Ken Bergmann
Microsoft Developer Network Technology Group
April 1996
Click to open or copy the files in the LAYERS sample application for this technical article.
This article is an extension of the Client/Server Solutions series previously published on the MSDN Library. The series explained some fundamental concepts for doing quality client/server development. A key topic discussed in this series was the Layered Paradigm. This article examines the Layered Paradigm in the light of Microsoft® Visual Basic® 4.0 and illustrates the mechanics of implementing this approach in a client/server application. The article presents an overview of the Layered Paradigm, lays out an implementation in the service model, and then walks through that implementation. Because this article draws heavily on the fundamentals first laid out in the Client/Server Solutions series, readers are highly encouraged to read that series before reading this document (see "Introduction," below).
Source code is included for the service implementation of the Layered Paradigm. The source code is a series of Visual Basic 4.0, 32-bit in-process dynamic-link library (DLL) components that build a framework for applications development. Consult the BUILD.TXT file for compilation and dependency instructions.
Quite a long time ago, I wrote a series of articles on client/server development from an enterprise point of view. One of the main topics I discussed was the Layered Paradigm, a perspective for implementing the standard components of a client/server application. Of course, because this was quite a while ago, the implementations were affected by the limitations of the previous versions of Microsoft® Visual Basic®. With the new capabilities in programming tools, the Layered Paradigm becomes not only easier to implement, but also more crucial to success than ever. But I'm getting ahead of myself. Let me explain what this article will cover. First, I'll give a brief overview of the Layered Paradigm, then I'll talk about the background of this article, and finally I'll illustrate an object-based implementation under Visual Basic 4.0. I'll go through the various layers, show some code, explain some of the attributes and limitations, and then discuss some alternatives at each layer. I'll finish up with a short discussion of how the paradigm fits into other aspects of enterprise development, including workbenches and shared code.
Because this article draws heavily on background information from the Client/Server Solutions series previously published in the MSDN Library, you should first read these four articles in the series:
Client/Server Solutions: The Architecture Process
Client/Server Solutions: The Design Process
Client/Server Solutions: The Basics
Client/Server Solutions: Coding Guidelines
I first started preaching about the Layered Paradigm when almost all solutions were considered to be two-tiered, or basic client and server. The application lived on the workstation and the data for the application was shared on a server. I implemented quite a few of these and several are still in use today at the enterprise level. Back then, the idea of a really advanced system was for it to be three-tiered, meaning that there were three physical machines that made up the system: the workstation applications (or clients), the server, and a piece in the middle that managed the relationship between the clients and the server. This piece supposedly was to wrap the "business rules," whatever the heck those are.
Of course, we all had businesses to run, so rarely did anyone get around to developing a three-tiered system. I usually had to make do with two-tiered systems and good programming techniques. That's where the Layered Paradigm came from. By "layering" or modularizing the functional components of a traditional system, the challenges of creating client/server systems could be addressed one at a time instead of all at once. This "layering" or modularization was very conducive to code reuse, sharing, and so on. Of course, even with these benefits, it still took a while to catch on. It was a new idea, and in those days, a logical modularization of an application was uncommon, and there certainly wasn't a term for it.
Skipping forward to today's world, you can now hear the term three-tiered used in several ways. Some still use it in the traditional (or pure) sense when referring to a system that has three physical components, none of which is local to the other components. There is also a new use for the term. It can now be used to refer to three logical distinctions within an application. These logical sections are usually referred to as the user interface, the business rules, and the data sections. It's important to understand the varieties in the terminology in order not to confuse this perspective with the layers of the Layered Paradigm. There is a good way to tell the difference: When we talk about three-tiered applications logically, there are still only three tiers, but in talking about any application from a layered perspective, there are always four layers.
Here are the four layers:
To return again to the distinction between the Layered Paradigm and three-tiered logical modeling, the following stacked diagram might help you understand why the Layered Paradigm has matured to four layers.
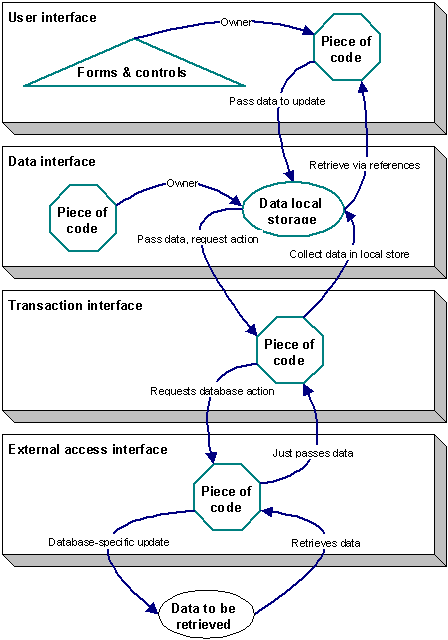
Figure 1. The four layers of the Layered Paradigm
The figure shows how the Layered Paradigm draws specific lines over who owns what data at each step in the process. The Layered Paradigm also makes it apparent where each type of operation takes place in the process. For example, in a three-tiered application, there is no room to model the translation between the requests for a particular type of database operation and the specifics of that operation for a particular database or transport. Because of this limitation, many applications today lack the ability to easily change the database or transport for which they were originally implemented. In an application implemented using the Layered Paradigm, only the bottom two interfaces can ever be affected by changing the database or transport. In most cases, it will only be the external access interface. Only in extreme cases will the transaction interface require modifications.
To avoid any confusion at this point, let me make very clear a distinction between the transaction interface and the data interface. The data interface simply provides common mechanisms for both storing data outside the database (that is, in memory, file caches, and the like) and for the applications to access this data. The transaction interface never owns the data; it is simply an operator interface. The transaction interface just passes data from a specific external access interface to the data interface; when the time comes for updates to the data, the data interface gives the transaction interface the data to be operated on and tells it what type of operation to affect. So, the transaction interface never owns data—it only operates on data. The data interface never operates on data—it only owns it. This distinction can be very important, and in later sections I'll explain why.
So, now that you know a little about the evolution of the Layered Paradigm, let's move right into an implementation.
Before I start flinging code around, it's important to outline the specifics of the implementation so that the modularization and ownership boundaries are defined. In an implementation of the Layered Paradigm, the ownership lines are very fluid. Therein lies its greatest advantage. Of course, whenever you are working with a technique that can be very subjective or fluid, it's important to outline the assumptions you are working under so that the decisions you make as you progress will have a solid grounding. Models work very well for this type of thing, so that's how I'll explain the architecture of this particular implementation. By the way, I call this a service model implementation because it is really just a collection of system services.
The following diagram lays out the components that are required for an implementation of the Layered Paradigm to work. The details of the components are irrelevant. The key here is to understand the services that each layer provides to an application. A good way to understand this is to think of the various tasks that must be done frequently when developing client/server or transaction processing systems. Issues like logging and generically accessing data are among the things that should come to mind. If you are having a hard time understanding services as they relate to client/server or transaction processing systems, it may help to give the diagram a quick once-over for now and then refer back to it as I discuss the components in more detail later.
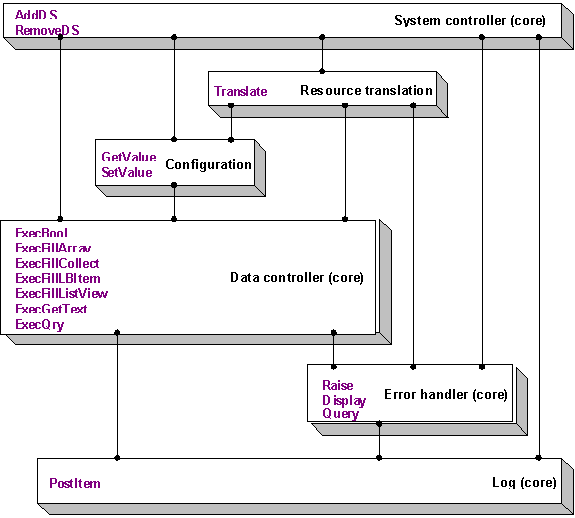
Figure 2. The required components in a Layered Paradigm implementation
Okay, now that you have a rough idea of the types of services that our implementation will have, let's look at them in depth and start to figure out how an application might use them.
The log service is on the bottom of the interface chain, so I'll start with it. Essentially, it will have the ability to take an item (whatever it might be) and post it, presumably to some type of persistent storage mechanism such as a file or database. For ease of implementation, we are going to assume that log services are noncritical so that we can write no-fail code in this service. As such, the code can simply be a method of the log service with no return value or a type of fire-and-forget routine.
Since I can envision several types of log mechanisms (different files) for storing my log data, I probably want to provide some standard flavors so that developers have less subclassing to do when they actually want to use my service in an application. I'll just be arbitrary and say three flavors. The first log mechanism is strictly for errors, the second is strictly for database transactions, and the third is a catch-all for the other two and anything else as well. The third is a kind of a super log, though maybe with less specific information. Here's how I would expect to use this service, and what I would get:
Log.PostItem NOT_ERROR, "clsInterests.Prepare", STR_MSG_ENTER
I'm using an object called Log and executing the PostItem method. Presumably I have some constants defined. The first is NOT_ERROR or some numeric code that indicates that this item is informational. Notice that the Log object I am using actually dictates which Log the item goes to, and the NOT_ERROR code in this case simply tells me that the item is informational. In an error log, this might be a severity level or the error number. I then give the class and current method name, or whatever process-identifying string I want. Then I give the details of the item. In this case, it's the constant STR_MSG_ENTER, which is presumably a string that signifies that the code is entering a new procedure.
Here is an example information log:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
As you look at the log extract, notice that some information is repeated. This is because each of the layers can operate more or less independently, and in the case of log services, they all make use of the same services. Having just one service that all the layers can talk to makes it easy to centralize issues such as formatting or the type of persistent storage. Perhaps we want to begin storing the log information into a local database instead of a text file. Simply modifying this common service will enact the changes across the system.
The error-handling service is another very common service that will need to be accessible from just about every part of the system. The error-handling service is tied closely with the error flavor of the log services. Essentially, the developer would only require one step to handle an error and to log it in all required logs.
By "handle an error," I mean to store the information about an error for persistence. Programming in this way requires some assumptions, but once they are fully known and understood, the load for all developers in the system is considerably lessened. I'm first going to just charge in and lay the assumptions out. After I've talked about each of the assumptions, I'll explain why they depend on each other and why they should be made.
The first major assumption is that operation procedures that don't return data should not return error codes, only Boolean values. If failure conditions are allowed, the procedure must store error information using a service and return a False. In other words, all routines that do work and from which code might branch depending on a return value, should only return Boolean values. Functions can return data or Boolean values, but not error codes. I'll explain this more in a bit.
The second assumption is that noncritical code should be in Sub procedure calls whenever possible. If the operation being done is not critical to the overall success of a higher operation, then it should be in a procedure, not in a function. Someone calling into noncritical code should not have to worry about making branching decisions based on returns from noncritical code. Again, this can be abstract and it will become clearer later, when I bring this all together.
The third assumption is that noncritical sections must not require their caller routines to check for or respond to error conditions. In other words, if you decide to have a Boolean function to conduct a portion of a larger process, the larger process does not have to deal with errors returned by the Boolean function. The function handles the error itself, up to and including preparing messages for the user and storing information in a log. This assumption can be hard to understand, but it gets clearer when considered with the other two.
When you combine these assumptions, it means that the interfaces for services should usually be Sub procedures and only occasionally require Boolean function calls. When they are Sub procedures, they cannot require that the caller check the error handler for possible error codes. Now let me explain a little about why I can say these things.
See, the first two assumptions simply define standard interfaces between worker functions and critical code. Once this distinction has been made, we further limit the overlap of responsibilities between types of code. If the calling code does not have to check for and handle error conditions, the code in the worker functions can be made to insulate the caller even more from the details of implementation. At this level of encapsulation, we are not only separating the interfaces, we are requiring that the worker functions be able to operate independently of each other. Replacing dependencies in this manner is widely known to be one of the keys to making reuse practical.
This structuring and classification of code brings some added benefits, because when these concepts are actually put in practice on a project, the impact of different styles of coding on a particular application can be lessened. Also, by requiring a high level of independence in code, we can make the code for an application much more compact and much less error prone. In the end, all these benefits mean that the code you end up with is less error prone and many times more reusable.
Here's a small example of coding using the assumptions:
'This routine deletes the current person.
Private Sub Delete()
On Error Resume Next
Dim sParm As String
'Do preliminary validation.
If Not CBool(lPKId) Then Exit Sub
Screen.MousePointer = vbHourglass
SysCon.StatusSet STR_STS_DEL & sMe
Log.PostItem NO_ERROR, "clsPerson.Delete", STR_MSG_ENTR
'Build the parameters list.
'With only one field this could be done inline,
'but that wouldn't be consistent with other parameter-building techniques.
sParm = CStr(lPKId)
Log.PostItem NO_ERROR, "clsPerson.Delete", qry_PrsDel & sParm
'Call Boolean execution function; it works or it doesn't.
'If it doesn't, the error handler will know why.
'I just tell it to tell the user.
If Not DBSvc.ExecBool(DS("MAIN"), qry_PrsDel & sParm) Then
'Ask the Error Service to display the last error.
'Stick standard could not delete message in front, and
'standard contact system administrator message on the end.
SysCon.ErrSvc.Display vbCritical, STR_MSG_NODEL, STR_MSG_CNTSA
End If
'Private retrieve function to reload data
Retrieve
Log.PostItem NO_ERROR, "clsPerson.Delete", STR_MSG_EXIT
SysCon.StatusReset
Screen.MousePointer = vbDefault
End Sub
This code is easy to read and very compact. Notice the use of the subroutines to handle all of the noncritical tasks, such as logging and setting the status indicators. There is literally one line of error handling in the whole routine! All the Sub procedures will handle and log their own errors and activities. Even the database procedure is straightforward. Either it returns or it doesn't. If it doesn't, it simply asks the error-handling service to tell the user about the last error. There is no cleaning up—all of the dirty work is done by the error-handling service.
The data controller services operate on many of the same assumptions as the services I've already discussed. They encapsulate every type of database operation that an application will ever need to perform. They do this in a generic way so that the transports can be interchangeable. For example, I could implement a version of the service that used Microsoft Jet to communicate with databases. I could implement another version that used Remote Data Objects (RDO) to accomplish the same tasks while using the same interface. I could go even further and implement a version that used sockets to talk across a network to a service provider that operated against flat files or a mainframe. As long as I can implement the same interface at this level, I have complete transport independence for my application and its services.
In deciding what the implementation actually looks like, it is important to consider the entire transaction model and match the service interface to it. For more information about designing and implementing transaction models, watch for an article later in the Client/Server Solutions series. For now, here is an example interface that I have implemented. The operator class interface looks like this:
'Interface to data service class that is an operator class.
'ds As CmpDbsJet.Source is the data class for data services.
'An instance of CmpDbsJet.Source holds information about what a database looks like.
'The data services can use the contents of a CmpDbsJet.Source to know
'how to operate. A caller passes an object of type CmpDbsJet.Source in to
'any operator function and the function operates on the object passed in.
'Private Function CheckConn(ds As CmpDbsJet.Source) As Boolean
'Public Function ExecBool(ds As CmpDbsJet.Source, ByVal sQry As String) _
As Boolean
'Public Function ExecFillArray(ds As CmpDbsJet.Source, ByVal sQry As String, _
' sArray() As String) As Long
'Public Function ExecFillCollect(ds As CmpDbsJet.Source, ByVal sQry As String, _
' cTmp As Collection) As Boolean
'Public Sub ExecFillLBItem(ds As CmpDbsJet.Source, ctlMe, ByVal sQry As String)
'Public Function ExecGetText(ds As CmpDbsJet.Source, ByVal sQry As String)_
As String
'Public Function Init(ds As CmpDbsJet.Source, objE As objErrHnd, _
' objILog As objLogEvent, objTLog As objLogTrans) As Boolean
'Public Sub Term(ds As CmpDbsJet.Source)
Note that I am using an operator class and a separate data class. A data class has no public methods; it only serves to hold data, in much the same way a user-defined type or collection might. A big advantage is that it can have code that executes when the properties of the class are set. This is useful when you need an entity to hold data but need to require that the data take a specific format or be in a particular order. However, an operator class doesn't really own any data. It operates on a data class that is passed into it. This is useful when you have operations that are similar but need to operate on different classes. For example, you might have two entities in your system, hourly employees and salaried employees. Both need to be taxed using the same algorithms. To do this, you code an operator class to do the taxing by simply passing in the object currently being evaluated. Because the two objects share some of the same properties, the operator can perform its function equally well on both. In the example interface shown above, it is the operator class that is shown. After all, there really isn't much to the interface of a data class.
In this particular implementation, I envisioned the possibility of having the application require access to more than one database at a time. Therefore, the databases can be accessed using a key to a collection of data classes that hold the information about the particular database. For example, you could establish the published key for the database that holds tax information as "TAXDB." This key enables a user to find the right object of type CmpDbsJet.Source in the collection of objects of this type maintained by the system controller. The object itself contains the actual information about the database.
Because most systems work on a primary database, a team might decide to declare a database with the name of MAIN as its primary database. The majority of the code will use this database when requesting database operations. Then, as other data needs to be accessed, other CmpDbsJet.Source objects could be added to the collection for use by any code in the system. These other objects might describe databases that are in different formats or even that require different transports. The bottom line is that the application code doesn't care; it uses the same code to accomplish tasks. In some cases, it uses the key for LOCAL instead of MAIN when it needs local data, or it uses TAXDB instead of CUSTDB, and so on.
Here is an example of a Prepare routine in which the application needs list boxes loaded with data. If a local database is present, the application would like to pull this lookup data from the local database instead of the primary server.
Public Sub Prepare()
On Error Resume Next
Screen.MousePointer = vbHourglass
Log.PostItem 0, "clsInterests.Prepare", STR_MSG_ENTR
SysCon.StatusSet STR_STS_PRE & gscCap_INGR
'Clear out any data currently in the combobox.
cmbTypeGrp.Clear
'If the flag for UseLocalData is set
If gicLocalDB Then
'Use pure SQL to get data from a local database.
Log.PostItem 0, "clsInterests.Prepare", gscLvw_INGR_Loc
DBSvc.ExecFillLBItem DS("LOCAL"), cmbTypeGp, gscLvw_INGR_Loc
Else
'Use a stored procedure to get data from central server.
Log.PostItem 0, "clsInterests.Prepare", gscLvw_INGR
DBSvc.ExecFillLBItem DS("MAIN"), cmbTypeGp, gscLvw_INGR
End If
'Set up the default.
cmbTypeGp.ListIndex = FIRST_ITEM
Log.PostItem 0, "clsInterests.Prepare", STR_MSG_EXIT
SysCon.StatusReset
Screen.MousePointer = vbDefault
End Sub
Notice that the code doesn't care where the data comes from. In either case, whether the data is pulled from a local database or a primary server, it will get loaded in an optimal way. This is a good example of the use of data and operator classes.
These two services are pretty skimpy. They are simply independent wrappers for the configuration settings and resource tables of an application. For the configuration service, this usually means data stored in the registry, but it might just as easily be a local database or a shared system database. The resource translation service is usually an interface to a resource-only DLL that holds the resource tables for an application. In reality, the resources might exist in multiple files or even in databases. Keeping these common interfaces ensures that the application won't be affected no matter where these pieces of data reside or in what form. Because the interface to these servers will not change by simply updating the data that is included in the file, when the servers are recompiled they can keep the same Class IDs. This means that compiled code that makes use of these servers does not need to be recompiled. You can just copy a new file to the system and register it. Any code that uses this server will never need to know that the data in the server has changed.
The system controller service wraps all the previous services up in a nice nutshell for the application. The application can use any of the separate services independently if it likes, but then it will need to understand the dependencies between them. So the primary focus of the system controller service is to wrap these servers all together. Then the application needs to worry only about getting an instance of the system controller service, and it automatically gets all the other services.
The secondary focus of the system controller service is to encapsulate any code that an enterprise wants to share at the system level. For example, the system controller might encapsulate status displays, initialization and version control procedures, or notification systems—anything that is used consistently by multiple users of the system controller, even if they are not necessarily within the same application. In the sample associated with this article, I have made the system controller responsible for handling the status and percent displays of the application. So any service or code in the application that has access to the system controller service can call the status and percent routines and know that the status and percent displays will handle the requests in an appropriate manner.
That pretty much wraps up my discussion of the services. Let's move on to how an application can use these services to actually get some work done.
Like every other service, these services need to be initialized and terminated at the appropriate points. And using the interfaces should be self-explanatory. What isn't so clear is how to appropriately use these services within the context of the Layered Paradigm. That's what I'll attempt to explain in this section. I'll start at the very top with the user interface and work my way down from there.
There are generally two schools of thought about how to accomplish the task of separating the user interface and the data interface. Both approaches are a matter of opinion and little else. I'll illustrate and explain both, so that you can choose the one that best suits your development style. There is also an extremist perspective that I'll explain afterwards, which those of you with gobs of time and resources might actually have a use for. Unfortunately, most development shops never have enough time or resources for the extremist approach to be realistic.
In this approach, you standardize the names of controls and forms up front. The data interface is called to populate the controls by way of a form that is either available or passed in. There are several different flavors of this approach. The following is an example of my favorite type. It is a High Schools class, and it holds all the high school records for a particular student. It shows the Initialization and the Display routines so that you can see how the caller of this function sets up the class. Previous to Display, the caller would also need to call Retrieve to make sure that the records were actually loaded into the class.
'This is the data interface class initialization routine.
Public Function Init(frmMeIn As Form) As Boolean
...'Set up error handling.
Set frmMe = frmMeIn
...'At this point the form is hooked up.
Init = True
End Function
'When the user of this class needs a specific record displayed
'it sets the iCurrRec property and calls the display routine.
Public Sub Display()
On Error Resume Next
Screen.MousePointer = vbHourglass
Log.PostItem 0, "clsHighSchools.Display", STR_MSG_ENTR
'Private function to clear the controls to display data in
Clear
SysCon.StatusSet STR_STS_RET & STR_OBJHSCCAP
'Do I have the record the user wants to see?
If iCurrRec >= LBound(sHsc, 2) And iCurrRec <= UBound(sHsc, 2) Then
frmMe!txtHscCode = Trim$(sHsc(idxHSRC_ORGN_Code, iCurrRec))
frmMe!txtHscName = Trim$(sHsc(idxHSRC_ORGN_Name, iCurrRec))
frmMe!dtHsc.Date = Format$(sHsc(idxHSRC_LastAttendDate, iCurrRec), _
"Short Date")
If CBool(sHsc(idxHSRC_Graduated, iCurrRec)) Then frmMe!chkHscGraduated
_ = True
End If
Log.PostItem 0, "clsHighSchools.Display", STR_MSG_EXIT
SysCon.StatusReset
Screen.MousePointer = vbDefault
End Sub
Notice that the control names must be predefined. And each user interface that uses this data interface must support the same control names, must have all the controls, and so on. While this approach was the one I have used most in the past, I now do most of my work with the following approach.
In this approach, the separation between the layers is very distinct and intentional. The bottom line here is that at initialization time, references for the controls in the interface are passed to the data interface and the data interface just “parties” on its control references. There can be some complicated issues with this approach, but overall it's a very comfortable middle ground for developing quality, elegant solutions. It goes something like this:
Public Function Init(objMyParent As Object, cmbMyType As Object, _
cmbMyTypeGrp As Object, _
txtMyInt As Object, btMyIns As Object, btMyUpd As Object, _
btMyDel As Object, btMyClr As Object) As Boolean
On Error GoTo initacterr
Set objParent = objMyParent
Set cmbType = cmbMyType
Set cmbTypeGp = cmbMyTypeGp
Set txtInt = txtMyInt
Set btIns = btMyIns
Set btUpd = btMyUpd
Set btDel = btMyDel
Set btClr = btMyClr
Init = True
Exit Function
initacterr:
Set objParent = Nothing
Set cmbType = Nothing
Set cmbTypeGp = Nothing
Set txtInt = Nothing
Set btIns = Nothing
Set btUpd = Nothing
Set btDel = Nothing
Set btClr = Nothing
Init = False
Exit Function
End Function
'When the form needs to display a record
'it sets the iCurrRec property and then
'calls this routine.
Public Sub Display()
On Error Resume Next
Screen.MousePointer = vbHourglass
Log.PostItem 0, "clsInterests.Display", STR_MSG_ENTR
'Private function to clear the controls to display data in.
Clear
SysCon.StatusSet STR_STS_RET & STR_OBJINTCAP
'Do I have the record the user wants to see?
If iCurrRec >= LBound(sInt, 2) And iCurrRec <= UBound(sInt, 2) Then
'FindItem searches a combobox for an integer and selects the item.
FindItem cmbTypeGp, CInt(sInt(idxSINT_INGR_PKId, iCurrRec))
FindItem cmbType, CInt(sInt(idxSINT_INCG_PKId, iCurrRec))
txtInt = Trim$(sInt(idxSINT_Comment, iCurrRec))
End If
Log.PostItem 0, "clsInterests.Display", STR_MSG_EXIT
SysCon.StatusReset
Screen.MousePointer = vbDefault
End Sub
In this procedure, the private control references are used to get essentially the same work done as in the previous example. One major difference is that the control references are set only once. So if a more flexible architecture were needed, some controls could be made optional on initialization. Also, the names of the controls in the caller can be anything; they can even reside on a different form than the caller of this class.
Just in case you have gobs of time and resources, I figured I would tell you about an ideal solution to the separation between user interface and data interface. It is a bit different than the previous two approaches. The crux of it is to have the data interface expose properties that the user interface can draw from. This complicates the user interface drastically, but it provides the biggest possible separation between the two interfaces. In this approach, there would be no initialization procedure. The user interface would call a Retrieve routine on the data interface and then start sucking the data for its controls out of the data interface. Of course, the data interface would get much smaller and dumber, but it really is just a trade-off anyway. The bottom line is that a more middle-of-the-road approach to this is where most programmers feel comfortable, but I wanted to point out that there is another alternative for those who feel so inclined.
In the previous examples, I deliberately left out how the data interface retrieves its data. This section should explain that. Essentially, the data interface should be able to think only in terms of types of operations it requires, and the transaction interface should handle actually implementing those operations. This is much like the distinction between a data class and an operator class. The transaction interface is called by the data interface with a request for data. The transaction interface, knowing the specifics of how to get the data from the external access interface, proceeds to get the data in whatever format it needs from the external access interface and feeds it to the data interface in terms the data interface can understand. In most cases, the transaction interface can just retrieve an array from the external access interface and pass this array on to the data interface. In the case of updates to data, or pulling data from multiple sources, this becomes very important.
Here is an example of the data interface creating a new record without using a transaction interface:
Private Sub Insert()
On Error Resume Next
Dim sParm As String
Screen.MousePointer = vbHourglass
SysCon.StatusSet STR_STS_INS & STR_OBJINTCAP
Log.PostItem 0, "clsInterests.Insert", STR_MSG_ENTR
'Build the parameter string using data from the controls.
'Interest Type
If cmbType.ListIndex = NO_ITEM Then
MsgBox STR_MSG_REQ, vbCritical, gscAppName
SysCon.StatusReset
Screen.MousePointer = vbDefault
Exit Sub
Else
sParm = sParm & CStr(cmbType.ItemData(cmbType.ListIndex)) & STR_SPCSP
End If
'Student ID
sParm = sParm & CStr(lPKIdStu) & STR_SPCSP
'Comment
If Len(Trim$(txtInt)) Then
sParm = sParm & sq & Left$(DoQuotes(txtInt), 255) & sq
Else
sParm = sParm & STR_NULL
End If
Log.PostItem 0, ("clsInterests.Insert"), gscIns_SINT & sParm
'Boolean Execution Procedure; it works or it doesn't...
If Not DBSvc.ExecBool(DS("MAIN"), gscIns_SINT & sParm) Then
SysCon.ErrSvc.Display vbCritical, STR_MSG_NOINS, STR_MSG_CNTSA
End If
Retrieve
Log.PostItem 0, "clsInterests.Insert", STR_MSG_EXIT
SysCon.StatusReset
Screen.MousePointer = vbDefault
End Sub
This code uses all the services well and isn't even very big. But you couldn't easily change the SQL statement that is being constructed without changing this critical code. Further, if you wanted to go to a transport that used a different flavor of SQL or didn't use SQL (such as Data Access Objects [DAO]), you would have lots of work to do. So here's what the same task would look like if you used a transaction interface:
Private Sub Insert()
On Error Resume Next
Dim sParm As String
Screen.MousePointer = vbHourglass
SysCon.StatusSet STR_STS_INS & STR_OBJINTCAP
Log.PostItem 0, "clsInterests.Insert", STR_MSG_ENTR
'Tell the Transaction Interface you are creating a new record.
objIntTrans.AddNew
'Set the data for the new record.
objIntTrans.Type = cmbType.ItemData(cmbType.ListIndex)
objIntTrans.StudentID = lPKIdStu
objIntTrans.Comment = txtInt
'Tell the Transaction Interface to proceed with the update.
objIntTrans.Update
'Private retrieve procedure to reload your data.
Retrieve
Log.PostItem 0, "clsInterests.Insert", STR_MSG_EXIT
SysCon.StatusReset
Screen.MousePointer = vbDefault
End Sub
Notice that all the smarts of building the SQL statement (or using DAO) are hidden inside the transaction interface. The data interface still manages the process, the persistence, and the flow of data to the user interface. But the work of actually performing database operations has been further isolated. Those who do lots of DAO work are probably wondering why such an abstraction layer is necessary. After all, the layer looks the same as if you had written it in DAO in the first place. But what if you needed to use stored procedures, instead of dynasets? Or what if your data was located on a mainframe? You would need to do API calls or build SQL statements to get the same tasks done. Simply using DAO would not be sufficient. By abstracting the transaction interface, you can efficiently make use of any techniques or different technologies that are required to work with your data. Regardless of whether that technique or technology is using an API, other OLE objects, or building SQL statements, this service abstracts those specifics from the rest of the application code.
If we have made a clear distinction between the data interface and the transaction interface, the role of the transaction interface should be more or less clear. And, as a side effect, the distinction between the transaction interface and external access interface should also be clearer. Essentially, the external access layer is a specific implementation of the data controller service's operator class. Back when I was talking about the data controller service, I pointed out that the operator class embodies all the specific operations that can be requested of a particular data source. In the implementation, I used a generic interface so that operator classes could be made interchangeable. This is the goal you should work toward when designing client/server components, but this goal was added to the requirements of our implementation and certainly is not dictated by the Layered Paradigm or the service model. In reality, the implementation of the transaction interface can be as simple as those sets of functions that make up your specific transaction model for accessing your data.
To emphasize even more the differences between the transaction interface and external access interface, think of the transaction interface as the piece of code that prepares the transactions and translates them from object requests into a format that the external access interface can speak. The external access interface is the physical implementation of acting out those object requests on a particular data source.
In this article, I've advanced the Layered Paradigm into the object-based arena that characterizes Visual Basic 4.0 development today. I've illustrated a model that could be used to implement the paradigm, and I've illustrated how that model could be implemented from an applications perspective. In addition, I've included the code that is an implementation of the service model explained in this article.
I want to add just a word of caution here. The code I am including is code I've used, but it is not designed for production use. It is to serve only as a model for you in developing your own solutions. Of course, by creating your own implementation, you will invariably come to understand this at a much deeper level as well. Which is, by the way, a good thing.
Anyway, you now have all you need to start leveraging the Layered Paradigm and the service model.