Kraig Brockschmidt
Microsoft Corporation
Created: October 1994
This paper is adapted from an article appearing in Dr. Dobb's Journal, the newsstand special edition, December 1994. Kraig Brockschmidt is the author of Inside OLE 2.
This article examines the OLE technologies that build upon the Component Object Model (COM): structured storage and object persistence; monikers; uniform data transfer and OLE Drag and Drop; OLE Automation; OLE Documents; and OLE Controls. OLE is about integrating components whose features and capabilities can evolve over time. Creating or using a component that employs the technologies listed above is really just a matter of choosing which interfaces you apply.
OLE and the technologies that fall under the OLE umbrella are all about integration between functional components of all sorts, wherever they may be—in the system or inside applications, inside in-process DLLs or out-of-process .EXE files, and in the near future, even in modules distributed across a network. The basis for all the integration is the Component Object Model, COM, that is described in "The Component Object Model: A Technical Overview." OLE uses COM as the low-level plumbing that enables transparent communication between components through a binary standard of interfaces; as COM evolves, OLE will automatically benefit and be extended to support diverse system services, from database access to messaging services to system management and more.
OLE's history is one concerned primarily with the creation and management of compound documents, but OLE is much, much more than that. As mentioned above, OLE is about integration between components, and those components come in many shapes and sizes, and the interfaces provided on those components vary just as greatly. In some cases, a particular component is implemented by OLE itself (to form a standard on which applications can depend), and other times, components are implemented by various types of applications. Components that are primarily users of interfaces implemented on other components are called "clients" or "containers," depending on what they do with those interfaces. Modules that implement components with interfaces are called "servers." All components based on COM are called component objects because they support fundamental notions of reusability, encapsulation, and polymorphism. For convenience, the use of the word object by itself in this article means "component object." How COM provides the ability for components to support these things is described in "The Component Object Model: A Technical Overview," but a few points deserve reiteration.
First, OLE and COM were specifically designed to facilitate legacy code, that is to facilitate adding integration features to existing programs without requiring a major redesign or rewrite. Designers can identify portions of their applications that are encapsulated enough to call component objects or identify features in an application that could benefit from using other components and implement OLE and COM interfaces on top of the existing code to enable integration.
Second, OLE exploits the existing operating system APIs as much as possible: OLE on Windows uses the Win32® API (or Win16 on Microsoft® Windows® version 3.1) and OLE on the Macintosh® uses the Macintosh API. OLE does not introduce its own APIs that are redundant with the operating system because, again, OLE is an integration technology designed to work with the thousands of applications that exist today.
Third, OLE and COM allow components to share the same process space or to exist in different process spaces, and in the future COM will allow components to interoperate even when executing on different machines altogether, but these differences are transparent to the programmer who is creating a component or writing code that uses another. A client application can protect itself from in-process components that might crash the whole process; in-process components can be used for increased performance when they are trusted. The ability to create out-of-process components is essential to a integration technology that can work with existing applications. Those applications are almost all implemented today as separate processes, so OLE allows you to slip the integration interfaces right in on top of that without major changes.
Finally, one of the most important aspects of OLE and COM is the ability to evolve functionality in components over time and deploy or redeploy those components in a robust fashion. The issues and problems surrounding the evolution of functionality over time has been treated in "The Component Object Model: A Technical Overview," but the major point to remember here is that OLE is not an all-or-nothing technology: When using or implementing a component, you have the ability to use as little or as much of OLE as is appropriate to your needs.
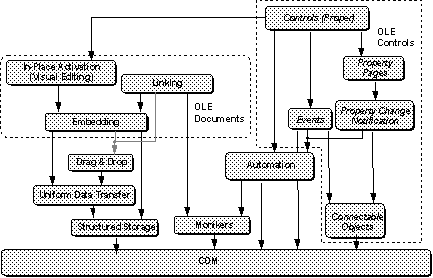
With that said, the purpose of this article is to now examine the OLE technologies that build upon COM as illustrated in Figure 1:
Figure 1. All OLE technologies build upon COM and one another.
We will look at each technology and what it means, and in the process we'll see that OLE is about much more than just compound documents—though compound documents are still important. OLE is about integrating components, and creating or using a component that supports the features listed above is really just a matter of choosing which interfaces you apply. OLE itself supplies the communication guts for working with interfaces, defines the rules for their use, and implements some components as a standard. OLE also provides core API functions that facilitate the interaction among various sets of interfaces on different components.
Once upon a time, programmers treated magnetic media as an addressable byte array: This or that piece of information was in this or that offset in this or that sector. While this was manageable for an application that used little data and completely owned the media, it didn't work for a system in which many applications shared the media. Thus were invented file systems, such as the file allocation table (FAT) file system, that put a layer of abstraction between the application code and the absolute disk sectors where the information is stored. An application created a "file," which it saw as a contiguous byte stream, but the file system would actually write that stream to possibly disparate sectors on the disk. The abstraction layer isolated the application from having to care about the absolute layout.
The advent of operating systems required the ability for multiple applications to share a common disk drive. Today's world of component integration with OLE requires the ability for many components to share a common byte array, be it a disk file or a record in a database, where each component needs its own bit of storage in which to save its persistent state. OLE's structured storage is the new abstraction layer for accomplishing this level of integration and can be built on top of any file or other storage system as illustrated in Figure 2 for a hard disk system.
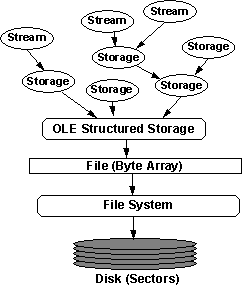
Figure 2. Structured storage sits above a file as a file system sits above a disk volume.
In structured storage, any byte array can be structured into two types of elements: storages and streams, where each element has a name (up to 31 Unicode characters). Storages implement the interface IStorage, which has directory-type functions for creating, destroying, moving, renaming, or copying other elements. Streams implement IStream with file I/O type functions like read, write, seek, and so forth. In fact, IStream members have a direct one-to-one correspondence with file I/O functions in Win32 and the standard ANSI C run-time library. Figure 3 illustrates Win32 and IStream similarities.
BOOL MyObject::ReadFromFile BOOL MyObject::ReadFromStorage
(LPSTR pszFile) (LPSTORAGE pIStorage)
{ {
OFSTRUCT of; HRESULT hr;
HFILE hFile; IStream *pIStream;
UINT cb=-1; LARGE_INTEGER li;
if (NULL==pszFile) if (NULL==pIStorage)
returnFALSE; return FALSE;
hFile=OpenFile(pszFile,&of,OF_READ); hr=pIStorage->OpenStream("MyStruct", 0
, STGM_DIRECT | STGM_READ
| STGM_SHARE_EXCLUSIVE, 0
, &pIStream);
if (HFILE_ERROR==hFile) if (FAILED(hr))
return FALSE; return FALSE;
cb=_lread(hFile, (LPSTR)&m_data hr=pIStream->Read((LPVOID)&m_data
, sizeof(MYSTRUCT)); , sizeof(MYSTRUCT), NULL);
_lclose(hFile); pIStream->Release();
return (SIZEOF(MYSTRUCT)==cb); return (SUCCEEDED(hr));
} }
Figure 3. Comparison of code to read a structure from a Win32 file and from a stream.
A storage can contain any number of other storages and streams within it, just a like a directory can contain files and subdirectories. But a storage isn't restricted to being disk-based only: Structured storage can be implemented on top of any byte-oriented storage system (or byte array), such as a disk file, a block of memory, or a database field. Regardless of the medium, however, structured storage provides uniform access through the standard IStorage and IStream interfaces. The storage model also defines transactioning for these elements, where you can create or open an element in "transacted" mode (in which changes are not permanent until committed) or "direct mode" (changes are immediately permanent).
Practically, this is a "file system within a file" with incremental access to elements and the exact layout of the file being left to the system. With such a system, the application can effortlessly give individual streams or even entire storages within the file to other components in which those components can save whatever persistent information they desire.
This system is perfect for creating compound documents, and OLE Documents make use of the structured storage technology. To further facilitate the creation and sharing of compound documents, even between applications on different platforms, OLE provides a standard implementation for disk-based storages and streams in what is called compound files, which is compatible with future versions of Windows (the same people are writing it). Microsoft provides the implementation for Windows and Macintosh and licenses the portable ANSI C/C++ source code to other vendors (preferably operating system vendors) who would like to supply it on other platforms.
A major benefit to having a single standard implementation of structured storage on a given platform (and between platforms) is that any application, including the system shell, can open and navigate through anyone's compound file. Elements of data are no longer hidden inside a proprietary file format; using OLE, you can browse the hierarchy of storage and stream elements. With additional naming standards and standardized stream formats for specific information, any application can glean much more information from some random file, without having to load the application that created it.
The next version of Microsoft Windows, Windows 95 (code-named Chicago), will exploit this browsing ability by offering shell-level document searching. Windows 95 will look in compound files for a stream called "Summary Information" where applications store (in a standard but flexible way) data like creation and modification times, author, title, subject, revision number, keywords, and so forth. Windows 95 then matches this information against a user query. So what was once a feature buried inside applications for one document type is now a standard part of the system itself for all documents and is open to future enhancements such as full-content searches.
We've seen that structured storage is necessary to allow multiple components to share the same disk file or other mass of storage. A component indicates its ability to save its persistent state to a storage or stream by implementing the interfaces IPersistStorage or IPersistStream, respectively. (There is also an IPersistFile interface for components that save to separate files.)
The container application that manages such "persistent" objects creates the instances of IStorage or IStream to give to components that implement IPersistStorage and IPersistStream. The container tells components to save or load their persistent states from the storages or streams. Thus, the container remains in control of the overall document or file, but gives each component individual control over a storage or stream within that file. This tends to make structures within a file more intelligent, that is, placing more of the code that knows how to handle the structures into component objects rather than in the container.
As an example, the code in Figure 4 shows how a container would open an IStorage and have a component save into it through IPersistStorage. If the component doesn't support IPersistStorage, the container, for lack of an interface pointer, cannot possibly try to save the component that way. This shows the power of QueryInterface: You can't ask something to do an operation it doesn't support. Of course, a container could take a failure to find IPersistStorage as an indication to look for IPersistStream instead and use that as an alternate.
BOOL SaveObject(IStorage *pIStorage, IUnknown *pObject)
{
IPersistStorage *pIPS;
HRESULT hr;
hr=pObject->QueryInterface(IID_IPersistStorage, (void **)&pIPS);
if (SUCCEEDED(hr))
{
hr=pIPS->Save(pIStorage);
pIPS->SaveCompleted(NULL);
}
return SUCCEEDED(hr);
}
Figure 4. Saving persistent data through IPersistStorage.
Think for a moment about a standard, mundane filename that refers to some collection of data that is stored on disk somewhere. The file name essentially describes the "somewhere," and so the name identifies a file that we could call an "object" (in a primeval sort of way). But this is somewhat limited—filenames have no intelligence because all the knowledge about how the name is used and stored exists elsewhere in whatever application uses that filename. This normally hasn't been a problem because most applications can deal with files quite readily.
Now think about a name that describes the result of a query in a database or one that describes a range of spreadsheet cells or a paragraph in a document. Then think about a name to identify a piece of code that executes some operation on a network server. Each different name, if unintelligent, would require each application to understand the use of that name. In a component integration system, this is far too expensive. To solve the problem, OLE has "persistent, intelligent names," otherwise known as "monikers."
A moniker is a component that encapsulates a type of name and the intelligence to work with that name behind an interface called IMoniker. Thus users of the moniker pass control to the moniker whenever they want to work with the name. While IMoniker defines the operations you can perform with a moniker, each different moniker class defines what data makes up the name and how that name is used in binding. A moniker also knows how to serialize itself to a stream as IMoniker is derived from IPersistStream.
The most basic operation in the IMoniker interface is that of binding to the object: IMoniker::BindToObject, which runs whatever algorithm is necessary in order to locate the object of reference and returns an interface pointer to the component that works with that information (this pointer is unrelated to the moniker itself). Once a client has bound to the referenced object, the moniker falls out of the picture entirely.
Other operations besides serialization include binding to an object's storage and generating a human-readable display name from the name stored in the moniker. There are many more functions as well, all in the IMoniker interface.
OLE defines and implements five basic type of monikers: file, item, anti, pointer, and generic composite. A file moniker maintains a text filename persistently, and binding means to locate a suitable application and have it load the file, returning an interface pointer to the "file" object. Item monikers are used in conjunction with file monikers to describe a specific part of a file that can be treated as a separate "item" object. To put a file and item moniker together requires the generic composite. This type exists only to contain other monikers, including other composites, and its persistent data is just the persistent data of all the contained monikers in series (separated by a delimiter). Binding a generic composite means binding those it contains in turn.
A composite moniker is used whenever the thing to which you want to create a reference cannot be described by a single simple moniker. A range of cells in a sheet of a Microsoft Excel workbook requires a file moniker to identify the workbook, an item to identify the sheet, and an item to identify the range in the sheet. Such a composite moniker is illustrated in Figure 5. Code that would create this moniker is shown in Figure 6.

Figure 5. A sample composite moniker with a file and two item monikers to identify a range of cells in a particular sheet of a spreadsheet file.
IMoniker * MakeMonikerToRange(char *pszFile, char *pszSheet, char *pszRange)
{
IMoniker *pmkComp, *pmkFile, *pmkSheet, *pmkRange;
pmkComp=NULL;
//"!" is a delimeter between monikers
if (SUCCEEDED(CreateItemMoniker("!", pszRange, &pmkRange)))
{
if (SUCCEEDED(CreateItemMoniker("!", pszSheet, &pmkSheet)))
{
if (SUCCEEDED(CreateFileMoniker("!", pszFile, &pmkFile)))
{
//This creates a File!Item(Sheet) composite
if (SUCCEEDED(CreateGenericComposite(pmkFile, pmkSheet
, &pmkComp)))
{
//Tack on the range to the File!Item(Sheet)
if (FAILED(pmkComp->ComposeWith(pmkRange, FALSE)))
{
pmkComp->Release();
pmkComp=NULL;
}
}
pmkFile->Release();
}
pmkSheet->Release();
}
pmkRange->Release();
}
return pmkComp;
}
Figure 6. Code that creates a composite moniker with a file and two items.
The anti moniker and pointer monikers are special types that either annihilate the last moniker in the series in a composite (anti) or wrap an interface pointer into a moniker (pointer) where binding is nothing more than a QueryInterface call. These are provided for uniformity, and neither can be stored persistently.
Of course, if OLE's standard monikers are not suitable for your naming purposes, you can always implement your own moniker component with IMoniker. Since you encapsulate your functionality behind the interface, your moniker is immediately usable in any other application that knows how to work with IMoniker.
Working with monikers is generally called "linking," the moniker's information being the link to some other data. OLE uses monikers to implement linked compound document objects, which involves other user interface standards for managing links. OLE also implements a central "running object table" in which is stored the monikers for already running objects. This can prevent a lot of excess processing when a file is already loaded or other data is already available in some other application. Monikers internally use this table to optimize their binding sequences, and you can use the table yourself.
Structured storage and monikers are about integrating storage and references to storage, but once you have a component that can read from that storage, you would normally like to have it render data for you. OLE's Uniform Data Transfer mechanism is the technology for data transfers and notifications of data changes between some source, called the data object, and something that uses the data, called the consumer. All of this happens through the IDataObject interface implemented on the data object. IDataObject includes functions to get and set data, query and enumerate available formats, and to establish a notification loop with the data source.
The "uniform" arises from the fact that IDataObject separates exchange operations (get, set, etc.) from specific transfer protocols like the clipboard. Thus a data source implements one data object and uses it in any OLE transfer protocol: clipboard, drag and drop, or compound documents. The OLE protocols (unlike the existing Windows protocols) are only about getting an IDataObject pointer from the source to the consumer. Once transferred, the protocol disappears, and the consumer only deals uniformly with IDataObject. So source and consumers can implement a core set of functions based on IDataObject and build little protocol handlers on top of that core.
Besides the separation of transfer from protocol, OLE also makes data transfer much more powerful and flexible with two data structures: FORMATETC and STGMEDIUM. FORMATETC (Format, etc.) improves on the "Clipboard format" of Windows (with analogs in other systems), which only describes the layout of a data structure—CF_TEXT, for example, describes a null-terminated ANSI character string. FORMATETC improves this by adding a detail field (full content, thumbnail sketch, etc.), a device description (the device for which the data is rendered), and a transfer medium identifier.
This last field brings us to STGMEDIUM, an improvement over the global memory handle. In existing Windows protocols, you must always exchange data using global memory. This is very inefficient for large data. With STGMEDIUM you can reference data that is not only in global memory but that which exists in any other medium, such as a disk file or an IStorage or IStream (whatever byte array they are sitting on).
The combined effect of FORMATETC and STGMEDIUM is that, when you have data that is most appropriately exchanged on a specific medium, you can keep the data on that medium and still ship it off to other applications. This can lead to tremendous performance gains for applications that were, up to now, forced to load large data sets into global memory, just to have them swapped out to the disk again (virtual memory paging)! This overhead is what OLE helps you avoid.
Other OLE technologies build upon the Uniform Data Transfer concepts, so you can take advantage of the improvements for however you transfer data.
First, the OLE DLLs provide functions to work with the system clipboard through IDataObject. A source cuts or copies data by packaging data into a data object and handing an IDataObject pointer to OLE's OleSetClipboard function. OLE, in turn, makes the formats therein available to all other applications (non-OLE applications can only see global-memory based formats). When a consumer wants to paste from the clipboard, it calls OleGetClipboard for an IDataObject representing the clipboard contents. With that interface it check formats or request a rendering. Any data placed on the clipboard by non-OLE applications are completely available through this interface. So toss the old clipboard code and commit completely to the more powerful OLE mechanism!
Another technology that builds on data transfer is OLE's drag-and-drop feature, really nothing more than a slick way to get an IDataObject pointer from a source to a consumer or "target." The source decides what starts a drag and drop (usually a mouse click + move in a specific place). It then packages up its data into a data object—exactly as it does for the clipboard!—and calls OLE's DoDragDrop, passing a pointer also to its implementation of the IDropSource interface. Through this interface, the source controls the mouse cursor and the time a drop or cancellation happens.
The target, on the other hand, implements the interface IDropTarget and registers it with OLE for a specific window. When the mouse moves over that window, OLE calls functions in that IDropTarget according to what is happening with the mouse: enter window, move in window, leave window, or drop.
In these functions, the target indicates the effect of a drop at the mouse location point, modified by the ctrl and shift keys. Valid effects are a move (no keys), copy (ctrl), link (shift+ctrl), or "no-drop," described using DROPEFFECT_* flags. The effect is handed back to the source to indicate which cursor to show, such as those in Figure 7. These default cursors are handled by OLE itself, leaving little for the source to do as shown in the typical six-line implementation of IDropSource (excluding IUnknown functions) in Figure 8. Sources do have the ultimate say in which cursor is shown, of course.
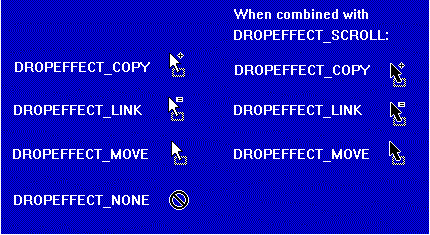
Figure 7. Cursors used in Drag and Drop
STDMETHODIMP CDropSource::QueryContinueDrag(BOOL fEsc, DWORD grfKeyState)
{
if (fEsc)
return ResultFromScode(DRAGDROP_S_CANCEL);
if (!(grfKeyState & MK_LBUTTON))
return ResultFromScode(DRAGDROP_S_DROP);
return NOERROR;
}
STDMETHODIMP CDropSource::GiveFeedback(DWORD dwEffect)
{
return ResultFromScode(DRAGDROP_S_USEDEFAULTCURSORS);
}
Figure 8. The usual implementation of an IDropSource interface.
Note that DoDragDrop, besides watching mouse motion and the ctrl and shift keys, also watches the esc key (used to cancel the operation) and the mouse button for a "up" message to cause a drop, as illustrated in Figure 9.
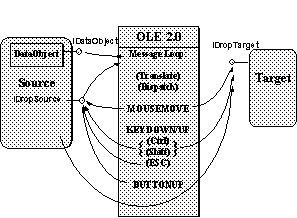
Figure 9. The DoDragDrop function enters a message loop that watches the mouse and keyboard and calls IDropSource and IDropTarget functions.
When a drop occurs on a target, that target just ends up with the source's IDataObject pointer—exactly the state as after a call to OleGetClipboard. At this point the transfer protocol again disappears and the consumer is left to deal with only IDataObject. The same is true for the source, which packages data into a data object for clipboard or drag and drop. Add to that the fact that drag and drop works equally well within an application as between applications, you get loads of mileage from one piece of code. The icing on the cake is that by adding a few formats for compound document objects, you can suddenly start exchanging compound document objects using the same protocols and the same code!
Consumers of data from an external source might be interested in knowing (asynchronously) when data in that source changes. OLE handles notifications of this kind through a component called an advise sink, which implements an interface called IAdviseSink. This "sink" absorbs asynchronous notifications from a data source and can also receive a new copy of the data if it desires. The consumer that implements the advise sink connects it to the source's IDataObject through a member function called DAdvise (disconnection happens through DUnadvise), and the consumer indicates whether it would like a fresh data rendering on the change. When the data object detects a change, it then calls IAdviseSink::OnDataChange to notify the consumer as illustrated in Figure 10.
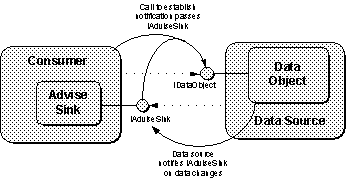
Figure 10. A source notifies a consumer of data changes through IAdviseSink.
The IAdviseSink interface actually contains more member functions than are used with other interfaces (such as IViewObject for notifications when a component's display image changes and IOleObject for state changes in compound document objects). But in any case, it's not made to handle arbitrary notifications from arbitrary components. That requires "events," which are introduced with OLE Controls (but more fundamental than controls, of course!).
Another key part to integrating components is the ability to drive them programmatically, that is, to control them without requiring an end user's presence. In more technological terms, it means having various components expose their end-user level functionality (like menu commands and working with dialog boxes) via interfaces such that some scripting tool can be used to invoke that functionality in some sequence.
We immediately see two sides to this picture. On the one hand, we have components that are "programmable" via interfaces, which we call automation objects. On the other, we have some application that provides a programming environment in which a developer or other advanced user can write scripts or create applications that use those automation objects' interfaces. We call these automation controllers. Moreover, the objects need a way in which to programmatically publish their interfaces (the methods' names and parameter type, as well as object properties) at run time such that the controller can perform type checking and can present lists of callable functions to the programmer.
The technology that supports doing this is OLE Automation, primarily through an interface called IDispatch. Applications that want to expose functionality for various application objects (like the frame, document windows, parts of the document, and so forth) implement IDispatch on each of those components. But IDispatch has a fixed set of member functions—how, then, does each component supply its unique functions?
The answer is an OLE Automation entity called the dispinterface. A dispinterface is an implementation of IDispatch that responds to a specific set of custom functions. An application frame and a document would both implement IDispatch but would have different dispinterfaces.
How this works involves the function IDispatch::Invoke, the prototype for which is shown in Figure 11. The dispID parameter (the "dispatch identifier") tells Invoke which method is being called or which property of this object is being retrieved or set; the wFlags parameter indicates whether this call to Invoke is a method call or a property get or set operation. An object's dispinterface, then, is primarily the set of dispIDs to which the object will respond through Invoke, and this varies from object to object, of course. Since some methods take parameters, and properties have types associated with them, the dispinterface also includes all of this "type information." Other functions in IDispatch make the type information available to automation controllers. so those controllers can use the types to enhance their programming environments.
interface IDispatch : public IUnknown
{
...
virtual HRESULT Invoke(DISPID dispID, REFIID riid, LCID lcid,
WORD wFlags, DISPPARAMS *pdispparams, VARIANT *pvarResult,
EXCEPINFO *pexcepinfo, UINT *puArgErr)=0;
}
Figure 11. Signature of the IDispatch::Invoke function.
When creating an automation object, you create a file using the Object Description Language (ODL) to define a dispinterface. This file is then run through a special compiler that generates a "type library" that contains all the type information for any number of automation objects and dispinterfaces. This type library, which can be kept in a separate file or attached to a server module (DLL or EXE) as a resource, provides a way for automation controllers to discover which automation objects and dispinterfaces are available without actually having to instantiate components just to ask for the information through IDispatch.
The type library itself is a component, but one that implements the interfaces ITypeLib, ITypeInfo, and ITypeComp. You generally never have to write code for these interfaces; OLE provides the implementations that work on any underlying type library. Automation controllers use these interfaces to navigate through all the information in the library so as to present the programmer with lists of callable functions on an object, to extract parameter types to perform checking, and so forth.
Visual Basic® (and Visual Basic for Applications) is one of the primary automation controllers available today. When you run a piece of Visual Basic code such as that shown in Figure 12, Visual Basic will translate the method calls and property manipulations in the Visual Basic code that uses the dot operator into IDispatch::Invoke calls to the component in question. Ultimately, all the calls are being made through the binary standard of interfaces, so Visual Basic doesn't care what language was used to implement the automation object.
Sub Form_Load ()
Set Cube = CreateObject("CubeDraw.Object") 'Creates the automation object
'Each line of code here calls IDispatch::Invoke with different flags
x = Cube.Theta '"Get Property" on "Theta"
Cube.Declination=.0522 '"Set Property" on "Declination"
Cube.Draw 'Method call
End Sub
Figure 12. Visual Basic code that translates to IDispatch calls.
This illustrates the integration power of automation: Visual Basic can create and manage many automation objects from many different applications at once and use them to programmatically combine information from a variety of sources. Automation is exceptionally powerful for corporate developers who are using off-the-shelf applications like Microsoft Word and Shapeware's Visio™ to create custom business solutions. Adding automation support to an application opens up that application to a tremendous number of new uses. In addition, corporate developers can encapsulate business logic into components and make this functionality accessible through high-level third-party tools, including fourth generation programming languages and even productivity application macro languages.
Built on top of structured storage, Uniform Data Transfer, and monikers, is the concept of OLE Documents, OLE's support for the creation and management of compound documents. In this there are two primary types of components. The container is the piece that controls the document and manages the relationships between the pieces of information in that document, such as layout. Compound document objects are the pieces that make up the data put into that document, and those pieces are supplied by servers (be they DLLs or EXEs).
OLE Documents is thus a way to integrate containers and servers through the medium of compound document objects. The objects themselves can be shared in two ways. The first is embedding, where the entire object is embedded within the container; that is, the object's persistent state is kept in the document itself. Embedded objects always implement the IPersistStorage interface for this purpose, and containers that support embedding typically use a compound file to provide IStorage instances to embedded objects (but they don't have to).
The other way to share an object is linking, where an image of the object is cached in the container document along with a moniker that refers to the location of the object's actual data; that is, the object's persistent state exists elsewhere, and the moniker is stored in the document instead to provide the "link" to that data. Since a moniker can be as complex as desired, the path from the compound document to the source of the link can be very complex. Therefore, a document can contain linked objects to things as simple as a file or as complex as a cell in a table in a document that is embedded within an email message that exists in a particular field of a database on a particular network server. Monikers impose no limits.
Also, while embedding is normally optimal for objects with small data sets, linking is more efficient for large data sets, especially ones that are shared between multiple users on a network—each link is a reference to a single source, whereas embedding the data would mean making a copy.
Compound document objects are nothing more than the regular type of OLE objects only with a particular combination of interfaces as shown in Figure 13 along with the interfaces a container exposes to its objects. Note that the object interfaces shown in Figure 13 are those as seen by the container. Those in parentheses are implemented only by objects in DLLs; those in EXEs implement only the unmarked interfaces and rely on DLL "object handlers."

Figure 13. The interfaces of a compound document object and container.
The most important ones of the set are IPersistStorage, IDataObject, IViewObject2, and IOleObject. The first two interfaces mean that compound document objects support persistence to IStorage elements and that they support exchange of their data, primarily bitmap and metafile renderings of their display images that can be cached in the document. Caching allows the container to open a document for viewing or printing even when the code to handle the object is unavailable—the cached images are suitable for these purposes.
IViewObject2 indicates the ability for the object to render itself directly to an hDC, usually the screen DC of the container's display or a printer DC on which the document is being printed. This gives very fine control for rendering quality to the object itself. It is not an interface limited to compound documents, mind you, as any object can implement it to express this ability. Compound document objects implement it as part of the OLE Documents standard.
IOleObject is the primary (and rather sizable) interface that says "this object supports the OLE Documents standard for compound documents." A container uses this interface for many purposes, the most important of which is activation. Activation means to instruct the object to perform some action, called a verb. The container will, as part of its user interface, show these verbs to the end user and forward them to the object; then the user selects them. The object has full control over what verbs it wants to expose. Many objects have an "Edit" verb which means "display some window in which this object's data can be modified." Others, like sound and video clips, have a "Play" verb which means "play the sound" or "run the video." So while the object defines which verbs it supports and what those verbs mean, the container is responsible for making the commands available to the end user and invoking them when necessary. That's all part of the standard.
Note that on the other side of the picture, the container has to provide a "site" object for each embedded or linked object in the container where that site implements the interfaces IOleClientSite and IAdviseSink. The latter interface is how the container knows when the object's display changes and can update its own display and the cache. IOleClientSite provides container information to the object.
In cases other than playing a sound or a video clip, activation of an object generally requires that the object display another window in which the operation takes place, such as editing. For example, if you have a table from a spreadsheet embedded within a document, and you would like to edit that table, you would need to get the table back into the spreadsheet application to make changes. Right?
Not necessarily. OLE Documents includes in-place activation (also called visual editing in more marketing-related contexts), which is a set of interfaces and negotiation protocols through which the container and the object merge their user interface elements into the container's window space. In other words, in-place activation allows the object to brings its editing tools to the container instead of taking the object to the editing tools. This includes menus, toolbars, and small child windows that are all placed within the container.
A number of interfaces that all start with the prefix IOleInPlace are necessary on both the container and the compound document object to make this all work. Through these interfaces the two sides create a mixed menu (composed of pop-up menus from both container and object), share keyboard accelerators, and negotiate the space around the container's frame and document windows in which the object would like to display toolbars and the like.
Because in-place activation is handled solely through additional interfaces for both container and object, support for it is entirely optional (although encouraged, of course). If a fully in-place capable container meets an in-place capable embedded object, they achieve a high level of integration between them. If either side doesn't support the technology, however, they can still work together using the lower-level activation model, requiring a different window. Even when in-place activation is supported all around, the user can still decide to work in a separate window if desired. In-place activation is completely flexible in this regard.
In-place activation is not limited to activating only one object at a time, or activating objects only on user command. Objects can mark themselves to be in-place activated, without the mixed menu or toolbar negotiation, whenever visible. This means that each object can have an editing window in its space in the container. These objects respond immediately to mouse clicks and the like because their windows are in the container, and those windows receive the mouse messages. Only one object, however, can be "UI active" which means that its menus and toolbars are also available. Of course, the UI active object switches (thus the UI switches) as the user moves between objects
With many objects active at one within a document, you can start to imagine how useful it would be if some of those objects were things like buttons or list boxes. Why, you could create forms with such objects, and create an arbitrary container that could hold objects from any source and benefit from all the other integration features of OLE! This is exactly why there are OLE Controls.
In the OLE context, an OLE Control is a compound document object extended with OLE Automation to support properties and methods through IDispatch. But there is one additional necessity that make OLE Controls special: events. An event is a notification that is fired whenever something happens to the controls, such as a state change, user input, and so forth. A control is really a device that transforms many different types of external events, like mouse clicks, keystrokes, and the pickle vat on the factory floor springing a leak, into meaningful programmatic events. On the occurrence of these programmatic events, some event handler can execute code, such as showing a button press down, transmitting a character over a modem, or calling the pickle vat repair company.
For the most part, OLE Controls are a set of extensions to the other OLE technologies, such as structured storage (adds an IPersistStreamInit interface) and OLE Automation (adds new ODL attributes for dispinterfaces, methods, and properties). It defines an generic notification mechanism called connectable objects, which is used to connect some sink object to a source where the source wishes to call the functions of a certain interface that is implemented on the sink. This is like the IAdviseSink interface working with IDataObject, but much more generic. This mechanism is, in fact, used to implement events, which are actually meaningful and useful outside of controls. An object expresses the events it can fire as a dispinterface that the event handler, such as a container application, implements with an IDispatch and connects to the object using the connectable objects technology. A similar extension involves property change notification, which applies very well to controls but is useful for any object that has properties of any kind to notify a sink when those properties change.
OLE Controls also introduces a technology called property pages, which is a flexible user interface model that any object can use to allow an end user to directly modify its properties. A property page in this technology is easily integrated into a tabbed dialog box along with property pages from other objects as well to create a consistent and easy-to-use environment for manipulating such data.
The new interfaces involved for connectable objects, property pages, property change notification, and events make up the bulk of the additions to a control over a regular in-place compound document object. So what is left that is really specific to controls? Not a lot, but a few key enhancements to the OLE Documents technology, through the interfaces IOleControl and IOleControlSite, make the ultimate difference between a compound document object and a control. For example, in compound documents only the UI active object can trap keyboard messages. Any control in a form or document should, however, be able to respond to a keystroke at any time, so OLE Controls provides the mechanism to make it work. OLE Controls also defines mechanisms for handling special controls like labels, push buttons (where one can be the "default"), and exclusive button sets. In addition, the container application that manages the controls exposes a set of "ambient properties" (through a dispinterface) to all the controls to provide environmental defaults to all the controls such as colors and fonts. These few things, combined with property pages and change notification, events, and automation enhancements, make up controls.
Since most of what it means to be a control or a container for controls is being a compound document object or container, OLE Controls leverages any work you do to support OLE Documents. Furthermore, applications like Microsoft Access® and Visual Basic support OLE Controls to create forms. With a few good controls, you can very quickly create very powerful front-ends or custom business solutions with a minimal amount of code—all you have to do is add some Visual Basic code to the event handlers that these applications supply.
You can expect the market will become full of very useful controls in the near future—witness the availability of useful VBX controls. Since OLE Controls is much more powerful and flexible and robust, you can expect them to build on this market and fly even higher.
OLE is all about integration—on many, many levels. Components can come in various ways, be they simple functional objects with an interface for something as simple as string functions to automation objects to data sources to compound document objects and controls. OLE is an extraordinarily rich set of technologies that are useful for many purposes. Implementing a simple object is very simple, as it should be, and is really quite fun. Implementing support for more complex technologies, like compound documents and controls, are more involved, of course, but more and more help is available each month in the forms of books like Inside OLE 2, articles such as this, and new tools. (Inside OLE 2 is in the MSDN Library, under Books.) For example, Visual C++ 1.5 supplies OLE classes as part of the Microsoft Foundation Class Library (MFC), which tremendously simplifies the implementation of OLE Automation, drag and drop, and compound documents. Visual C++ 2.0 will improve the support even more and add wizards and classes to make implementing OLE Controls a snap.
Regardless of your tools, if integration is what you seek, OLE is the answer. OLE helps you integrate components with many features and capabilities, allowing the features of those components to evolve over time. OLE is a complete solution to integration that can itself grow over time to support distributed objects, for example, without requiring changes to existing code. All the OLE integration technologies are what will make the dream of true component software become a solid reality.
Table 1. Description of Interface Names
| COM Interfaces | |
| IUnknown | The base interface for all other interfaces, thus implemented by all objects. Allows clients to obtain interface pointers to other interfaces supported by an object and manage objects through reference counting. |
| IMalloc | The interface implemented by allocator objects to support memory allocation with specified ownership rules. OLE implements a default allocator. |
| IClassFactory[Lic] | The interface associated with a "class object" that manufactures (instantiates) objects of that class. Also support locking of an object server in memory. IClassFactoryLic is an extension of IClassFactory that provides functions for handling licensing issue for object creation. IClassFactoryLic is defined in OLE Controls but is simply an extension to COM. |
| IEnum<X> | Supports iteration (enumeration) through a sequence of structures or objects of type <X>. |
| IExternalConnection | Provides a way for objects to know when remote connections to the object are being established and terminated. |
| IRunnableObject | Provides a way for objects to know when they transition from a "loaded" state to a "running" state and when they become contained in compound documents. |
| IMarshal | Used to package and send interface method arguments between applications (or networks), the process called marshaling. |
| IStdMarshalInfo | Retrieves the class identifier of the proxy and stub implementations used to handle marshaling of a custom interface. |
| Connection Point Interfaces (Interfaces are defined in OLE Controls but not control-specific) | |
| IConnectionPointContainer | Implemented by an object to provide access to its various connection points (IConnectionPoint implementations) for generic notification connections to the object. This handles an objects "outgoing" interfaces on the order of how IUnknown handles incoming interfaces. |
| IConnectionPoint | Provides functions to establish and terminate a generic notification connection to an object. |
| Structured Storage Interfaces | |
| IStorage | Implemented on "storage" objects to provide directory-like functions for the management of a storage hierarchy. |
| IStream | Implemented on "stream" objects to provide file I/O type functions through which components can write binary data. |
| IRootStorage | Implemented on the root storage object of a compound file, that is, the one connected to the underlying disk file. This interface is used to change the underlying disk file in low-memory save operations. |
| ILockBytes | In OLE's Compound Files implementation, ILockBytes makes any binary storage medium such as a disk file, database record, or block of memory, appear as a contiguous byte array to objects that implement IStorage and IStream. OLE provides standard disk file and memory implementations of this interface, and applications can provide their own to build a compound file in other storage systems. |
| IEnumSTATSG | Enumerates STATSG structures which provide information about storage and stream objects such as open mode, element name, creation date and time, etc. |
| IPersist | Base interface for persistent object interfaces through which a caller can obtain the class identifier of an object that can handle the contents of the storage element. |
| IPersistStorage | Implemented by an object to indicate its capability of reading and writing its persistent state to an from an IStorage object. Compound document objects always implement this interface. |
| IPersistStream[Init] | Implemented by an object to indicate its capability of reading and writing its persistent state to an from an IStream object. IPersistStreamInit is an interface defined in OLE Controls that extends IPersistStream with an initialization function. |
| IPersistFile | Implemented by an object to indicate its capability of reading and writing its persistent state to an from a standard file. |
| Naming Interfaces | |
| IMoniker | Implemented on moniker objects to provide binding and other name-related services. |
| IParseDisplayName | Includes functions to convert a human readable name into a moniker. |
| IBindCtx | Used to describe track a monikers binding process to pass information between components used in the binding. This can help monikers break out of circular reference loops. |
| IEnumMoniker | Enumerates through monikers. |
| IRunningObjectTable | Implemented on OLE's "running object table," which tracks which objects are currently running according to their monikers. Used to avoid relaunching applications or reloading files redundantly thereby optimizing moniker binding. |
| OLE Automation Interfaces | |
| IDispatch | Implemented by OLE Automation objects to expose their methods and properties for access by Automation controllers. |
| ITypeLib | Used by Automation controllers to navigate information in type libraries. |
| ITypeInfo | Used by Automation controllers to obtain type descriptions of individual objects or IDispatch interfaces. |
| ITypeComp | Provides a way to access information needed by compilers to bind to and instantiate structures and interfaces. |
| ICreateTypeInfo | Used by tools for creating type information for individual objects. |
| IProvideClassInfo | Implemented by an object to provide easy access to the ITypeInfo interface that describes all the automation interfaces of that object. This interface is defined as part of OLE Controls, but is an extension of OLE Automation. |
| Property Notification and Property Page Interfaces (Interfaces are defined in OLE Controls but not control-specific) | |
| IPropNotifySink | Implemented by the client of an automation object to be notified when an object's property changes as well as to control potential property changes. A client connects this interface to an object via connection points. |
| ISpecifyPropertyPages | Implemented by an object to indicate what implementations of IPropertyPage are available for this object's properties. |
| IPropertyPage[2] | Implemented by a property page object to support creation of UI in which a user can manipulate properties. IPropertyPage2 is a simple extension to IPropertyPage to support browsing of properties. |
| IPerPropertyBrowsing | Implemented by a property page object to support browsing of individual properties. |
| Uniform Data Transfer Interfaces | |
| IDataObject | The single interface through which data transfers happen with methods to get/set data, enumerate and query formats, and to establish or terminate a notification loop with an advise sink (IAdviseSink[2]). |
| IDataAdviseHolder | Helps implementers of IDataObject to manage multiple IAdviseSink connections. |
| IAdviseSink[2] | Receives asynchronous data change and other notifications (such as view and document changes. IAdviseSink2 is the same with one added method for compound document linking. |
| IViewObject[2] | Implemented by an object to support direct renderings to device contexts, such as the screen or printer, as well as supporting a notification connection for view changes through IAdviseSink. IViewObject2 is an extension to IViewObject that includes an additional member for obtaining object extents. |
| IEnumFORMATETC | Provided through IDataObject implementations to enumerate arrays of FORMATETC data structures, describing the data formats available from the object. |
| IEnumSTATDATA | Enumerates a set of notification connections to an IDataObject implementer. |
| Drag and Drop Interfaces | |
| IDropSource | Implemented by the source of a drag-and-drop operation to control the duration of the operation and the mouse cursor. |
| IDropTarget | Implemented by registered targets for drag-and-drop operations to know when the mouse enters or leaves a window, moves in a window, or when a drop happens. |
| OLE Document Interfaces | |
| Embedding and Caching Interfaces | |
| IOleObject | Primary interface through which compound document objects provide services to containers, such as execution of verbs (action). |
| IEnumOLEVERB | Provided through IOleObject to enumerate supported verbs of an object. |
| IOleAdviseHolder | Manages IAdviseSink interfaces given to compound document objects for notification. |
| IOleClientSite | Implemented by container applications to provide container context information to compound document objects. |
| IOleCache[2] | Implemented in object handlers (such as OLE's default handler) to allow containers to manage cached presentations of a compound document object. IOleCache2 provides containers a way to force an update of the cached presentations. |
| IOleCacheControl | Implemented in object handlers to support the connection of the cache to another object's IDataObject implementation. |
| Linking Interfaces | |
| IOleLink | Provides functions for manipulating a linked object, supported alongside IOleObject. This interface is always implemented in OLE's default handler for any object. |
| IOleContainer | Implemented by container applications to allow enumeration of the object in the container. |
| IOleItemContainer | Implemented by applications that support complex linking to portions of documents or to embedded objects within a document. Specifically used by the binding process of items monikers.. |
| In-Place Activation Interfaces (Visual Editing) | |
| IOleWindow | The base interface for other in-place activation interfaces; it contains a function to retrieve the window associated with the interface and for entering or exiting context-sensitive help mode. |
| IOleInPlaceObject | Implemented on compound document objects to indicate in-place activation support; it supplies activation functions to containers.. |
| IOleInPlaceActivateObject | Supports communication between an in-place object and the container's frame and document windows. |
| IOleInPlaceSite | Implemented next to IOleClientSite in a container to indicate in-place activation support and to provide objects a way to notify the container when in-place state changes occur. |
| IOleInPlaceUIWindow | Implemented on container document and frame related objects to support border space negotiation for in-place objects. |
| IOleInPlaceFrame | Derived from IOleInPlaceUIWindow, this interface is implemented on a container's frame object to support not only border space negotiation but also menu merging and keyboard accelerator translation. |
| OLE Controls Interfaces | |
| IOleControl | Implemented by an OLE Control to provide for keyboard mnemonic translation and notification of changes in a container's ambient properties. |
| IOleControlSite | Implemented by an OLE Control container to supply container operations to OLE Controls, such as transformation of coordinates and accelerator translation. |