
Kraig Brockschmidt
Microsoft Systems Developer Relations Group
September 13, 1994
Kraig Brockschmidt is a software design engineer and author of Inside OLE 2, published by Microsoft Press. His articles have also appeared in Microsoft Systems Journal and Windows Tech Journal.
This technical article will examine OLE version 2.0 technologies such as OLE Documents (In-Place Activation and OLE Linking and Embedding), Component Objects and the OLE Component Object Model, Compound Files, Monikers, Uniform Data Transfer, OLE Drag and Drop, and OLE Automation. In addition, this article will describe the purpose of each technology, explore some of the mechanisms involved, and explain how each technology can help you meet customer demands for integration, consistency, new features, performance, and usability. With this guidance, you can begin adopting technologies where they are important. This approach greatly increases the amount of code reuse in an OLE application.
OLE is rapidly becoming a major component in applications for Microsoft® Windows®. But what is it? What do you do with it? Microsoft considers OLE tantamount to its newest generation of operating systems, such as Windows 95. You might have heard Microsoft's message that an application developed for Windows 95 is a "Win32® and OLE 2.0" application. But, unlike OLE, writing a Win32 application is relatively easy—just port your code to 32 bits. Win32 is, after all, the application programming interface (API) you use to write any application for Windows, so supporting Win32 is both the end you seek and the means to that end.
OLE 2.0, however, is more confusing. How an application uses OLE is less clear than how an application uses Win32. The main reason is that OLE 2.0 does not define a platform or an operating system—you can't write an application with OLE 2.0 alone. In fact, OLE 2.0 is a means, not an end. More specifically, OLE 2.0 is a collection of powerful, object-oriented technologies that you can use to implement a number of important features in your applications. There is no one single way to qualify yourself as an OLE application. Instead, there are many ways, using at least one of the OLE 2.0 technologies. OLE is just a convenient metaphor for all those technologies. So when people ask, "Are you using OLE in your application?" they are really asking, "What OLE 2.0 technologies are you using to implement features in your application?"
Note Throughout the rest of this article, OLE 2.0 will be referred to simply as OLE.
Microsoft research has shown that customer demands fall into three categories: new features, integration between applications, and consistency between applications, as shown in Figure 1. OLE technologies help you meet all three demands in your applications. Each technology addresses some or all of these demands, as well as application architecture and performance, which are important considerations for any application.
Figure 1. Customer demands in software
There are nine primary OLE technologies, as shown in Figure 2. Many technologies shown on the top of the diagram depend on the technologies shown below them. This means that although the higher-level technologies are more visible to your customers, you really need to begin adopting technologies from the bottom up. Bear in mind that you don't have to fully adopt a lower-level technology before you move up. In many cases, you only need to understand how the lower-level technologies work and how they apply to the features you want to implement.
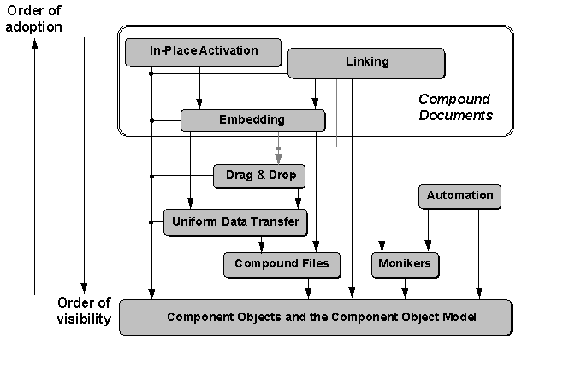
Figure 2. OLE technologies and their interdependencies, where the higher technologies are the most visible, but the last technologies you can adopt. Note that Embedding and Linking can use OLE Drag and Drop, but do not depend on this lower-level technology.
All the technologies shown below the "OLE Documents" box in Figure 2 are considered "base" technologies. These technologies include:
The collection of OLE Document technologies shown in Figure 2 is a standard for a high-level of data integration between applications. Just imagine that there are things, and there are places to put things. The things are OLE Document objects, the places are container applications. How they are shared and manipulated depends on the specific technology in question:
So what do you do with all of this stuff? Which ones must you use to create an "OLE application?" That really depends on your application and what's important for your customers. Therefore your strategy in building an OLE application involves three steps:
The key step in this strategy is number two: Understanding how OLE technologies will meet your customers' demands.
Everything in OLE is based on the OLE Component Object Model (COM), a specification for building modules of code (called objects) that determines how some other program (the object user) accesses and uses that code. The COM defines which objects are independent from which tools or programming languages (although the COM was designed to be most convenient for C++ programmers). This independence makes the COM a binary standard: Regardless of how an object is built, all object users see it with the exact same structures in memory as they would with any other object. Therefore, the use of any objects is consistent within your application, regardless of who implemented those objects and what tools they used.
The memory structures are nothing more than tables of function pointers—pointers to the member functions of the object (as shown in Figure 3). The COM calls each table an interface, a semantically related group of functions. Each interface in OLE is identified by a specific name, and each name is prefixed with a capital "I." By implementing a given interface, an object agrees to a specific contract implied by that interface, so the user of that object knows what to expect when calling functions in that interface.
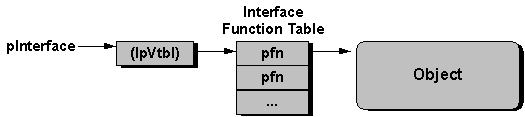
Figure 3. An interface on an object is actually a table of pointers to related functions that operate on the object. A pointer to an interface points to another pointer, which then points to the function table.
A pointer to an interface, which is the only way in which an object user can communicate with an object, can only access the specific member functions of that interface. The user never has a pointer or access to the object as a whole, which is necessary to create a binary standard. However, an object can implement as many interfaces as it wants, providing a different interface pointer—a different function table—for each supported interface. As a convenience, you can draw interfaces on an object as a plug-in jack, as shown in Figure 4. With a variable number of interfaces, an object can be so simple that it only supports a few string functions, or so complex that its interfaces completely describe the capabilities of a 3-D charting package.

Figure 4. The plug-in jack notation. The object supports three interfaces by providing three interface pointers.
OLE provides many ways to obtain the first interface pointer to any given object. Obtaining the first pointer marks, as far as the object user is concerned, the creation point of the object. The object then controls its own lifetime through a reference count it maintains internally. When the object is created (that is, when the first interface pointer to the object is created), the reference count is one. When the object user is done using the object, it can "release" the interface pointer it owns, which tells the object to decrement its reference count. If the reference count reaches zero, the object is allowed to free itself.
The reference count tracks how many interface pointers exist for that object, so that the object frees itself only when the last reference to that object is released. Controlling the reference count of an object and obtaining different interface pointers for the same object is the purpose of the most fundamental interface in OLE. This interface, IUnknown, is the base interface for all other OLE interfaces. All objects that comply with COM must at least implement the IUnknown interface. So by implementing one interface, your object always implements IUnknown and can therefore be called a COM object.
IUnknown has three member functions: AddRef and Release, which manage the object's lifetime through reference counting, and QueryInterface, the fundamental function for a process called "interface negotiation." Negotiation is a process whereby the object user can obtain interface pointers to any other interface on that object, when given any single interface pointer on any object. It's something like asking the object what languages it speaks. When you discover that it knows a particular language, you can communicate with it in that language, through that interface pointer.
The big benefit of negotiation is that when an object user comes into contact with a random object at run time, the user can at least talk to the object by using IUnknown, because the object must support that interface. Through IUnknown, the user can ask the object for other interfaces. "Do you know how to draw yourself?" it might ask, and if the object knows, it will provide an interface that deals with drawing itself, and so on. Because interfaces stay out of the way until asked for, either object or object user can support as many interfaces as desired, without restricting who else can talk to it. A user and an object always converse by using the largest number of interfaces known to both, instead of being forced to deal only with a least common denominator.
Of course, the COM does more than just define what objects are and how they work. The COM is actually a very powerful model, and the implementation of a set of mechanisms for object-oriented programming (these mechanisms are contained in a dynamic-link library called COMPOBJ.DLL). It is also the foundation for system-level object technologies you will see in future versions of Windows. The other OLE technologies are simply the first set of technologies to take advantage of COM, and so by virtue of using any other technology, you will be using this object model.
Although not visible to end users, the COM can now be used by itself as a basis for your own application architecture. As a binary standard, it helps to provide consistency between objects, regardless of where those objects (that is, their code modules) live in storage, where they execute, what interfaces they support, and what tools and languages were used to create them. The QueryInterface mechanism lets you add more interfaces to an object implementation, or more interfaces that an object user understands how to manipulate, at any time, without ever having to ask anything else to recompile. An object user that knows every interface can work with any object and communicate through the largest set of common interfaces. With a few standards, the object user and object need not know anything specific about each other. As will be seen later, this is the motivation behind OLE Documents.
One of the key benefits of using the COM for system objects is the ability to create Component Objects. An object by itself might be private to an application, or perhaps shared with other applications when the owner of that object deems it appropriate. However, any object implementation—or object class—can be structured in a "server module" (that is, a DLL or an EXE) so that any other object user in the system, and even anyone on the network, can instantiate an object of that class and make use of it, by only knowing a class identifier. The COM takes care of locating the server module for that class identifier (by using the system registry), loading and running the server, asking that server to create an object, and returning an interface pointer to the object user. Without the COM, this sort of process has generally been left to the end user, making for a much more frustrating environment.
Once the object user obtains an interface pointer to an object, the COM handles all communication between the object user and the object (as shown in Figure 5), regardless of the barriers between the two (the cross-network capabilities are not yet available in stores). The piece of code involved here is the Component Object Library, COMPOBJ.DLL (or COMPOB32.DLL under Microsoft Windows NT™). Because of the binary standard, the object user need not concern itself with the boundaries being crossed when using the object: The COM handles all the plumbing. The COM is the basis for all integration features of OLE.
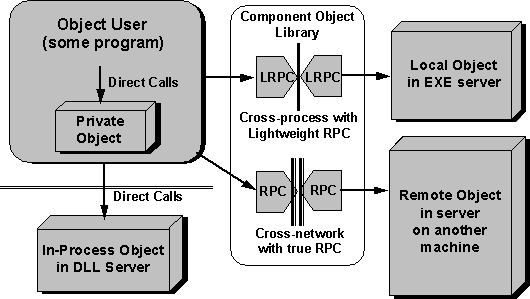
Figure 5. When an object user has an interface pointer for any object, it doesn't have to know where the object lives in the file system or where it executes. The COM library hides all the underlying communication mechanisms when objects are in other processes or on other computers. Note that a library with full remote procedure calls (RPC) support is not yet available in stores.
Regardless of what an object does, or what interfaces it supports, the server module that contains it must have a standard structure, in order for the Component Object Library to locate the object's server and create an object. This structure, shown in Figure 6, differs for DLLs and EXEs, but consists of three common elements:

Figure 6. A component object, with whatever interfaces it wants, is part of a larger "server" module that contains the code necessary to locate and create the object.
Component objects are the crux of the future operating system code-named Cairo (the next generation of the Windows NT operating system). In Cairo, all meaningful functionality in the system is implemented in reusable component packages. At this time, OLE is simply the first set of important technologies to exploit such a design. Of course, you can use this technology today by building shareable and reusable components within a suite of applications, to form a high level of integration and consistency between applications. EXE-based objects can take advantage of process separation from the object user, and remote objects pave the way to many distributed services. Either way, all interfaces look the same, regardless of where the object actually lives and executes. There are also many opportunities for end users to buy off-the-shelf installable components of their choice, to customize their systems and ensure consistency.
A final point about the COM: Once an object user has established a connection to an object (an interface pointer), the COM gets out of the way, except for facilitating communication. This means that two applications can talk to each other directly through object interfaces, without having to go through some obscure APIs in the operating system. Vendors can get together to define their own custom interfaces, and without having to seek Microsoft's approval or request any changes to Windows itself, they can publish and implement those interfaces. The COM provides all the glue you need, now and in the future. You just have to take advantage of it to implement many powerful and specialized features specific to your customers' needs.
A moniker is a special type of component object used to manage an abstract reference (such as a name) for some other object. Simply stated, a moniker is a component object with the IMoniker interface that handles the details of managing a reference. The object (or data) referred to might be a file, a portion of a file, or even the result of a query. The moniker simply maintains the information necessary to locate (or generate) the object and the code necessary to resolve that information into a real object, such as running applications to load files or connecting to a database and sending it a query. Monikers are much like treasure maps that know how to follow themselves—all you have to do is say, "Give me the treasure," and it does the rest. Although OLE provides a number of basic moniker implementations, you can implement your own. Your implementations will combine readily with any existing moniker usage in OLE.
Monikers have almost limitless uses for establishing connections between the source of helpful information and the consumer of that information. This not only opens the door for many new and interesting features of your own creation; it enhances the usability of a system or an application, because connections can be automated. More reliable connections mean, of course, greater consistency for your customers.
With ordinary file input/output (I/O) functions in the Win32 API, you deal with a file as one large flat stream of bytes. This makes it extraordinarily difficult to implement features such as incremental saves and transactioning within an application. To solve this and a number of other problems, OLE includes a specification for "structured storage" (also known as a "file system within a file"), as shown in Figure 7. The OLE-specific implementation of structured storage, which is compatible with future versions of Windows, portable to other systems, and robust under low-memory conditions, is called Compound Files. This technology lets you manage your storage in terms of a hierarchical structure made of storage objects, which act like directories, and stream objects, which act like individual files. Storage objects are simply another class of components that support an IStorage interface, which handles management of the hierarchy. Streams are similar—they support an interface called Istream, which handles data reads and writes.

Figure 7. A compound file is made of a root storage under which you can create sub-storages and streams. Any sub-storage can have any number of other sub-storages and streams. Storage and stream objects are, of course, based on the COM and implement specific interfaces related to storage.
Incremental access (reads as well as writes) is the normal mode of operation. If you want to change a little data in an individual stream, you only need to open that stream, and write your modified data (even if it causes the stream to grow). Compound Files will write that data into the underlying disk file where there is space. The key point is that the only parts of the file affected are those composing the individual stream; the rest of the file remains undisturbed. The Compound Files technology manages the exact layout and position of bytes within the file itself, which can be fragmented. But as far as you're concerned, your streams are contiguous. You still define the internal formats of the streams and the hierarchy, but Compound Files controls the exact placement of all necessary data in the actual disk file entity. In many ways, this technology frees you from dealing with seek offsets (and garbage collection) in the same way that a file system frees you from dealing with absolute disk sectors.
The Compound Files technology also has built-in transactioning support, so that you no longer need to manage change states yourself to implement this feature. Only when you commit changes will Compound Files actually write to the disk. At any time before then, you can discard all the changes and revert to the previously saved state. OLE does all the work. In the same way, the Compound Files technology also has built-in support for incremental access, a feature that is, at best, extraordinarily difficult and tedious with ordinary file-handle–based APIs. Incremental access is the normal mode of operation of a compound file: If you want to read or write the information in a single stream, simply open that one stream and manipulate it as a small flat byte array. Compound Files worries about finding space in the actual disk file for the data, automatically expands the file as necessary, and performs garbage collection for unused space. Obviously, this can save you a lot of work, while you still benefit from the performance improvements that incremental access can provide.
Applications do not have to use this technology today, but structured storage of this kind will be the native file system in future versions of Windows. Compound Files also opens the path to a high degree of integration and consistency within the system shell, especially where document browsing is concerned. Because the only application-specific data formats in the file are contained within streams, the hierarchical structure of the file itself is a known standard. A document browser can thus look into any compound file, without having to launch the application that created it. If a file has streams that contain standardized data structures, such as one for a document's summary information, the browser could also search items such as author, creation date, keywords, and so on when processing a query. This is a key element in the future of the Windows shell.
The Compound Files technology lets you define standards for the names and formats of individual streams within the file, thus addressing the areas of integration and consistency. For example, if you create a "Summary Information" stream in your file, you enable any other application, including the system shell, to open your file, read that stream, and browse the information therein, such as author, creation/modification times, keywords, title, and so on. The benefits of this for document browsing or executing shell-level queries is enormous, and future versions of Windows will exploit this capacity. To end users, it means that they can locate information in files without having to run all the applications that created those files—much more consistent and much faster. All files integrate with the shell, and the shell is the consistent location where users go to locate and browse information.
Monikers are a way to establish connections between sources of information and consumers. Uniform data transfer is a more powerful and efficient way to exchange data than anything previously available in Windows. Once a connection is established, the data is exchanged through the use of data objects (any objects with the IDataObject interface). These data objects form the foundation for Clipboard and OLE Drag and Drop exchanges, as well as data transfer in OLE Document scenarios. The "uniform" in this data transfer technology comes from the fact that a single data object implementation can be used identically with the Clipboard, OLE Drag and Drop, and OLE documents, within both sources and consumers alike.
This technology is more powerful than a standard Clipboard format because it allows rich descriptions of the data in question, using a structure called FORMATETC. This structure includes device information and a detail description, making it much more powerful than a standard Clipboard format (which is still contained in the FORMATETC to describe the simple format of the data itself). Obviously, applications that are very sensitive to output quality can appreciate richer descriptions and device-specific rendering optimizations.
Uniform data transfer is also more efficient because it allows exchanges to happen through any medium, such as a normal disk file, a compound file, a stream object, a graphics device interface (GDI) object, and global memory. In the past, global memory was your only choice. Unfortunately, it does not work well for large data or highly structured data. In OLE, the medium, and the actual handle or pointer to the data, is managed in a structure called STGMEDIUM. If a FORMATETC is a better Clipboard format, STGMEDIUM is a better global memory handle, or more appropriately, a better way to address where the data is stored. Applications that generate a large amount of data can appreciate the ability to keep this data on disk—where it belongs—through all transfer operations.
OLE makes it possible for you to use data objects when dealing with the Clipboard, so you can use all this new power in the context of your application as it exists today. Any global memory-based data you place on the Clipboard will appear to other non-OLE applications; the data that non-OLE applications place there will appear to you as a data object. You can deal with the Clipboard entirely through this technology. In addition, you can also use data objects to manage dynamic data exchange (DDE)-style notification (or "advise" loops) between a data source and a consumer of that data. The source provides the IDataObject interface, and the consumer implements an object with the IAdviseSink interface, which it then passes to the source. When data changes in the source, it calls member functions in IAdviseSink that indicate the change.
When all is said and done, uniform data transfer provides a consistent way to deal with data for the programmer—through IDataObject—and helps your applications work better together. As far as data transfers are concerned, it uses a high level of integration between sources and consumers. You can optimize your data for specific devices and use the best mediums for exchanges. When you use it in combination with monikers, you can create an environment where the end user really doesn't need to manually manage links between the data source and data consumer. Because this last possibility is popular, OLE provides a standard for such a combination: The linking capabilities of OLE Documents, which we'll learn about a little later.
Uniform data transfer is concerned with connecting a data source to a consumer of that data by means of a data object. OLE Drag and Drop is another way (in addition to the Clipboard) to exchange a data object between a source and a consumer. A Drag is like a Copy/Cut; a Drop is like a Paste. In this sense, any application that has ever used the Clipboard for any sort of data transfer can use OLE Drag and Drop to perform the same transfer in a much more direct fashion. Anything you can transfer by using a data object in OLE, you can transfer with OLE Drag and Drop, including OLE Document objects. If you write code for using data objects with the Clipboard, much of the same code is reusable in an OLE Drag and Drop implementation.
Applications are either drop sources, which supply the data in question, drop targets, which consume data dropped on them, or both. Because most applications can at least copy and paste their own data, they will usually be both a source and a target for their own formats. An OLE Drag and Drop operation is illustrated in Figure 8. The source provides a data object and implements the IDropSource interface on some object (such as the application's document). The target implements an IDropTarget interface on some object (such as a document) and registers it with OLE.

Figure 8. The mechanism of an OLE Drag and Drop operation involves both a source and a target, with OLE in the middle, managing the important mouse and keyboard events.
When the operation begins (that is, when the source detects the appropriate mouse click), the source passes its data object and IDropSource interface to OLE, which enters into a message loop that detects mouse events and keyboard events. If the mouse moves into a registered target window, OLE tells the target through IDropTarget, as it does if the mouse simply moves over the window or later moves out of that target window. The target tells OLE if the data hovering over it is useful (that is, if it could be dropped) and indicates what would happen if a drop occurred. This indication is passed back to the source through IDropSource, which then changes the mouse cursor to reflect what would happen on a drop.
If the keyboard state changes at any time, OLE also tells the target the new conditions, and the target again indicates what would happen on a drop. The ctrl key changes the default operation from Move to Copy, and ctrl and shift together mean "link." If the esc key is pressed, which means Cancel, OLE tells the source that the operation terminated without a drop. Finally, if the mouse button is released over a suitable target, that target is given the source's data object, from which it can retrieve data. The source is told whether to delete that data (in a Move) or keep it intact (in a Copy).
The more data formats that sources provide and targets understand, the higher level of integration you can achieve with other applications, or even with the system shell—especially in Windows 95. In Windows 95, users will expect that they can drag anything on the screen to some other location, so this technology is key to ahieving high levels of both integration and consistency. It's also an important feature, and is even relatively simple to implement. You won't find many features with this level of performance.
A demonstration performed at the Win32 Professional Developer's Conference in Anaheim last December also shows that the source does not even have to render the data when an OLE Drag and Drop operation begins. The demonstration showed an OLE Drag and Drop of a document image from a scanner application into a word processor. As the source, the scanner application indicated that it could provide text in a data object. When the word processor received the drop, it simply asked the data object for text. In response, the scanner application fired up its optical character recognition (OCR) engine to create text from the document image. The process was natural and very powerful, which gave the end user the sense of a high degree of integration between the word processor and the scanner application, even though neither application knew anything specific about the other. This was all accomplished through OLE technologies.
OLE Automation is the one technology that you can exploit in virtually any application for the benefit of your customers. OLE Automation is a way in which you expose the functionality and attributes of your application, known as methods and properties, through automation objects that implement the IDispatch interface. Your application is then called an automation server, and you can also provide the same information in a type library, which others can access and examine without having to load and run your application.
The users of those objects, or automation clients, are generally some sort of programming tool, for example, an application such as Microsoft Visual Basic® or a macro programming language in another application. Using the language of that tool, the programmer, especially a corporate developer, can write scripts that let multiple applications perform specific tasks. The tool facilitates the programmer's efforts by displaying the names of available objects and the names of methods and properties supported from those objects, as well as prompting the programmer for the appropriate parameters.
This sort of cross-application programming capability has never existed before, even though it has been a demand of users for some time. Ideally, there would be only one automation client on any computer—the user's choice—and with all other applications providing automation objects, the client becomes the central macro-programming tool for everything. This provides consistency, very good integration between applications, and a corresponding increase in usability. As with OLE Drag and Drop, the relative simplicity of this technology makes it very cost-effective to adopt, and almost any application—even games—can adopt it. Think of how easy it would be to program a demonstration script!
OLE Documents are a way in which one application shares data from any other arbitrary application, as long as both conform to the OLE Documents standard. Under the OLE Documents standard, the two applications, the container and server, share an OLE document object. The server defines the object—its data, display renderings, and manipulation or editing facilities. The container provides the space, or the OLE document, in which to display and store the object in some meaningful way, and provides the user interface necessary to generate commands to the object. Any application that manages presentation space of some kind, such as word processors, desktop publishing (DTP) programs, presentation graphics packages, e-mail systems, and so on, makes a great container. Any application that generates some form of data that is useful in a variety of documents, such as sound, video, drawings, charts, and so on, is a great server candidate. However, not all applications work with this model. A multimedia title, for example, is a presentation of a fixed data set that isn't suitable as a container or server.
One key point to remember about the OLE Documents standard is that neither application needs any prior knowledge of the other. A container written to the standard can contain any object from any server that conforms to the standard, and vice-versa, including OLE version 1.0-compliant applications. This also means that a container written today will work with an object and server written to the same standard two years from now. Without any more work, that container will be able to integrate automatically with the new server. And, of course, the converse is true.
The data shared in the form of OLE Documents objects maintains all the information necessary to create them (including a class identifier of the server), so that the same information is available when a user wants to manipulate the object later. At that time, the end user activates the object in the container. What actually happens depends on the "flavor" of the object and the features it supports. The object might be embedded or linked. An embedded object can support in-place activation, also known as OLE Visual Editing. A linked object, which uses a moniker to maintain the link information, might be a link to another embedded object. Furthermore, different servers can mark themselves as capable of converting or emulating objects from other servers.
All the technologies under the OLE Documents umbrella are primarily concerned with integration between applications, and, therefore, usability. With such integration also comes a fair amount of consistency, because users get the choice as to which tool is used for which purpose. No matter what application they are using to generate documents, they can always, for example, use the same graphics and table tools to manipulate those kinds of data. This is much better than using different applications with different sets of tools and vastly different user interfaces. Users want integration and consistency, and OLE Documents are a way to achieve that to a very high degree. So let's review these technologies in a little more detail.
When the data necessary to activate and display any given object is entirely contained within an OLE Document (in reality, within a storage object in the container's compound file) the object is called an embedded object—all its state information is "embedded" in the document. Any container will support embedding, because embedding is the minimal level of support for OLE Documents. When the user activates the object, the object server displays a window in which the user can make changes or otherwise manipulate the object.
Many components are involved in the embedding scenario, as shown in Figure 9. The container must implement what is called a site, an object that implements the IOleClientSite and IAdviseSink interfaces. These interfaces provide the server/object with information and functionality relevant to the container. IAdviseSink, for example, is the interface through which the object informs the container that its display has changed or that the object has been closed from editing.
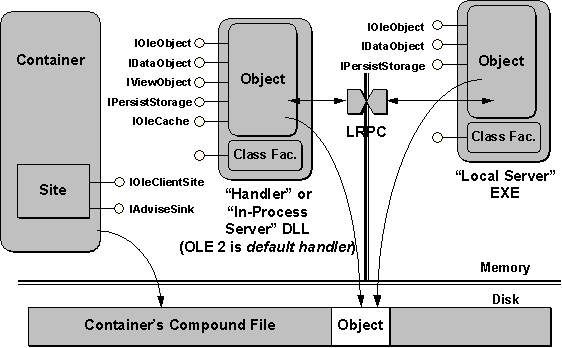
Figure 9. The modules and interfaces involved in embedding. Note that the object has direct access to its storage in the container's document file.
The object half of the embedding pictured in Figure 9 is more complicated. From the container's perspective, the object is always present in a DLL to which the container makes direct calls. This DLL might be a full custom implementation of the object, in which case the DLL is an in-process server. If the DLL contains only a partial implementation, such as code for printer optimization, the DLL is called an object handler and depends on a local server executable to round out the object's implementation. Because the container always has to talk to a DLL object implementation, OLE provides a default handler that provides some basic functionality independent of the specific object class. Note that handlers and in-process servers, as well as the local server, are structured exactly like the component object server mentioned earlier. The only difference between a simple component and a complex handler is the number and nature of interfaces on the object itself!
From the view of the container and any DLL object implementation, the object must implement the following interfaces, through which the container has access to specific functionality:
IOleObject
Functions for OLE Documents-related functions, related to IOleClientSite.
IDataObject
Functions for obtaining renderings from the object.
IViewObject
Functions for asking the object to draw itself.
IPersistStorage
Functions for communicating storage information to the object.
IOleCache
Functions for controlling display caches for the object.
The cache that IOleCache deals with is necessary to let the user print or view a document, even if the object server is not present. The default cache implemented in OLE (which most custom handlers and in-process servers use) normally caches at least one screen metafile for the object in the OLE document. If the document is moved to another computer without the server, the user can still view the object. The container, through IOleCache, can request the caching of more presentations, as well.
Whenever the user wants to perform some action that is beyond the capabilities of a handler, such as activating the object, the handler attempts to launch the local server, by communicating with it through lightweight RPC (LRPC). The local server must provide a complete object implementation, but it only has to implement the IOleObject, IDataObject, and IPersistStorage interfaces. IViewObject and IOleCache are only applicable to the handler.
What is most interesting now is the storage situation. In Figure 9, the container has a compound file for its document. It reserves part of that compound file, in the form of a sub-storage, for each embedded object. When the container wants to load or save the object's data, it simply passes an IStorage pointer to that sub-storage to the object, which then writes its data in directly. In fact, whenever an object is loaded, in a handler or any type of server, the object has total read and write access—that is, total incremental access, one of the best features of compound files. For this reason, it is highly recommended, though not required, that a container use a compound file for its documents. The container always has to provide a storage object to the embedded object, but there are other ways to accomplish that.
Embedded objects are most useful for small amounts of data, because they are stored as part of the document itself. In some cases, the data for an OLE Documents object is so large that it is inefficient to embed all that data in a document. In this case, it's preferable to leave the data in another location, such as another file or a database field, and embed nothing more than a reference to the other location. The object then becomes a linked object and the reference stored in the document is a moniker, as shown in Figure 10. When the user activates a linked object, the object server displays a window in which the user can make changes, just like an embedded object. The only difference is that changes made to that source might affect other linked objects that refer to the same source. For this reason, OLE provides some help to containers to ensure that the display of the linked data is always up-to-date.
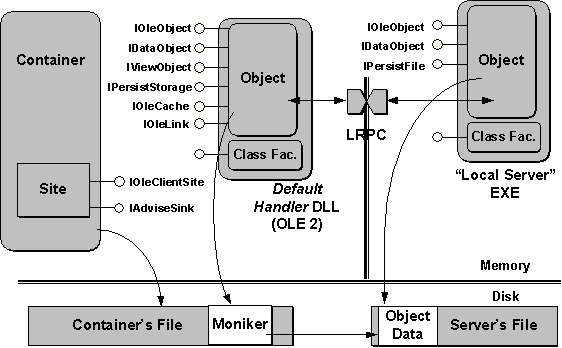
Figure 10. The modules and interfaces involved during linking. A moniker maintains the reference to the actual data in another location.
For the most part, embedded objects and linked objects implement most of the same interfaces. Once it supports embedding, the container needs only a few additional pieces of code to support linking. That's why it makes sense to implement embedding first, then add a little more code for linking support. It is, however, acceptable to only support linking when necessary.
In any case, notice that the object in the handler/in-process server, when linked, supports an interface called IOleLink, through which the container can change the link source (moniker), update the link, or cancel the link completely. When the link is to another file, the server must implement the IPersistFile interface, through which OLE, when resolving the moniker, asks the server to load the linked file. If the moniker actually references a subset of a file, the server will have more to implement—usually one or more separate objects with the IOleItemContainer interfaces. These are necessary when a simple filename is not sufficient to locate the object.
When the source of the link is actually another embedded object, a simple filename in a moniker is not sufficient to locate a linked object (see Figure 11). Sometimes the information to which you want to link is only stored in an embedded object. In this case, a container supports such linking by creating a moniker that describes the name and document of the embedded object when it copies that object to the Clipboard or in an OLE Drag and Drop operation.
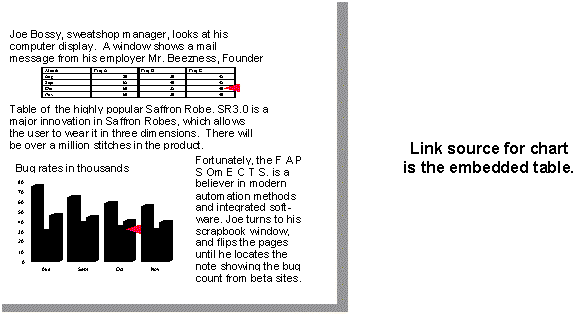
Figure 11. Example of a chart linked to an embedded table.
Now the container becomes a partial server. Although it doesn't have to implement an embedded object itself, it must implement all the mechanisms necessary to relocate and reload that object, perhaps even to activate it, even when the container is not running and the OLE document is not loaded. The container in this case must implement a class factory, expose that class factory, and provide an unloading mechanism. The object created by that class factory is one that can resolve or "bind" the moniker to the embedded object it references. This can involve multiple objects with implementations of IPersistFile and IOleItemContainer. Although it is non-trivial to implement to a container, it is necessary to let the user consistently link, or integrate, with whatever source of data is available. Note that the object itself is hardly affected by this technology.
Something that does affect the object more, with a little impact on the container, is support for conversion and emulation. These small technologies let one server work with embedded objects (and only embedded objects) from another server. This requires prior knowledge of those objects and their data formats, of course, making it no different than file-level conversion between applications today. These technologies simply allow the same type of functions with objects, and only affect a server's treatment of storage through its IPersistStorage interface.
Conversion is a process in which an object is irrevocably changed—converted—from its original class into another class. From that point on (until it's converted again), it will always depend on the new server for all functions, such as activation. Conversion means that the new server can read another format, but cannot write it. Emulation, on the other hand, is the process whereby another server is used to work with the object, but the object retains its original identity. The new server can read the object, work with it, and write that object again in its original format. This is most useful when a document is shared between people with different server applications for, say, spreadsheets or drawing objects. Each person can work with the object without changing its identity. More important for consistency's sake, each person can choose his or her preferred tool for working with that object, and any other object classes as well. Consistency is always improved when the user has a choice.
The final OLE technology is really a user interface enhancement to embedding (it does not affect linking at all). When both the container and the embedded object support in-place activation, the server will negotiate with the container to display necessary editing tools, such as menus, toolbars, and virtually anything else, directly inside the container's windows. Normally, without this technology, the server displays such tools in another window and work happens on a visible copy of the object. With in-place activation, the server places its tools in the container's context, leaving only one visible object—the one in the document. This results in an environment that is much more consistent and focused on the document, rather than on applications. The object seems to integrate directly with the container, appearing as part of the container itself.
Additional interfaces are required on both sides of the fence, as shown in Figure 12. The container must implement the IOleInPlaceFrame, IOleInPlaceUIWindow, and IOleInPlaceSite interfaces on its frame, document, and site, respectively. The frame deals with top-level user interfaces, such as menus, accelerators, and toolbars. The document, which can be omitted if necessary, deals with tools displayed inside a document window. The additional site interface, which sits right alongside IOleClientSite and IAdviseSink, exposes to the object additional container functions that only have meaning during an in-place session.

Figure 12. Additional interfaces for in-place activation
To support in-place activation, the object need only add two interfaces that supply additional in-place related functions to the container: IOleInPlaceObject and IOleInPlaceActiveObject. Note that with the interface separation attained with the QueryInterface mechanism mentioned earlier, these additional interfaces do not change the nature of the object as a simple embedding. These new interfaces come into play only if the container asks for them. This means that if such an object is embedded in a container that does not know in-place activation, it will be used as a standard embedded object. In sum, by implementing this higher-level technology in an object, you always retain compatibility—even with containers that have not implemented it. You do not lessen your object's usefulness by implementing more features. You can make the object as rich as you want, and still work with a sparse container.
The opposite, of course, is also true. If a container supports in-place activation, it can still embed objects that do not. The container will try to activate an object in place, but the object won't know what the container is talking about and will just activate normally, which is fine with the container. When the container does encounter a capable object, it can activate that object in place. With QueryInterface, integration is always as rich as possible between a container and an object.
This article has discussed all the OLE technologies in terms of integration, consistency, and new features. OLE brings all these elements to your application in the following ways:
Integration
Any object can go in any container, and when activated in-place, such objects appear as part of the container. In Windows 95, even the desktop and the system shell will be containers, and shell extensions will be achieved through specialized in-place capable objects. Controls will also use these technologies.
Consistency
Objects from the same class behave identically, regardless of the document in which they live. Whenever a new server is installed, its objects become immediately and automatically available to all containers, without any change to the container. Monikers also provide some link tracking to cut down on broken links, and with conversion and emulation, users choose their preferred tools for working with objects.
New Features
You can use OLE to integrate any data from any source as a container, or to integrate with any document as a server. For example, you can get easy multimedia support (sound and video) by creating a container that can embed such data, even though it knows nothing else about multimedia.
Of course, one question remains:
The simple answer is: Yes, if you have a reason. You do not have to use any OLE technology to run under Windows 95, but if you want to run well, integrate with other applications and the shell, be consistent with other applications, and support new features that are not available any other way, then you will want to use OLE. On the other hand, it is perfectly understandable if you have little or no use for these technologies today. In the future, many new features that you will want to exploit will be offered only through OLE-style mechanisms. You can give yourself a head start by using OLE today.
The point is the same as with Win32: Under Windows 95, a 32-bit application will simply run better than a 16-bit application. An OLE application (whatever that might be for you) will simply run better and integrate better with both Windows 95 and other applications. In short, Win32 and OLE are your paths to great Windows 95 applications. Customers will notice the difference.
One note of caution: OLE is big. There are many functions and interfaces, and potentially a lot of work to adopt all these technologies. Take a step-wise approach to implementation, working from the bottom-level technologies shown in Figure 2 up, so that you can build a solid foundation in your application for the higher-level technologies. And remember the strategy:
For more specific information on OLE technologies and how they can improve applications in various categories (such as spreadsheets, databases, accounting, e-mail, and so on), see "How to Apply OLE 2 in Applications" (MSDN Library Archive, Backgrounders and White Papers, Operating System Extensions). You may also find this article on CompuServe® (WINOBJ) and the Internet (gowinnt.microsoft.com).
For information on programming with OLE, see the book Inside OLE 2 by Kraig Brockschmidt, available in your local bookstores or directly from Microsoft Press by calling (800) MS-PRESS (the order number is ISBN 1-55615-618-9). The OLE 2 Programmer's Reference, Volumes 1 and 2 (ISBN 1-55615-628-6 and -629-4) is another good resource.
To help with most of the detailed work for implementing OLE Drag and Drop, OLE Automation, and OLE Documents, don't forget the OLE support in Microsoft Foundation Class Library (MFC) version 2.5, shipped with Microsoft Visual C++™. If you can use MFC in your application, you won't find a faster way to adopt the visible OLE technologies.
The following documents can be ordered by contacting the Microsoft Developer Solutions Team at (800) 227-4679.
| Strategic White Papers | Primary Audience |
| The Microsoft Object Technology Strategy (098-55163) | MIS, ISVs, System Consultants |
| Management Backgrounders | Primary Audience |
| OLE Corporate Backgrounder (098-56457) | Users, MIS, ISVs, System Consultants |
| The Benefits of Component Software (098-56459) | Users, MIS, ISVs, System Consultants |
| OLE Documents (098-56352) | Users, MIS, ISVs, System Consultants |
| OLE Controls (098-55315) | MIS, ISVs, System Consultants |
| Open Systems: Technology Leadership and Collaboration (098-55058) | MIS, ISVs, System Consultants |
| Technology Comparisons | Primary Audience |
| OLE and OpenDoc: Information for Customers (098-56353) | MIS, ISVs, System Consultants |
| Object Strategies: How They Compare (098-55636) | MIS, ISVs, System Consultants |
| Technical Documents | Primary Audience |
| OLE Documents Technical Backgrounder (098-56453) | Developers |
| Microsoft OLE: Today and Tomorrow (098-56454) | Developers |
| What is an OLE 2 Application? (098-56455) | Developers |
| Developing Applications with OLE 2 (098-56456) | Developers |
| OLE Control Specification Overview (098-56458) | Developers |
| The Microsoft Foundation Class Library (MFC) white paper | Developers |
| The OLE 2.0 Programmer's Reference (ISBN 1-55615-628-6 and -629-4) | Developers |
| Inside OLE 2.0 (ISBN 1-55615-618-9) | Developers |