Charlie Kindel
Program Manager, Windows NT/Cairo
Created: August 27, 1993
Updated: October 6, 1995
This article is designed to help you understand OLE persistent property sets and how to use them. Property sets are documented in the OLE 2.0 Programmer's Reference. Unfortunately, documentation in earlier versions of the OLE and Win32® software development kits (SDKs) were incomplete. Therefore, this document was originally created in an attempt to create a "one-stop shopping place" for OLE property set information. Today, the OLE property sets topic in the Win32 SDK is accurate; however, this article strives to explain OLE persistent property sets in more detail.
Also included in this article are helpful code snippets and structure definitions that you may find useful when implementing property-set–related code. To some, this kind of information may be obvious, but for others it will save them the trouble of trying to figure it out themselves.
This article assumes the reader is familiar with the overall architecture of OLE and understands the OLE structured storage model (in particular, the IStorage and IStream interfaces).
"Property sets are tagged collections of values, whose meaning (schema) is known to the code that manipulates them; that is, as much as that code needs to know the meaning."
That's the first sentence from the section on property sets in the original OLE 2.0 Programmer's Reference (Appendix B, page 636). When I first read it, I said "Huh?" and read it again. It didn't help. As I read on, it became obvious that someone needed to document these things better.
Property sets are a means of storing information in such a way that any conforming program can manipulate that information. OLE does not currently provide any code for manipulating property sets; all it does is specify a standard structure for a data format. However, future versions of Microsoft® operating systems may include component object module (COM)–style interfaces for accessing property sets and the properties they contain.
Because the data format is made up of tagged collections of values, the data format is partially self-identifying. In other words, each value stored within a property set has a type associated with it that indicates how the value is stored. For example, if a specific property within a property set were to hold an animal's scientific name, that name would be stored as a zero-terminated string. Stored along with the name would be a type indicator that indicated that the value was a zero-terminated string. Any piece of code that knew the OLE property set data format could read (and write) the property that holds the animal's scientific name because the property would indicate that it was a zero-terminated string.
Every property consists of three things: an identifier, a type indicator, and a value. Each property within a property set has a unique identifier, which is used to name the property. The type indicator describes the representation of the data in the value. For example, if the property contained a 2-byte (16-bit) integer specifying the number of legs an animal had, the property would look something like this:
| Property Identifier | Type Indicator | Value |
| PID_LEGCOUNT | VT_I2 | WORD |
Again, any application that knows about property sets would be able to look at the property with an ID of PID_LEGCOUNT, recognize that it is a 2-byte integer (VT_I2), and extract the value. Of course, the given application might not know anything about animals, much less what legs are. The standard structure defined by OLE for property sets is generic with respect to the semantics of the properties being represented; it says nothing about what they mean.
Each property set can have a dictionary associated with it. This dictionary provides a human-readable name for each of the property IDs that define the set. An application can read the dictionary of a property set and allow the user to pick and choose using informative names.
In order to better illustrate what property sets are, several examples are in order. The first example shows how property sets can be stored within files to allow common access to the information represented by the property set. The second example shows how property sets can be transferred, or communicated, between applications or OLE objects.
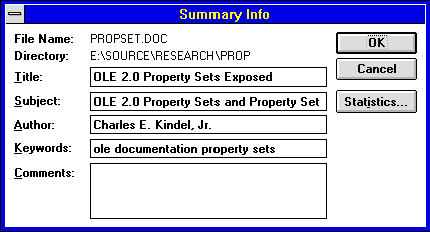
One of the simplest and most commonly used property sets is the Summary Information property set. Most documents that are created by applications have a common set of attributes that are useful to users of those documents. These attributes include the author of the document, the subject of the document, when it was created, and so on. In the Microsoft Windows® 3.1 world, each application has a different way of storing this information within its documents. In order for a user to examine the summary information for a given document, it is necessary to run the application that created the document, open it, and invoke the application's Summary Information dialog box. The Summary Information dialog boxes that Microsoft Word 2.0 displayed for this document are shown below (Figures 1 and 2).
Figure 1. Word for Windows 2.0 Summary Info dialog box
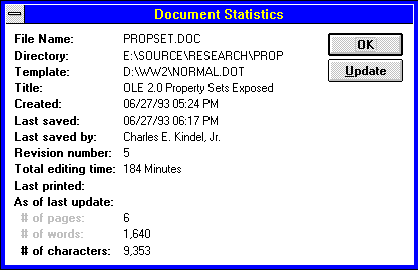
Figure 2. Word for Windows Document Statistics dialog box
Unfortunately, no application but Word for Windows 2.0 is going to be able to display the summary information for this document because Word 2.0 used a proprietary file format. Wouldn't it be great if any application could display the summary information stored in any document? Wouldn't it be neat if you could choose the File Properties menu item in the Windows File Manager and have it display the document summary information similar to that shown above for any file?
Newer versions of Microsoft Word and many other OLE-enabled applications now save their documents using OLE structured storage, and store document summary information using the standard described here. The Windows 95 shell is able to display the summary information property set for any file, as long as that file is an OLE structured storage file, and the creating application saved the information in the OLE property set format. Right-click on any Word 6.0 document in the Windows 95 shell, and choose "Properties...". You'll see a property sheet that looks like this (Figure 3):
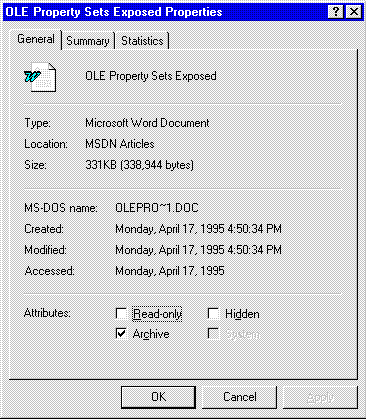
Figure 3. The Windows 95 File property sheet
If you click on the Summary tab, the Windows 95 Summary Information property page is displayed (Figure 4). It shows the values of the properties for the document by opening the file and reading the summary information property set stream.
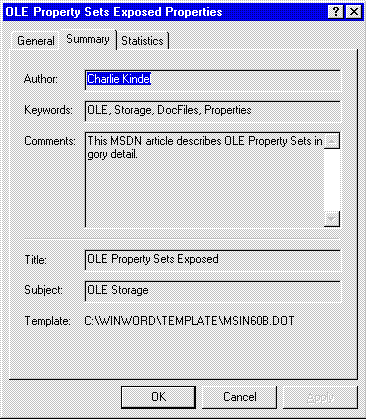
Figure 4. The Windows 95 Summary Information property page
The Document Summary Information Property Set ("\005SummaryInformation") is the only property set actually proposed in the OLE specification (see the "Document Summary Information Property Set" topic in the Win32® SDK).
Microsoft Office for Windows 95 introduced a second standard property set, called the "DocumentSummaryInformation" property set ("\005DocumentSummaryInformation"—a poor choice of names, considering how easily it is confused with the one above). This set can be thought of as an extension to the original SummaryInformation property set. The applications in Office 95 include a property page for viewing the DocumentSummaryInformation property set. (See the Microsoft Office Software Development Kit for more details on the DocumentSummaryInformation property set.)
Storing information about what is contained inside a document is handy, and having a standard that allows all files to share the same information with all applications is even nicer. But SummaryInfo is only one example of how property sets can be used.
Another use for property sets is in the transfer of data between OLE objects, or even applications. To illustrate this, we'll use an example from the Securities Industry (no, not security like alarms and dogs, but securities like stocks and bonds).
Traders on Wall Street rely on large amounts of data, such as stock quotes and news stories, to make decisions regarding trades of securities. This data is referred to as market data and is delivered to traders' workstations in real time (or at least very soon after the data was generated). In this example, we are talking about transferring real time market data between two OLE objects.
In this example we will ignore all securities except stocks, and we'll even simplify the model that Wall Street traders really use. . . after all, it's just an illustration.
Let's assume that at any given time during an open day on Wall Street, we are interested in the opening, high, low, current, and last closing price of an instrument (a specific stock), and the volume that the stock has traded so far that day. The other piece of information we are interested in is the ticker symbol for the stock. Thus we have the following data items:
| Item | Meaning |
| SYMBOL | The ticker symbol for the instrument we are interested in (for example, "MSFT"). |
| OPEN | The price the instrument opened on (assume every instrument opens every working day). |
| CLOSE | The price of the instrument when the market last closed. |
| HIGH | The highest price of the instrument since it opened. |
| LOW | The lowest price of the instrument since it opened. |
| LAST | The last or current price of the instrument. |
| VOLUME | The number of shares of this instrument that have traded so far. |
Let's assume that the trader wants to watch the above values for four different stocks during the day. That is, he or she wants his/her trading application to receive updates for these four stocks as their values change. For the sake of this example, we'll choose MSFT, IBM, AAPL, and BORL as the four stocks our trader wants to keep an eye on.
Assume that the trader has installed on his/her workstation some sort of server that gets real time market data off the network and provides services to other applications on the system for accessing that data. Call this server application the Data Server. Also assume that the trader has on his/her workstation a "Trader's Application" that allows him or her to choose instruments to monitor and to make trades. This application communicates with the Data Server in some way to get the appropriate data updates.
Without thinking about how the data is transferred between the Data Server and the Trader's Application, we can still think about what data is transferred and what format the data is in. Assume that the what is answered by the above table, and that the format is property sets.
Recall that a property in a property set has three attributes: the property identifier, a value type indicator, and a value. For this example we can define the following properties:
The FormatID_StockQuote Property Set Definition
| Property Identifier | Type Indicator | Value |
| PID_SYMBOL | VT_LPSTR | Zero-terminated string |
| PID_OPEN | VT_CY | Currency value |
| PID_CLOSE | VT_CY | Currency value |
| PID_HIGH | VT_CY | Currency value |
| PID_LOW | VT_CY | Currency value |
| PID_LAST | VT_CY | Currency value |
| PID_VOLUME | VT_I4 | 32-bit unsigned integer |
Every property set must have a Format Identifier associated with it. The Format ID identifies the class of objects that know the meaning of the properties in the set. Let's call this set FormatID_StockQuote and refer to it from here on as the StockQuote property set.
A single data element representing the stock of IBM during the day might look like this:
| PID_SYMBOL | contains "IBM" |
| PID_OPEN | contains 42 3/4 |
| PID_CLOSE | contains 42 3/4 |
| PID_HIGH | contains 49 1/8 |
| PID_LOW | contains 40 7/8 |
| PID_LAST | contains 47 3/8 |
| PID_VOLUME | contains 123,032 |
During a trading day on Wall Street only a few of the properties of a single instrument change. For example, the opening price doesn't change all day, and the low price may go unchanged for several hours. Using property sets as the data transfer format allows us to transfer only the data that has changed. For example, at some point during the day the Data Server may update the Trader's Application by transferring the following StockQuote property set:
| PID_SYMBOL | contains "IBM" |
| PID_HIGH | contains 49 1/8 |
| PID_LAST | contains 49 1/8 |
| PID_VOLUME | contains 23,321 |
This example demonstrates how property sets can be used as a data transfer format, allowing sparse data representation. By transferring only the changed data, the overall performance of the trader's workstation is enhanced. As you can imagine, using property sets as a data transfer format has many advantages beyond this example.
Another use of OLE persistent property sets, one that you will see a lot of in the future version of Windows NT™ (code-named "Cairo"), is to tag just about any object in the system with properties. Just as a word processor document can be tagged with a Summary Information property set containing properties such as "Author", a printer object could have a "Location" property. Another example would be a "User" object, which might have properties with names like "First Name", "Last Name", and "Office Number".
Such pervasive use of property sets allows for very powerful querying capabilities. For example a user of Cairo will be able to essentially tell the system, "Find all printers in my building that understand PostScript™, have more than 4 MB of RAM, and have a full paper bin."
It is important to note that the OLE designers intended that property sets be used to store data suited to representation as a collection of fine-grained values. The assumption was that the entire stream containing the property set would be read and/or written as a whole. Data sets that are too large for this to be feasible should be broken into separate streams and/or storages, which can be transacted, and so forth. It was not the intention of the OLE designers to provide a substitute for a database of millions of tiny objects.
OLE defines property sets; it does not provide any code or interfaces to manipulate them (although, as mentioned above, future Microsoft operating systems may include interfaces to manipulate property sets). This section describes the OLE persistent property set specification in detail.
The OLE 2.0 specification defines a standard serialized format for property sets. This format has the following characteristics:
Figure 5 shows the overall structure of the format.

Figure 5. Serialized format for property sets
All data elements are stored in the Intel® representation (little endian).
The overall length of this property set stream is limited to 256K bytes.
Names in an IStorage that begin with the value '\0x05' are reserved exclusively for the storage of property sets. Streams or storages that begin with '\0x05' must therefore be in the format described below; storages so named must contain a "Contents" stream in the format. One of the things the inventor of a new standard property set does is specify the standard string name under which instances of that type are stored. For example, the summary information property set defined by OLE is always found under the name "\005SummaryInformation". The original OLE 2.0 specification provided no conventions for choosing this name; however, a convention for choosing such names has subsequently been specified and is discussed below. Use of this convention is required to enable the property set interfaces that will appear in future versions of Windows to open the property set.
Given the overall picture of the serialized format in Figure 5, we can discuss the individual components of the format.
Note The OLE 2.0 specification for the serialized property set format allowed for more than one section, but use of that functionality is now discouraged and will not be supported through the property-related interfaces in future versions of Windows.
At the beginning of the property set stream is a header. The following structures illustrate the header:
typedef struct PROPERTYSETHEADER
{
// Header
WORD wByteOrder // Always 0xFFFE
WORD wFormat; // Always 0
WORD dwOSVer; // System version
CLSID clsid; // Application CLSID
DWORD dwReserved; // Should be 1
} PROPERTYSETHEADER;
Following are the definitions of the members of this structure.
| Member | Meaning |
| wByteOrder | The byte-order indicator is a WORD and should always hold the value 0xFFFE. This is the same as the Unicode™ byte-order indicator. When written in little-endian (Intel) Intel byte order, this appears in the file or stream as 0xFe, 0xFF. |
| wFormat | The format version is a WORD and indicates the format version of this stream. Property set writers should write zero for this value. Property set readers should check this value; if it is non-zero, then they should refuse to read the set, for it is in a format that they don't in fact understand. |
| dwOSVer | The OS version number is encoded as OS kind in the high order word (0 for Windows on DOS, 1 for Macintosh, 2 for Windows NT) and the OS-supplied version number in the low order word. For Windows on DOS and Windows NT, the latter is the low order word of the result of GetVersion(). |
| clsid | The class identifier is the CLSID of a class that can display and/or provide programmatic access to the property values. If there is no such class, it is recommended that the Format ID be used (see below), though a value of all zeros is also acceptable; the former simply allows for greater future extensibility. |
| dwReserved | Reserved for future use. A writer of a property set should write the value one here; however , a reader of a property set should only check that the value is at least one. |
2.1.1.1. Originating OS Version
The dwOSVer DWORD should hold the operating system kind in the high WORD and the OS-supplied version number in the low WORD. Possible values for the operating system kind are:
| Operating System Kind | HIWORD of dwOSVer |
| 16-Bit Windows (Win16) | 0x0000 |
| Macintosh® | 0x0001 |
| 32-Bit Windows (Win32) | 0x0002 |
For Windows, the operating system version is the low order word of GetVersion. For example, in Windows the following would correctly set the Originating OS Version:
#ifdef WIN32
dwOSVer = (DWORD)MAKELONG( LOWORD(GetVersion()), 2 ) ;
#else
dwOSVer = (DWORD)MAKELONG( LOWORD(GetVersion()), 0 ) ;
#endif
Note In previous versions of this document, dwReserved was documented as containing the count of sections in the property set. Since that time, the specification has been revised such that only one section is allowed.
Each Format Identifier/Offset pair (FIDO for short) both names and points to a section. The Format ID (FMTID) is represented in the same 16-byte format as OLE GUIDs (and CLSIDs) and uniquely identifies a section. The offset is the distance of bytes from the start of the whole stream to where the section begins. The Format ID is the semantic name of its corresponding section, telling how to interpret the property values therein.
The following structure is helpful in dealing with Format Identifier/Offset pairs:
typedef struct FORMATIDOFFSET
{
FMTID fmtid ; // semantic name of a section
DWORD dwOffset ; // offset from start of whole property set
// stream to the section
} FORMATIDOFFSET;
See the "Format Identifiers" section for more information on Format IDs.
Each section is made of up a property section header followed by an array that locates each property value within the section. Properties in this array are not sorted in any particular order. Offsets within this array are the distance from the start of the section to the start of the property (type, value) pair. This allows entire sections to be copied as an array of bytes without any translation of internal structure.
typedef struct tagPROPERTYSECTIONHEADER
{
DWORD cbSection ; // Size of section
DWORD cProperties ; // Count of properties in section
PROPERTYIDOFFSET rgPropIDOffset[]; // Array of property locations
} PROPERTYSECTIONHEADER
typedef struct PROPERTYIDOFFSET
{
DWORD propid; // name of a property
DWORD dwOffset; // offset from the start of the section to that
// property type/value pair
} PROPERTYIDOFFSET;
The members of this structure are described below.
| Member | Meaning |
| cbSection | This DWORD indicates the size of the section. Having the section size as the first four bytes lets you copy and manipulate entire sections as VT_BLOB values without any translation of internal structure. |
| cProperties | This DWORD gives a count of the property values in the section. |
| rgPropIDOffset | An array of property ID/offset pairs. Property IDs are 32-bit values that uniquely identify a property within a section. The offsets indicate the distance from the start of the section to the start of the property type/value pair. By having the offsets relative to the section, sections can be copied as BLOBs. |
Each property value contains a type tag followed by the bytes of the actual property value. The tag indicates the type of the property. All type/value pairs begin on a 32-bit boundary. Thus values may be followed with null bytes to align the subsequent pair on a 32-bit boundary (note though that there is no guarantee that property values are in fact as tightly packed in a section as this restriction permits; that is, there may be additional gratuitous padding).
typedef struct SERIALIZEDPROPERTYVALUE
{
DWORD dwType; // type tag
BYTE rgb[]; // the actual property value
} SERIALIZEDPROPERTYVALUE;
A consequence of these rules is that the smallest legal section, one containing zero properties, contains the following eight bytes: 08 00 00 00 00 00 00 00.
As was mentioned above, all type/value pairs begin on a 32-bit boundary. It follows that in turn, the type indicators and values of a type value pair are so aligned. This means that values may be necessarily followed by null bytes to align a subsequent type/value pair.
However, within a vector of values, each repetition of a value is to be aligned with its natural alignment rather than with 32-bit alignment. In practice, this is only significant for types VT_UI1, VT_I2, VT_UI2, and VT_BOOL (which have 2-byte natural alignment); all other types have 4-byte natural alignment. Therefore, a value with type tag VT_I2 | VT_VECTOR would be a DWORD element count, followed by a sequence of packed 2-byte integers with no padding between them; whereas a value of with type tag VT_LPSTR | VT_VECTOR would be a DWORD element count, followed by a sequence of (DWORD cch, char rgch[]) strings, each of which may be followed by null padding to round to a 32-bit boundary.
Property identifiers are unsigned 32-bit values that uniquely identify a given property within a property set. As a designer of property sets, you can use any property ID with a value between 0x00000001 and 0x80000000, noninclusive. Properties with IDs of 0x00000000 and 0x00000001 are used for a dictionary of human-readable property names and a code page indicator, respectively. Property IDs with the high bit set (that is, greater than 0x80000000) are reserved for future use by Microsoft.
2.1.5.1. Property ID Zero: Property Set Dictionary
To enable users of property sets to attach meaning to properties beyond those provided by the type indicator, property ID zero is reserved in all property sets for an optional dictionary giving human-readable names for the properties in the set and for the property set itself. The value is an array of (property ID, string) pairs.
The value of property ID zero is an array of property ID/string pairs. Entries in the array are the IDs and corresponding names of the properties; these are not in any particular order with respect to their property IDs. Not all of the names of the properties in the set need appear in the dictionary: The dictionary may omit entries for properties that are assumed to be universally known by clients that manipulate the property set. Typically, names for the base property sets for widely accepted standards will be omitted.
Property names that begin with the binary Unicode characters 0x0001 through 0x001F are reserved for future use.
The name indicated as corresponding to property ID zero is to be interpreted as the human-readable name of the property set itself; like all property names, this may or may not be present.
The dictionary is stored as a list of property ID/string pairs; the code page for the strings involved is as indicated in property ID one. This can be illustrated using the following pseudo-structure definition for a dictionary entry (it is a pseudo-structure because the sz[] member is variable size):
typedef struct tagENTRY {
DWORD propid; // Property ID
DWORD cb; // Count of bytes in the string, including the null
// at the end.
char sz[cb]; // Zero-terminated string. Code page as indicated
// by property ID one.
} ENTRY;
typedef struct tagDICTIONARY {
DWORD cEntries; // Count of entries in the list.
ENTRY rgEntry[cEntries];
} DICTIONARY;
Note the following:
The following example may be useful to help illustrate the dictionary format:
The property set described in the second example in the introduction of this paper (real time stock market data transfer example) might have a human-readable name of "Stock Quote" for the entire set and "Ticker Symbol" for PID_SYMBOL (#define PID_SYMBOL 7). If a property set contained just a symbol ("MSFT") and the dictionary, the property set section would have a byte stream that looked like the following:
Offset Bytes
; Start of section
0000 43 01 00 00 ; DWORD size of section
0004 04 00 00 00 ; DWORD number of properties in section
; Start of PropID/Offset pairs
0008 00 00 00 00 ; DWORD Property ID (0 == dictionary)
000C 20 00 00 00 ; DWORD offset to property ID
0010 01 00 00 00 ; DWORD Property ID (1 == code page)
0014 00 00 00 00 ; DWORD offset to property ID
0018 07 00 00 00 ; DWORD Property ID (i.e. PID_SYMBOL)
001C 00 00 00 00 ; DWORD offset to property ID
; Start of Property 0 (which is really the dictionary
0020 08 00 00 00 ; DWORD Number of entries in dictionary
; (Note: No type indicator!)
0024 00 00 00 00 ; DWORD dwPropID = 0
0028 18 00 00 00 ; DWORD cb = (wstrlen("Stock Quote")+1)
; * sizeof(WCHAR) == 24
002C L"Stock Quote\0" ; char sz[24]
0044 03 00 00 00 ; DWORD dwPropID = 3 (PID_SYMBOL)
0048 1C 00 00 00 ; DWORD cb = (wstrlen("Ticker
; Symbol")+1) * sizeof(WCHAR) == 28
003C L"Ticker Symbol\0" ; char sz[28]
... ; dictionary would continue, but may not contain entries for
; every possible entry. Also, entries do not need to be in order
; (except dwPropID == 0 must be first).
; Start of Property 1 (code page indicator)
00D0 02 00 00 00 ; DWORD type indicator (VT_I2)
00D4 B0 04 00 00 ; USHORT codepage (0x04B0 == 1200 == Unicode)
; Start of Property 7 (PID_SYMBOL)
0134 1E 00 00 00 ; DWORD type indicator (VT_LPWSTR == 1F)
0138 10 00 00 00 ; DWORD count of bytes
013C L"MSFT\0" ; WCHAR sz[5] (+ 2 bytes for the NULL)
2.1.5.2. Property ID Ox00000001: Code Page Indicator
Property ID one (0x00000001) is reserved as an indicator of which code page or script any not-always-Unicode strings in the property set originated from (code pages are used in Windows and scripts are from the Macintosh world). All such string values in the entire property set, such as VT_LPSTRs, VT_BSTRs, and the names in the property name dictionary found in property ID zero, use characters from this one code page. If the code page indicator is not present, the prevailing code page on the reader's machine must be assumed (use the Win32 API GetACP to determine the current code page). If an application cannot understand the indicated code page, it should not try to modify strings stored in the property set.
When an application that is not the author of a property set changes a property of type string in the set, it should examine the code page indicator and take one of the following courses of action:
Possible values for the code page indicator are given in the Win32 API reference (see the NLSAPI functions, and specifically the GetACP function) and Inside Macintosh Volume VI, §14-111. For example, the code page US ANSI is represented by 0x04e4 (or 1252 in decimal); the code page for Unicode is 1200. Whether a Windows code page or a Macintosh script is found in property ID one is determined by the "originating OS version" (PROPERTYSETHEADER::dwOSVer) of the property set as a whole. Note that Windows code page equivalents exist for the Macintosh scripts numbers (Windows code page 10000, for example, is the Macintosh Roman script).
It is strongly recommended that the Unicode code page (1200) be used. This is the only practical way to achieve worldwide interoperable property sets. In code page 1200, note especially that the count at the start of a VT_LPSTR or VT_BSTR is to be interpreted as a byte count, not a character count. The byte count includes the two zero bytes at the end of the string.
Property ID one is of type VT_I2, and therefore consists of a DWORD containing VT_I2 followed by a USHORT indicating the code page. For example, the type/value pair for property ID one representing the US ANSI code page is the following six bytes:
02 00 00 00 e4 04
plus any necessary padding.
2.1.5.3. Property ID 0x80000000: Locale Indicator
Property ID 0x80000000 (PID_LOCALE) is reserved as an indication of which locale the property set was written in. The default locale for a property set, in the event that PID_LOCALE does not exist in the property set, will be the system's default locale (LOCALE_SYSTEM_DEFAULT).
Applications can choose to support the locale or accept the default behavior. Applications that allow users to specify a working locale should write that locale identifier to this property. Applications that use the user's default locale (LOCALE_USER_DEFAULT) should write the user's default locale identifier.
Applications should be concerned with the possibility of getting information from a property set that is of a different locale than that of the application, the user, or the system (that is, a foreign object).
Property ID PID_LOCALE is of type VT_U4, and therefore consists of a DWORD containing VT_U4 followed by a DWORD containing the Locale Identifier (LCID) as defined by Appendix C of the Win32 SDK.
A property pair (type, value) is a DWORD type indicator, followed by a value whose representation depends on the type. The serialized representations of each of the different types of values are as follows:
| Type indicator | Value Representation |
| VT_EMPTY | No bytes. |
| VT_NULL | No bytes. |
| VT_I2 | 2-byte signed integer. |
| VT_I4 | 4-byte signed integer. |
| VT_R4 | 32-bit IEEE floating-point value. |
| VT_R8 | 64-bit IEEE floating point value. |
| VT_CY | 8-byte two's complement integer (scaled by 10,000). |
| VT_DATE | A 64-bit floating-point number representing the number of days (not seconds) since December 31, 1899. (That is, January 1, 1900, is 2.0, January 2, 1900, is 3.0, and so on.) This is stored in the same representation as VT_R8. |
| VT_BSTR | Counted, null terminated binary string; represented as a DWORD byte count of the number of bytes in the string (including the terminating null) followed by the bytes of the string. Character set is as indicated by the code page indicator. |
| VT_ERROR | A DWORD containing a status code. |
| VT_BOOL | A Boolean (WORD) value containing 0 (false) or -1 (true). |
| VT_VARIANT | A type indicator (a DWORD) followed by the corresponding value. VT_VARIANT is only used in conjunction with VT_VECTOR: see below. |
| VT_UI1 | 1-byte unsigned integer. |
| VT_UI2 | 2-byte unsigned integer. |
| VT_UI4 | 4-byte unsigned integer. |
| VT_I8 | 8-byte signed integer. |
| VT_UI8 | 8-byte unsigned integer. |
| VT_LPSTR | This is the representation of many strings. It is stored in the same representation as VT_BSTR. Note that the serialized representation of VT_LPSTR has a preceding byte count, whereas the in-memory representation does not. Character set is as indicated by the code page indicator. |
| VT_LPWSTR | A counted and null terminated Unicode string; a DWORD character count (where the count includes the terminating null) followed by that many Unicode (16-bit) characters. Note that the count is a character count, not a byte count. |
| VT_FILETIME | 64-bit FILETIME structure, as defined by Win32. |
| VT_BLOB | A DWORD count of bytes, followed by that many bytes of data. The byte count does not include the four bytes for the length of the count itself: An empty blob would have a count of zero, followed by zero bytes. Thus, the serialized representation of a VT_BLOB is similar to that of a VT_BSTR but does not guarantee a null byte at the end of the data. |
| VT_STREAM | Indicates the value is stored in a stream that is sibling to the CONTENTS stream. Following this type indicator is data in the format of a serialized VT_LPSTR, which names the stream containing the data. |
| VT_STORAGE | Indicates the value is stored in an IStorage that is sibling to the "CONTENTS" stream. Following this type indicator is data in the format of a serialized VT_LPSTR, which names the IStorage containing the data. |
| VT_STREAMED_OBJECT | Same as VT_STREAM, but indicates that the stream contains a serialized object, which is a class ID followed by initialization data for the class. |
| VT_STORED_OBJECT | Same as VT_STORAGE, but indicates that the designated IStorage contains a loadable object. |
| VT_BLOB_OBJECT | A BLOB containing a serialized object in the same representation as would appear in a VT_STREAMED_OBJECT. That is, following the VT_BLOB_OBJECT tag is a DWORD byte count of the remaining data (where the byte count does not include the size of itself) which is in the format of a class ID followed by initialization data for that class. The only significant difference between VT_BLOB_OBJECT and VT_STREAMED_OBJECT is that the former does not have the system-level storage overhead that the latter would have, and is therefore more suitable for scenarios involving numbers of small objects. |
| VT_CF | A BLOB containing a clipboard format identifier followed by the data in that format. That is, following the VT_CF tag is data in the format of a VT_BLOB: a DWORD count of bytes, followed by that many bytes of data in the format of a packed VTCFREP (described just below), followed immediately by an array of bytes as appropriate for data in the clipboard format format (text, metafile, or whatever). |
| VT_CLSID | A class ID (or other GUID). |
| VT_VECTOR | If the type indicator is one of the above values with this bit on in addition, the value is a DWORD count of elements, followed by that many repetitions of the value. For example, a type indicator of VT_LPSTR | |VT_VECTOR has a DWORD element count, a DWORD byte count, the first string data, a DWORD byte count, the second string data, and so on. |
Clipboard format identifiers, stored with the tag VT_CF, use one of five different representations:
typedef struct VTCFREP {
LONG lTag;
BYTE rgb[];
} VTCFREP;
The values for RGB are determined by the different values for lTag:
| lTag Value | RGB Value |
| -1L | A DWORD containing a built-in Windows clipboard format value. |
| -2L | A DWORD containing a Macintosh clipboard format value. |
| -3L | A GUID containing a format identifier (seldom used). |
| Any positive value | A null-terminated string containing a Windows clipboard format name, one suitable for passing to RegisterClipboardFormat. The code page used for characters in the string is per the code page indicator. The "positive value" here is the length of the string, including the null byte at the end. |
| 0L | No data (rarely used). |
All type/value pairs begin on a 32-bit boundary. Thus values may be followed with null bytes to align the subsequent pair on a 32-bit boundary. Given a count of bytes, the following code will calculate how many bytes are needed to align on a 32-bit boundary:
cbAdd = (((cbCurrent + 3) >> 2) << 2) - cbCurrent ;
2.1.6.1. Defining New Types
There is no provision for adding new type indicators to the list above. Property sets are designed to be partially self-describing, such that code that does not know all about the property set can at least tell the types of values contained in it. If new VT tags were allowed to be defined, it would be impossible for code to skip over values that are not understood. However, new types can be defined by using the VT_VARIANT type combined with the VT_VECTOR flag. For example, assume you wanted to store the following packed structure in a property set:
typedef struct tagPACKED
{
DWORD dwValue1 ; // 32 bit value
WORD wFlag ; // 16 bits of flags
WORD wValue2 ; // 16 bit value
} PACKED ;
This 64 bit structure could be stored using VT_VARIANT | VT_VECTOR as follows:
DWORD // dwTypeIndicator = VT_VARIANT | VT_VECTOR ;
DWORD // dwElementCount = 3 ;
DWORD // dwTypeIndicator = VT_I4 ;
DWORD // dwValue1 ;
DWORD // dwTypeIndicator = VT_I2 ;
WORD // wFlag ;
DWORD // dwTypeIndicator = VT_I2 ;
WORD // wValue2 ;
OLE 2.0 provides standard facilities for storing documents to the file system (OLE 2.0 Structured Storage). The interfaces for doing this are IStorage, IStream, and so on. It is logical (and useful) for property sets to be stored in documents, and OLE 2.0 specifies how they should be stored so that other applications can find and manipulate the information.
If the property set you are storing is internal to your application, you may not want to adhere to the rules described here. On the other hand, if you want to expose your property set to other applications, you need to follow these rules:
Persistent property sets are named within the format with Format IDs (FMTID); but in an IStorage or IStream, they are named using strings with a maximum length of 32 characters. In addition, all OLE persistent property sets stored in a stream or storage must have "\005" as the first character of the stream or storage name. A normal "string-ized" version of an FMTID contains 38 characters (for example, "{F29F85E0-4FF9-1068-AB91-08002B27B3D9}"). How can we squeeze this down to fit in the space legally allowed for IStorage and IStream names?
The first task is to establish a mapping between FMTIDs and strings. Converting in one direction, we have in hand an FMTID, and need a corresponding string name. First, we check whether the FMTID is one of a fixed set of well-known values, and use the corresponding well-known string name (from the following table) if so. (The first FMTID was defined as part of OLE2; the second one was defined by Microsoft Office.)
| FMTID | String Name | Semantic |
| F29F85E0-4FF9-1068-AB91-08002B27B3D9 | \005SummaryInformation | OLE2 summary information |
| D5CDD502-2E9C-101B-9397-08002B2CF9AE | \005DocumentSummaryInformation | Office 95 document summary information |
Otherwise, we algorithmically form a string name as follows: First, convert the FMTID to little-endian byte order if necessary. Then take the FMTID and consider it as one long bit string (128 bits) by concatenating each of the bytes together. The first bit of the 128-bit value is the most significant bit of the first byte in memory of the FMTID; the last bit of the 128-bit value is the least significant bit of the last byte in memory of the FMTID. Extend these 128 bits to 130 bits by adding two zero bits to the end. Next, chop the 130 bits into groups of 5 bits; there will be 26 such groups. Consider each group as an integer, and map it as an index into the array of 32 characters:
ABCDEFGHIJKLMNOPQRSTUVWXYZ012345
This yields a sequence of 26 Unicode characters that uses only uppercase characters and numerals. Note that no two characters in this range compare equally in a case-insensitive manner in any locale. The final string is the concatenation of the string "\005" with these 26 characters, for a total length of 27 characters.
The name-to-FMTID mapping is the obvious inverse of the above. However, converters of property string names to GUIDs should accept lowercase letters as synonymous with their uppercase counterparts.
For example, assume there is a class of applications that edit information about animals (such as a database of all pets in a city). We define a class ID (CLSID_AnimalApp = {43D67B39-E3BA-11ce-9050-080036F12502}) for this set of applications so they can indicate that they understand property sets containing animal information (FormatID_AnimalInfo = {43D67B3A-E3BA-11ce-9050-080036F12502}) and property sets containing medical information (FormatID_MedicalInfo = {43D67B3B-E3BA-11ce-9050-080036F12502}). One possible way of storing the information about a specific animal (in this case, my dog, Revo) is given below. This implementation stores the animal information property set in an IStream:
IStorage (File): "C:\OLE\REVO.DOC" CLSID = CLSID_AnimalApp
// AnimalInfo
IStream: "\0050z4m3bjxDxtdbickIaamtyxeCa"
WORD dwByteOrder, WORD wFmtVersion, DWORD dwOSVer,
CLSID CLSID_AnimalApp, DWORD cSections...
...
FormatID = FormatID_AnimalInfo
Property: ID = PID_ANIMALTYPE, Type = VT_LPSTR, Value = "Dog"
Property: ID = PID_ANIMALNAME, Type = VT_LPSTR, Value = "Revo"
Property: ID = PID_MEDICALHISTORY, Type = VT_STREAM,
Value = "\005MedicalInfo"
...
// MedicalInfo
IStream: "\0051z4m3bjxDxtdbickIaamtyxeCa"
WORD dwByteOrder, WORD wFmtVersion, DWORD dwOSVer,
CLSID CLSID_AnimalApp, DWORD cSections...
...
FormatID = CLSID_MedicalInfo
Property: ID = PID_VETNAME, Type = VT_LPSTR, Value = "Dr. Woof"
Property: ID = PID_LASTEXAM, Type = VT_DATE, Value = ...
...
...
Note that the class IDs of the IStorage and both property sets is CLSID_AnimalApp. CLSID_AnimalApp identifies any application that can display and/or provide programmatic access to these property sets. Any application can read the information within the property sets (which is the point of property sets), but only applications identified with the class ID of CLSID_AnimalApp can understand the meaning of the data in the property sets.
Applications should be written to expect that a property set may be stored in either an IStorage or IStream, unless the property set definition indicates otherwise. For example, the SummaryInformation property set has in its definition that it can only be stored in a named IStream. In the cases where you are searching for a property set, and you do not know whether it is in a storage or stream, it is suggested that you look for an IStream with your property set name first; then, if that fails, look for an IStorage.
The sample application below is a console application that can convert an FMTID to a property set name and vice versa.
// THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF
// ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO
// THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A
// PARTICULAR PURPOSE.
//
// Copyright 1993 - 1995 Microsoft Corporation. All Rights Reserved.
//
// MODULE: propsetname.cpp
//
// PURPOSE: Convert between OLE persistent property set names and
// Format IDs (FMTIDs).
//
// FUNCTIONS:
//
// COMMENTS:
// Comply with "cl propsetname.cpp /link ole32.lib"
//
//
#define _INC_OLE
#include <windows.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define CBIT_CHARMASK 5
#define CBIT_BYTE 8
#define CBIT_GUID (CBIT_BYTE * sizeof(GUID))
#define CWC_PROPSET (1 + (CBIT_GUID + CBIT_CHARMASK-1)/CBIT_CHARMASK)
#define WC_PROPSET0 ((WCHAR) 0x0005)
#define CCH_MAP (1 << CBIT_CHARMASK) // 32
#define CHARMASK (CCH_MAP - 1) // 0x1f
CHAR awcMap[CCH_MAP + 1] = "abcdefghijklmnopqrstuvwxyz012345";
#define CALPHACHARS ('z' - 'a' + 1)
GUID guidSummary =
{ 0xf29f85e0,
0x4ff9, 0x1068,
{ 0xab, 0x91, 0x08, 0x00, 0x2b, 0x27, 0xb3, 0xd9 } };
WCHAR wszSummary[] = L"SummaryInformation";
GUID guidDocumentSummary =
{ 0xd5cdd502,
0x2e9c, 0x101b,
{ 0x93, 0x97, 0x08, 0x00, 0x2b, 0x2c, 0xf9, 0xae } };
WCHAR wszDocumentSummary[] = L"DocumentSummaryInformation";
__inline WCHAR
MapChar(IN ULONG i)
{
return((WCHAR) awcMap[i & CHARMASK]);
}
//+--------------------------------------------------------------------------
// Function: GuidToPropertySetName
//
// Synopsis: Map property set GUID to null-terminated UNICODE name string.
//
// The awcname parameter is assumed to be a buffer with room for
// CWC_PROPSETSZ (28) UNICODE characters. The first character
// is always WC_PROPSET0 (0x05), as specified by the OLE Appendix
// B documentation. The colon character normally used as an NT
// stream name separator is not written to the caller's buffer.
//
// No error is possible.
//
// Arguments: IN GUID *pguid -- pointer to GUID to convert
// OUT WCHAR awcname[] -- output string buffer
//
// Returns: count of non-NULL characters in the output string buffer
//---------------------------------------------------------------------------
ULONG GuidToPropertySetName( IN GUID const *pguid, OUT WCHAR awcname[])
{
BYTE *pb = (BYTE *) pguid;
BYTE *pbEnd = pb + sizeof(*pguid);
ULONG cbitRemain = CBIT_BYTE;
WCHAR *pwc = awcname;
*pwc++ = WC_PROPSET0;
// Note: CWC_PROPSET includes the WC_PROPSET0, and sizeof(wsz...)
// includes the trailing L'\0', so sizeof(wsz...) is OK because the
// WC_PROPSET0 character compensates for the trailing NULL character.
//ASSERT(CWC_PROPSET >= sizeof(wszSummary)/sizeof(WCHAR));
if (*pguid == guidSummary)
{
RtlCopyMemory(pwc, wszSummary, sizeof(wszSummary));
return(sizeof(wszSummary)/sizeof(WCHAR));
}
//ASSERT(CWC_PROPSET >= sizeof(wszDocumentSummary)/sizeof(WCHAR));
if (*pguid == guidDocumentSummary)
{
RtlCopyMemory(pwc, wszDocumentSummary, sizeof(wszDocumentSummary));
return(sizeof(wszDocumentSummary)/sizeof(WCHAR));
}
while (pb < pbEnd)
{
ULONG i = *pb >> (CBIT_BYTE - cbitRemain);
if (cbitRemain >= CBIT_CHARMASK)
{
*pwc = MapChar(i);
if (cbitRemain == CBIT_BYTE && *pwc >= L'a' && *pwc <= L'z')
{
*pwc += (WCHAR) (L'A' - L'a');
}
pwc++;
cbitRemain -= CBIT_CHARMASK;
if (cbitRemain == 0)
{
pb++;
cbitRemain = CBIT_BYTE;
}
}
else
{
if (++pb < pbEnd)
{
i |= *pb << cbitRemain;
}
*pwc++ = MapChar(i);
cbitRemain += CBIT_BYTE - CBIT_CHARMASK;
}
}
*pwc = L'\0';
return(CWC_PROPSET);
}
//+--------------------------------------------------------------------------
// Function: NtPropertySetNameToGuid
//
// Synopsis: Map non-null-terminated UNICODE string to a property set GUID.
//
// If the name is not properly formed as per
// NtGuidToPropertySetName(), STATUS_INVALID_PARAMETER is
// returned. The pguid parameter is assumed to point to a buffer
// with room for a GUID structure.
//
// Arguments: IN ULONG cwcname -- count of WCHARs in string to convert
// IN WCHAR awcname[] -- input string to convert
// OUT GUID *pguid -- pointer to buffer for converted GUID
//
// Returns: NTSTATUS
//---------------------------------------------------------------------------
HRESULT PropertySetNameToGuid(IN ULONG cwcname,IN WCHAR const awcname[],OUT GUID *pguid)
{
HRESULT Status = E_INVALIDARG;
WCHAR const *pwc = awcname;
if (pwc[0] == WC_PROPSET0)
{
// Note: cwcname includes the WC_PROPSET0, and sizeof(wsz...)
// includes the trailing L'\0', but the comparison excludes both
// the leading WC_PROPSET0 and the trailing L'\0'.
if (cwcname == sizeof(wszSummary)/sizeof(WCHAR) &&
wcsnicmp(&pwc[1], wszSummary, cwcname - 1) == 0)
{
*pguid = guidSummary;
return(S_OK);
}
if (cwcname == sizeof(wszDocumentSummary)/sizeof(WCHAR) &&
wcsnicmp(&pwc[1], wszDocumentSummary, cwcname - 1) == 0)
{
*pguid = guidDocumentSummary;
return(S_OK);
}
if (cwcname == CWC_PROPSET)
{
ULONG cbit;
BYTE *pb = (BYTE *) pguid - 1;
RtlZeroMemory(pguid, sizeof(*pguid));
for (cbit = 0; cbit < CBIT_GUID; cbit += CBIT_CHARMASK)
{
ULONG cbitUsed = cbit % CBIT_BYTE;
ULONG cbitStored;
WCHAR wc;
if (cbitUsed == 0)
{
pb++;
}
wc = *++pwc - L'A'; // Assume uppercase
if (wc > CALPHACHARS)
{
wc += (WCHAR) (L'A' - L'a'); // Oops, try lowercase
if (wc > CALPHACHARS)
{
wc += L'a' - L'0' + CALPHACHARS; // Must be a digit
if (wc > CHARMASK)
{
goto fail; // Invalid character
}
}
}
*pb |= (BYTE) (wc << cbitUsed);
cbitStored = min(CBIT_BYTE - cbitUsed, CBIT_CHARMASK);
// If the translated bits wouldn't all fit in the current byte
if (cbitStored < CBIT_CHARMASK)
{
wc >>= CBIT_BYTE - cbitUsed;
if (cbit + cbitStored == CBIT_GUID)
{
if (wc != 0)
{
goto fail; // extra bits
}
break;
}
pb++;
*pb |= (BYTE) wc;
}
}
Status = S_OK;
}
}
fail:
return(Status);
}
//---------------------------------------------------------------------------
// Function: Usage
//
// Synopsis: Spits out usage information and exits.
//---------------------------------------------------------------------------
void Usage(char * pszProgramName)
{
fprintf(stderr, "\nUsage: %s [<fmtid> | <propset name>\n", pszProgramName);
fprintf(stderr, " <fmtid> is a FMTID\n");
fprintf(stderr, " (e.g. \"{B8081511-E3BB-11CE-9050-080036F12502}\"\n");
fprintf(stderr, " <propset name> is a stringized property set Name\n");
fprintf(stderr, " (e.g. \"\\005Rifqa2oxDxtdbickIaamtyxeCa\"\n");
exit(1);
}
//---------------------------------------------------------------------------
// Function: main
//
// Synopsis: main entry point.
//---------------------------------------------------------------------------
void main(int argc, char **argv)
{
WCHAR wcsFmtID[39] ;
GUID fmtid ;
char szOutput[39] ;
strcpy(szOutput, "<error!>") ;
if (argc < 2)
Usage(argv[0]) ;
if (*argv[1] == '{') // Specified a format ID; convert to string name.
{
// Convert to Unicode.
MultiByteToWideChar(CP_ACP, 0, argv[1], -1, wcsFmtID, 39) ;
// Convert to GUID.
if (FAILED(CLSIDFromString(wcsFmtID, &fmtid)))
{
fprintf(stderr, "Could not convert format ID string to a FMTID\n");
Usage(argv[0]) ;
}
WCHAR wcsName[32] ;
GuidToPropertySetName( &fmtid, wcsName);
// Convert back to ANSI.
WideCharToMultiByte(CP_ACP, 0, wcsName, -1, szOutput, 39, NULL, NULL);
// Output.
printf("Stringized name: \\005%s", szOutput+1) ;
}
else // Must be a string-ized name; convert to format ID.
{
char* pStart = argv[1] ;
// Convert "\005" or "\0x05" to '\005'
if (*pStart== '\\')
{
if (*(pStart+1) == '0' && *(pStart+2) == '0' && *(pStart+3) == '5')
pStart = pStart + 3;
else if (*(pStart+1) == '0' && *(pStart+2) == 'x' &&
*(pStart+3) == '0' && *(pStart+4) == '5' )
pStart = pStart + 4;
else
{
fprintf(stderr, "Stringized name is invalid.\n");
Usage(argv[0]) ;
}
*pStart = '\005' ;
}
if (*pStart != '\005')
{
fprintf(stderr, "Stringized name must begin with '\\005'.\n");
Usage(argv[0]) ;
}
ULONG cwcname = (ULONG)MultiByteToWideChar(CP_ACP, 0, pStart, -1, NULL, 0) ;
if (cwcname == 0)
{
fprintf(stderr, "Invalid input string.\n");
Usage(argv[0]) ;
}
WCHAR* pwcsName = (WCHAR*)malloc(cwcname * sizeof(WCHAR));
MultiByteToWideChar(CP_ACP, 0, pStart, -1, pwcsName, cwcname) ;
HRESULT hr = PropertySetNameToGuid(CWC_PROPSET, pwcsName, &fmtid) ;
free(pwcsName) ;
if (FAILED(hr))
{
fprintf(stderr, "Could not convert name to FMTID.\n");
Usage(argv[0]);
}
if (FAILED(StringFromGUID2(fmtid, wcsFmtID, 39)))
{
fprintf(stderr, "String to GUID conversion failed.\n");
Usage(argv[0]);
}
// Convert wcsFmtID back to ANSI.
WideCharToMultiByte(CP_ACP, 0, wcsFmtID, -1, szOutput, 39, NULL, NULL);
// Output.
printf("Format ID: %s", szOutput) ;
}
}
// Eof