for the case where you have a new customer, or the customer has a new address. However, in the above case, 80% of the time this won’t occur, but will force the data entry operator to tab multiple times through the address information (even more if you have both a billing and shipping address) in order to enter an order. You’ve designed a UI for every eventuality, slowing down the one that usually occurs! Having a button that allows entry into the other section would allow the system to display the extra address information, but would allow for fast entry of the customer number, followed immediately by order entry.
Now that we have the use cases and the interface completed, let’s take a look at designing the classes that may be involved. To do this, we’ll use a simplified version of Class-Responsibility-Collaboration (CRC) Cards. These are regular index cards which contain information about a class (one per card) and which classes it collaborates with in order to fulfill its responsibilities.
We begin by grabbing the nouns from our Use Case descriptions. These become our candidate classes.:
Nouns:
| User | File |
| Import type | Spreadsheet |
| Customer | Selected file |
| Employee | Incorrect data report |
| Timesheet | Future additions |
We throw out any classes that we know we don’t want to model, and close up duplicates. We also create some simple hierarchies if we find them in our list. In this case, we throw out “user” because we aren’t going to be modeling the user as a class. We also look at “future additions” to see what it means and find out that it, like “customer”, “employee” and “time sheet” are types of imports. So we create a hierarchy for “import type” that includes “customer”, “employee” and “time sheet” knowing that we can further subclass “import type” in the future.
Looking at “file”, “spreadsheet” and “selected file”, we see that they are all related. We probably want a “file” class that is subclassed into “spreadsheet” and whatever else may come along. Finally, an “incorrect data report” is a type of report, so we’ll probably want to have a hierarchy there as well. Our candidate list now looks like this:
Nouns:
Import type Customer Employee Timesheet File Spreadsheet Report Incorrect data report
We continue by grabbing the verbs that describe our system. These will be candidates for “responsibilities” which we will then match to our classes.
Verbs:
selects is imported cancel print
We throw out “selects” because that is a user action. The “cancel” is tied to an import type class (that is what we are canceling) and “print” is tied to the report class. The “is imported” verb is a tricky one. It can be tied to the import type class because each type knows how to import itself, but it can also be tied to the file class which should know how to handle its type of file. In fact, we have a responsibility that should probably be broken up into two: the import type class should know how to verify itself (in other words, know if the data is correct and where it goes), while the file class should know how to pass its data to whoever requests it. Bingo! We’ve got a collaboration here.
We then assign methods and properties for any responsibility. (Here I did that for the Import class.) Looking at our classes now, we see:
Classes:
Import type Subclasses: Customer, Employee, Timesheet Responsibilities: Verify itself, Import itself, Cancel itself Collaborates with: File (to get data), Incorrect data report (upon cancel) Methods: Import (Public) - Starts the whole shebang CheckFileExists (Prot) - See if the file to be imported exists AppendToTemp (Prot) - Works with “File” to get a temp file CheckTemp (Prot) - Checks that the temp file is correct AppendToFinal (Prot) - Appends the data to the main file Cleanup (Prot) - Does any final operations Properties: cFileName - The name of the input file File Subclasses: Spreadsheet Responsibilities: Pass data Report Subclasses: Incorrect data report Responsibilities: Print itself
Reviewing this hierarchy, we can see that adding a new type of import (like Expenses) would simply require subclassing the “import type” class, with no application changes. Changing an import to work with a mainframe comma delimited file would require a new subclass of the “file” class, and once again, would not affect the application.
In order to trace from the Use Case down to the CRC and finally to the code itself, we number each Use Case and CRC card. We place the number of every CRC card that was derived from a Use Case on that Use Case, and place the number of the Use Case on the derived CRC Card. The CRC Card includes the name of the class and its methods, allowing us to trace to the code.
When a business change is made, we simply go over the Use Cases with our users, noting what has changed, find the appropriate CRC Cards, make the necessary design changes, and finally modify the code to implement the business change in our classes. In this way, our documentation stays current with our code, easing future maintenance as well!
Once we have our classes designed in our CRC cards, we have a “blueprint” for each class and its public interface. In other words, we develop according to the CRC, adding any additional protected or private properties and methods that may be necessary to implement the class (for instance, we may need some properties to save state information).
Review each class to ensure that its public interface is easy to understand. Use standard terms for method names, even creating multiple internal methods that have a single entry point that calls them in order. For instance, in the above import routine, the public interface is the method import(). However, it calls multiple protected methods that each do one function. This is a good general rule: each method should perform one (and only one) function. You may have a method that automates a process by calling multiple methods, but then that process method is also only doing one thing-detailing a process.
One other option is to create a business object that contains all of the information for modeling something in the real world, and then creating role and process objects that automate the roles and processes that happen in the business. These role and process objects are used by the UI front ends, while the business is used only by the role or process object.
For example, you may create a Part object that knows how to keep track of how many parts are available, how to build itself from other parts, how to reorder itself, where it is located, etc. You can then create an Inventory Role object that queries reorder information, minimum information, and location information.
One implementation issue to remember is that you cannot pass parameters to OLE objects upon instantiation, so don’t set up your business objects to expect a parameter.
Once the business objects are created, they can be deployed in any format that you require. You can bind them into one executable with their interface and data objects by placing them all in a single project. This works well on smaller systems that are to be physically deployed on one machine or a small departmental LAN.
As the LAN grows, you can separate the business objects into their own project, and place them on another machine, accessing them automatically through DCOM (Distributed OLE) or Remote OLE Automation. Visual FoxPro does all the work-all that is necessary is that you compile them separately and register them on the other machine with DCOMCFG or another tool of that sort.
Visual FoxPro’s strong object-oriented capabilities have been greatly enhanced through the integration of DCOM and Remote OLE Automation. Creating your business objects as separate classes in their own logical layer will allow you to have your applications grow as your business does.
© 1997 Microsoft Corporation. All rights reserved.
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY.
Microsoft, Visual FoxPro, and Visual Basic are registered trademarks and SQL Server is a trademark of Microsoft Corporation.
Other product or company names mentioned herein may be the trademarks of their respective owners.