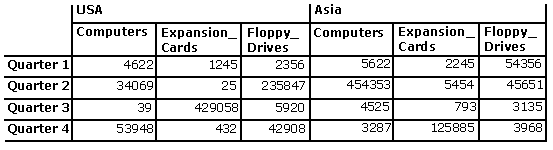
It is often useful for consumers to get a flattened view of a dataset. The process of flattening can be illustrated by considering the following dataset. The axis dimensions are Products, Geography, Quarters. Slicer dimensions are Measures, Years, and SalesRep.
Flattening this dataset yields the following rowset:
[Quarters]. [MEMBER_ CAPTION] |
[The World]. [North America]. [USA]. [Com- puters] |
[The World]. [North America]. [USA]. [Expan- sion_ Cards] |
[The World]. [North America]. [USA]. [Floppy_ Drives] |
[The World]. [Asia]. [Com- puters] |
[The World]. [Asia]. [Expan- sion_ Cards] |
[The World]. [Asia]. [Floppy_ Drives] |
| Qtr1 | 4622 | 1245 | 2356 | 5622 | 2245 | 54356 |
| Qtr2 | 34069 | 25 | 235847 | 454353 | 5454 | 45651 |
| Qtr3 | 39 | 439058 | 5920 | 4525 | 793 | 3135 |
| Qtr4 | 53948 | 432 | 42908 | 3287 | 125885 | 3968 |
Note In this table, the names of columns 2–7 are created by concatenating names from the Geography and Products dimensions. It is assumed that the provider fully qualifies the member names from the Geography dimensions to ensure uniqueness — hence “[The World].[Asia]” instead of “[Asia]”. On the other hand, it is assumed that member names from the Products dimension do not need to be fully qualified — hence “[Computers]” rather than “[All Products].[Product Line].[Computers]”. The provider is only required to return unique names. The extent to which the names are qualified in order to make them unique is up to the provider. Note also that a provider need not use qualification as a way of ensuring uniqueness. A provider can use any method that it wants to.