Ken Bergmann
Microsoft Developer Network Technology Group
January 26, 1996
This article discusses several advanced data access topics, including the types and advantages of cursors, the use of asynchronous queries, and the handling of multiple result sets.
It is intended for advanced programmers with a solid knowledge of both Microsoft® Visual Basic® programming and data access mechanisms in a client/server environment, with specific focus on Microsoft SQL Server as the database management system of choice.
Remote Data Objects (RDO) is an incredibly useful and powerful tool for Microsoft® Visual Basic® client/server developers, but using it fully has proven to be a challenge for many of these same developers. While it is possible to gain speed improvements by simply porting existing code and libraries to this new interface, this approach fails to tap the real power and performance that can be gained by putting some of the more complex techniques and features to work in your code. As is usually the case, there is a relationship between creating complex code and the performance benefits that are actually gained by doing so.
Now you can use the power of Data Access Objects (DAO) version 3.1 to leverage existing code and the power of a tight, fast interface to Microsoft SQL Server. With DAO 3.1, the existing object model has been extended to include the features and enhancements that are present in RDO 1.0 today. What this means to developers is that by using DAO 3.1, the same code syntax they use today will, with only slight modifications, bypass the familiar Microsoft Jet functionality we all know and love and go directly to Open Database Connectivity (ODBC) for high-speed access to Microsoft SQL Server.
What this really means is that many developers who currently program against Microsoft Jet databases will be using the same techniques to access data on Microsoft SQL Server. This article will show how to maximize the benefits of programming for Microsoft SQL Server, whether you are using RDO 1.0 today or upgrading to DAO 3.1 later.
To begin to leverage the power of ODBC and Microsoft SQL Server, you need to fully understand the cursors and their role in efficient scalable data access.
Cursors aren't really as enigmatic as we sometimes think. In fact, most people have a basic idea of what they are. Of course, most database developers use them, albeit unwittingly, just about every time we use DAO, RDO, or the ODBC API function. These interfaces all use cursors in some form. Whenever our applications require data access and we request a Dynaset, Recordset, or Resultset to be opened, we are really receiving a type of cursor from the interface. These interfaces can have their own cursor library or they can use the cursors provided by the data source we are accessing. So as a user of a cursor, you aren't creating the cursor directly. You are requesting it from a service provider such as a relational database management system (RDBMS) or a cursor library such as that included in the ODBC API. Now that we know where we get cursors from, let's talk about what cursors can do.
Because all of us probably have different ideas of what cursors are, I want to set down a simple working definition for clarity in this discussion. A cursor is defined here as being the manipulator of a set of data. This data is prepared by a service, exists within the address space, and uses the resources of the owner of the cursor. A cursor manages this data and has the ability to retrieve a portion of that data for a user of the cursor. A request by the cursor's user to retrieve a piece of data is called scrolling.
Because there can be many ways for a cursor to interact with the service (the data provider) and the user (who makes requests about the data), there are many types of cursors that can be created. Fortunately, there are only a few major distinctions in cursor types. These distinctions can overlap a great deal, so the variety of cursors is more like a collection than a specific list. So, rather than trying to list the distinct varieties, I will start by outlining the distinguishing factors. As you read, you will begin to see how the distinctions merge.
Updatable cursors give the user the capability to make changes to the data in a cursor and have those changes propagated back to the data provider by the cursor. You can think of this as having write privileges on the original data. In a read-only (unupdatable) cursor, any changes to the data in a cursor cannot be propagated back to the data provider. These kinds of cursors offer generally better performance because they allow the data provider to offload the data to the cursor once and then essentially forget about it and continue servicing other requests, free from concerns about concurrency problems. Both updatable and nonupdatable cursors support scrolling.
Cursors in all forms use the concept of a current record. A current record is the unit of information that is currently available for transfer from the cursor to the user of the cursor. Cursors that allow the user of the cursor to request that a piece of data be made the current record more than once are called scrollable cursors. Cursors that don't have this ability are called nonscrollable cursors; they can only provide data in a first-in, first-out (FIFO) format as data is requested. Consequently, a nonscrollable cursor is an efficient kind of cursor because it requires only the resources used to hold the data until the user of the cursor asks for the data. After the data that makes up the current record is transferred to the user, the cursor can release the resources that were used to hold that piece of data. In addition, a nonscrollable cursor doesn't require any logic about the data it holds. It only holds the data and gives it up when asked. In most implementations, when a nonscrollable cursor is requested by the user, the cursor provider (the service from which a user requests a cursor) doesn't use a cursor and instead connects the data requester to the data provider somewhat directly. With this in mind, we will limit our discussion to those types of cursors that do support scrolling.
For a cursor to be scrollable, it must have logic that will allow the user to request by position the data presented in the current record. When the cursor receives a request to change the data in the current record, it must retrieve the data from its private store and populate the current record for the user. Typical requests that are supported include the requests to move to the beginning or end of a cursor as well as to move one unit of information forward or backward within the cursor. You may recognize these as the MoveFirst, MoveNext, MovePrevious, and MoveLast methods present in Table, Dynaset, Recordset, or Resultset objects. In effect, these methods are how a user initiates scroll requests from a cursor.
When one compares scrollable and nonscrollable cursors based on performance, the nonscrollable cursors usually win by a wide margin. It becomes easy to see why when you consider the logic involved with maintaining data versus just passing the data around. In an ideal world, the user of a cursor would want to use these different types of cursors at different times within the same application. Unfortunately, presenting an interface that works with both scrollable and nonscrollable cursors can be challenging. For quite a while, this issue had been neglected. Interfaces for data access provided either scrollable cursors (such as DAO) or nonscrollable cursors (such as DB-Library). But now, you can actually choose at run time whether to use a scrollable or nonscrollable cursor. Using RDO, you have an optional constant that can be used when calling the OpenResultset method. This constant is defined in the RDO interface as rdOpenForwardOnly. By including this in the options used when calling the OpenResultset method, a nonscrollable cursor is created. With DAO 3.1, there is an additional type of recordset that can be opened, dbOpenForwardOnly. What this means programmatically is that on a resultset or recordset opened with this option, the only navigation method allowed is the MoveNext method. This allows the application to retrieve the data as fast as it can be transferred from the data provider. For situations where no updates are expected, and the data is accessed in a simple loop, this is the fastest way to get the data.
Scrollable cursors can retrieve and manage the data elements that make up the individual records from the data provider in several possible ways. One way is to use a keyset. You establish a keyset when the cursor retrieves only the unique keys for the records from the data provider. These record identifiers are called keys. When a specific record is requested, the cursor uses the key for that record to get the full contents of the record. The collection of these keys is called a keyset. Of course, there are many ways to define and use a keyset in a cursor. We will talk about some of these variations a little later.
An important aspect of using a keyset-driven cursor is that it can be faster than a standard scrollable cursor because it has less data to manage at any one time. A standard scrollable cursor would have to store the entire contents of each record in the set of records. By using a keyset, the cursor only has to keep track of the keys for each record. The key for a record is almost always smaller than the other elements of the record combined.
Whether or not a cursor uses keysets, all cursors must have rules regarding membership. Membership in a cursor is defined by the point in time when the set of records in a cursor becomes fixed. In a cursor that doesn't use keysets, the membership is usually fixed at cursor load time. That's because the operation involved with retrieving and storing each record is so expensive. In a keyset-driven cursor, this cost is lessened, so it is common for keyset-driven cursors to require membership only at scroll time. Of course, if the cursor is dynamic, then the rules change.
A dynamic cursor manages only a portion of the entire recordset at any one time, and it retrieves only the first n records at load time. When the cursor owner requests a record outside the scope of the currently loaded recordset, the cursor loads an additional n records. There is some variation in exactly when the loading of records is done, but this approach is generic enough for discussion.
So cursors can be dynamic and use keysets or dynamically load static data. When a cursor dynamically loads the keyset, it is called a mixed cursor. Mixed cursors are generally a good common ground when the application needs scrollable access to a large set of records.
When using RDO and Microsoft SQL Server, you have the advantage of using another type of cursor to further increase performance. Using RDO or DAO 3.1, you automatically have access to the ODBC cursor library. But with Microsoft SQL Server, you get access to the Microsoft SQL Server built-in cursor functionality. To take advantage of this, you need to set the rdoDefaultCursorDriver or CursorDriver properties. By using Microsoft SQL Server cursors, you can increase performance in several areas, mainly because the server is doing the caching required of a cursor, instead of downloading records to be cached at the workstation. With Microsoft SQL Server version 6.0 and later, you have full access to all the previously mentioned types of cursors, so you can choose any cursor options you like.
The main cursor types are exposed through RDO using the following flags on the OpenResultset method:
Asynchronous operation has always been a challenge for Visual Basic developers. Using the new features of RDO and DAO 3.1, the database perspective on this changes radically. The following section outlines a common way to accomplish asynchronous query execution in Visual Basic using RDO syntax. The DAO 3.1 syntax would be very similar and mostly redundant.
A common way to create the disjoint required for asynchronous execution is to use a timer control. The timer can be set to fire at specific intervals. To execute a query asynchronously, you call the OpenResultset method with the rdAsyncEnable flag. Then you enable the timer. At each interval when the timer fires, it checks the status of the current query. If the query is completed, it calls a routine to handle the results. To keep this simple, we are using a technique that allows only one query at a time. Alternatively, there are many techniques that use arrays or round-robins to handle multiple queries at the same time.
Sub ExecuteAsyncQuery(connWork as rdoConnection, ByVal sQry as String, _
ByVal iType as Integer, ByVal iLockType as Integer
'rsWorker is an rdoResultSet object defined public
Set rsWorker = connWork.OpenResultSet(sQry, iType, iLockType, rdAsyncEnable)
tmStatus.Enabled = True
End Sub
Sub tmStatus_Timer()
tmStatus.Enabled = False 'So no re-entrancy
If rsWorker.StillExecuting Then
tmStatus.Enabled = True 'It's still working...
Else
ProcessResults
End If
End Sub
To cancel this query, you might use code that looks like this:
Sub btCancel_Click()
tmStatus.Enabled = False
If rsWorker.StillExecuting Then
rsWorker.Cancel
Set rsWorker = Nothing
Else
If Not fAlreadyProcessing Then ProcessResults
End if
End Sub
There are many situations where using asynchronous queries is preferable. Basically, you want to use asynchronous queries when you have a long process that needs to be completed, but you don't want to tie up an end-user computer to complete it.
Microsoft SQL Server tasks are an alternative to asynchronous queries. Tasks are commands that the Microsoft SQL Server Executive launches once or at desired intervals. Because these tasks are run on the server, they are asynchronous to a client requesting their execution. They can also make use of logging and alert mechanisms, making this a very powerful and rich alternative to asynchronous queries. For more information on tasks and alerts, see my "Client/Server Solutions: Leveraging Microsoft SQL Server Services in a Transaction Processing Environment" technical article.
When using RDO or DAO 3.1 for your data access mechanism, it becomes possible to have queries that produce more than one set of results in a single resultset or recordset object. When a query returns more than one set of results, the resultset or recordset object initially presents only the first set. To gain access to the successive sets, you must call the MoreResults method in RDO or the NextRecordset method in DAO 3.1. By doing this, you flush the contents of the current set of results and move to the next one. You may not reverse this operation. Here is a sample using a query that returns the content that will fill several list box controls; again, I've chosen to implement this in RDO.
Sub Prepare()
Dim rsWork as ResultSet 'Use the public conn
Dim iIndex as Integer
iIndex = 0
Set rsWork = connMain.OpenResultSet(sLstQry)
If rsWork.BOF and rs.EOF Then
'No data returned, do error handling
Else
Do Until rsWork.EOF
lstData(iIndex).AddItem Trim$(rsWork("Description"))
lstData(iIndex).ItemData(lstData(iIndex).NewIndex) = CLng(rsWork("PKId"))
rsWork.MoveNext
Loop
Do While rsWork.MoreResults
iIndex = iIndex + 1
Do Until rsWork.EOF
lstData(iIndex).AddItem Trim$(rsWork("Description"))
lstData(iIndex).ItemData(lstData(iIndex).NewIndex) = _
CLng(rsWork("PKId"))
rsWork.MoveNext
Loop
Loop
End if
End Sub
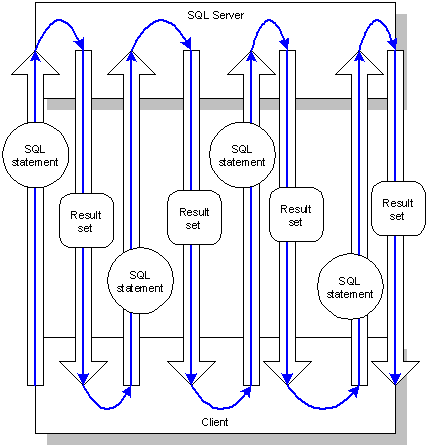
Developing client/server applications today means considering efficient use of distributed resources. Going over wide-area networks is much more costly than pinging the server two floors down. Using multiple result sets can create more options in the way that transactions are packaged. For example, the task of retrieving data to populate a form might involve data from several tables or sources. Packing the requests into a single statement or stored procedure and allowing the server to send back multiple results eliminates the need for the client to handle multiple sessions with the server. It turns this type of communication:
Into this:
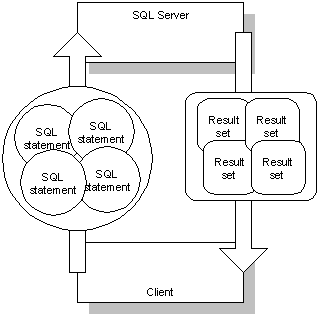
The latter organization is much more efficient when the cost of network requests is high.
You can use this type of optimization, for example, in order to:
Ultimately, RDO and the new features in the release of DAO 3.1 will have a significant impact on the performance of client/server applications. However, full realization of these benefits will require a proper use of these new features and possibly an adjustment to the way we design transaction models in the future.