Herman Rodent
Microsoft Developer Network Technology Group
Created: August 6, 1993
Click to open or copy the files in the Bucket sample application for this technical article.
This article is the third in the "OLE for Idiots" series and describes the implementation of the simplest form of OLE (object linking and embedding) container application. This is what it's all about—sticking other people's objects in your application—but you can't start here. You need to read "OLE for Idiots: A Is for Attitude" and "OLE for Idiots: B Is for Beginning" first.
The Bucket sample application, which accompanies this article, was written in C and was derived from the TBSS sample application associated with the previous article in the series, "OLE for Idiots: B Is for Beginning." Bucket supports object embedding (not linking) and editing by a server in a separate window (not in-place editing).
This article looks at what you must do to add the simplest form of OLE (object linking and embedding) container support to an existing Microsoft® Windows™-based application. Although this article could be read on its own, you would do well to read the previous two articles first—"OLE for Idiots: A Is for Attitude" and "OLE for Idiots: B Is for Beginning"—because they cover the fundamental design of the application and the use of OLE's structured storage respectively.
I have some good news and some bad news. First, the good news: This article takes the shortest possible route to achieving a container application. The sample code is written in straight C and avoids (as much as possible) too much discussion of the Component Object Model upon which OLE 2.0 is built. The bad news is that this article is not a substitute for reading the OLE documentation. You will need to do that as well.
If you're starting from scratch—that is, you've read none of the OLE documentation—then take time to read at least the introductory sections so that you will be familiar with some of the terminology and goals of OLE. By the time this article is available, you should be able to read a pre-release version of Kraig Brockschmidt's book, Inside OLE 2, on the Microsoft Developer Network CD. Kraig's book gives a complete discussion of the OLE model, including step-by-step instructions on how to create your own OLE applications. Much of the information in this article came straight from Kraig's book. I cannot recommend it highly enough.
Throughout this series of articles, "OLE" means OLE version 2.0. So far as I am concerned, OLE 1.x does not exist. If you are porting from OLE 1.0 to OLE 2.0, much of the material will seem obvious. If you are starting with OLE 2.0, be assured that no previous knowledge of OLE 1.0 is required.
OLE 2.0 is probably most noted for its in-place editing feature. This article, however, doesn't go as far as in-place editing in the implementation. It stops, instead, at the point where an object can be inserted in the document and subsequently edited by its server, with the server being run in a separate window. Later articles will cover the addition of in-place editing.
Bucket, the sample application that accompanies this article, includes support for the Clipboard, but does not support drag-and-drop operations. Drag-and-drop operations are covered in the next article in this series, "OLE for Idiots: D Is for Drag and Drop."
I chose to do all the sample implementation in C rather than C++ because I know C and so do all of you. Some of you know C++. If you want to implement in C++, there is nothing here to prevent you. In fact, implementing in C++ is potentially simpler because much of the component object model upon which OLE 2.0 is based is similar to C++ objects.
In almost all of my code samples, I generally ignore whether a pointer is near, far, or huge, and simply name it as a pointer. So, for example, a pointer to a bucket would be named pBucket rather than npBucket, lpBucket, or hpBucket. As we move towards the happy days of 32-bit flat memory model programming for Windows, I hope this style will become more commonplace.
The code extracts shown in the article have comments, debug code, and error handling code removed to keep them as brief and obvious as possible. The actual code for the Bucket sample contains a lot of debug code (in dprintf macros) and a menu item you can use to change the level of debug messages displayed as the application runs.
In implementing the Bucket sample application, I followed these steps:
My own implementation took several weeks. Much of the time was spent trying to find out what was wrong with the few lines of code I'd just written. Some of my investigations took me down blind alleys and wasted a lot of time. By following the order set down here, you should be able to avoid some of these problems.
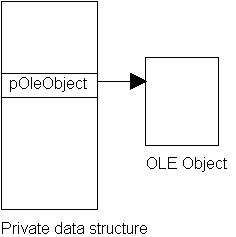
There is much talk of objects these days. OLE 2.0 documents are full of this talk, and unfortunately, this article must refer to them, too. Two types of objects are discussed here: private objects and compound document objects. The private object is a collection of data used to manage a compound document object embedded in the container application. I somewhat unfortunately used the type name OBJECT for this private data. So while reading this article, try to bear in mind that the terms "my object," "private object," "private data," and so on refer to the application's object, and "compound document object" refers to a compound document object that is part of the application's private object. Figure 1 shows an example of a private data object containing a reference to a compound document object.
Figure 1. A compound document object as part of some private data
The first change to make is to add code to check the OLE version number and initialize the OLE libraries. Note that we use OleInitialize here and not CoInitialize (as was used in the TBSS application) because we now need to use the entire OLE system and not just a few of its component parts. The INIT.C module in Bucket contains the code to perform the required initialization.
dwOleVer = CoBuildVersion();
if (HIWORD(dwOleVer) != rmm) {
Message(0, "This application requires OLE Version %u.%u",
rmm / 10, rmm % 10);
return FALSE;
}
if (LOWORD(dwOleVer) < rup) {
Message(0, "This app requires a later version of the OLE libs.");
return FALSE;
}
if (OleInitialize(NULL) != S_OK) {
Message(0, "Failed to initialize the OLE libraries");
return FALSE;
}
bOleInit = TRUE;
Having successfully initialized the OLE libraries, the start-up code goes on to perform its first piece of real OLE magic:
InitInterfaces();
This function is contained in the IFACE.C module and is responsible for initializing the function pointer tables associated with the OLE interfaces that Bucket supports. Since we haven't discussed the nature of these interfaces yet, just accept that they need initializing, and we'll come back to what's going on here later.
When the application terminates, the OLE 2.0 libraries are dismissed by calling OleUninitialize.
You can modify your own application at this point to include the initialization and termination calls and check that the OLE libraries load when your application runs. Not very exciting, but it's a start.
The first major addition to your application will be the Insert Object dialog, which allows the user to select a compound document object for insertion into your document. You can go about creating this dialog in two ways: You could read the OLE specification and write your own code for the dialog, or you can take the easy way out and use the code provided in OLE2UI. If you've read the OLE specification, you'll be feeling better already just knowing you won't have to implement the dialog yourself. Figure 2 shows the Insert Object dialog.
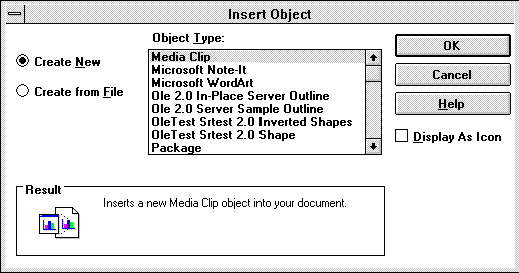
Figure 2. The Insert Object dialog from OLE2UI
If you've reviewed the Object Linking and Embedding 2.0 Toolkit files, you may have noticed that the user interface DLL (OLE2UI) comes as a set of source files. The reason for this is that many developers will need to modify the text of the dialogs for internationalization, and it's simplest to supply the source for the entire thing. No OLE2UI.DLL is supplied because you are expected to build the sources yourself and name the DLL in some way unique to your application.
Note Obviously, we can't all create our own unique dialog DLL and call it OLE2UI.DLL!
If you want to try building the OLE2UI sample, now would be a good time to do so. By default, it produces files called OUTLUI.LIB and OUTLUI.DLL, which are intended to go with the Outline sample application shipped with the OLE Toolkit.
If you don't want to bother building the sample and are satisfied with the US language version of the dialogs (as I was), you can use the OUTLUI.DLL supplied with the OLE Toolkit and move on to more important things. The APIs in OLE2UI are not listed in the Object Linking and Embedding Programmer's Reference, Version 2. Documentation in the Help file OLE2UI.HLP supplied with the OLE Toolkit is rather minimal.
Invoking the Insert Object dialog involves filling in a data structure (OLEUIINSERTOBJECT) and calling the OleUIInsertObject application programming interface (API). Here's the first part of the code from the InsertObjCmd function in the OBJECT.C file:
void InsertObjCmd(HWND hWnd)
{
OLEUIINSERTOBJECT io;
char szFile[OLEUI_CCHPATHMAX];
UINT uiRet;
_fmemset(&io, 0, sizeof(io));
io.cbStruct = sizeof(io);
io.dwFlags = IOF_SELECTCREATENEW | IOF_SHOWHELP;
io.hWndOwner = hWnd;
szFile[0] = '\0';
io.lpszFile = szFile;
io.cchFile = sizeof(szFile);
uiRet = OleUIInsertObject(&io);
if (uiRet != OLEUI_OK) {
if (uiRet != OLEUI_CANCEL) {
Message(0, "Failed to invoke dialog. Err: %u", uiRet);
}
return;
}
[code omitted]
As you can see, this is fairly simple. The dwFlags field is set so that the Help button is available and the default selection is to create a new compound document object. The szFile buffer is used to return the name of a linked file and is not used in this version of the application, which only supports embedded objects. Some of the other fields of the structure are filled in as return values.
You can add an Insert Object menu item to your application and try invoking the dialog box before proceeding to the next part, which involves actually creating a compound document object and requires a good deal more code.
Before we can create a compound document object, we need to revise the way the application stores its data. If you aren't familiar with OLE's structured storage, take a few minutes to read the previous article, "OLE for Idiots: B Is for Beginning," and perhaps some of the information about structured storage in the OLE documents.
In the TBSS application associated with "OLE for Idiots: B Is for Beginning," I used structured storage the same way you use an MS-DOS® file: I opened it, accessed it, and closed it. We have to change that model slightly because each compound document object we are going to create has to have its own storage object available all the time. This doesn't mean we will have lots of MS-DOS file handles open—we will use just one for the entire storage tree with a number of substorages (like subdirectories) for the compound document objects.
Keeping the storage object open in the application involves some fairly significant changes to the application code. To begin with, we need to always have a storage object open, even if no file is loaded, so the FileNew function in the application has to create a temporary storage object. If a file is opened, the current storage is either written to a file or discarded (at the user's discretion) and a new storage object created from the contents of the file being opened.
Saving a file by its existing name (Save) is fairly trivial, as we shall see, but saving it by a different name (Save As) is not so simple and requires us to copy all the current storage object tree to a new tree opened for the new filename.
One additional problem occurs when we try to reload the file later, so we need to deal with this problem now because it affects the overall storage architecture: There has to be some way to enumerate all the object storages in the file so that we can reload all of them. This could be done in one of two ways: Given a storage object, it is possible to enumerate all its children using one of OLE's enumerator objects. The enumeration can select only storage objects (not streams) and then the results of the enumeration could be tested to ensure that each storage object so found was in fact one of the compound document objects we stored. This requires rather a lot of code, and it turns out to be much simpler to write a list of the object storage names into a stream held in the root of the main storage object. The Bucket application keeps the names of its compound document objects in a stream called OBJLIST and some additional information in another stream called INFO. Naming the storage objects is another minor problem. I chose to keep a 32-bit numeric value, which is used to hold the next free object number, as a part of the INFO stream. Each object is assigned a name containing "OBJ" followed by the object's numerical value: OBJ1, OBJ2, and so on. This system develops an interesting bug when the object number rolls over, but with 32 bits you are going to have to create a lot of objects for that to be a problem in my lifetime!
There is one additional point to consider when naming a stream or substorage that is to be part of a storage used to save a compound document object: The name must indicate in some way that the stream (or storage) is private to the application and must not be altered or deleted by the compound document object's server at any time. This is done by making the first character of the stream or storage the hex value 3. So the INFO stream name is actually declared as "\3INFO" in GLOBAL.H.
I chose to name both INFO and OBJLIST using this convention, even though OBJLIST is only used in the root.
So, to recap: We need a storage object open all the time, and each compound document object is going to need a substorage of its own. At this point, I decided that my Bucket application would no longer support its own objects; it would only support compound document objects. This meant that I had only one object type to deal with.
Figure 3 shows a screen shot of the DocFile Viewer from the OLE 2.0 Toolkit with one of Bucket's files open. The file contains two compound document objects. You can see the INFO and OBJLIST streams and the OBJ0 and OBJ1 substorages used to save the compound document objects. Note that each substorage also has an INFO stream and a number of other streams belonging to the compound document object itself.

Figure 3. One of Bucket's files viewed with DocFile Viewer
"Aaaaargh!" I hear you say. "We can't do that with our application." And of course you don't need to. I simply wanted to keep the volume of sample code down to a minimum, the intention being to reintroduce the private object types later when the application becomes an OLE server. Once the private objects become compound document objects, the question of supporting them goes away because both internal and external objects are all compound document objects, and the internal ones are supported by the code that supports external compound document objects. Wimping out? Sure it is, but it avoids writing code today that will be thrown out tomorrow.
Let's begin by looking at the code that creates the temporary storage object when the FileNew function in STORE.C is used. FileNew is called when the application starts and whenever the user selects the File New menu item:
gachFileName[0] = '\0';
hResult = StgCreateDocfile(NULL, // filename
STGM_READWRITE | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT | STGM_CREATE,
NULL,
&gpStorage);
The global variable gachFileName is used to store the name of the currently open file. Because we have a temporary file open, gachFileName is set to be an empty string. The OLE function StgCreateDocfile is used to create a new storage object. Using NULL for the filename argument results in the creation of a temporary storage object. The pointer to the new storage object is saved in gpStorage. We will use gpStorage again later when we create a compound document object.
There is actually a little more code than this in the FileNew function, but this is all we need to look at for the moment. Now that we have created a storage object, we are one step closer to being able to create a compound document object from the Insert Object dialog.
Deep down inside the OLE documentation is a note that says that all OLE container applications must support the IOleClientSite and IAdviseSink interfaces. Reading the documentation on these interfaces led me to believe that this was going to be a lot of work—there is certainly a lot to understand. As it turned out, it wasn't so bad to do, but it was very hard to find out just which bits were important, which were optional, and which could thankfully be ignored.
What are interfaces? OLE's component object model defines objects as having internal data and one or more public interfaces. These interfaces are groups of functions that can be invoked to get the object to do something. Container applications need to provide a certain set of functions that OLE can call in order to get the container application to do something or, at least, to notify the container application of an event that has occurred that it might be interested in. In terms of regular programming for Windows, these interfaces in the container application are simply a set of callback functions.
The IOleClientSite interface consists of nine functions that OLE uses to request the container application to perform various tasks. Three have common trivial implementations, two have some real code to them, and the rest are not required. Of the two functions that do any real work, one is used to save an object's data to its storage, and the other function is concerned with drawing the object in a shaded or unshaded manner as a part of the user interface.
The IAdviseSink interface consists of eight functions called by OLE to notify the container application of various events. Three share a common implementation with their equivalents in IOleClientSite, one function is used to repaint our document's view, and the others are not required.
So you can see from this brief description that whatever these interfaces are, they aren't going to be a lot of work to create.
Each OLE interface consists of a pointer to a table of function pointers called a vtable (pronounced "vee table"). Our first job in implementing an interface is to create the table of function pointers and initialize it to point to the relevant functions. Figure 4 shows how this all fits together.
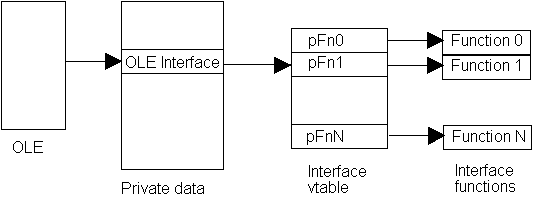
Figure 4. How OLE calls a specific function through an interface in the application's private data
The tables for the interfaces supported by Bucket are defined in the IFACE.C file as:
IOleClientSiteVtbl MyClientSiteVtbl;
IAdviseSinkVtbl MyAdviseSinkVtbl;
IDataObjectVtbl MyDataObjectVtbl;
Ignore the IDataObject interface table for the moment. We'll come back to that one when we look at Clipboard support. Each of the table types (IOleClientSiteVtbl, for example) are defined in the OLE header files. Each table we create needs to be initialized, which is done by the InitInterfaces function, also in the IFACE.C module. InitInterfaces is called as a part of the application initialization. Note that if we were implementing this in C++, the table initialization for these interfaces could be done by the compiler because the OLE vtable structure is the same as the virtual function pointers used in C++ objects, and each interface can be implemented as a C++ object. Here's a section of the InitInterfaces function that sets up the table for the IOleClientSite interface:
MyClientSiteVtbl.QueryInterface = ClientSite_QueryInterface;
MyClientSiteVtbl.AddRef = ClientSite_AddRef;
MyClientSiteVtbl.Release = ClientSite_Release;
MyClientSiteVtbl.SaveObject = ClientSite_SaveObject;
MyClientSiteVtbl.GetMoniker = ClientSite_GetMoniker;
MyClientSiteVtbl.GetContainer = ClientSite_GetContainer;
MyClientSiteVtbl.ShowObject = ClientSite_ShowObject;
MyClientSiteVtbl.OnShowWindow = ClientSite_OnShowWindow;
MyClientSiteVtbl.RequestNewObjectLayout = ClientSite_RequestNewObjectLayout;
Each function in the table has to be implemented according to the description in the Object Linking and Embedding Programmer's Reference, Version 2. The IFACE.C module contains all of the functions with appropriate stub code for those functions that do nothing. Shortly we'll look at what the interface functions do that we are required to implement.
OLE's component object model uses reference counts to control the lifetime of its objects. Each time a pointer to an object is returned from one of the object's interface functions, the object makes a call to its own AddRef function, which increases the reference count by one. When the pointer is no longer in use, the user of the pointer calls the object's Release function to decrement the reference count. If calling Release causes the reference count to become zero, the object is deleted.
In implementing Bucket, I initially ignored reference counts completely. This didn't give me any problems until I tried to implement Clipboard data transfers. When the Clipboard is finished with the object, it calls its Release function to decrement its reference count, which should result in the temporary data object being deleted as its reference count falls to zero. Because I had no reference count implemented, I couldn't determine when to delete the object.
Implementing reference counts on the objects you create is easy, so it is as well to do this right from the start.
Let's look at the data structure that Bucket uses to hold all the data for one of its embedded objects. Here's the definition from GLOBAL.H:
typedef struct _OBJECT FAR *POBJECT;
typedef struct _OBJECT {
DWORD dwMagic; // Magic number
POBJECT pNext; // Pointer to the next one
LONG lRef; // Reference count
LPOLEOBJECT pOleObj; // Pointer to its OLE info
LPSTORAGE pStorage; // Pointer to its storage object
char szStorageName[32]; // Its storage name (OLE1 etc)
RECT rc; // Container rectangle
BOOL bSelected; // Is it selected?
BOOL bObjOpenInWindow; // TRUE if open in server window
struct _ObjIClientSite { // IClientSite interface
IOleClientSiteVtbl FAR * lpVtbl; // Pointer to generic vtbl
// for IClientSite
POBJECT pObject; // Pointer to the object's data
} ObjIClientSite;
struct _ObjIAdviseSink { // IAdviseSink interface
IAdviseSinkVtbl FAR * lpVtbl; // Pointer to generic vtbl
// for IAdviseSink
POBJECT pObject; // Pointer to the object's data
} ObjIAdviseSink;
struct _ObjIDataObject { // IDataObject interface
IDataObjectVtbl FAR * lpVtbl; // Pointer to generic vtbl
// for IDataObject
POBJECT pObject; // Pointer to the object's data
} ObjIDataObject;
} OBJECT;
In implementing the required interfaces and reference counting, the fields of interest are lRef, ObjIClientSite, ObjIAdviseSink, and ObjIDataObject. lRef is simply a 32-bit value that holds the reference count for the object. This value starts at zero when the object is created. The three interfaces all have similar structures: a pointer to the interface vtable and a pointer to an OBJECT structure.
The similarity in the interface structures is intentional. Figure 5 shows who's pointing at what during a call to an interface function. When we give OLE a pointer to an interface, we actually provide a pointer to the vtable pointer. When OLE needs to call a function in one of our interfaces, it dereferences the interface pointer we supplied earlier (1) to get the address of the vtable (2), and then indexes into the table to find the address of the function it wants to call (3). When the function is called, the first parameter passed is the C++ this pointer (a pointer to the object whose function is being called). In our case, the this pointer will be a pointer to one of the interface structures declared in our own object structure (ObjIAdviseSink, for example). So when one of our interface functions is called, we can cast the this pointer to be a pointer to the appropriate interface structure (in this case, struct _ObjIAdviseSink) (4), and then use the pObject member of that structure (for example, the _ObjIAdvise Sink) to obtain the address of the base of our actual object data (5). Hence, when any of the functions for any of the interfaces our object supports is called, we will be able to reference any of the object's private data.

Figure 5. Who's pointing at what during a call to an interface function
Now that we've looked at the data structures, let's look at how the reference counting functions AddRef and Release are implemented. Because every interface needs these functions and our own interface data structures are similar, we can use one generic implementation and a bit of type casting to provide these functions for all our interfaces. Here are the generic AddRef and Release functions as implemented in IFACE.C (with some debug code removed for clarity):
STDMETHODIMP_(ULONG) MyAddRef(LPVOID pThis)
{
POBJECT pObject;
pObject = ((struct _ObjIClientSite FAR *)pThis)->pObject;
(pObject->lRef)++;
return pObject->lRef;
}
STDMETHODIMP_(ULONG) MyRelease(LPVOID pThis)
{
POBJECT pObject;
LONG lReturn;
pObject = ((struct _ObjIClientSite FAR *)pThis)->pObject;
lReturn = --(pObject->lRef);
if (pObject->lRef == 0) {
DeleteObj(pObject);
}
return lReturn;
}
As you can see, these functions are trivial. The this pointer is cast to one of the interface structures (which structure isn't important as they are all the same), the object base address is obtained, and the lRef field of the object is modified appropriately. The DeleteObj function is in OBJECT.C, and we'll look at that later.
Here's how these generic functions are called in implementing the IOleClientSite interface:
STDMETHODIMP_(ULONG) ClientSite_AddRef(LPOLECLIENTSITE pThis)
{
return MyAddRef(pThis);
}
STDMETHODIMP_(ULONG) ClientSite_Release(LPOLECLIENTSITE pThis)
{
return MyRelease(pThis);
}
The same technique is used to implement these functions in the IAdviseSink and IDataObject interfaces.
Now is as good a time as any to look at one of the practical problems we face in implementing these OLE interfaces. In creating a regular Windows-based application, we know that each time we provide a callback function to Windows, that function must be exported and have an instance thunk created for it by calling MakeProcInstance. If you look at the Bucket sample, you won't find the interface functions treated this way: They are not in the .DEF file, and there are no calls to MakeProcInstance for them. Yet they are callbacks—OLE will be calling them. If you look at the AddRef and Release functions shown above, you will see that they are defined as STDMETHODIMP_(ULONG). If you dig around in the OLE header files, you will find that this definition includes the __export compiler directive, so these functions are exported. But what about the MakeProcInstance calls—how can we live without these? Well, we can't, and we don't. For some time I was mystified by how all this could work, until the strange set of compiler flags used in the make files of the OLE sample programs was pointed out to me. Each of these includes /GA /GEs instead of the more usual /Gw switch for Windows-based applications. The /GA switch replaces the Windows entry/exit prologue code (generated by using /Gw) with more efficient code for protected-mode Windows. The /GEs switch causes the prolog code of exported functions to load DS from the value in SS. In this way, you can avoid calling MakeProcInstance to create a thunk that loads DS. The RELNOTES.WRI file shipped with the OLE 2.0 Toolkit contains more detailed information.
In your own application, you can choose either to use these compiler switches or do all the MakeProcInstance calls yourself. Letting the compiler deal with it provides a cleaner solution.
More information on compiler switches is in Dale Rogerson's articles, "Microsoft Windows and the C Compiler Options" and "The C/C++ Compiler Learns New Tricks," both on the MSDN Library CD.
Part of the object model for OLE allows the interrogation of any object to see if it supports a given interface. In order to support this facility, every object must provide the QueryInterface function. As for AddRef and Release, QueryInterface can be implemented generically.
STDMETHODIMP MyQueryInterface(LPVOID pThis,
REFIID iid,
LPVOID FAR* ppNew)
{
POBJECT pObject;
*ppNew = NULL;
pObject = ((struct _ObjIClientSite FAR *)pThis)->pObject;
if (IsEqualIID(iid, &IID_IOleClientSite)) {
*ppNew = &(pObject->ObjIClientSite);
} else if (IsEqualIID(iid, &IID_IAdviseSink)) {
*ppNew = &(pObject->ObjIAdviseSink);
} else if (IsEqualIID(iid, &IID_IDataObject)) {
*ppNew = &(pObject->ObjIDataObject);
} else {
return ResultFromScode(E_NOINTERFACE);
}
((LPUNKNOWN)(*ppNew))->lpVtbl->AddRef(*ppNew);
return NOERROR;
}
Given the reference ID of an interface, QueryInterface tests to see if the interface is supported by our object. Note the use of OLE's IsEqualIID function rather than a direct comparison. If the interface is supported, a pointer to the interface data structure (within our OBJECT structure) is returned, and the reference count is incremented by calling the AddRef function via the interface pointer. The implementation of QueryInterface then becomes trivial for any particular interface. The implementation for IAdviseSink follows.
STDMETHODIMP AdviseSink_QueryInterface(LPADVISESINK pThis,
REFIID iid,
LPVOID FAR* ppNew)
{
return (MyQueryInterface(pThis, iid, ppNew));
}
As I mentioned a little earlier, apart from AddRef, Release, and QueryInterface (which all compound document objects must support), we need implement only two functions of the IOleClientSite interface—the remainder can be stubbed out. The functions we need to implement are SaveObject and OnShowWindow. OLE calls SaveObject to save an object's data to the object's storage medium. Below is my implementation from IFACE.C with some debug code and comments removed for clarity.
STDMETHODIMP ClientSite_SaveObject(LPOLECLIENTSITE pThis)
{
POBJECT pObj;
LPPERSISTSTORAGE pPersist;
HRESULT hResult;
pObj = ((struct _ObjIClientSite FAR *)pThis)->pObject;
pPersist = (LPPERSISTSTORAGE) OleStdQueryInterface(
(LPUNKNOWN) pObj->pOleObj,
&IID_IPersistStorage);
if (!pPersist) {
return ResultFromScode(E_FAIL);
}
hResult = OleSave(pPersist, pObj->pStorage, TRUE);
if (!MyTestOleResult(hResult)) {
return ResultFromScode(E_FAIL);
}
return NOERROR;
}
The this pointer is used to obtain a pointer to our private object structure. The code queries the compound document object for a pointer to its IPersistStorage interface and calls the OleSave function to save the object's data to the storage object we created for the compound document object at the time the object itself was created. Note that we haven't looked at object creation yet!
A call to the OnShowWindow function notifies the container application as to whether the object is visible in its server window or not. The call is made when the server window opens and again when it closes so that the container can draw the object in an appropriate way. If the object is not visible in its server window, it is drawn normally. If the server has the object open and visible, the container should draw the object shaded to indicate to the user that it cannot be currently edited or activated. Obviously, this changes when editing in place is used because there will be no server window present. Implementation is straightforward:
STDMETHODIMP ClientSite_OnShowWindow(LPOLECLIENTSITE pThis, BOOL fShow)
{
POBJECT pObject;
pObject = ((struct _ObjIClientSite FAR *)pThis)->pObject;
pObject->bObjOpenInWindow = fShow;
InvalidateRect(ghwndMain, &(pObject->rc), TRUE);
return NOERROR;
}
A flag is set in the object's data structure to indicate whether the object is visible in the server window or not, and the region occupied by the object is invalidated so that it will be redrawn. Bucket's object rendering code tests the flag to determine whether the object should be shaded or not. (We'll look at the actual rendering code later.)
All the other IOleClientSite functions return some sort of error code to indicate that they are not supported or that some default action should be taken.
Apart from AddRef, Release, and QueryInterface (which all compound document objects must support), we need only implement one function from the IAdviseSink interface—OnViewChange, which is called when some aspect of the contained object must be redrawn to reflect a change made by its server. Here's the implementation:
STDMETHODIMP_(void) AdviseSink_OnViewChange(LPADVISESINK pThis,
DWORD dwAspect,
LONG lIndex)
{
POBJECT pObj;
pObj = ((struct _ObjIClientSite FAR *)pThis)->pObject;
gfDirty = TRUE;
InvalidateRect(ghwndMain, &(pObj->rc), TRUE);
}
The global flag gfDirty is set TRUE to indicate that a change has been made to the document, and the region occupied by the object is invalidated so that it will be redrawn. Figure 6 shows a typical order of events when the application makes a call to an OLE function (1) and OLE responds with an advise notification (2).

Figure 6. A typical advise notification sequence
That's it for the interfaces we are required to support in the simplest form of container application. Now we can move on to creating a compound document object.
We now have sufficient support for a compound document object and can start to create it using the Insert Object dialog that we looked at such a long time ago! OLE provides an API called OleCreate for this purpose; it requires several parameters. The key parameters are the class ID of the object to create, a storage object for use in saving the compound document object once it's created, and a pointer to the container application's IOleClientSite interface.
The compound document object's storage (as you may remember) will be created as a substorage of the global storage we always have open. The client site interface is implemented in the application, so all that's missing is the class ID of the object, and that's supplied as a return parameter from the Insert Object dialog.
Before we look at the code to actually create the compound document object, I should point out that we are going to create compound document objects in other ways (from Clipboard data, for example), and we don't want the same chunk of code appearing in lots of different places in the application. When I first developed Bucket, I had several different places where OleCreate was called, and in a fit of tidiness, I put them all into one function, which takes a parameter that determines from what source the compound document object is to be created. So as we look at the creation code, try to bear in mind that you aren't going to understand what all the options are for yet.
Here's the tail end of the function that shows the Insert Object dialog and actually invokes the compound document object creation function:
pObj = CreateObj(gptInsert.x,
gptInsert.y,
DEFAULT_OBJ_WIDTH,
DEFAULT_OBJ_HEIGHT,
NULL,
NULL,
&(io.clsid),
FROM_CLASSID);
if (!pObj) return;
AppendObj(pObj);
ActivateObj(pObj);
InvalidateRect(hWnd, &(pObj->rc), TRUE);
The internal function CreateObj in OBJECT.C is called with the coordinates of the object rectangle, the class ID of the compound document object, and a flag to indicate that the object should be created from the class ID. If successful, the new object is added to the internal object list. The new object is then activated. Activation causes the compound document object's server to be run so that the user can set the initial state of the new object. The screen area is repainted to show the new object in place. Note that the server runs asynchronously to the container, so the repaint will occur before the server is finished with the object. OLE uses the IOleClientSite::OnShowWindow function to request the container to alter the drawn image as the server window appears and disappears.
Now let's look at the bits of the CreateObj function in OBJECT.C that actually do the work. A lot of code has been cut out here so that you can see just the bits relevant to creating a compound document object from its class ID.
POBJECT CreateObj(int x, int y, int w, int h,
LPSTORAGE pStorage, LPDATAOBJECT pDataObj,
REFCLSID pClsid,
DWORD dwFlags)
{
POBJECT pObj;
HRESULT hResult;
DWORD dwJunk;
pObj = (POBJECT) ALLOCATE(sizeof(OBJECT));
if (!pObj) return NULL;
pObj->dwMagic = OBJECT_MAGIC;
pObj->lRef = 0;
pObj->pNext = NULL;
pObj->pOleObj = NULL;
pObj->pStorage = NULL;
pObj->szStorageName[0] = '\0';
pObj->rc.left = x;
pObj->rc.top = y;
pObj->rc.right = x + w;
pObj->rc.bottom = y + h;
pObj->bSelected = FALSE;
pObj->ObjIClientSite.lpVtbl = &MyClientSiteVtbl;
pObj->ObjIClientSite.pObject = pObj;
pObj->ObjIAdviseSink.lpVtbl = &MyAdviseSinkVtbl;
pObj->ObjIAdviseSink.pObject = pObj;
pObj->ObjIDataObject.lpVtbl = &MyDataObjectVtbl;
pObj->ObjIDataObject.pObject = pObj;
if ((dwFlags & FROM_CLASSID) || (dwFlags & FROM_DATA)) {
char szStorageName[32];
wsprintf(szStorageName, "OBJ%lu", gdwNextObject++);
hResult = gpStorage->lpVtbl->CreateStorage(gpStorage,
szStorageName,
STGM_READWRITE
| STGM_SHARE_EXCLUSIVE
| STGM_DIRECT | STGM_CREATE,
NULL,
NULL,
&(pObj->pStorage));
if (!MyTestOleResult(hResult)) {
Message(0, "Failed to create %s storage",
(LPSTR) szStorageName);
DeleteObj(pObj);
return NULL;
}
lstrcpy(pObj->szStorageName, szStorageName);
}
if (dwFlags & FROM_CLASSID) {
hResult = OleCreate(pClsid,
&IID_IOleObject,
OLERENDER_DRAW,
NULL,
(LPOLECLIENTSITE)&(pObj->ObjIClientSite),
pObj->pStorage,
(LPVOID)&(pObj->pOleObj));
if (!MyTestOleResult(hResult)) {
DeleteObj(pObj);
return NULL;
}
}
return pObj;
}
The function begins by allocating storage for the private object data structure. The ALLOCATE macro makes changing the memory allocation scheme easy during development. It maps to _fcalloc in the C run-time library, but you can change that in GLOBAL.H if you want to do it differently.
Once the storage is allocated, the fields of the OBJECT structure are set to initial values. Note how the OLE interfaces are initialized.
Because we are (in this case) creating the compound document object from only its class ID, we have no storage object currently allocated for it. Calling the CreateStorage method with the global storage object (gpStorage) as the parent allocates a substorage. The name of the storage object is constructed from the next free storage number so that it'll be unique, and this name is saved as part of the private object data.
Once the storage object has been created, OleCreate is called to create the actual compound document object itself, and the compound document object pointer is saved in the private object data structure. Once the compound document object is created, the only task that remains is setting up a request for notifications (via our IAdviseSink interface) and defining some names that OLE will use in dialogs when referring to our application and the file we currently have open:
pObj->pOleObj->lpVtbl->Advise(pObj->pOleObj,
(LPADVISESINK)&(pObj->ObjIAdviseSink),
&dwJunk);
OleSetContainedObject((LPUNKNOWN)(pObj->pOleObj), TRUE);
pObj->pOleObj->lpVtbl->SetHostNames(pObj->pOleObj,
gszAppName,
gachFileName);
The call to OleSetContainedObject here is one of those "don't ask me, just do it" things. It seems that without calling this function, some pointers OLE obtains to our objects won't get released, and hence the objects will never be correctly deleted. In practice, I found that there were still cases when the user deleted an object and, even after releasing all the pointers to the object and its interfaces, the reference count was still nonzero. I currently consider this to be a bug in my sample code—even though I can't find it. Maybe you will!
That's it. You now have a compound document object embedded in your document. We just need to look at two more topics—activating a compound document object and rendering the image of a compound document object.
When a compound document object is initially created by the user, the server needs to be run so that the user can set the initial state of the object. The server also needs to be run if the user wants to edit the object, which is initiated by double-clicking it. Activating the compound document object's server is done by calling its DoVerb function. The DoVerb function is used to invoke one of an object's verbs. Some verbs (such as OPEN) are supported by all objects; others may be private to the object. We'll look at how DoVerb is used to activate the server here:
BOOL ActivateObj(POBJECT pObj)
{
HRESULT hResult;
hResult = pObj->pOleObj->lpVtbl->DoVerb(pObj->pOleObj,
OLEIVERB_OPEN,
NULL,
(LPOLECLIENTSITE)&(pObj->ObjIClientSite),
0,
ghwndMain, // parent window
&(pObj->rc));
if (!MyTestOleResult(hResult)) return FALSE;
return TRUE;
}
Note the use of the OLEIVERB_OPEN flag and the ubiquitous IOleClientSite interface, which is used to control the container when the server is running.
If you review the story so far, you'll see that we have occasionally made calls to InvalidateRect to mark an area for repainting. Now let's look at what we do when we eventually get a WM_PAINT message in order to render the compound document object's image.
In the module MAIN.C, you'll find a function called Paint, which processes the application's WM_PAINT messages. Paint walks down the internal object list, calling the internal RenderObj function for each object, and then finally draws a small cross to mark where the current insertion point is:
static void Paint(HWND hWnd, LPPAINTSTRUCT lpPS)
{
POBJECT pObj;
pObj = gpObjList;
while (pObj) {
RenderObj(lpPS->hdc, pObj);
pObj = pObj->pNext;
}
SetROP2(lpPS->hdc, R2_NOT);
MoveTo(lpPS->hdc, gptInsert.x - 10, gptInsert.y);
LineTo(lpPS->hdc, gptInsert.x + 10, gptInsert.y);
MoveTo(lpPS->hdc, gptInsert.x, gptInsert.y - 10);
LineTo(lpPS->hdc, gptInsert.x, gptInsert.y + 10);
}
Not too much rocket science here, so let's look at the RenderObj function, which does all the real work. I've omitted the code that shows the red rectangle around the currently selected object because it has nothing to do with rendering the compound document object itself:
void RenderObj(HDC hDC, POBJECT pObj)
{
LPOLEOBJECT pOleObj;
LPVIEWOBJECT pViewObj;
HRESULT hrErr = NOERROR;
RECTL rclHim;
pOleObj = pObj->pOleObj;
pViewObj = (LPVIEWOBJECT)OleStdQueryInterface(
(LPUNKNOWN) pOleObj,
&IID_IViewObject);
rclHim.top = pObj->rc.top;
rclHim.left = pObj->rc.left;
rclHim.bottom = pObj->rc.bottom;
rclHim.right = pObj->rc.right;
hrErr = pViewObj->lpVtbl->Draw(pViewObj,
DVASPECT_CONTENT, // draw content (for now)
-1,
NULL,
NULL,
NULL,
hDC,
&rclHim,
&rclHim,
NULL,
0);
if (pObj->bObjOpenInWindow) {
OleUIDrawShading(&(pObj->rc),
hDC,
OLEUI_SHADE_FULLRECT,
0);
}
}
The function begins by obtaining a pointer to the compound document object's IViewObject interface, which it is required to support. Next, it defines a rectangle to indicate where the object is in the container window, and the object's Draw method is invoked to actually draw it. Note the use of the RECTL structure, rather than the more usual RECT. OLE uses 32-bit parameters throughout. Actually, the object effectively draws itself, which is rather convenient. In practice, the OLE cache should contain an image of the object that can be used here so that the object's server is not started simply to render it. Please refer to Kraig Brockschmidt's book for more details on how the cache works.
Finally, the function tests to see if the object's server window is open, and if it is open, the object is shaded out by calling the OleUIDrawShading function in the OLE2UI library.
If you're doing the implementation as you read this, now is a good time to stop reading, write some code, and test everything. You should be able to insert a compound document object, move it around, and double-click it to reinvoke the server to edit it. You can't save what you've done yet, but we'll look at that next.
There's not much point in creating all these objects if we can't save them, so moving right along, let's see how that's done. Saving the state of the container and its embedded objects is not difficult, but there is a reasonable amount of work to do.
Going back to our earlier discussion about the general architecture of the storage system, you may recall that we have a storage object open all the time, which makes it reasonably easy to perform the File Save operation, but a little more difficult to perform the File Save As operation because we need to generate a completely new storage tree under the new file name. What is common to both Save and Save As, however, is that, given a storage object, we need to write the INFO stream that contains data about the application window size and so on, the OBJLIST stream that contains the names of all the object substorages, and finally a substorage for each compound document object.
If the user selects Save As, we need to create a new storage tree and copy the existing one to it. Fortunately, the copy operation is trivial. Here's the code that creates the new storage file and copies the entire storage tree to it:
hResult = StgCreateDocfile(achFileName,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT | STGM_CREATE,
NULL,
&pStor);
if (!MyTestOleResult(hResult)) goto ERROR_SAVING;
hResult = gpStorage->lpVtbl->CopyTo(gpStorage,
NULL,
NULL,
NULL,
pStor);
if (!MyTestOleResult(hResult)) goto ERROR_SAVING;
That was fairly easy, but there's a catch. Each of our private objects contains a pStorage, which now points to the old storage tree and not the new one, so we need to release each of these pointers and set them up to point to the correct storage objects in the new tree.
pObj = gpObjList;
while (pObj) {
if (pObj->pStorage) {
pObj->pStorage->lpVtbl->Release(pObj->pStorage);
}
hResult = pStor->lpVtbl->OpenStorage(pStor,
pObj->szStorageName,
NULL,
STGM_READWRITE
| STGM_SHARE_EXCLUSIVE
| STGM_DIRECT,
NULL,
NULL,
&pObj->pStorage);
pObj = pObj->pNext;
}
Now let's look at only the piece of code from FileSave in STORE.C that saves the individual compound document objects. Note that for each compound document object we save, we also save an INFO stream with our own private data on the individual object. It might have been better to save this data as a part of the OBJLIST stream. Here's the code that saves the compound document objects:
pObj = gpObjList;
while (pObj) {
hResult = pObj->pStorage->lpVtbl->CreateStream(pObj->pStorage,
INFO_STREAM,
STGM_READWRITE
| STGM_SHARE_EXCLUSIVE
| STGM_DIRECT | STGM_CREATE,
NULL,
NULL,
&pInfoStream);
if (!MyTestOleResult(hResult)) goto ERROR_SAVING;
hResult = pInfoStream->lpVtbl->Write(pInfoStream,
pObj,
sizeof(OBJECT),
&cb);
pInfoStream->lpVtbl->Release(pInfoStream);
if (cb != sizeof(OBJECT)) goto ERROR_SAVING;
pPersist = (LPPERSISTSTORAGE) OleStdQueryInterface(
(LPUNKNOWN) pObj->pOleObj,
&IID_IPersistStorage);
if (!pPersist) {
Message(0, "One of the compound document objects does not support being saved");
} else {
hResult = OleSave(pPersist,
pObj->pStorage,
TRUE);
if (!MyTestOleResult(hResult)) {
Message(0, "Failed to save compound document object");
goto ERROR_SAVING;
}
}
pObj = pObj->pNext;
}
The code creates an INFO stream and writes the private object data to it. We don't actually need all this data, but it was easier to just write the whole thing than decide which bits I really needed.
A pointer to the compound document object's IPersistStorage interface is obtained by calling OleStdQueryInterface, and the helper function OleSave is used to store the compound document object.
Having written a file containing a set of compound document objects and some other private data, we can now look at what's involved in opening that file and reading its contents. To load from a file, follow these steps:
Testing the file to determine if it's a structured storage file can be done in one call:
if (StgIsStorageFile(achFileName) != S_OK) {
... // report the problem
}
Once we know it's a structured storage file, we can see whether it contains an INFO stream, and if it does, read the stream to ensure the file was created by Bucket. Here's the code (with some of the error handling removed) that verifies the file was created by Bucket.
hResult = StgOpenStorage(achFileName,
NULL,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT,
NULL,
NULL,
&pStor);
if (!MyTestOleResult(hResult)) goto ERROR_OPENING;
hResult = pStor->lpVtbl->OpenStream(pStor,
INFO_STREAM,
NULL,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT,
NULL,
&pInfoStream);
if (!MyTestOleResult(hResult)) goto ERROR_OPENING;
hResult = pInfoStream->lpVtbl->Read(pInfoStream,
&FileHead,
sizeof(FileHead),
&cb);
pInfoStream->lpVtbl->Release(pInfoStream);
if (cb != sizeof(FileHead)) goto ERROR_OPENING;
if (FileHead.dwMagic != FILEMAGIC) goto ERROR_OPENING;
Once we know the file was created by our own application, we can go ahead and open the object list stream:
hResult = pStor->lpVtbl->OpenStream(pStor,
OBJLIST_STREAM,
NULL,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT,
NULL,
&pInfoStream);
Then, for each entry in the object list, we open the object's storage, read the INFO stream, and create a compound document object from the data in the storage.
hResult = pInfoStream->lpVtbl->Read(pInfoStream,
szStorageName,
sizeof(szStorageName),
&cb);
if (!MyTestOleResult(hResult) || (cb != sizeof(szStorageName))) break;
hResult = pStor->lpVtbl->OpenStorage(pStor,
szStorageName,
NULL,
STGM_READWRITE
| STGM_SHARE_EXCLUSIVE
| STGM_DIRECT,
NULL,
NULL,
&pObjStorage);
if (!MyTestOleResult(hResult)) goto ERROR_OPENING;
hResult = pObjStorage->lpVtbl->OpenStream(pObjStorage,
INFO_STREAM,
NULL,
STGM_READWRITE | STGM_SHARE_EXCLUSIVE
| STGM_DIRECT,
NULL,
&pObjInfoStream);
if (!MyTestOleResult(hResult)) goto ERROR_OPENING;
hResult = pObjInfoStream->lpVtbl->Read(pObjInfoStream,
&O,
sizeof(O),
&cb);
pObjInfoStream->lpVtbl->Release(pObjInfoStream);
if (cb != sizeof(O)) goto ERROR_OPENING;
pObj = CreateObj(O.rc.left, O.rc.top,
O.rc.right - O.rc.left, O.rc.bottom - O.rc.top,
pObjStorage,
NULL,
NULL,
FROM_STORAGE);
if (!pObj) goto ERROR_OPENING;
Once the new object has been created, we save the storage name and release the storage pointer. Finally, the new object is added to the internal object list.
lstrcpy(pObj->szStorageName, szStorageName);
pObjStorage->lpVtbl->Release(pObjStorage);
AppendObj(pObj);
} while (1);
When all the objects are loaded, the object list stream can be released.
pInfoStream->lpVtbl->Release(pInfoStream);
Notice that we used Bucket's internal CreateObj function to create the compound document object from the data in the storage object. Here's the piece of code from CreateObj that does the important bit:
if (dwFlags & FROM_STORAGE) {
hResult = OleLoad(pStorage,
&IID_IOleObject,
(LPOLECLIENTSITE)&(pObj->ObjIClientSite),
(LPVOID)&(pObj->pOleObj));
if (!MyTestOleResult(hResult)) {
Message(0, "Failed to load compound document object");
DeleteObj(pObj);
return NULL;
}
pObj->pStorage = pStorage;
}
As you can see, most of the work of creating a compound document object from its storage object is done by calling the OLE function OleLoad. In fact, the various helper functions that are part of the OLE API set make most storage operations fairly easy to perform once you know which API to use!
Remember that your storage architecture doesn't have to be the same as Bucket's. The only requirement is that you provide a separate storage object for each compound document object. The INFO and OBJLIST streams in Bucket's architecture are there only to manage the "what should go where" problem.
It's hard to say whether Clipboard support is easier or harder with OLE than with regular Windows. It's certainly different. One of OLE 2.0's goals was to avoid the needless copying of data that occurred with OLE 1.0 because it was based on dynamic data exchange (DDE). This copying was wasteful of resources and took more time than was really necessary. OLE 2.0 solves the problem by changing the way data is transferred, making it both more flexible and more efficient.
OLE uses the IDataObject interface for data transfers. In order to place a compound document object on the Clipboard, the object must support the IDataObject interface. This doesn't mean that any object you wish to copy has to support this interface—only the object you copy to the Clipboard. Why the distinction? It's possible to implement a special object only for data transfers. This is potentially much cleaner than forcing all your objects to support the IDataObject interface.
Because I was working on the principle of "the less code, the better," I decided that it would be simpler to add the IDataObject interface to Bucket's internal objects rather than create a whole new object. In retrospect, I'm not so sure this was the right choice, but it still works.
The IDataObject interface consists of 12 functions, including the usual three: AddRef, Release, and QueryInterface. Of the other nine, only four needed anything more than a simple stub. I should point out that the implementation is a bit thin here, with only enough code to make the few cases that I tried work. There are plenty of debug statements to trap cases not implemented, should they occur, and Kraig Brockschmidt's book covers this topic extremely well. We'll look at how the IDataObject functions are implemented in the next two sections.
Sending an object to the Clipboard involves first making a copy of the object. "But you said we didn't need to do any copying!" We need to do this so that, if the user modifies the object in the container and subsequently does a paste from the Clipboard, the result of the paste will be the object state when it was copied to the Clipboard, rather than its recently modified state. Kind of a shame to have to copy it, but there you go—users are funny like that. Actually, you need not copy the object. You could simply set some flag that prevents it from being altered while it's in the Clipboard. This might be a good plan for large objects although it does change the way the user perceives data in the Clipboard. Bucket implements a direct copy of the object because that is really the simplest thing to do. Let's look at the code from ClipCommand in CLIP.C, which processes Copy and Cut requests.
pObj = gpObjList;
while (pObj) {
if (pObj->bSelected) break;
pObj = pObj->pNext;
}
pCFObj = CopyObj(pObj);
if (!pCFObj) {
Message(0, "Unable to copy object");
return;
}
A search for the currently selected object happens first. Bucket only supports single selection to make things easy. Once located, the object is copied by calling the CopyObj function in OBJECT.C. CopyObj uses CreateObj to make a copy of the object to a new (temporary) storage object.
pDataObj = NULL;
hResult = OleGetClipboard(&pDataObj); // we don't care what it returns
if (pDataObj) pDataObj->lpVtbl->Release(pDataObj);
Access is obtained to the Clipboard. This looks very hokey, but it's straight out of the OLE manual. For some odd reason, we need to do a "get" call first rather than some form of "open." A side effect of this is that there might actually be an object in the Clipboard, and if there is, we get a pointer to it. We don't want to access this object, so we must release its pointer before proceeding.
pDataObj = (LPDATAOBJECT) &(pCFObj->ObjIDataObject);
hResult = OleSetClipboard(pDataObj);
We get a pointer to the IDataObject interface in the new object that we copied our data to and send it to the Clipboard.
if (wParam == IDM_CUT) {
DeleteObj(pObj);
InvalidateRect(ghwndMain, NULL, TRUE);
}
If the user requested Cut, we delete the object and repaint to show the change.
That looks fairly simple, but actually there is quite a lot going on here. When we send the object to the Clipboard, OLE calls the EnumFormatEtc function to interrogate the object through its IDataObject interface to see what formats it supports. Here's how that's implemented in IFACE.C:
STDMETHODIMP DataObject_EnumFormatEtc(LPDATAOBJECT pThis,
DWORD dwDirection,
LPENUMFORMATETC FAR *ppForm)
{
if (dwDirection != DATADIR_GET) {
return ResultFromScode(E_FAIL);
}
*ppForm = OleStdEnumFmtEtc_Create(giSingleObjGetFmts,
gSingleObjGetFmts);
return NOERROR;
}
If the request asks for what formats the object can have "put" to it, the function reports that "put" isn't supported by returning E_FAIL. Just as you were wondering how to enumerate the formats a compound document object supports (right?), you can see the OLE2UI library has yet another handy helper function to do this for us. The call to OleStdEnumFmtEtc creates an enumerator object for the formats we support in the application. The module DATAFORM.C contains the array of supported formats. As it turns out, you can afford to be generous here and offer to support formats you can't deliver on. Keeping the list reasonable, though, avoids wasted calls attempting to get data you can't provide.
Once the Clipboard is finished enumerating formats, it releases the enumerator object pointer, which results in the object deleting itself. (Well, that's one vote in favor of object-oriented programming, I guess.)
If the Clipboard viewer is active, it will attempt to show some rendition of the object, and this results in more calls to the IDataObject interface as the Clipboard attempts to get data in some format it can display. There are three functions involved in this: QueryGetData, GetData, and GetDataHere. QueryGetData is used to test to see if a call to GetData for a given format would succeed. To implement this, I created a function called IsValidDataFormat in DATAFORM.C. This function tests to see if a given format is in our own list of supported formats, and if not, it asks the compound document object whether it supports it by calling the compound document object's own IDataObject::QueryGetData function. The code for IsValidDataFormat follows.
BOOL IsValidDataFormat(POBJECT pObj, LPFORMATETC pFmt)
{
int i;
LPDATAOBJECT pDataObj;
HRESULT hResult;
for (i=0; i<giSingleObjGetFmts; i++) {
if (gSingleObjGetFmts[i].cfFormat == pFmt->cfFormat) {
return TRUE;
}
}
pDataObj = (LPDATAOBJECT)OleStdQueryInterface(
(LPUNKNOWN) (pObj->pOleObj),
&IID_IDataObject);
if (pDataObj) {
hResult = pDataObj->lpVtbl->QueryGetData(pDataObj,
pFmt);
if (SUCCEEDED(hResult)) return TRUE;
}
return FALSE;
}
So, given that we have a function to test for supported formats, the implementation of QueryGetData is trivial.
STDMETHODIMP DataObject_QueryGetData(LPDATAOBJECT pThis,
LPFORMATETC pFormat)
{
POBJECT pObject;
pObject = ((struct _ObjIClientSite FAR *)pThis)->pObject;
if (!IsValidDataFormat(pObject, pFormat)) {
return ResultFromScode(DATA_E_FORMATETC);
}
return NOERROR;
}
Now we can provide enumerations of our format list and provide information on support for specific named formats. Let's look at how the data is actually transferred. The GetData function requests that the IDataObject interface provide the storage that contains the requested data. The GetDataHere function requests that the IDataObject interface copy the data to storage provided by the caller. There's quite a lot in common between these two functions, but I chose to implement them independently. Let's look at GetData first.
STDMETHODIMP DataObject_GetData(LPDATAOBJECT pThis,
LPFORMATETC pFormat,
LPSTGMEDIUM pMedium)
{
POBJECT pObject;
LPDATAOBJECT pDataObj;
HRESULT hResult;
pObject = ((struct _ObjIClientSite FAR *)pThis)->pObject;
pDataObj = (LPDATAOBJECT)OleStdQueryInterface(
(LPUNKNOWN) (pObject->pOleObj),
&IID_IDataObject);
if (pDataObj) {
hResult = pDataObj->lpVtbl->GetData(pDataObj,
pFormat,
pMedium);
if (SUCCEEDED(hResult)) return NOERROR;
}
if (GetObjData(pObject, pFormat, pMedium, FALSE)) return NOERROR;
return ResultFromScode(DATA_E_FORMATETC);
}
The GetData function first tries to get the data directly from the compound document object by obtaining a pointer to its IDataObject interface and then by calling the compound document object's GetData function. If that fails, a call is made to the internal function GetObjData to see if that can provide it. The implementation of GetDataHere is similar, as you can see below.
STDMETHODIMP DataObject_GetDataHere(LPDATAOBJECT pThis,
LPFORMATETC pFormat,
LPSTGMEDIUM pMedium)
{
POBJECT pObject;
LPDATAOBJECT pDataObj;
HRESULT hResult;
pObject = ((struct _ObjIClientSite FAR *)pThis)->pObject;
pDataObj = (LPDATAOBJECT)OleStdQueryInterface(
(LPUNKNOWN) (pObject->pOleObj),
&IID_IDataObject);
if (pDataObj) {
hResult = pDataObj->lpVtbl->GetDataHere(pDataObj,
pFormat,
pMedium);
if (SUCCEEDED(hResult)) return NOERROR;
}
if (GetObjData(pObject, pFormat, pMedium, TRUE)) return NOERROR;
return ResultFromScode(DATA_E_FORMATETC);
}
First, the compound document object is requested to supply the data. If that fails, we try to supply it by calling our own GetObjData function.
Before looking at how GetObjData works, you might be wondering exactly why we could possibly supply data on a compound document object if it can't supply it itself. There seem to be three cases in which this occurs.
The first case is for the CF_TEXT format. Sometimes the compound document object can't provide any data in the CF_TEXT format. This is often the case for picture type objects, and in these cases, the container should provide the type name of the object. Of course, we get this name by asking the object for it, which makes me wonder why we need to do this at all. Why couldn't OLE do this for us? So many questions, so few answers. Nonetheless, the responsibility falls on the container to provide some sensible text if the object doesn't.
The second case the container has to handle is in providing the "Object Descriptor" format, which is required to support paste operations on compound document objects. The compound document object cannot provide this format itself because part of the information has to do with how the object is being displayed in the container. Note that we haven't covered any display issues because this article is already rather long and they are covered well in Kraig Brockschmidt's book. Once more the OLE2UI DLL comes to the rescue with the OleStdGetObjectDescriptorDataFromOleObject function, which does what we need it to and wins the prize for the longest API name so far.
The third case is a request for the "Embedded Object" format, which turns out to be a case of simply copying from one storage object to another.
Enough banter; back to the code. Here is the implementation of GetObjData. This is another case of doing the least work possible—a lot of cases are ignored. I implemented what was needed to make all the test cases I tried work. I've left the debug and error handling code out here to keep it as short as possible, but even so, it's still rather long and involved.
BOOL GetObjData(POBJECT pObj, LPFORMATETC pFmt, LPSTGMEDIUM pMed, BOOL bHere)
{
HGLOBAL hGlobal;
LPSTR pData = NULL;
POINTL pointl;
HRESULT hResult;
LPSTR pRet;
if (!bHere) {
pMed->tymed = NULL;
pMed->hGlobal = NULL;
pMed->pUnkForRelease = NULL; // all punks should be locked up for life
}
if (pFmt->cfFormat == CF_TEXT) {
if (!(pFmt->tymed & TYMED_HGLOBAL)) return FALSE;
if (!bHere) {
hGlobal = GlobalAlloc(GMEM_MOVEABLE | GMEM_ZEROINIT | GMEM_SHARE,
1024); // nice big chunk
if (!hGlobal) return FALSE;
} else {
hGlobal = pMed->hGlobal;
}
pData = GlobalLock(hGlobal);
if (pData) {
hResult = pObj->pOleObj->lpVtbl->GetUserType(pObj->pOleObj,
USERCLASSTYPE_FULL,
&pRet);
if (!MyTestOleResult(hResult)) {
lstrcpy(pData, "Some OLE thing");
} else {
lstrcpy(pData, pRet);
}
GlobalUnlock(hGlobal);
}
if (!bHere) {
pMed->tymed = TYMED_HGLOBAL;
pMed->hGlobal = hGlobal;
}
return TRUE;
} else if (pFmt->cfFormat == gcfObjectDescriptor) {
if (!(pFmt->tymed & TYMED_HGLOBAL)) {
return FALSE;
}
pointl.x = pointl.y = 0;
if (!bHere) {
hGlobal = OleStdGetObjectDescriptorDataFromOleObject(pObj->pOleObj,
NULL,
DVASPECT_CONTENT,
pointl);
if (!hGlobal) return FALSE;
} else {
return FALSE; // can't do 'here'
}
if (!bHere) {
pMed->tymed = TYMED_HGLOBAL;
pMed->hGlobal = hGlobal;
}
return TRUE;
} else if (pFmt->cfFormat == gcfEmbeddedObject) {
if (!(pFmt->tymed & TYMED_ISTORAGE)) {
return FALSE;
}
if (!bHere) {
return FALSE; // expected 'here'
} else {
hResult = pObj->pStorage->lpVtbl->CopyTo(pObj->pStorage,
NULL,
NULL,
NULL,
pMed->pstg);
if (!MyTestOleResult(hResult)) return FALSE;
return TRUE;
}
}
return FALSE;
}
There are two arguments to the GetObjData function that are important: the format type and the storage type. The format type is CF_TEXT, "Object Descriptor," or whatever, and the storage type is the type of medium in which the data is to be returned. When dealing with the Windows Clipboard, we usually provide data in global memory blocks. OLE uses private Clipboard formats and a form of delayed rendering by the data source, which allows a much wider variety of media to be used. For example, the data can exist in a structured storage object in a file. The data can be huge and yet pass through the Clipboard from one application to another without the file data ever actually being moved anywhere. The implementation of GetObjData only supports those formats and media types I found to be required during development. A more complete implementation of the IDataObject interface would include support for a much wider range of types and media.
Much of the detail involved in pasting data into a container from the Clipboard is the same as that which we have just looked at in supporting copy operations. Here's the code in CLIP.C that handles paste requests:
pDataObj = NULL;
hResult = OleGetClipboard(&pDataObj);
if (!MyTestOleResult(hResult)) return;
pObj = CreateObj(gptInsert.x,
gptInsert.y,
DEFAULT_OBJ_WIDTH,
DEFAULT_OBJ_HEIGHT,
NULL,
pDataObj,
NULL,
FROM_DATA);
AppendObj(pObj);
InvalidateRect(hWnd, &(pObj->rc), TRUE);
OleGetClipboard is used to get an IDataObject interface pointer, and the internal CreateObj function is used to create the compound document object from the data. The new object is added to the list and the view redrawn to reflect the change. The CreateObj function creates a storage object for the new compound document object and then uses OleCreateFromData to actually create it. Here are the two sections of code from CreateObj that handle this:
if ((dwFlags & FROM_CLASSID) || (dwFlags & FROM_DATA)) {
char szStorageName[32];
wsprintf(szStorageName, "OBJ%lu", gdwNextObject++);
hResult = gpStorage->lpVtbl->CreateStorage(gpStorage,
szStorageName,
STGM_READWRITE
| STGM_SHARE_EXCLUSIVE
| STGM_DIRECT | STGM_CREATE,
NULL,
NULL,
&(pObj->pStorage));
if (!MyTestOleResult(hResult)) {
DeleteObj(pObj);
return NULL;
}
lstrcpy(pObj->szStorageName, szStorageName);
}
if (dwFlags & FROM_DATA) {
hResult = OleCreateFromData(pDataObj,
&IID_IOleObject,
OLERENDER_DRAW, // let server choose format
NULL, // no specific format
(LPOLECLIENTSITE)&(pObj->ObjIClientSite),
pObj->pStorage, // storage object
(LPVOID)&(pObj->pOleObj));
if (!MyTestOleResult(hResult)) {
DeleteObj(pObj);
return NULL;
}
}
That's it for minimal Clipboard support. Once you have implemented this, you should be able to insert an object, copy it to the Clipboard, and paste it back again. Try cutting and pasting objects between your own application and other OLE applications, such as those supplied with the OLE Toolkit.
The container application described here allows the user to insert compound document objects into a simple document view. The document can be saved to disk and later reloaded. Individual objects can be transferred through the Clipboard.
There is a lot missing. Much of the code is minimal and supports only a few essential cases, but it should provide you with a good starting point.
I found learning about this very hard. Creating Bucket was much harder than creating the Soundblaster device driver I wrote for Windows NT™, for example. I hope that this article will help you get a good start and that you will go on to invest time in reading Kraig Brockschmidt's book even though his examples are in C++!
I did not implement drag-and-drop in this version, even though it is similar in some ways to Clipboard support. I felt that a complete implementation would involve too much change—change from the way objects currently are moved around inside the application window using the rubber band method to using the drag-and-drop method instead. Drag-and-drop will be covered in the next article in this series.
The printing support is minimal—almost embarrassingly so. The individual objects are rendered to the printer device context (DC), but no attempt is made to provide correct clipping or to achieve any sort of WYSIWYG effect.
When I look back at my own code, it seems to me that Bucket's OBJECT structure could have been improved a little, and I could have provided AddRef and Release functions for these objects. In other words, I could have created my own objects, using the same object model that OLE uses, and this might well have made things a bit more consistent. This is the approach Kraig takes in his most excellent book.