Herman Rodent
Microsoft Developer Network Technology Group
Created: June 22, 1993
Click to open or copy the files in the TBSS sample application for this technical article.
This article is one of a series of articles that discuss implementing Object Linking and Embedding (OLE) version 2.0 in Microsoft® Windows™-based applications. This article looks at the structured storage facility in OLE and shows how an application can be simply converted from using MS-DOS® files for its storage to OLE's structured storage system. Using structured storage is the first step toward creating an OLE container application.
Any application that you want to become a container for OLE objects must provide a means for the OLE objects it contains to store themselves. The OLE architecture requires that the application provide a pointer to an OLE storage object for this purpose. So before we can really get anywhere with adding OLE container support to an application, we need to learn something about OLE's structured storage system.
You can take two approaches to adding the structured storage necessary for container support in your application. You can take the easy way and create an OLE structured storage object on a chunk of global memory. You can then save the global memory block in your own file any way you like, or you can modify your application to use structured storage instead of regular MS-DOS® files.
My own first response was to immediately opt for the global memory block idea: I didn't want to mess with my file format, and I already understood how to allocate global memory and write it to one of my files. The idea of going for a whole new file architecture seemed a tremendous amount of work, and for what purpose? After reading the OLE documentation and the chapters in Kraig Brockschmidt's unpublished book, Inside OLE 2, that discuss structured storage, I saw that there might be some advantage in converting to this new technology, and consequently, I changed my view and decided to try the idea of porting my application to the new file format instead.
This article is not an in-depth study of OLE's structured storage architecture or features, neither is it a comprehensive account of how you should alter your own application. This is an account of how I modified my own simple TEXTBOX application, and it serves to show just how easy and straightforward modification can be. The TBSS (Text Box with Structured Storage) application is the result of these efforts.
Almost all current OLE discussion centers around objects, methods, and so on. I've tried to avoid too much of this type of discussion by dealing with OLE in much the same way I'd deal with any other Microsoft Windows™ subject—that is, by referring to data structures and the functions that manipulate those structures. It's just a matter of terminology, of course, but what I'm trying to make clear is that there's nothing weird, difficult, or strange about implementing OLE. After all, it's just code.
For those of you who really can't be bothered to dive into the OLE documents, I'll try to sum up what structured storage is all about in as few words as possible.
A single structured storage object is like an entire disk. It has a file allocation table (FAT), one or more directories and subdirectories, and one or more files contained within the directories. In the simplest case, this entire structure can live inside one MS-DOS file. It can also live inside a New Technology File System (NTFS) file in Windows NT™, a chunk of memory, a database record, a Coke® can, a small cardboard box, or, in fact, any storage mechanism you can provide with a simple interface called ILockBytes. The OLE implementation provides a default implementation of ILockBytes for MS-DOS files, which means we get to use structured storage for free.
As for why you might want to use it? That's easy. If your application currently uses more than one file to represent its data, you can put all those files together in one structured storage object, which is itself contained in a single MS-DOS file. Think how easy that would be to distribute and how difficult it would be for a user to accidentally nuke one of the files without noticing it.
The OLE implementation of structured storage provides functions for everything you would normally need when dealing with directories and files within a file system. The directories in a file system are similar to the storage objects in the structured storage system. Files are similar to streams in structured storage. You can create nested storage objects (effectively subdirectories); create, read, write, and delete streams (files); and so on. Each stream supports a single seek pointer. If you want to know more, read the documentation, but be assured that it's all there—all the functions you need to replace your existing multifile storage mechanism with a single structured storage file have been implemented.
Having read some of the documentation, I found that I had a good idea of what I might be able to do with the structured storage functions, but no real idea about where to start. In particular, I really couldn't see how to call the functions that are described in the manual as C++ methods. As I found out, this is all really quite simple. The following sections show how I did it and what the code looks like.
Your code will need to include the OLE2.H header file to get the function definitions, macros, structures, and so on that we are going to use, and you will need to link the OLE2 and STORAGE libraries when building the .EXE file. The TBSS sample includes OLE2.H in GLOBAL.H, thus providing the OLE functions to all its modules. This isn't very efficient in terms of compilation time, but it keeps the code clutter to a minimum.
The OLE libraries require that they be initialized by a simple call and subsequently shut down when your application has finished with them. The documentation shows that there are two ways to go about this. You can call the OleInitialize/OleUninitialize pair or the CoInitialize/CoUninitialize pair. The difference is that the OleInitialize function initializes the entire OLE library set and the CoInitialize function deals only with the lower-level component object library. Because we are going to use only the structured storage facility, which depends solely on the component object library, we can use the CoInitialize/CoUninitialize functions to achieve what we need. We'll worry about the OleInitialize/OleUninitialize functions as we need them.
The OLE 2.0 documentation suggests that, in addition to the initialization functions, you check the version of OLE present on the machine at run time. The general rule to follow when checking versions is that your code should run on any machine with the same or higher major version number as the version you used to develop the application.
Let's look at the code in the TBSS sample that deals with the startup/shutdown stuff. This code is in the INIT.C module in the InitCurrentInstance function:
dwOleVer = CoBuildVersion();
if (HIWORD(dwOleVer) < 20) {
Message(0, "This application requires OLE Version 2.x");
return FALSE;
}
A call is made to CoBuildVersion to get the current run-time version. Note that this is the only API you can call before initialization of the libraries. The current version is tested to make sure it's at least version 2.0, and if not, the application exits.
if (CoInitialize(NULL) != S_OK) {
Message(0, "Failed to initialize the OLE libraries");
return FALSE;
}
bOleInit = TRUE;
If the version is okay, we go on to call CoInitialize and check the return code. If the initialization succeeds, the bOleInit variable is set to TRUE so that, when it's time to terminate the application, we will know that the OLE libraries were initialized and need to be shut down. According to the documentation, it's important not to call the OLE uninitialization functions if initialization of the libraries wasn't done or failed.
So that's all we need to get started. Two calls. All that reading, worry, note taking, and coffee just to make two calls! Really, it doesn't get much worse than this.
When the application terminates, we must be sure to shut down the OLE libraries. The following code takes care of that and can be found in the Terminate function in the INIT.C module:
if (bOleInit) {
CoUninitialize();
}
There's a lot of other stuff in the INIT.C module, but it was all there in the original TEXTBOX application. Only the few lines of code shown here have been added to support the OLE functions we are going to use.
I really wanted to do the absolute minimum that I could get away with in converting my application to use structured storage. In the end, things turned out a little bit more complicated because I decided that I should at least try out some of the OLE 2.0 features to satisfy myself that they did, in fact, work! I also wanted the TBSS application to be able to read the files written by the earlier TEXTBOX application.
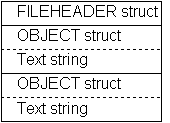
The original TEXTBOX application file format is discussed in "OLE for Idiots: A is for Attitude." The file format layout is reproduced here in Figure 1.
Figure 1. The structure of a TEXTBOX (.TBX) file containing two text rectangle objects
All the code that deals with file I/O is contained in the FILE.C module. Modifying the application to use structured storage involves changes to only this source file. In the following description, remember that a stream is rather like an MS-DOS file and a storage object is like an MS-DOS directory. I use the term substorage to mean a storage object created as the child of another storage object just as subdirectories work in the MS-DOS file system.
The code in FILE.C provides two basic functions: to read a file and create a list of objects, and to write the current list of objects out to a file. The file also contains information about the application's main window size and a tag marking it as one of our files. In adapting the application to use structured storage, I considered splitting the information into two separate streams. The data originally contained in the FILEHEADER structure would be written to one stream and the object list to another. I considered writing each object to its own stream and keeping all these object streams in an objects directory. Although this is reasonably easy to do, I decided that this would only make for more code and not improve anything much, so I stuck to the simple approach, leaving the creation of substorages for later.
The final design, then, consists of two streams contained within the storage object as shown in Figure 2.

Figure 2. The structured storage system used by TBSS
Let's begin by looking at how to create one of these structured storage objects contained in an MS-DOS file. We will be able to test our work with the DocFile Viewer (DFVIEW) application that is shipped with the OLE 2.0 Software Development Kit.
The TEXTBOX application opens an MS-DOS file, writes the header, and then loops, writing object header and data pairs. It then closes the file. In order to save the same information in our structured storage format, we will take these steps:
I use the word close here as an analogy with what we would be doing with real files. In practical terms, we will be using a function called Release to perform this action. Let's look at the code that implements these steps in the FileSave function in FILE.C. I have omitted comments and some error handling for clarity.
LPSTORAGE pStorage;
hResult = StgCreateDocfile(gachFileName,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE | STGM_DIRECT | STGM_CREATE,
NULL, &pStorage);
The StgCreateDocfile function creates a new storage object or (with the flags used here) truncates an existing one to zero. The name is a hangover from the OLE 1.0 days. This is much the same as creating an MS-DOS file. We supply the name and some option flags and, in this case, the address of where the result is to be placed (&pStorage). The flags used in this case give us read/write access, don't let any other process access it, turn off transaction processing, and create the file if it doesn't already exist.
I didn't mention the transaction processing before. OLE's structured storage is a bit more than just a file system in a file. It also has a complete transaction processing option for producing extremely robust applications. This can greatly facilitate undo operations if the system is used wisely. If you're all turned on by the idea of using this, read the discussion of structured storage in Chapter 3, "Architectural Overview," and Chapter 11, "Persistent Storage Interfaces and Functions," of the Object Linking and Embedding Programmer's Reference, Version 2 and also Chapter 5, "Structured Storage and Compound Files," in Kraig Brockschmidt's book, Inside OLE 2, when it is published.
Having created the storage object, we now need to create the INFO stream. In looking for a C function to accomplish this, I found the C++ method IStorage::CreateStream in the OLE documentation. Here is what we need to do to call this method from C:
hResult = pStorage->lpVtbl->CreateStream(pStorage, INFO_STREAM,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE | STGM_DIRECT | STGM_CREATE,
NULL, NULL, &pInfoStream);
Note The way that OLE 2.0 is implemented means that it can be used equally well from C or C++. The C++ usage is generally a little cleaner than C and requires one less parameter in the calls because of the way in which a C++ call always supplies a pointer to the object whose method is being invoked. In C++, the pointer is called the this pointer because it refers to the current object. When calling these object methods as C functions, we need to explicitly provide the this pointer as the first parameter. If you're not a C++ programmer (and I'm not), you really don't need to know much more than this. Just remember that every function you see documented as Class::Method will require you to supply the object pointer as the first parameter, so your C call will have one more parameter than is listed in Object Linking and Embedding Programmer's Reference, Version 2.
You can see that we are not calling a function directly by its name, which is normal C practice, but instead we are dereferencing the object pointer through a table of pointers to functions. The OLE implementation always generates the lpVtbl field in every object, so you will always call these method functions in exactly this way.
The first parameter is the object pointer. The second is the name of the stream. I have used the INFO_STREAM constant here, which is defined in GLOBAL.H as the string "INFO". The third parameter is a set of option flags. The set used here is the same as we used to create the storage object earlier. The final parameter supplies the address to return the stream object pointer.
Here's the definition of the IStorage::CreateStream method from Object Linking and Embedding Programmer's Reference, Version 2:
HRESULT IStorage::CreateStream(pwcsName, grfMode, res1, res2, ppstm)
const char FAR * pwcsName
DWORD grfMode
DWORD res1
DWORD res2
LPSTREAM FAR * ppstm
Please notice that the this pointer is not shown.
In my own implementation, this was the biggest step. I struggled for ages to find out how to call these C++ methods in C. This is all there is to it. Once I had this figured out, the rest was simply a matter of finding the names of the functions I needed.
Moving right along, let's look at how the INFO stream data is written out and how we close the stream:
hResult = pInfoStream->lpVtbl->Write(pInfoStream, &FileHead,
sizeof(FileHead), &cb);
pInfoStream->lpVtbl->Release(pInfoStream);
As you can see, writing data to a stream is exactly like writing to an MS-DOS file. We get the function pointer by using the same dereferencing technique we used to get the CreateStream function pointer. The object pointer is passed as the first parameter, followed by a pointer to the information we want to write, the length of the data, and a pointer to where we want the result count to be written. The OLE functions guarantee to always return exactly the count of bytes read or written even if an error occurs—this is sooo much better!
Finally, I close the stream by calling the Release function.
Note Having lots of storage structures and streams open in your application doesn't affect the MS-DOS file handle count. Remember, the entire storage object is contained in one file, so you only have one MS-DOS file handle in use at any time. If you're not getting enthusiastic about using structured storage by now, go back and read about it again. Structured storage is a tremendous improvement over dealing with the file system directly.
Writing out the text information to the TEXTOBJECTS stream follows the same technique as used for the INFO stream:
hResult = pStorage->lpVtbl->CreateStream(pStorage, OBJECT_STREAM,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE | STGM_DIRECT | STGM_CREATE,
NULL, NULL, &pObjStream);
pObj = gpObjList;
while (pObj) {
hResult = pObjStream->lpVtbl->Write(pObjStream, pObj, sizeof(OBJECT),
&cb);
hResult = pObjStream->lpVtbl->Write(pObjStream, pObj->pInfo,
pObj->uiSize, &cb);
pObj = pObj->pNext;
}
pInfoStream->lpVtbl->Release(pInfoStream);
Once the code was written and compiled, I ran it and checked the result by saving a file containing just one object, and then I viewed the result with the DocFile Viewer. Figure 3 shows a screen shot of the DocFile Viewer with the file open. The DocFile Viewer is one of many applications that come with the OLE 2.0 Software Development Kit. The DocFile Viewer allows you to view the structure and contents (in hex) of a structured storage file.
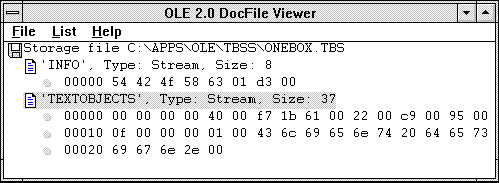
Figure 3. A Docfile Viewer look at a structured storage file
If you've been following the story so far, I'm sure you can guess that reading the structured storage object back in as the two streams we wrote out is fairly trivial. There is one additional thing to do here, though. I wanted the TBSS application to be able to read the files written by itself and also by the older TEXTBOX application. I was going to use the file extension as an indicator of which sort of file was being opened until I came across the StgIsStorageFile function, which tests a file to see if it is a structured storage file. (Isn't it nice to have obvious API names for a change?) I used this function to make a first test and, if it failed, used the old TEXTBOX code to try to read it as an MS-DOS file. If the test went okay, the file was opened as a structured storage file and new code executed to read it that way. Here's the call to test the file type:
if (StgIsStorageFile(gachFileName) != S_OK) {
...
Once we find it is a storage file, the code goes on to open the storage, open the INFO stream, read it, and close it:
hResult = StgOpenStorage(gachFileName, NULL, STGM_READ | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT, NULL, NULL, &pStorage);
hResult = pStorage->lpVtbl->OpenStream(pStorage, INFO_STREAM, NULL,
STGM_READ | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT, NULL, &pInfoStream);
hResult = pInfoStream->lpVtbl->Read(pInfoStream, &FileHead,
sizeof(FileHead), &cb);
pInfoStream->lpVtbl->Release(pInfoStream);
Just as you suspected, this code is pretty much a copy of the write code, but it uses the Read method function to retrieve the stream data. The code for reading the text objects is so similar that I'll omit it.
As you can see, there really isn't anything difficult here. We used a couple of functions to perform initialization and another handful to do all the storage and stream manipulation in almost exactly the same way we would normally deal with directories and files.
The OLE 2.0 documentation includes many more functions. Check out creating substorages, experiment with creating fascinating data structures, and verify them with the DocFile Viewer.
If you're looking for something to show the boss, this is going to be a hard sell because there's not much that looks different so far in the application. But we've made a start. In the next article, we'll go on to add basic container support to the application and make use of the storage work we did here, so we can store objects embedded in our application by the user.
One point to note here is that we have used structured storage in the same way we use MS-DOS file handles: open, access, close. As we'll see when we come to creating an OLE container application, the application needs to provide a structured storage object for each OLE object at creation time. This means that the OLE application generally has to have an open storage object all the time, which involves changing the way the application deals with the whole open/close scenario. Just to make things a little more complex, each OLE object needs to have its own storage object in which it can save itself. This means that we will be providing a set of substorages from the root storage, one for each object, and we are going to have to manage this list of substorages. This is a little more complicated than the simple approach in this article, but rest assured that the final code is really not much more complicated than that shown here.