Because retrieving and updating data are the main operations of most database applications, performing these operations quickly speeds up the entire application. This section offers suggestions for designing the most efficient tables and queries and for writing code that updates records quickly.
See Also For information on optimizing data retrieval and updates in client/server applications, see Chapter 19, “Developing Client/Server Applications.”
A well-designed database is a prerequisite for fast data retrieval and updates. Take time to plan the design of your database carefully. Determine which tables, fields, and relationships your database needs to operate efficiently and accurately.
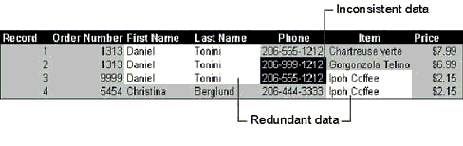
If existing tables in your database contain redundant data, you can split the data into related tables so that you can store data more efficiently. This process is called normalization. You can use the Table Analyzer Wizard to manually normalize your tables, or you can have the wizard do this for you automatically.
See Also For information on how to determine which tables, fields, and relationships belong in your database, search the Help index for “database design.” For more information on using the Table Analyzer Wizard, see “Using the Table Analyzer Wizard” later in this chapter.
You can save space in your database and improve join operations by choosing appropriate data types for fields. When defining a field, choose the smallest data type that’s appropriate for the data in the field. Also, give fields you use in joins the same or compatible data types.
See Also For more information on data types, search the Help index for “data types.” For information on the size of data types, search the Help index for “fields, size.”
An index helps Microsoft Access find and sort records faster. You can make dramatic improvements in the speed of queries by indexing fields on both sides of joins, or by creating a relationship between those fields and indexing any field used to set criteria for the query. Finding records through the Find dialog box (Edit menu) is also much faster when searching an indexed field. Intelligent indexing of large tables can significantly improve performance when your query uses Rushmore™ query optimization.
See Also For information on Rushmore query optimization, search the Help index for “Rushmore queries.”
Note Microsoft Jet can use a descending index to optimize a query as long as criteria on the indexed field uses an equal sign (=) as the comparison operator. If the index is descending and the comparison operator is something other than an equal sign, the index won’t be used. Ascending indexes (the default) can always be used to optimize a query.
Indexes take up space on your hard disk and slow down the adding, deleting, and updating of records. In most situations, the speed advantages for data retrieval outweigh these disadvantages. If your application updates data very frequently or if you have disk space constraints, you may want to limit indexes; otherwise, use them generously. Make sure to create a primary key or unique index if the data in a field or combination of fields uniquely identifies the records in a table.
If you use multiple-field indexes, Microsoft Access can optimize queries that join multiple fields from one table to multiple fields in another table (such as LastName, FirstName in one table to LastName, FirstName in another table) or that search for values in multiple fields. When joining or searching in individual fields, use a single-field index on each field.
If you use criteria on a field in a multiple-field index, the criteria must apply to the first field or fields in the index in order for Microsoft Jet to use the index to optimize the query. For example, if you have a multiple-field index on the two fields LastName and FirstName used in a join to the LastName and FirstName fields in another table, Microsoft Jet can use the multiple-field index to optimize the query when you have criteria on LastName only, or on LastName and FirstName, but not if the criteria is on FirstName only. If the criteria is on FirstName only, you must add a single-field index on FirstName to optimize the query. The simplest approach is to add multiple-field indexes to fields used in multiple-field joins and also add a single-field index to any field on which you use criteria to restrict the values in the field. You can add both a multiple-field index and a single-field index to the same field.
If you use criteria to restrict the values in a field used in a join, test whether the query runs faster with the criteria placed on the “one” side or the “many” side of the join. In some queries, you get faster performance by adding the criteria to the field on the “one” side of the join instead of the “many” side.
When Microsoft Access processes sums and other aggregate functions in a query, you can make the query more efficient by grouping the records effectively. For example:
See Also For information on the First function , search the Help index for “First function.”
Instead of using domain aggregate functions, such as the DLookup function, in a query, add the table referred to in the DLookup function to the query or create a subquery to access the table’s data.
When using the Count function to calculate the number of records returned by a query, use the syntax Count(*) instead of Count([fieldname]). Count(*) is faster because it doesn’t have to check for Null values in the specified field.
If you add a query that contains a calculated field to another query, the expression in the calculated field slows performance in the top-level query. For example, suppose this is Query1:
SELECT Format$(Field1) As TempField FROM Table1
Query1 is nested in the following query, Query2:
SELECT * FROM Query1 Where TempField = 100
When you nest Query1 in Query2, the expression Format$(Field1) in Query1 slows performance in Query2. For best performance, use calculated fields only in the top-level query of nested queries. If that’s not practical, use a calculated control on the form or report that’s based on the query to show the result of the expression instead of nesting the query.
After you save a query, Microsoft Jet recompiles the query the next time the query runs. On slower computers, this takes much longer than running the compiled query. (The query regains its usual speed after being compiled.) To make your application’s queries run as fast as possible the first time through, make sure that all its queries are compiled when you deliver it. To compile a query, run it by opening it in Datasheet view and closing it without resaving the query.
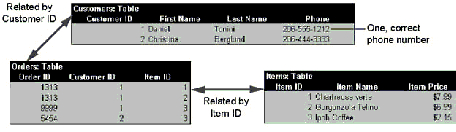
If your database has a table that contains a great deal of duplicate information in one or more fields, you can use the Table Analyzer Wizard to split the data into smaller related tables so that you can store data more efficiently. This process is called normalization. After identifying the data that can be moved to smaller tables, the Table Analyzer Wizard identifies a unique value within each new table to use as a primary key, or if no such value exists, creates an incrementing AutoNumber field to use as the primary key. It creates foreign key fields and uses them with the primary keys to create a relationships between the new tables. Finally, the wizard searches through your data, identifies any values that appear to be inconsistent, and prompts you to choose the correct value.
For example, the following illustration shows a single table that contains redundant and inconsistent data.
When you run the Table Analyzer Wizard to normalize this table, it creates a set of related tables, such as those shown in the following illustration.
Using the Table Analyzer Wizard, you can either specify the tables you want to create or have Microsoft Access normalize your tables automatically.
Û To use the Table Analyzer Wizard
In the last screen, you can create a query to view all the information from the split tables in a single datasheet.
See Also For more information on database design and relationships, search the Help index for “database design” and “relationships.”
In Microsoft Access versions 2.0 and earlier, it was recommended that you always use transactions to improve performance when you add, delete, or change a set of records in code. In Microsoft Access 95 and Microsoft Access 97, you should only use explicit transactions in situations where you may need to roll back changes. Microsoft Jet can now automatically perform internal transactions to improve performance whenever it adds, deletes, or changes records. Microsoft Jet manages this process dynamically and, in nearly all cases, produces better performance than using explicit transactions.
See Also For information on Windows Registry settings that affect internal and explicit transactions, see “Adjusting Windows Registry Settings to Improve Performance” earlier in this chapter. For more information on transactions, see “Microsoft Jet Transactions” in Chapter 9, “Working with Records and Fields.”