Sten and Per Sundblad
Microsoft Regional Directors, Sweden
From Regional Director Magazine
July 1997
Imagine that you have been selected to help develop a Microsoft® Visual Basic®, Transaction Server, and Microsoft SQL Server™ application. The main purpose of the application is to help Scandinavian racing gamblers to make better bets.
Your job is to design efficient business services for at least some of the classes of this application.
One of the main requirements for the application is that it be scalable. It should be able to support some tens of internal users, working from the office of the racing association owning the application. This is easy. It should also be able to support thousands of simultaneous gamblers accessing part of the application over the Internet. This is not so easy.
All this scalability business is of special importance to you, because you will be at least partly responsible for the design of several so-called "business services."
One of your colleagues has already done an analysis. A result of that is Figure 1, picturing an architectural overview of the application. The diagram is created with the help of Microsoft Visual Modeler.
Figure 1
The architecture, in accordance with the services model, divides this application into three general parts:
The analysis documentation explains this overview as follows:
The User Services tier divides the application into three parts, or logical packages (Figure 2). Note that these packages are logical model packages, not the kind of physical packages you work with in Microsoft Transaction Server. Sometimes they will be the same, but in many cases they will not.
Figure 2
These packages, and the objects within them, are the parts of the system the user will be working with. They are his or her interface to the system. You may see them as three separate graphical user interface (GUI) applications if you wish, one for each of the most important user roles:
This separation of the application's user interface into several logical applications, one for each of the actor or user roles, is often helpful. In this case, the gambler's application will probably be an Internet application, allowing anybody with the right permission to access it. The handicapper's and the administrator's applications will most likely be Intranet or LAN applications, since these user roles probably will be filled by internal people.
A very good idea is to organize small work groups of GUI developers that work closely with users—one group for each of these packages. Of course, there should also be a coordinator who is responsible for the conceptual integrity of the three logical applications. They should, at least in principle, look the same and behave the same, even though each one is developed by a separate group of developers.
In physical design, which happens later, you and your colleagues may decide to divide the user interface differently. This is okay. The first division has still been useful, because it has allowed your group to tackle the user-interface development in an efficient way from the very beginning of the project.
The next tier, the business services tier, has been divided into four different packages. Each package will contain classes belonging to a certain subject area as follows:
Figure 3
To sum it up, the business services tier is divided into four distinct packages. Each one of these packages is a special case of a more general package. In other words, you may use this architecture as a blueprint for many different cases and applications.
Business service objects and methods don't talk to the database directly. They do it through special data services objects—query objects. In fact, business services should ideally not even know if their objects persist in relational databases or in other storage formats.
We plan to store our data persistently in SQL Server databases. The data services tier, then, consists of database query objects. They are available to business services, and in some instances also to user services, to fulfill any need to get information from or save information to the database or the databases. (We have to consider the possibility that an application might use more than one database and more than one database server. After all, we do move toward more and more distributed server environments. This, by the way, is one of the areas where Microsoft Transaction Server may help us a lot.)
The packages in this tier conform well to the packages of the business services tier. This is logical, at least at first. If you later on find a better way to separate the objects from each other, all you have to do is to rearrange them.
Figure 4
As you can see, there are four packages in this tier:
The analysis documentation also contains an initial data model (Figure 5). Somebody has created it using Microsoft Data Tool, which comes with the Enterprise Editions of Visual Basic and Microsoft Visual Studio™. The Figure 5 is not extremely detailed, but it gives you a good overview of the business at hand. It contains "things of real significance for the business," relationships between these things, and for each of them their key column or set of key columns. In other words, it is a strategic data model.
You should note that this is a logical data model, not a physical representation of a database. It may later on be implemented in the fashion of the diagram, but it may also be optimized for the tasks it has to fulfill.
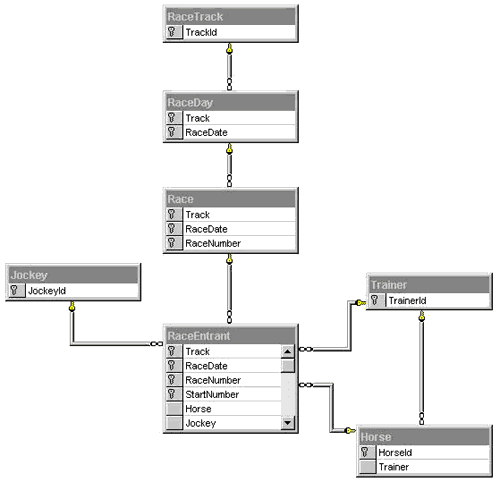
Figure 5
Following the diagram from top to bottom you can see the following information:
Please let me remind you that this is a logical data model, not a physical representation of a database. One of the things you'll have to consider before you turn it into such a representation is the suitability of your key structures. You will probably come to the conclusion that some of the primary key combinations should be exchanged for so-called synthetic keys—keys without real information value. In the model above races are identified by a three column combination, which is moved down to the RaceEntrant table to be part of the four-column key combination for that table. If you replace the Race key with a numeric RaceId you simplify joins as well as selects.
The time for making such decisions is not quite here yet. We just wanted to mention it to avoid misunderstandings of the data model above.
You may regard the data-model diagram (Figure 5) as one way of documenting a set of business rules. The bullets points following the diagram is another. In fact, the diagram should be an implementation of the bullets.
To be precise, the bullets are not business rules in a proper form. Barbara von Halle (Database Programming & Design magazine columnist; she often writes about business rules as an analysis concept) would probably prefer to call them "business ramblings," which are statements about business rules, not yet expressed precisely enough to qualify as real business rules.
The subject of business rules should interest any client/server developer. After all, they should govern most of what you develop for the middle tier of the Services Model. This article, however, is not mainly about business rules. It's more about how to design scalable and efficient Visual Basic applications for Microsoft Transaction Server and SQL Server, given certain sets of business rules.
Your first job is to create an effective and efficient design for the Race Resources business services package. You should start by deciding which objects you should include in your package. Using the data model and talking to your program manager and selected users you come up with a suggestion. You document your suggestion in the Figure 6.
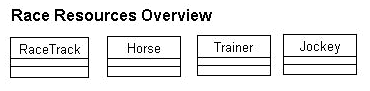
Figure 6
The following are the classes you think should belong in your resource package:
One of the responsibilities of these classes is to hold data about objects for the user interface. A Horse object, for instance, should keep data such as the horse's name, sex, and age for the client application. A proper generic name for this kind of object is data object. At least we think so, and this is what we are going to call them from now on in this article.
Classes of data objects, like those in Figure 6, should handle individual objects only. For set operations you will need separate classes that are capable of returning sets of information to the user interface and of keeping collections of your data classes. You should add these classes to your diagram right now, even though you may not plan to design them until you're through designing the individual classes.
Figure 7 shows how each individual class now has a set-oriented class also. The names of the new classes are the same as those of its corresponding individual class, only with a plural s attached to them. This is to indicate that their purpose is to handle set-oriented issues rather than individual ones.
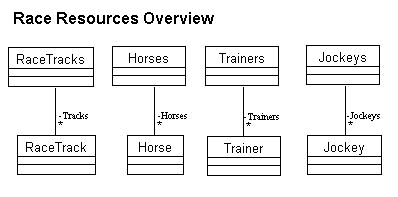
Figure 7
The new classes are associated with the individual classes so that each set-oriented object is associated with zero, one, or several individual objects of the corresponding class. This is what the star at the side of the association line in the diagram tells you. Each association also has a name.
The information in Figure 7 represents business rules as follows:
Let's start our design efforts by focusing on the individual classes and their responsibilities. Later we can come back to the collection classes.
Resource classes, like the ones in Figure 7, have many things in common, as Figure 8 shows. Each of these classes should publish methods that allow their clients to:
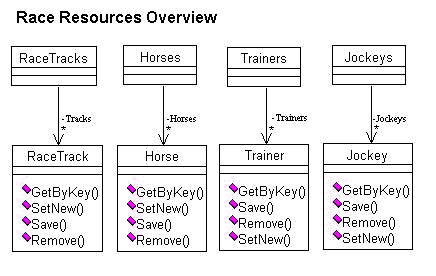
Figure 8
Please note that all the methods of Figure 8 are public. You can see that from the "eraser-like" symbol to the left of each method's name. Visual Modeler marks a private method with a padlock and a "friendly" method with a key. You'll see more of those, especially the padlock, in later examples.
Please note also the arrows on the lower parts of the association lines. They show you that the associations are navigable only in one direction, from the collection objects to the individual objects. A Horse object, for instance, will not know anything about a Horses object that may own it, whereas a Horses object will own a collection of Horse objects and thus know about all of them.
This is just a beginning, but it shows quite well that resource objects have much in common, a fact that you may use to your advantage. It allows you to build design patterns. It even allows you to build Visual Basic Wizards to support these patterns.
Now, you have a model that Visual Modeler can use to generate code for you. It may be a bit premature, but please allow us to show how code, generated by Visual Modeler for the Horse class, may look. Look at Figure 9. It shows that Visual Modeler has generated a public subroutine for each of the public methods in the design model.
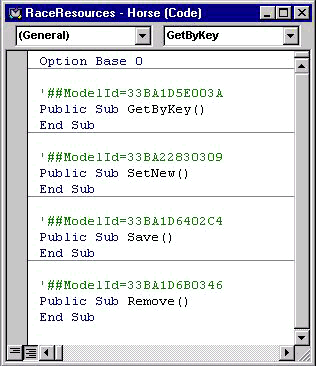
Figure 9
We'll later show you how to make Visual Modeler generate functions instead of subroutines, and how it will generate complete method interfaces with arguments and comments.
Right now the only comments are the ModelId annotations. Don't touch them! They are the vehicle Visual Modeler uses to map program components to model components in Round Trip Code Generation and Reverse Engineering.
Let's take a closer look at the methods of the Horse class to see how they are supposed to work from an external viewpoint. We'll start with the GetByKey method.
This method is the one that client applications will call when they want an indicated object to be fetched from the database. To be able to fulfill such a request, the method needs to know the key value of the required object.
Keys come in different shapes. We've already seen that from the data model. A racehorse in this system is identified by an integer value, whereas the identification for a racetrack is a string value. This is complicated enough, but it can get worse.
To identify a RaceDay object you need a TrackId as well as a Date. This is a combination of two different data types, a string and a date. If you want to identify a specific race you'll have to add a numeric value—the race number—resulting in a key combination of three different data types.
You may not see this as a real problem. However, if you strive for as much generalization as possible, which we think you should, then it really is a problem. You would want every GetByKey method to look and work in the same way, no matter what kind of object the method belongs to.
Fortunately there is a solution. If you choose the Variant data type for the key argument, it will look the same for all objects.
If the client application wants a racetrack, it will do as follows:
vKey = "Tab"
objTrack.GetByKey(vKey)
For a horse it would do this:
vKey = 2425
objTrack.GetByKey(vKey)
and for a race, this:
Redim vKey(1)
vKey(0) = "Tab"
vKey(1) = "1997-06-30"
objTrack.GetByKey(vKey)
If you choose this route, then all GetByKey methods will look the same and at least in principle behave the same. Take a look at Figure 10, and you'll see the similarities so far between the four resource classes of your application.

Figure 10
How does the resource object fulfill its responsibility to get an individual object from the database and make it available to the client application? This is not an issue for external design, which we are doing right now. The main thing now is to design the outside, the programmer's interface to your structure, not how the inside of your application shall fulfill the different services.
All the client programmer should need to know is how to ask for the service and how to find out if it was carried out without problem or not. This is what we should focus on in external design.
As things are right now, it is clear how the client should ask for the GetByKey service. There is, however, no way for the client to know if the required operation was successful or not.
In general there are two ways for an object to notify a client of any errors or other problems:
Which way should you choose?
The answer is simple, at least if you want maximum flexibility and scalability from your application. If you do, you should run at least part of it under Microsoft Transaction Server. The objects we are discussing now are data objects. In some circumstances you would probably want to run those as near the client as possible, but in others you would have to run them in a server. That would be the case for Internet and, probably, also intranet implementations. In those cases you should definitely run them under Transaction Server, taking advantage of benefits like automatic pooling of threads and objects.
Given that, your choice is clear. Microsoft Transaction Server is, for good reasons, very conservative. It will never let an error leave Microsoft Transaction Server and return to the client. If that should happen, it would rather stop the entire process and roll back any work that had been done within it. By doing that, Microsoft Transaction Server stops the potentially failing operation from distributing information that might be in error or destroyed. Even more important, it prevents erroneous data from being committed.
This conservatism even has a name. It is called the "Failfast policy of Transaction Server." We like it.
Because of it, you can't have a Transaction Server object raise an error and expect it to return that error to a client outside of Transaction Server. Instead it will stop the process and set up its own error. Consequently, you'll have to make the object return an error code rather than raising an error. You will have to change the subroutine into a function.
You can easily accomplish this with Visual Modeler. All you have to do is to enter a Return Class for the method in question. While you're at it you might as well write a short description of the method. As you can see in Figure 11, you can do it in the same dialog box as the one where you choose a return class for the function.
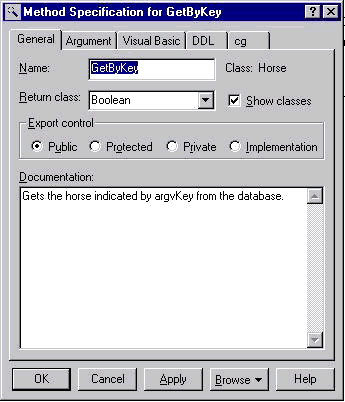
Figure 11
Please note that we have chosen Boolean as the return data type. We figure that all the client needs to know first hand is whether the method call succeeded or failed. If it succeeded everything is dandy. If it failed, the client application will need more information about the nature of the failure. We'll come back to that part later. Right now we want to do another code generation, just to let you see what Visual Modeler will do with the changes we have introduced to the model.
Just as before, we will ask Visual Modeler to generate code for the Horse class only. We shall also ask Visual Modeler to generate the Option Explicit keyword, which was lacking in the last example. You can do that from Visual Basic Options on the Tools menu in Visual Modeler.
Here is the result. We have made new or changed code segments bold to help you spot them more easily:
Option Explicit
Option Base 0
'Gets the horse indicated by arg vKey from the database.
'
'##ModelId=33BA1D5E003A
Public Function GetByKey(vKey As Variant) As Boolean
End Function
'##ModelId=33BA22830309
Public Sub SetNew()
End Sub
'##ModelId=33BA1D6402C4
Public Sub Save()
End Sub
'##ModelId=33BA1D6B0346
Public Sub Remove()
End Sub
Please note the following:
You can see how the code and the model go hand in hand. You have made changes to the model. Visual Modeler has furthered those changes into the code. You could also do it the other way around. You could make your changes in code and then by way of Reverse Engineering update the model to reflect those changes.
You should now do the same to the other resource classes—Trainer, Jockey, and RaceTrack. They should all have a vKey argument and a Boolean return class to their GetByKey methods. Each one of them should also have a proper comment, describing what the method does.
Doing the same thing over is tedious and error prone. We guess you'll easily see the value in having suitable Resource Class Templates, or even Resource Class Creation Wizards. But it's still too early for that. We need to establish more fully the exact responsibilities of nearly all resource classes before we can discuss those things intelligently.
One of those responsibilities is to make class properties available. A Horse class should publish properties like the horse's name, sex, and color. A Trainer class should publish the first and last names of the trainer and whether he or she is an amateur or not. All of these properties are persistent, which means that they should persist over and between sessions. In client/server lingo: they should always be saved in the database when changed.
So, long term, such properties belong in the database. Short term they also belong in main memory for high availability and editing. The place for that is clearly together with individual data objects such as Horse objects, Trainer objects and so on.
Again you have at least two basic design options:
We won't attach the property objects directly to the data objects. That would make objects such as Horse and Trainer responsible for a lot of operations on the property objects. It is much better to create a generalized intermediate class and have that one perform as many generalized duties as possible. The more work you can delegate to that class, the less work you have to design for the individual classes.
Figure 12 shows that each one of the resource classes now has exactly one object of the ADBGnrlStFl class, and that this class has a collection of FieldObject objects. There are no details of the new classes yet, but they will surface one by one as we go along.
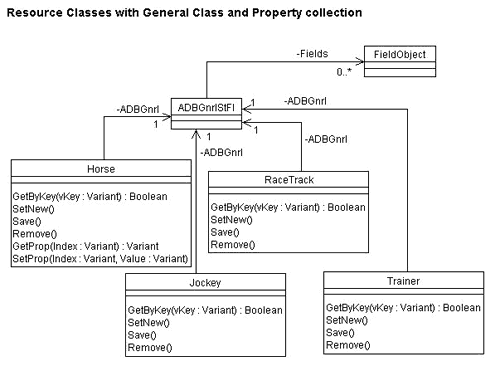
Figure 12
The names of some of our classes begin with the ADB prefix, meaning that they are general classes created by ADB-Arkitektur. Of course, you may want to give your versions of them other name prefixes.
The FieldObject name is fairly obvious, but ADBGnrlStFl may need explanation. Gnrl means that it is a general class, the objects of which do generalized operations. StFl means that it is a stateful class that needs to be kept alive as long as its client needs to keep that state. This means that as long as there is a client of a Horse object, this client will probably want access to the properties of that Horse object. Microsoft Transaction Server should not be allowed to put it away in an object pool each time it has performed some work.
These habits of Microsoft Transaction Server—to pool object instances and other resources—is highly beneficial. Every time you possibly can, you should take advantage of it. You can't with stateful objects. This is a good reason to keep stateful objects apart from stateless objects. You should also keep stateless functions away from stateful objects. Every time you put stateless functions in stateful objects you hurt the scalability of your application. This is why there is an ADBGnrlStFl class in the first place. Later you'll see that there is also an ADBGnrlStLs class for generalized stateless operations.
From an external viewpoint, all you need now to make field values available to client applications is to introduce a method to get and another to set the values of each persistent property or field. GetField and SetField seem to be good names for these methods.
They both need to know which field value to get or set. Just as in any collection class you should allow clients to select a field object by giving its name or its ordinal number. If Name is the second field of the Fields collection of a Horse object, the client should be able to get the value by any of the following calls:
sName = objHorse.GetField("Name")
sName = objHorse.GetField(2)
Consequently, the only argument of the GetField method should be a Variant. The best name for it is, as in collection classes, Index.
Also, the GetField method should be able to return the requested value with no regard to the actual data type. String data, numeric data and date values should all be treated the same. Thus, GetField should return a Variant value.
SetField needs two arguments but no return value. The first argument is the index to the right field; the second argument is the new value. The two arguments should, following the same reasoning as the one about GetField, both be Variants.
Figure 13 shows the interface of these additions to the horse class.
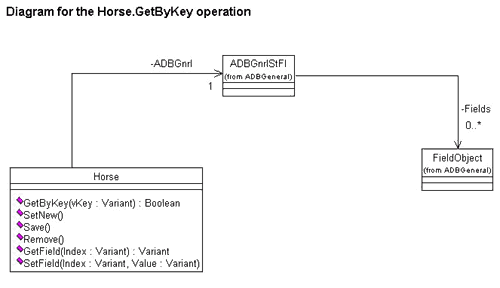
Figure13
There are several other solutions. One is to publish the entire property collection in a Property Get procedure. This, however, is not problem-free. For example, the data object will not be able to prevent the client from doing bad things.
Another solution, at least as good as the one with GetField and SetField, is to create indexed public Property Get FieldValue and Property Let FieldValue procedures to allow clients to do as follows:
Horse.FieldValue("Name") = "ManOWar"
Text1.Text = Horse.FieldValue(2)
Still, at least for this article, we'll go with the GetField and SetField solution.
Normally, the best way is to take external design as far as you possibly can before you start on internal design. However, this is not a normal situation. After all, what we are trying to do is to present some ideas on design patterns, not to build a system. So we'll take the liberty of doing otherwise. We'll jump ahead to take a look at the inner functionality of your Horse class, just to see what kind of help it needs to get the required horse from the database.
First and foremost, it should not do it all by itself. Other methods of other objects may need the same service. Furthermore, fetching a horse from the database should be a stateless operation. Fast in/fast out is the way to go. Fetching a horse is entirely different from keeping data about a horse. The same object should not carry out both of these services.
For a stateless object—one that fetches horses—Microsoft Transaction Server can work miracles. It will keep a small store of such objects all ready to go when needed. When a client wants a horse fetched, Microsoft Transaction Server will give it such an object. As soon as the horse is fetched and returned, Microsoft Transaction Server takes the object back into store.
Consider the Horse object, a stateful data object. It must stay alive for its client just as long as the client lives. How large a proportion of its entire lifetime will be spent fetching one or another horse? Probably less than one percent. The rest of the time it will manipulate properties, save or delete objects, and—more than anything else—wait for the user.
If this is true, a stateless object running under Microsoft Transaction Server will be able to serve about 100 times more clients than a stateful object could have done. This is a good reason to keep potentially stateless operations away from stateful objects. Doing that, you increase the scalability of the entire application.
But why a FetchHorses object? Why don't we just create one single object that could do all database operations for Horse objects? This object could fetch and update horses. It could insert new horses and delete horses no longer needed. All these operations are stateless, right? Why not keep them all in the same object?
The reason is that they don't relate to transactions in the same way. In Microsoft Transaction Server you don't have to program transactional behavior, which is a difficult, tedious, and error-prone job. Instead, you declare transactional behavior individually for each component. You have four choices:
Insertions, updates, and deletions are transactional operations. Fetching is not. This is why you should keep these kinds of operations separated from each other. They should reside in different classes. Ergo, you need a FetchHorses class with a GetByKey method.
This class could have several other methods too. What they all should have in common is that they should fetch horses from the database. They shouldn't do transactions.
Who is going to call the method in the fetch object? Again, you have at least two choices:
If you follow us on the second route you will benefit enormously.
All resource objects, and several other objects too, will delegate the GetByKey service to ADBGnrlStFl. Depending on which kind of object uses the service, ADBGnrlStFl should call different fetch objects. If the caller is a Horse object, ADBGnrlStFl should call a FetchHorses object. If it is a Trainer object, a FetchTrainers object should be called. And so on.
ADBGnrlStFl has no way of knowing which fetch object to call. The data object using the service must tell it.
For this the ADBGnrlStFl.GetByKey method needs a second argument. This argument should be a reference to the fetch object that should be called.
As you can see Figure 14, we have played it safe. We have declared the objFetcher argument of the GetByKey method as Object, even though this results in late binding. If we were a bit bolder, and we nearly were, we should have designed a general ADBFetcher class, letting the HorseFetcher and other fetchers implement this class. The main benefit of that would have been early binding. Even though this would have been to our advantage, and even though there are other benefits as well, we have decided to let the new Implements keyword wait a bit in this design pattern. If you're bolder than we were, please feel free to experiment with it. If you use it successfully, it will add value to your design pattern, no question about it.

Figure 14
The general object doesn't really know which fetch object it calls. Since we were cowards and avoided the Implements keyword, it doesn't even know for sure if the fetch object is capable of handling the call. This will be your responsibility as a server developer.
Also, it doesn't know or care about the content of the vKey argument. It might be a string value, a numeric value, or even a combination of several values. The ADBGnrlStFl object doesn't care. It just sends the key argument along to the fetch object, which does have to know the structure of the key.
The key structure is part of the contract between the data object and any stateless object that may serve it. Generalized objects like ADBGnrlStFl just send the key argument along without regard to structure or content. This is part of the beauty of the way we have designed the vKey Variant argument. It allows you to delegate more work to reusable generalized objects. The good result is that you won't have to design and program that work to the individual objects, which are less reusable.

Figure 15
The fetch object must know the key of the object it should fetch from the database. It will also need a place to put the fields of the fetched object. This place should be general enough for any kind of object. Since it will always be a set of properties, why don't we call it a property bag? To be flexible enough it must be a Variant variable, so we'll give it the name vPropBag.
Let's add the FetchHorses class to our model and design a GetByKey method for it. Then we'll be able to discuss how it should fulfill the request.
Please note in the diagram to the right that we have labeled this class as a Race Resource Service class. We'll come back to this concept in the next article of this series, as we try to bring order to our design pattern.
The diagram also shows that GetByKey will be a Boolean function receiving two variant arguments: vKey and vPropBag.
Let's get back to ADBGnrlStFl, the generalized stateful object that has just called a FetchHorses object on behalf of a Horse object. Let's suppose that the call went well, meaning that we have a set of properties in the vPropBag property bag. The next task must be to unpack the property bag and place its content in the Fields collection. For this the general object needs an operation—an UnpackProperties operation.
Let's add this operation and create a new diagram that focuses on the Horse.GetByKey operation.
As you can see from Figure 16, the UnpackProperties method takes one Variant argument—the (hopefully) filled property bag. From the padlock to the left of the method name you can see that it's a private method, callable only from within the object itself.
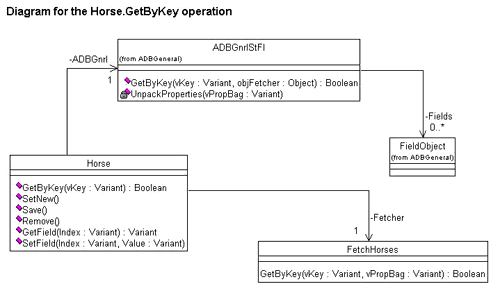
Figure 16
The beauty of this part of the design is that the client programmer only has to call the Horse.GetByKey method, giving the key of the horse wanted. The Horse object in turn can delegate all the work to the general ADBGnrlStFl object. The same applies to other resource classes like Trainer, Jockey, RaceTrack, Customer, Product, and so on. Generalized objects will perform standard operations for specialized objects. Result: increased development productivity and reliability.
Up until now, we haven't called the database. Again, we can turn this into a standard operation and have a general object do the work. Enter the ADBGnrlStLs class, a class of stateless but still generalized objects that do work for specialized stateless objects like those of the FetchHorses class.
These objects should be able to query the database, using query objects received from the client. For example, FetchHorses objects will send them FetchHorses queries, whereas FetchTrainers objects will send them FetchTrainers queries.
It's the job of the individualized fetch object to prepare the query with a proper SQL statement and a proper parameter set. The ADBGnrlStLs object should only have to call the database and then put the results in the property bag in a standardized way. It doesn't even have to know about the key values, since those are already set up as parameters to the query.
Now, the design of the GetByKey operation is complete, as you can see from Figure 17.
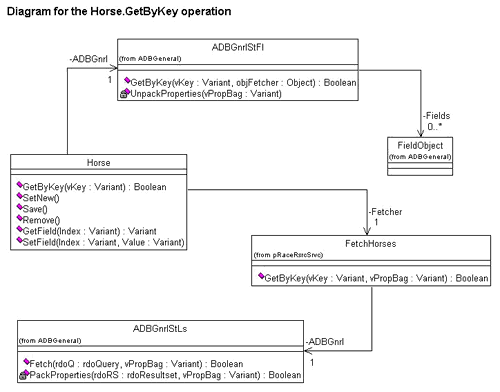
Figure 17
This is what happens from start to finish:
vKey = 2242
bRetCode = objHorse.GetByKey(vKey)
Set objFetcher = New FetchHorses
bRetCode = ADBGnrl.GetByKey(vKey, objFetcher)
Dim vPropBag As Variant
bRetCode = objFetcher.GetByKey(vKey, vPropBag)
' Set up rdoQ as a new query object with the right SQL.
' not shown here
rdoQ.rdoParameters(1) = vKey
bRetCode = ADBGnrl.GetByKey(rdoQ, vPropBag)
' Call the database, creating an rdoReslutset object.
' not shown here
If Not(rdoRS.EOF) Then
bRetCode = PackupProperties(rdoRS, vPropBag)
End If
Dim vPropBag As Variant
bRetCode = objFetcher.GetByKey(vKey, vPropBag)
UnpackProperties vPropBag
Then, if run under Microsoft Transaction Server, it should call SetComplete to let Transaction Server pool any resources used by the object.
Please note that all we have shown you in the examples above are the basics needed for the GetByKey operation to work properly. We haven't shown you any error handling and there are also other details missing. The basic and main things, however, are there.