There is a way for applications to access file data that is even faster than using the file system cache. By mapping a file directly into its address space, an application can access the data in the file like an array and need never call the file system at all. This avoids all the overhead associated with the file system call and the search of the cache. The next table shows our little laptop's performance while accessing the file as we did earlier in the chapter, this time adding memory mapping as an access mode. The times shown are
Table 6.2 Memory Mapped vs. File I/O Times in Milliseconds per Record
Type of file access | Operation | Non-cached time | Cached time | Mapped time |
Sequential | Read | 6.58 | 1.32 | 0.75 |
Sequential | Write | 22.91 | 1.70 | 0.64 |
Random | Read | 20.45 | 1.51 | 0.97 |
Random | Read/Write | 40.66 | 3.16 | 1.31 |
|
File activity just doesn't get any faster than that! But memory mapping of files is not always advisable. For one thing, you'd have to recode an existing application to get rid of all those old-fashioned file system calls. Although the resulting code would be simpler, you must weigh this against taking the time and effort to recode an existing application. Another tricky tradeoff occurs when access is strictly sequential; the cache uses much less memory to read the file, as we have seen. Also, using memory mapping means that you lose access to the file system synchronization modes such as file locking or the more exotic opportunistic locking. This means that any multiple writers of the file, whether they be threads inside a process or multiple processes sharing the file, must coordinate their access using mutexes. And if there is any possibility that the file might be remotely accessed by multiple processes which are writing to the file from different computers, you must invent an inter-process synchronization mechanism which might obviate the performance advantage you got from memory mapping in the first place.
In cases where you decide to map files into memory, it's a clear winner in speed. Performance Monitor uses memory mapping for accessing the log file when it is reading it for reprocessing. Because access to the file might be random, this is just the sort of task which benefits from memory mapping. Conversely, output of log files is done through the normal file system calls because the cache can detect the sequential nature of the output and can therefore use memory more efficiently writing files created in this fashion.
The principal difference in the behavior of the system between using mapped and unmapped files is that mapped files go directly into the working set of the process, while, as we have seen, buffered files go into the "working set" of the file system cache. When a process maps a file into its address space, it might use quite a bit of RAM to hold the file. But from the memory manager's viewpoint, it really doesn't make too much difference whether the working set of the process or the working set of the cache gets the page that's faulted in. The real elegance of the memory management scheme on Windows NT is exemplified in this point, which is illustrated by the next experiment.
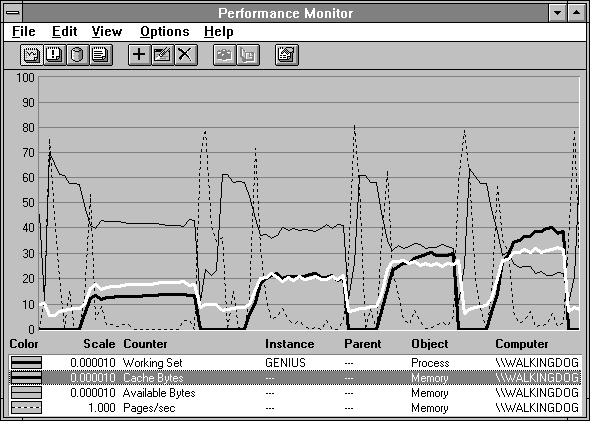
We start two processes, each accessing a file with normally distributed record access. First the distribution covers 1 MB, then 2 MB, 3 MB, and so on up to 8 MB. One process reads the file using the file system calls, and the other maps the file into its address space. The results are displayed in the next two charts. The first four trials with working sets from 1 to 4 MB are shown in Figure 6.19, and the next four trials with working sets from 5 to 8 MB are shown in Figure 6.20.
Figure 6.19 Competing processes using mapped and file system reads
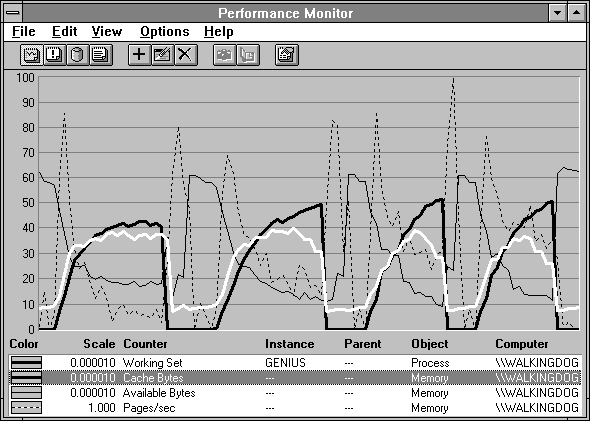
Figure 6.20 More competing processes using mapped and file system reads
In the beginning, the highlighted cache has a slight size advantage, but as the working sets get larger, the process in heavy black begins to get ahead. The thin black line shows Available Bytes declining, and the dotted line shows that Pages/sec are rising as the experiment progresses. By the time the normal distribution covers 8 MB, the paging rate on this laptop is shaking it right off your lap.
These charts seem to indicate that the memory manager is favoring the process's working set over that of the cache. To some extent this is true. In general, the code and data referenced directly by processes is more crucial to good application performance than the file data in the cache. The cache tends to get the space not needed by processes. It certainly gets any unused space, as we saw when it took pages trimmed from inactive working sets. When processes are active, however, they tend to do a bit better than the cache, as in this case. But the result is not overwhelmingly in favor of the process, as the next figure shows.
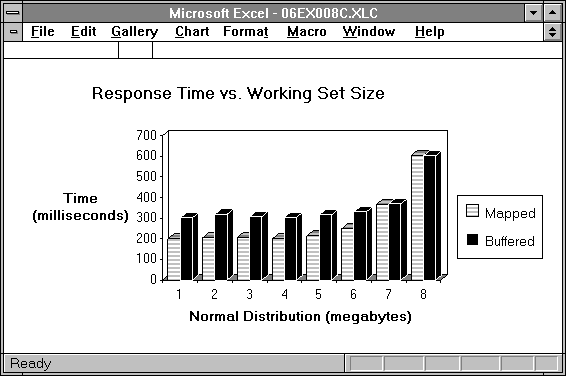
Figure 6.21 Response time for mapped and buffered competing processes
Figure 6.21 shows each process's response time as measured by Response Probe during this experiment. The mapped access is faster in the beginning, as we saw in Table 6.2. Then, as the paging increases, and disk access time becomes a significant component of the response time, the two processes' performance evens up. The fact that the working set of the process doing mapped access is a bit larger is not a significant advantage. This indicates that the policy of the memory manager is perfectly balanced.
In the next chapter we discuss how you tune memory manager to favor either the cache or the application in specific circumstances.