
Fred Pace
MSDN Content Development Group
July 1997
Click to copy the files in the IntGen sample application for this technical article.
In my article, "Modeling Metadata for API Generation," I discussed how metadata that describes the tables and fields of a database (known as entities and attributes) can be modeled and used in conjunction with code templates to produce source code. In this article, I’ll show how a generation engine might be built that can read text files containing tags, search for and replace the tags with data from the metadata database, and write out the resultant source code to disk. In the process of showing you the details of how the engine is built, I hope to illustrate how good design techniques can be used to simplify the development process, allowing for cleaner, more encapsulated code.
Included with IntGen sample for this article are the generation engine (geneng.dll) and its source code; a sample front-end application (intgen.vbp) to the generation engine; a Microsoft® Access database (intgen.mdb) that stores our metadata; and a handful of templates that can be used with the front-end for generating source code. It is important to understand that this is sample code; it shouldn’t be used in the generation of production code.
The samples were built using the Microsoft Visual Basic® version 5.0 development system and Microsoft Access 97, both of which you’ll need if you plan on working with the code. If you haven’t yet read "Modeling Metadata for API Generation," I suggest you look at it, as it forms much of the basis for this article.
In the first article, I described templates as text files that contain source code interspersed with placeholders called tags. The generation engine will replace the tags with data from the IntGen metadata database (intgen.mdb) or a constant stored in the generation front-end program. Tags that refer to metadata are also stored, along with the name of a column, in the IntGen database in a table called TagMap. The TagMap table is crucial to generation and will be discussed later in this article.
A good template is created from a piece of source code that exhibits the traits of consistency and task isolation. Consistent code is code that reads the same way time after time after time. If you solve a problem a certain way in one piece of code and differently in another piece of code, you are not using a consistent programming style and your code is not a good candidate for a template. Source code that exhibits task isolation has clean, encapsulated methods that generally have a single function and are stateless. For example, a data-access application programming interface (API) might have isolated methods that connect to a data source—Init(); execute a Structured Query Language (SQL) statement against a data source—ExecBoolean(); or prepare a SQL statement for execution against a data source—Insert(), Update(), or Delete(). Code that is both consistent and has isolated tasks makes an excellent template because it solves problems (for instance, the creation of data-access services) the same way with the same methods every time.
A generation system is going to need to know what templates to use to create source files, where they are, and how they relate to each other. The current IntGen database doesn’t include a method for storing this information, so a schema needs to be designed and added to the IntGen database. IntGen template storage will be done in a three-level hierarchy: Template Groups, Templates, and Template Items. This hierarchy is illustrated in Figure 1.
Figure 1. Template storage schema
Let’s examine the tables and their structures and relationships.
A Template Group is a description of the types of files that are to be generated. The Template Group table stores information about the output directory where the files will be created, the language that the generation engine needs to be generating (for example, Visual Basic or Transact-SQL [T-SQL]), and a description of the Template Group. Figure 2 depicts some sample Template Group data.
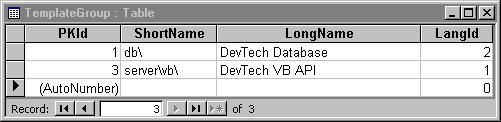
Figure 2. Sample Template Group data
Each Template Group should have one or more Template records. A Template record stores the name of the source code file that needs to be created, as well as a path that the file will be created in. This path is created as a subdirectory of the path given in the Template Group. The Template table does not store the names of the actual template files. Figure 3 depicts some sample Template data.

Figure 3. Sample Template data
Notice the use of a tag in the OutFile field. I chose to allow the use of tags here so that file names could incorporate metadata into their names. For instance, I may want to use the table (entity) name as part of the file name in all my CREATE TABLE scripts. By placing a tag in the Template.OutFile field, I can expand it to give me the name of the table (entity) being created. Thus, tb<!tbname!>.sql might expand to tbAuthor.sql.
The Template Item table stores the file names and paths of the individual template files that will be used as the basis of generated source code. Because a source-code file may require the processing of several template files, each Template record in the Template table should have one or more Template Items. For example, if you refer back to Figure 3, you’ll notice a Template record for a Create Table file. It takes three template files to actually make a Create Table file, and those three template files need to be referenced in the Template Item table. Figure 4 depicts some sample Template Item data.

Figure 4. Sample Template Item Data
Notice the TypeId and the BuildOrder fields. TypeId is used to note whether the template file should be processed only once for a given entity, or whether the file should be processed once for each attribute of a given entity. Entity-level processing takes a template that may look like this:
CREATE TABLE <!TbName!>
(
And then, for a given EntityId, outputs something similar to this:
CREATE TABLE Author
(
Attribute-level processing takes a template that looks like this:
,<!TbField!> <!TbFType!> <!IsNull!>
And expands it against every attribute for a given EntityId into something like this:
,Email varchar(12) NOT NULL
,Name varchar(50) NOT NULL
Pretty slick isn’t it? So now, regardless of whether an entity has one attribute or fifty, the template will be expanded for all and the output concatenated. Later in this article, I’ll show you the code that actually does all this.
Now that we have created a schema for template storage, we can move on to tackling the bigger issues, such as how templates will be parsed.
Often, when a developer sits down to design a system, he or she becomes bogged down in all the details of the system to be created. Not only can this cause delays in getting the darned thing built, but it can lead to ulcers and many sleepless nights. I’d like to show you a few steps that can dramatically simplify the task of designing and coding a system. I know, I know, everyone already knows these steps. Well, if you’ve seen some of the code I’ve seen lately, and heard some of the panic, you’d have to wonder about that.
Before designing a system, every developer should take the time up front to complete each of the following steps:
Let’s take the generation engine sample and work it through these steps.
What is it that you are trying to build? Do you know? Can you describe it? If you can’t get this first step done, then you shouldn’t even attempt to start building the system until you get a better handle on its requirements. The next paragraph describes the core functionality of the generation engine.
The generation engine takes as input a language code and the contents of a text file (a template), which may or may not contain tags, as a string. The engine must then find each tag in the string and replace it with either data from the metadata database or a string constant. After each tag has been replaced, the engine should then provide the converted string as output.
This is where you say, “You mean I have to build that? Hmm, it’ll take about six months and a wish upon a star.” I’ve said that before, myself. But wait, we’re not ready to code yet. Let’s move to the next step.
Now that the system to be built has been successfully identified, it needs to be turned into smaller, more manageable systems. To paraphrase Hannibal Lector in the movie Silence of the Lambs, “Look at each item and ask yourself: What is its nature?” Reread the core functionality statement above, and then answer this: What does the system do?
It searches.
With this information it’s apparent that I will need to build a search system that can take a string and locate a substring with it. Is that so tough to write? Well, it’s a whole lot more manageable than the entire generation system.
It replaces.
The replace functionality needs to be able to accept a tag and replace it with a piece of data. Is that rocket science? Again, it’s a lot easier than trying to write the whole system.
That’s really about it. There’s some small support functionality, but for the most part the generation system is really only two pieces of functionality.
This step may not always be necessary, as I know a lot of you out there are wizards that have designs come to you in visions. If that’s the case, great, you can skip this. Personally, I tend to pseudo-code most functionality that I consider slightly complex and just move the easy stuff straight to code. For this article, let’s consider search and replace functionality complex, and write some pseudo-code.
Since a string that is provided to our engine will most likely (but not always) require searching and replacing, I’ll wrap all the search-and-replace functionality into a single method called Expand(). The pseudo-code for Expand() looks like this:
Accept a string and a SQL statement (so that the correct entity or attribute data can be replaced)
Find first occurrence of a tag
While an occurrence is found
Get the entire tag and its exact position
Get a replacement value for the tag **
Strip out the tag and replace it with the new data
Find another tag occurrence in the string
Loop
Notice the asterisked line above, which gets a tag’s replacement value. Let’s pseudo-code its functionality as well:
Accept a string (the tag) and a SQL statement (this was passed in to the above Expand() method)
Determine if the string matches any of our string constant tags
If so, get the value and exit
Get the tag’s data (which is a column name)
Create a recordset using the SQL statement
Get the data for the column name from the recordset
Exit
Once you are satisfied with your pseudo-code, the next step is to code the methods.
Coding the pieces should now be a much easier task if you have detailed enough of the logic in your pseudo-code. Because I’ll be covering some of the code techniques later in this article, I won’t include them here.
After the core pieces have been built and tested, focus can now be shifted to building all the support functionality and the cool-for-the-sake-of-being-cool functionality. To geneng.dll, I’ll add a method to read a template file from a string (GetTemplate()), and another method to write an expanded template back to disk as a source code file. If you’re interested in the source code for these methods (or any from geneng.dll), check out the sample that is included with this article.
For some reason, writing a parser for the first time can be a daunting task. Let’s look at some of the actual code from the generation engine and allay some of the complexity fears. The code below illustrates the main search loop of the generation engine. In the sample, this code can be found in the CAdmin.Expand() method.
'Test for existence of tag in buffer.
lTagLoc = InStr(sTemplate, scTagOpen)
While lTagLoc > 0
'initialize results
. . .
'find end of tag
lCurrent = InStr(lTagLoc, sTemplate, scTagClose)
If lCurrent > 0 Then
lLastPos = lCurrent + Len(scTagClose) - 1
sTag = Mid$(sTemplate, lTagLoc, lLastPos - lTagLoc + 1)
Else
. . .
End If
sNew = ReplaceTag(sTag, sQry)
'insert replacement into buffer
. . .
'test for existence of tag in buffer
lTagLoc = InStr(sTemplate, scTagOpen)
Wend
That’s the heart of the system! The entire parsing and search engine lies within a simple While loop and comprises less than thirty lines of code. The loop basically looks for a substring (a tag) within the main string (sTemplate) and then sends the substring off for replacement using ReplaceTag() . After a replacement value is retrieved, the substring is snipped out of the main string and the replacement value is put into its place. When the main string is put back together again, it is searched for another occurrence of the substring and the process begins again until no more substrings are found.
Practice a bit with your Visual Basic string functions (InStr(), Mid$(), Right$(), and Left$()), and you’ll wonder why you ever thought this kind of stuff was hard.
In order to understand how tag replacement is done, it’s important to first understand the TagMap table in the metadata database. The TagMap table stores the name of each tag that refers to a field in any of the metadata tables as well as a pointer to where the data for that tag can be found. Figure 5 illustrates some sample TagMap data.
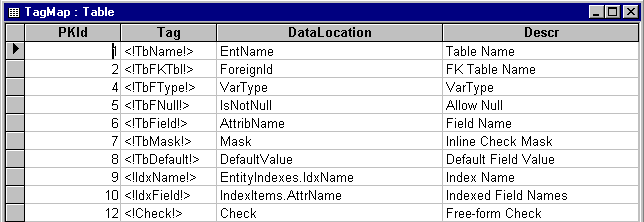
Figure 5. Sample TagMap data
The DataLocation field stores an actual column name found in an entity or attribute query. For example, the <!TbName!> tag is to be replaced by the data found in a column called EntName. However, not all tags that are available to a template file are related to a field in the metadata database. Instead, some tags are defined in code as string constants. For instance, the <!IsNull!> tag refers to the string constant “Not Null”. Tags that refer to constants are not placed into the TagMap table.
When the generation engine is first instantiated, a collection (m_cTagData) is filled with the DataLocation of each tag in the TagMap table and keyed with the tag name. This collection is then used by the replacement method to resolve tags that refer to metadata. Examine the following code that depicts the tag replacement method, CAdmin.ReplaceTag():
Private Function ReplaceTag(sTag As String, sQry As String) As String
. . .
Set rsTemp = m_dbGen.OpenRecordset(sQry, dbOpenSnapshot)
Select Case Trim$(sTag)
Case "<!IsNull!>"
If rsTemp("IsNotNull") Then
sText = scNotNull
End If
Case "<!IsFK!>"
If rsTemp("IsFK") Then
sText = scIsFK
End If
. . .
Case Else
sField = m_cTagData(sTag)
sText = rsTemp(sField)
End Select
. . .
ReplaceTag = sText
End Function
The method receives the name of a tag and a SQL statement as parameters. The SQL statement is then used to create a temporary recordset containing the data from the current entity or attribute being operated on. An attempt is then made to resolve the tag as a string constant. If a match is not found, then the tag must refer to a column of metadata. The tag is used as a key to retrieve the column name from the m_cTagData collection. The column name returned from m_cTagData is then used as a key in the recordset collection rsTemp, thus producing the metadata that we need for replacement. The magic here, folks, is in the keyed collections, which provide a great way to retrieve data that is only known at run time.
Isn’t hard-coding the logic of the Select Case statement bad? Not at all. I know that the power of a template-based code generation system lies in its flexibility, but the logic that we have hard-coded doesn’t affect the flexibility at all. The data fields available to the generation engine are defined in the schema of the metadata database. As the database is an integral part of the generation system, if fields are added to the schema, the generation engine’s source code would have to be modified anyway in order to take advantage of the newly added fields. Because of this, the metadata schema is considered a fixed or known domain. Coding logic that relies upon a known domain (such as the metadata schema), therefore does not limit flexibility because the domain is constant and can be relied upon to be there when the system is run.
Building a system such as a template generation engine needn’t be an insurmountable task. As with any development project, the secret to success lies in the design. Of course, that new system you’ve been told to build looks huge! But what is it really? Isolate the individual tasks that really make up the project. Get that core functionality built and tested before worrying about whistles and bells.
As I mentioned earlier, the generation engine covered in this article is meant only as an example to illustrate design techniques and code samples. It doesn’t represent how systems of this type should or must be done. Perhaps you can think of a different way or even a better way. By all means, build it. That is how you are going to become a better developer. Maybe templates aren’t your thing and you’d rather just hard-code a generator. That works too; build it. Remember that one of the traits of a good developer is consistency. Do your design work the same way, time after time. Write your code the same way, time after time. After these skills become a habit, you’ll find yourself with better designs that you can commit to code in a lot less time. Just practice it!