Glossary
Unicode originated through collaboration between Xerox and Apple. An informal think tank of several companies formed; others, including IBM and Microsoft, rapidly joined. In 1991, this group founded the Unicode Consortium. Its membership now includes such companies as Apple, AT&T, Compaq, Digital, Ecological Linguistics, Hewlett-Packard, Hangul & Computer, IBM, Lotus, Microsoft, NeXT, Novell, Reuters, Software AG, Research Libraries Group, Sybase, Taligent, Tandem, and Unisys.
The Unicode Consortium published the Unicode Standard, version 1, in 1990. At that time, the International Standards Organization was completing a similar encoding, ISO 10646. Concerned that two standards was one too many, the Unicode Consortium and the International Standards Organization worked together from 1991 to 1992 to merge the two. Unicode 1.1 and ISO 10646, both published in 1993, are identical code-for-code. In 1994, China and Japan began working on national standards based on ISO 10646. Unicode is now starting to appear in retail products—for example, Microsoft's Windows NT, Apple's Newton MessagePad, Novell's NetWare 4.01 Directory Services, and Sybase's Gain Momentum development environment.
If you plan to support Unicode in your software, make sure to get The Unicode Standard, Worldwide Character Encoding, Version 1.0, Volumes 1 and 2, published in book form by Addison-Wesley. The MSDN Developer Library (Level 1) includes the update document, The Unicode Standard, Version 1.1, which you'll need as well. The update can also be obtained from the Unicode Consortium. (A single-volume edition of The Unicode Standard, Version 1.1, is currently in preparation.)
The complex programming methods required for working with characters of mixed-byte lengths (as we saw with DBCS), the involved process of creating new code pages every time another language requires computer support, and the importance of mixing and sharing information in a variety of languages across different systems were some of the factors motivating the creators of the Unicode standard.
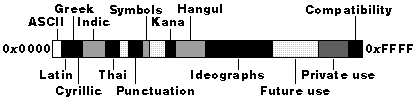
Unicode encompasses virtually all characters used widely in computers today. This includes most of the world's written scripts, publishing characters, mathematical and technical symbols, geometric shapes, basic dingbats (including all level-100 Zapf Dingbats), and punctuation marks. Some 35,000 code points have already been assigned characters; the rest have been set aside for future use. In addition to modern languages, Unicode covers languages such as literary Chinese, classical Greek, Hebrew, Pali, and Sanskrit. A private-use zone of 6500 locations is available to applications for user-defined characters, which typically are rare ideographs representing names of people or places.
In abstract form, Unicode's encoding layout looks like the one shown in Figure 3-8.
Figure 3-8 Unicode's encoding layout.
Encoding standards possess limited real estate and must conserve code points. Unicode rules, however, are strict about code-point assignment—each code point represents a distinct character. A character is an abstract concept, defined in The Unicode Standard, Volume 1, as "the smallest component of a written language that has semantic value." If a semantic value cannot be expressed in plaintext using an existing character, a distinct Unicode code point is assigned to a new character. A comparison of the way in which characters are treated in ASCII and Unicode illustrates this concept. In ASCII, an individual symbol such as a short dash (-) is often used to represent any of several distinct characters: a hyphen, a nonbreaking hyphen, a minus sign, or an en dash. In contrast, a Unicode value refers to only one character unless the Unicode character exists for compatibility with standards such as ASCII—for example, U+002D (the "hyphen-minus"). In Unicode, the hyphen and the minus sign also have distinct code points, and the Unicode standard depicts them as having slightly different widths. There are numerous other examples. The Unicode Standard, Volume 1, lists approximately one dozen space and dash characters, each with a slightly different appearance and meaning.
There are also many cases in which Unicode deliberately does not provide code points because to do so would be repetitious. Examples are font variants (such as bold and italic) and glyph variants, which basically are different ways of representing the same characters.
The Unicode standard also does not distinguish characters on the basis of minor differences in semantics. For example, a comma can be used either as a list separator or as a thousands separator. In both cases it is a separator and so doesn't warrant two separate code-point assignments. Nor does the Unicode standard distinguish on the basis of pronunciation (an ideograph as used in Japanese vs. the same ideograph as used in Chinese or Korean) or meaning (q as a Greek character or q as a mathematical symbol). As noted before, some exceptions have been made when necessary to accommodate one-to-one round-trip conversions between Unicode and other preexisting character-set standards (most notably, compatibility-zone characters), but on the whole the Unicode standard contains only one instance of each character. The Unicode standard assigns a unique name and code point to each character. It also provides alias information (for example, = ess-zed) and cross- references to other characters. (See Figure 3-9.)
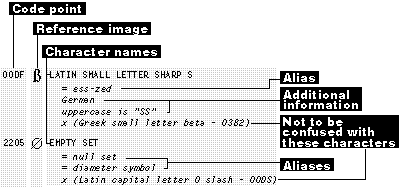
Figure 3-9 Two typical Unicode standard descriptions.
For the most part, Unicode defines characters uniquely, but some characters can be combined to form others, such as accented characters. The most common accented characters, which are used in French, German, and many other European languages, exist in their precomposed forms and are assigned code points. The same characters can be expressed by combining a base character with one or more nonspacing marks. For example, a followed by a nonspacing accent mark (`) is displayed as à. Nonspacing accent marks make it possible to have a large set of accented characters without assigning them all distinct code points. This is useful for representing accented characters in written languages that are less widely used, such as some African languages. It's also useful for creating a variety of mathematical symbols. The Win32 API function FoldStringW maps multiple combining characters into precomposed forms. Since the precomposed characters exist primarily for compatibility with other encodings, the Unicode standard considers them as semantically identical to composite characters. (See Figure 3-10.)
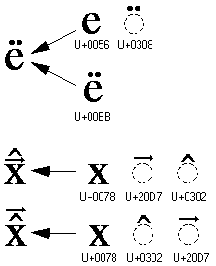
Figure 3-10 Precomposed and composite characters.
Limitations and Capabilities of Unicode
Glossary
For all its advantages, Unicode is far from a panacea for internationalization. The code-point positions of Unicode elements do not imply a sorting order, and Unicode does not encode font information. Microsoft Win32–based applications need to obtain sorting and font information from the operating system. Basing your software on the Unicode standard is only one step in the internationalization process. You still need to write code that adapts to cultural preferences or language rules. (See Chapter 5.) Some Win32 API functions incorporate Unicode information, but most are based on linguistic research conducted by Microsoft.
Unicode doesn't help with complex text-based operations
Not all Unicode-based text processing is a matter of simple character-by-character parsing. Complex text-based operations such as sorting, hyphenation, line breaking, and glyph formation need to take the context of a character into account. The complexity of these operations hinges on language rules and has nothing to do with Unicode as an encoding standard; in general, Unicode doesn't help with these operations.
Unicode provides characters that simplify text layout
There are, however, exceptional characters that have very specific semantic rules attached to them; these are detailed in The Unicode Standard, Volume 1. Some always allow a line break (for example, most spaces), whereas others never allow a line break (for example, nonspacing or nonbreaking characters). Other characters, including many used in Arabic and Hebrew, are defined as having strong or weak text directionality. The Unicode standard defines an algorithm for determining the display order of bidirectional text, and it also defines several "directional formatting codes" as overrides for exceptional cases to help create comprehensible bidirectional text. These formatting codes allow characters to be stored in logical order but displayed appropriately depending on their directionality. Neutral characters, such as punctuation marks, assume the directionality of the strong or weak characters nearby. Formatting codes can be used to delineate embedded text or to specify the directionality of characters. Arabic and Hebrew editions of Windows 3.1 adopted the Unicode standard's bidirectional algorithm with slight variations. (For more information on displaying bidirectional Unicode-based text, see The Unicode Standard, Version 1.0, Volume 1, Appendix A; and "Unicode 1.0.1" in Volume 2, page 2. See also the update document for Unicode version 1.1.)
Unicode does not significantly increase file size
Some developers worry that basing their software on Unicode will cause their files to double in size. In fact, Unicode rarely makes files twice as large as they would be under an 8-bit standard. Although English plaintext data would double in size, the bulk of most major applications consist of files in a binary file format, not in a plaintext format. Also, as applications become more sophisticated and work more with rich file types such as audio and video, file sizes will grow regardless of the text storage format.
Even when you're dealing with Unicode plaintext, it's possible to limit file size growth to less than 50 percent by using schemes for file and disk compression, including those supported by Windows. Information theory indicates that data expressed in Unicode can be compressed to the same size as corresponding 8-bit text. For more information on compression, consult the proceedings of the Unicode Implementers Workshops, available from the Unicode Consortium.
Some tools, such as ANSI C and Visual C++, support wide characters as data, but not as source file text. Therefore, the size increase of most Unicode-based program executables is negligible. For the large percentage of programs that are mostly code, executables are unlikely to double in size even if all message text and user interface strings are converted to Unicode.
Keep in mind that with Unicode you are trading larger files for more efficient code, especially in the case of Far Eastern languages and multilingual support. Since ideographic characters already take up 2 bytes in DBCS code pages, you won't see much difference in file size by switching to Unicode if your code must handle Far Eastern languages.
Unicode is not currently supported in many applications and fonts
Another area of concern for end users and developers is the availability of applications and fonts that support Unicode. The Windows NT Unicode Sans Lucida font (L_10646.TTF) supports 1300 Unicode characters, including Cyrillic and Greek characters, and a large collection of mathematical symbols. Other fonts, such as the Console font, contain about 600 Unicode characters. Microsoft is working on creating additional fonts that cover a large repertoire of characters, as well as on font technology that will allow fonts containing different characters to be combined. A number of font vendors are currently offering Unicode-encoded fonts. Information on software that supports the Unicode standard is available from the Unicode Consortium.