Ken Bergmann
Microsoft Developer Network Technology Group
April 1996
This article discusses techniques for creating workbench-style applications for the enterprise. We will be covering several approaches and tying in the perspectives of the Layered Paradigm and the service model. All discussion is object-based with emphasis on implementation in Microsoft® Visual Basic® version 4.0. The article is structured around OLTP (online transaction processing) applications but has some carryover into other types of applications as well.
For background information, it is strongly recommended that you read the articles in the Client/Server Solutions series previously published in the MSDN Library (see "Background Information," later in this article).
It seems the concept of workbench-style applications development is back again. With the ability to create OLE servers in Microsoft® Visual Basic® version 4.0, developers are once again approaching their application challenges from a super component perspective. This is basically a good thing, because it means more and more developers are thinking their applications through from a component-based point of view. As a supporter of the services model and the author of the Layered Paradigm, this means to me that more developers are open to an object-based message. (For an overview of the Layered Paradigm, please see "Client/Server Solutions: The Architecture Process.") In this article, I will be discussing several approaches for building workbench style applications. I'll talk a little about the various approaches and point out the advantages and disadvantages of each as well as discuss how each fits in with the services model. Along the way there may be some digression into ways to extend the models and lots of information about proper client/server development techniques.
Doing some background reading before delving into this article might be helpful to you. A good understanding of transaction models is advised and I strongly recommended that you read the foundation articles in the Client/Server Solutions series previously published in the MSDN Library:
Client/Server Solutions: The Architecture Process
Client/Server Solutions: The Design Process
Client/Server Solutions: The Basics
Client/Server Solutions: Coding Guidelines
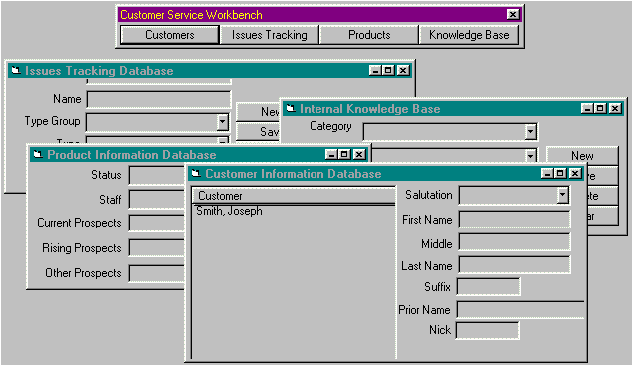
The workbench-style application is one in which a common application is created to encapsulate the features or functional areas that might be (or sometimes currently are) served by separate applications. The features or areas of the application might be related or even share data; they might also be very distinct. As an example, let's look at a mockup of a customer workbench.
Figure 1. A sample customer service workbench application
In this sample workbench application, there is a customer maintenance form, a customer issues tracking form, a product order form, and a form for accessing the Knowledge Base. The purpose of such an application is to provide a phone support technician with access to all the information about a customer's issue history, allow modifications to the customer information, order new products for the customer, and research the current customer's questions without ever leaving this single workbench application. In terms of tasks, a single user might be asked to accomplish, this example is a bit much, but it should emphasize the point. Workbench applications are designed to put all the tasks or data that a specific user might need in the same place on the user's desktop.
A primary concern when dealing with workbench applications is size. When attempting to create a single application that can simultaneously manage extensive lists of customers and their information, products and their information, and orders and their information, size must become an important consideration. Of secondary consideration is ease of development. These two considerations are often thought to be exclusive, even though they don't need to be. Since this an important issue, I'll start applying techniques right here.
The first thing that should be apparent at this point is that by separating the functional areas from each other and from the actual workbench code, the size of any one executable is diminished and the development of each piece (workbench included) can be handled in separate stages, sequentially or in parallel. This separation is critical and obvious, but the implementation is fraught with issues and pitfalls. These will be of primary interest in the following discussion.
To be clear, I want to point out that because implementing a workbench without such a separation is really no different than monolithic applications development, it will be assumed for this discussion that the term workbench will refer only to those implementations in which the functional areas and the workbench components are separated.
To accomplish this bringing together of diverse applications, designing a workbench requires a much broader thought process than a single transaction application might need. The first step in this process should be to outline the foundation for the workbench. Several of the components for the workbench application are common to any transaction processing application. The logging, error handling, database, registry, translation, and binary resource handling services outlined in the Layered Paradigm are a good starting point. However, there are several other services that the workbench framework will need to provide. Some examples of these services are access to menus, tool bars, shared data, and so on. I use the term services here and not components because these services will be used only in workbench applications, whereas components are designed to be used in any application. The fundamental approach to successful workbench design is not deciding what cool stuff to add to the workbench, but avoiding adding limitations.
The services of a workbench typically end up defining each other as the features of the specific workbench implementation are extended. Because the services tend to depend heavily upon each other, there is usually not much overlap between the different implementations of specific workbench services. What I mean is that when two different people start laying out frameworks, the choices they make first will be heavily built upon later. As the frameworks progress, their features are usually radically different. Because the two implementations have fundamental differences, it becomes almost impossible to use the same techniques in separate frameworks. This might sound obvious, but it really isn't. We usually think, "This is a modular design. If one piece doesn't work, or isn't perfect, I'll just pull it out and fix it. No problem." And that's valid when you are talking about components (components are, for the purposes of this discussion, by definition not foundational to a workbench). However, with foundational services, the decisions being made are much more critical. As I go through the other parts of a workbench, I hope this will be impressed on you all the more.
Sharing user interfaces from a workbench perspective isn't all that different from sharing other services that don't have interfaces. The hardest part is providing a generic access mechanism that minimizes the need for state tracking, branching, or error handling. Personally, I have always found that tracking state or dealing with conditional returns is a pain in the neck. So whenever possible, I try to get out of having anything to do with handling these issues. Here are a few techniques that you can use when developing interfaces for shared users:
I'll discuss each technique in detail in the following sections, but I wanted to call your attention to something to remember as you evaluate the following techniques. These techniques aren't relevant because of the features they provide, but for the limitations they overcome. Sharing user interface designs is always about removing obstacles, and only after that can it be about adding features.
This is an extension to many of the encapsulation techniques taught today. Don't just encapsulate variables or steps in a process, but limit the responsibility of worker code as well. It has to do with how errors are handled and allowed. The basic premise that you should be operating under is that the user interface doesn't have to succeed or even exist for the operation to complete successfully. When calling a status update event from the middle of some worker code, what do you care if the interface update is successful or not? You shouldn't even care if the interface actually exists or not! You just diligently call the status routines and the logging routines. If the system allows for status and logging, all the better. If not, it's no skin off your back. It all comes down to limiting the responsibility of worker code. Several techniques to implement this are explained in detail in the Client/Server Solutions series, specifically "Client/Server Solutions: Implementing the Layered Paradigm."
This technique boils down to a single operating assumption. In your design, children shouldn't know who their parents are, and likewise parents should not be privy to the details of their children. An example of this can be found in the way status displays are handled in the Component Shell (see "Client/Server Solutions: Implementing the Layered Paradigm"). It is pretty much each individual routine's responsibility to worry about setting the status displays. Any routine can set the status display to whatever it requires and reset it to the default when finished. If an operator routine is calling into a worker function, then it is assumed that the worker function can party on the status display all it wants. It is the operator routine's responsibility to update the display when the worker function returns if the operator routine so desires. Well-behaved operator routines make no assumptions about what the worker routines will do. In this case, as in the previous one, the entire implementation comes down to limiting the responsibility of operator or controller code.
Rather than have code that directly sets flags or status indicators (a common practice today), use methods to perform the same functions. This way, when the logic behind deciding when to switch states or set flags grows or changes, the impact can be isolated to a single routine or set of routines outside of critical worker code. An easy way to accomplish this is through the use of property procedures.
Here is where workbench implementations become interesting. Object management services are essentially where the connection between the workbench and the functional areas is managed. There are several aspects of this relationship. Before we talk about the process of literally managing the objects that represent the functional areas, there is another fundamental issue to be addressed.
Of the many parts in a workbench, the one that is probably the most important concerns the ownership of forms. In most workbench implementations, the forms for a specific functional area are either owned by that functional area or they are owned by the workbench alone. If the forms are owned by the workbench, then access to the forms is through automation interfaces. If the forms are owned by the functional areas, then the functional areas must be out-of-process servers. Theoretically, the functional areas could all use modal forms, but this is generally not recommended. (For more information on this, see the Visual Basic 4.0 Enterprise Edition documentation on creating OLE servers [Product Documentation, Languages, Visual Basic 4.0 Professional and Enterprise Editions, Creating OLE Servers].) When the forms are owned by the workbench, the functional areas may be in-process or out-of-process servers. The following diagram illustrates the two types of form ownership discussed here.
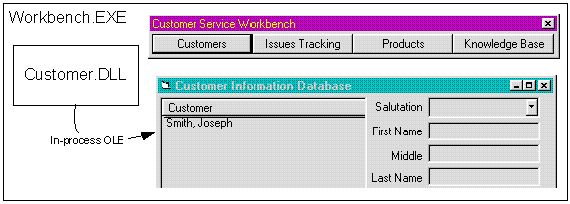
Figure 2. In-process interface sharing
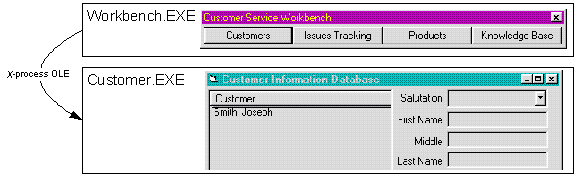
Figure 3. Cross-process interface sharing
So the two realistic approaches toward solving this problem lead down very different paths. One has all the functional areas implemented as out-of-process servers. In the other, all the functional areas may be implemented as in-process servers. See how the entire workbench solution will hinge to some extent on how you deal with this single issue?
This part of the workbench causes the functional areas to connect and communicate with the workbench or each other. There are many ways to approach this interface, and it is built around the previous issue of form ownership. The hinge point is this: Regardless of where the forms are owned, are the functional areas to be implemented as in-process or out-of-process servers? Another less obvious point of interest is that while having forms reside outside the workbench will require a separate out-of-process server, this server does not have to actually be a functional area. All of these issues distill clearly into decisions about which limitations you cannot accept, rather than decisions about which features you want to include.
If the functional areas are to be implemented as out-of-process servers owning their own forms, then a common technique is to store references to each functional area in a collection maintained by the workbench. A reference to this collection is passed to each functional area when it is initialized. The keys for the collection are published as functional areas are defined. This way, any functional area can access any other functional area simply by referencing the collection based on the key.
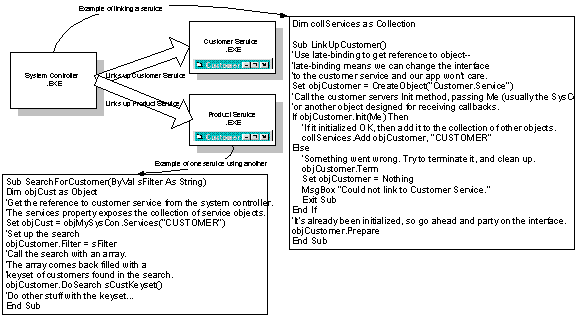
Figure 4. An example of using out-of-process servers for functional areas
This is by far the easiest of the object management schemes, but it is not without its drawbacks. It requires that every functional area be an out-of-process server and provide a published interface as part of its contract with the workbench. Using an out-of-process server will make it easier to code the functional area, but it can cause performance issues when it is dealing with shared services. Of course, if services aren't shared this isn't an issue, but it complicates the interface between the functional area and the workbench. The key to this decision comes down to making smart trade-offs.
In a situation where the functional areas are implemented as in-process servers, the work of juggling the object references can be abstracted to the same level of simplicity as in the previous example. Doing this requires quite a bit more work in the workbench and makes the implementation of the components a little more abstract. The primary task here is that the forms provided by the workbench must be abstracted and proctored to the functional areas. This task must be contained within a code base provided by either the workbench or abstraction layer. There are many techniques for doing this and they each have positive and negative aspects. The following diagrams will illustrate the important variations.
Workbench provides generic forms only
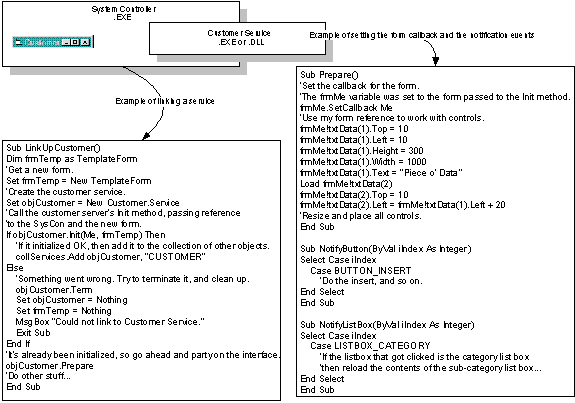
Figure 5. An example of implementing cross-process interfaces
In Figure 5, the forms are generic and provided by reference to the functional area servers. The server is responsible for adjusting the form to look right and for handling the notification events. All notifications are done through the generic notification methods. In this example, a double reference is used to perform the synchronization between the functional code and the form. The operational sequence goes something like this:
This technique can take a bit of coding to do the form adjustment correctly and get the notifications worked out. But a code generator would do the former, and patience mixed with good design would take care of the latter. The main advantage of this technique is run-time flexibility or causing the minimum impact when recompiling a functional area. While this approach could use in-process or out-of-process servers, using out-of-process servers would sacrifice run-time performance for the ability to do independent recompilation.
Using forms-only out-of-process server
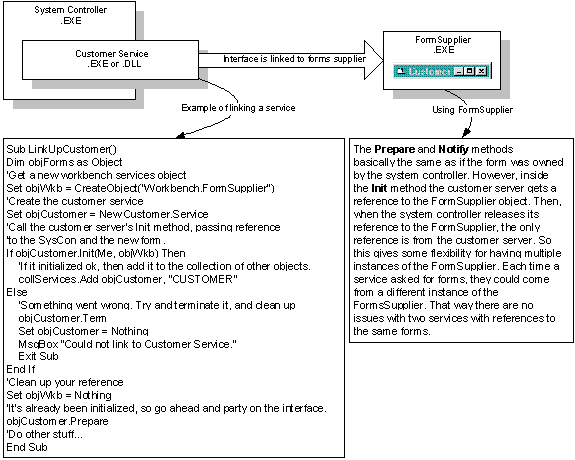
Figure 6. An example of using a forms-only out-of-process server
In this diagram, the forms are provided by a separate out-of-process server. The forms are precoded, and they are requested by key from the out-of-process server. Because the forms are precoded, there is no need for the functional area to manage what the interface looks like. Notifications are still required. In this way, you save on development time and increase performance, while sacrificing the run-time flexibility of the workbench. The main advantage here is that the forms are in a separate process. A side effect is that the forms can be recompiled without change to the workbench or the underlying servers.
There is another elegant technique to bring up at this point. It inverts the ownership lines in the workbench, so it can be a little confusing. The general model would look like the following, but like the preceding techniques it can have variations.
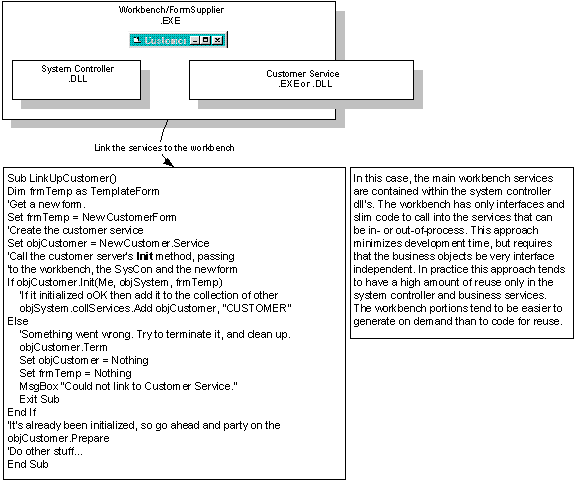
Figure 7. An example of an inverted workbench design
This technique is used when you want to have workbench code that doesn't need to be recompiled to add services. Only the noncritical middle layer is recompiled when services are modified. This technique can be really helpful anywhere you need flexibility to decide which components have to be recompiled for services to be added or modified. You can see examples of this in the Component Shell (an implementation of the Layered Paradigm), where binary resources are compiled into a separate DLL that can be recompiled with the same GUID. That way, you have the ability to swap components while affecting the minimum amount of code. The key here is to pick an interface and keep it unchanged. As long as the interface stays the same, the DLL can keep the same GUID.
It is important to realize that the benefits of the techniques described above cannot always be measured in terms of development time or run-time performance. Often you will find that in practice, certain frameworks lend themselves more easily to cross-project reuse according to the dynamics of your particular development team. The reverse can also be true, in that certain techniques, while valid or optimal in terms of performance, can go against the working dynamics across development teams. Because of this, it is important to evaluate a technique not only on its run-time or development performance, but also on the ability of your team and others to leverage existing code bases and to reuse them in future implementations.
If you must evaluate techniques strictly on their implementation merits, remember the key performance and development time trade-offs discussed earlier with the primary approaches to the functional area interfaces issue. These boil down to the fact that when using in-process servers for functional area interfaces, if at any time the interface changes or services need to be added, a recompile of some portion of the workbench is required. However, with out-of-process servers this is not the case. In a smart implementation, the object management routines in the workbench can be driven off text information that identifies the servers and classes for the workbench. This information can be stored in the registry, a database, resource file, or whatever, and used at run time to populate the object references. But for this type of flexibility in your system, a sacrifice must be made. In this case, you need to choose between run-time performance and abstraction layers. The one thing to take away from this discussion is this: The key to choosing the technique that is best for you is knowing that you will be sacrificing features, rather than including features.
In the end, there are really only two key questions that will influence the entire system. These are "Who owns the forms?" and "Are the servers for the functional areas going to be in-process or out-of-process servers?” When answering these questions, remember that it is usually not so much a matter of identifying which features you want, but identifying those features you cannot afford.
This article illustrates many techniques and variations for drawing the ownership lines and making these decisions. As you try to apply these techniques and approaches to your daily tasks, keep in mind that success lies in answering the general questions, not the specific. Work through the foundational decisions before attempting to specify the particular features of the system. I am certain you will find that once these issues have been worked out, everything else will become either an exercise in good client/server development or an extension of the Layered Paradigm.