
Tony Scott
Tony Scott is an architectural consultant with Microsoft Consulting Services, focusing on enterprise architecture and database design.
art (aρτ) n. The application, or the principles of application, of knowledge and skill, in an effort to produce some practical result.
Webster's Comprehensive Dictionary, 1986
Optimizing and tuning a relational database (RDB) system is a knowledge-intensive art. The skillful practitioner must have an understanding of:
This paper addresses each of these issues with respect to the Microsoft® SQL Server for Windows NT®, version 4.21a. Furthermore, this paper takes a pragmatic approach with regard to the presentation of this material. "Optimization" is defined as the planning for efficient operation with respect to user and application performance requirements, and logical database design. "Tuning" entails implementing operational or design performance enhancements based on the observation of tunable performance characteristics, and their relationship to performance requirements. Thus, optimization takes place as early as the planning and design phases of the SQL Server solution process, while tuning occurs during the pilot, implementation and or roll-out phases. Accordingly, this paper addresses SQL Server optimization and tuning processes from a design and development point of view.
The following SQL Server solution phases are discussed in detail with respect to performance considerations and practices:
This paper assumes that you are already familiar with SQL Server, either from Microsoft on OS/2 or Windows NT® operating systems, or from SYBASE on UNIX or VMS. However, this paper will review, in brief, several key architectural features in order to support important optimization and tuning concepts. Furthermore, this paper assumes that you are proficient in relational database design and understand basic Structured Query Language (SQL) constructs. Also, you should be familiar with the Windows NT Performance Monitor and its use for gathering performance related data.
Because it is not feasible to cover all performance-oriented concepts and techniques in detail within the scope of this paper, the information presented will address topics that have the greatest or most strategic impact on SQL Server performance. Furthermore, it is expected that this information will be used to conduct performance experiments that will lead to the best performance within your own SQL Server environment.
The information presented in this paper should be viewed only as a set of guidelines, because every SQL Server environment is different. Finally, the order of topic presentation corresponds to the order in which such subjects should be considered during the design and implementation of the SQL Server solution process.
In order to discuss optimization and tuning of the SQL Server, it is necessary to briefly discuss and illustrate some key architectural structures and concepts that are strategic to performance considerations. Moreover, understanding these structures and concepts is vital to the development of optimal SQL Server solutions.
In order to build an optimal SQL Server solution, one must be able to take advantage of the characteristics of the system. An understanding of the fundamental building blocks of the database is the best place to start. These building blocks consist of the basic internal structures that by their nature affect how the SQL Server performs. This section presents information concerning the low-level structures associated with a database in general, as well as the tables and indexes that by and large are the focus of the optimization and tuning process at this level.
At the highest level, a SQL Server database is, in essence, a storage area for database objects. These objects represent tables, indexes, views, system- and user-defined datatypes, stored procedures, and so on. However, this list of objects describes what resides in the database, not the elements that constitute the database. A SQL Server database is composed of fractional space of one or more logical devices, which in turn are broken down into disk fragments and then possibly into segments. This represents the external view of the database as described by the data definition language and system tables such as sysdevices, sysdatabases, sysusages, and syssegments.
There is also an internal view of the database, which consists of low-level data constructs such as devices, disk fragments, allocation units, extents, and pages. It is this internal view that is of greatest interest, with respect to understanding how to build optimal SQL Server solutions. A brief summary of each of the internal structures follows. In addition, a discussion relating these internal structures to the higher-level data objects serves as the basis for strategies for the optimal design and tuning of database objects and queries.
Devices
Database devices store databases and transaction logs. These devices are stored on disk files and as such, are physical storage allocated to the server. A database device must be at least 2 megabytes (MB) or 1024 2-kilobyte (K) blocks in size. When created, the device is divided into allocation units, each of which is 256 2K pages, or 0.5 MB. Thus, a database device consists of at least 4 allocation units (Figure 1).
Figure 1. Database devices divided into allocation units
Once a database device has been created, an new row is added to the sysdevices table in the master database. This table contains data relevant to the size, page addressing, logical name, and physical location of the device file. Once a database device of a specific size has been created, it cannot be changed. Thus, care should be given to the determination of device size.
Disk Fragments
A disk fragment represents the space used by a database over one or more database devices. Each disk fragment of storage for a database must be at least 1 allocation unit in size. However, by default, a new database requires a disk fragment at least 4 allocation units in size, or 2 MB. Moreover, database expansion must be requested in 1-MB (or 2 allocation units) increments. If the requested size cannot be satisfied, SQL Server allocates as much storage as possible in 0.5-MB (or 1 allocation unit) increments. Hence, disk fragment sizes reflect multiples of 0.5 MB (Figure 2).
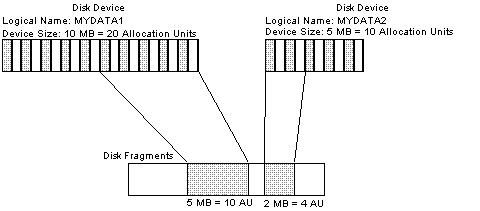
Figure 2. Disk fragments
A disk fragment is actually a mapping between logical pages used within a database and virtual pages used by the SQL Server kernel. This mapping is recorded by at least one row entry in the sysusages table in the master database. There is a limit of 32 entries per database in the sysusages table.
Allocation Units
An allocation unit represents 256 contiguous pages, or 0.5 MB, of internal SQL Server data storage. Within each allocation unit, the first page is the allocation page. It contains an array that shows how the other 255 pages are used. In addition, each allocation unit consists of 32 extent structures.
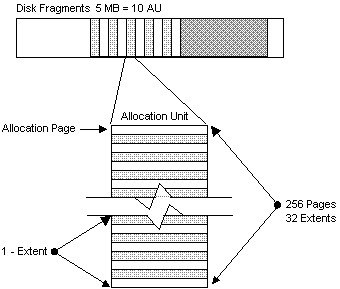
Figure 3. Allocation units
Extents
Extents are the smallest unit of data storage reserved for tables and indexes. Each extent consists of eight contiguous pages. Thirty-two extents populate a single allocation unit. Extents are linked together to form a doubly linked circular chain for each table or index object.
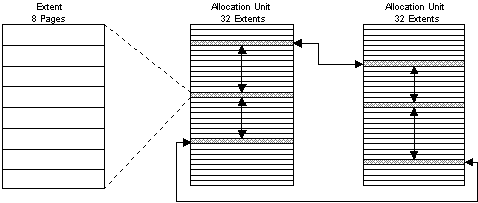
Figure 4. Extents
Pages
SQL Server pages are 2K in size. The page is the unit of input/output (I/O) for accessing and updating data. There are five distinct types of pages:
Page management is accomplished via extent structures. Thus, from a database table or index object perspective, an allocation of an extent (or 8 pages) occurs if a new page is required.
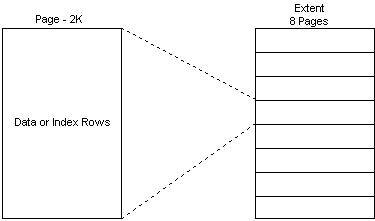
Figure 5. Extent structures
Tables
SQL Server tables are composed of data pages. Data pages are 2K in size and are chained together to form a doubly linked list. Each data page has a 32-byte header that contains information about the page and links to other pages in the chain. The data rows are stored immediately after the header information and contain row storage information and the actual data. Thus, each data page is capable of storing up to 2016 bytes of data, including overhead storage. In addition, a table with no clustered index will have a row in the sysindexes table that points to the first logical page and the last or root page of the table's data page chain (Figure 6).
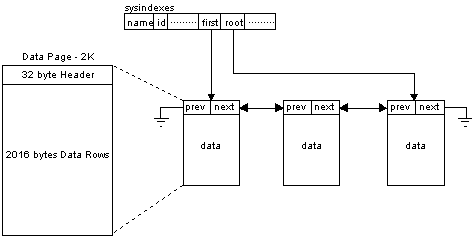
Figure 6. Data pages
All data is stored in a contiguous manner, thereby simplifying data page scans. Information concerning the columns for each row is kept in the syscolumns table for each table data object.
Indexes
SQL Server indexes are composed of index pages, which possess the same physical characteristics as data pages. Index pages consist of a 32-byte header and index rows taking up to 2016 bytes. The index rows contain pointers to index node pages, data pages, or data rows, depending on the type of index represented. Each page chain in an index is referred to as a level. Index pages at the same level are doubly linked, with the lowest level being the zero (0) level. The highest level is called the root and consists of only one page. These characteristics are true of all SQL Server index types.
There are two types of SQL Server indexes, clustered and nonclustered. Clustered index pages (Figure 7) are composed of index rows containing pointers to other index node pages or data pages at the leaf level. Thus, data pages are physically ordered by the key value associated with a clustered index. In addition, each clustered index will have a row entry in the sysindexes table with a indid of 1. This entry points to the first data page in the tables chain via its logical page number, and to the root page of the clustered index via its logical page number.
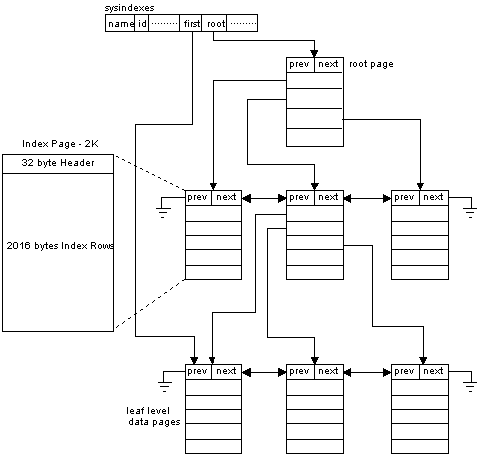
Figure 7. Clustered index pages
Nonclustered index pages (Figure 8) are composed of index rows containing pointers to other index node pages or individual data rows at the leaf level. Hence, data pages are not physically ordered by the key value associated with a nonclustered index. In addition, each nonclustered index will have a row entry in the sysindexes table with a indid greater than 1. This entry points to the first index page in the leaf level of the index chain via its logical page number, and the root page of the nonclustered index via its logical page number.
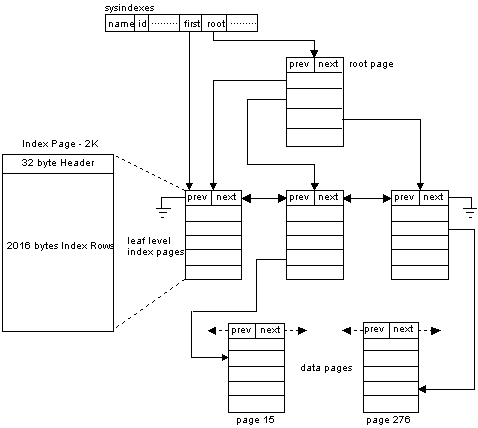
Figure 8. Nonclustered index pages
The SQL Server communicates with clients via a network interface layer called the Net_Library. This interface layer, along with the Open Data Services layer, accounts for the bulk of the SQL Server network architecture.
A Net_Library is a network interface specific to a particular network interprocess communication (IPC) mechanism. SQL Server uses a common internal interface between Open Data Services, which manages its use of the network, and each Net_Library. By doing this, all network-specific considerations and calls are isolated to just that Net_Library. There may be multiple Net_Libraries loaded, one for each network IPC mechanism in use (for example, one for named pipes, another for TCP/IP sockets, another for SPX, and another for Banyan VINES SPP). Unlike SQL Server on other operating systems, Microsoft SQL Server uses this Net_Library abstraction layer at the server as well as the client, making it possible to simultaneously support clients on different networks. Windows NT allows multiple protocol stacks to be in use simultaneously on one system.
It is important to distinguish between the IPC mechanism and the underlying network protocol. IPC mechanisms used by SQL Server include named pipes, SPX, and Windows® Sockets. Network protocols include NetBEUI, NWLink (SPX/IPX), TCP/IP, and VINES IP. Named pipes, a common IPC used in SQL Server environments, can be used efficiently over multiple network protocols—NetBEUI, NWLink SPX/IPX, and TCP/IP, all simultaneously. SQL Server in other environments has traditionally supported only a single IPC mechanism (usually TCP/IP sockets) that is hard-coded directly into the network handler. All clients needed to speak to that IPC mechanism, and nothing else, and usually only with a single network protocol.
ODS functions as the network connection handler for SQL Server for Windows NT. In the past, Open Data Services and the Sybase Open Server were often referred to as "conceptually" the front end of SQL Server. However, they were different implementations that attempted to perform the same function. But it is literally true that SQL Server for Windows NT is an ODS application. SQL Server uses the same ODS library (OPENDSNT.DLL) as any other ODS application. ODS manages the network, listening for new connections, cleaning up failed connections, acknowledging "attentions" (cancellations of commands), and returning result sets, messages, and status back to the client.
SQL Server clients and the server speak a private protocol known as Tabular Data Stream (TDS). TDS is a self-describing data stream. In other words, the TDS data stream contains "tokens" that describe column names, datatypes, and events (such as cancellation), and return status in the client-server "conversation." Neither clients nor servers write directly to TDS. Instead, open interfaces of DB-Library and ODBC at the client are provided that emit TDS. Both use a client implementation of the Net_Library. At the server side, ODS is basically the mirror image of DB_Library/ODBC.
Intelligent database design is perhaps the most critical element of an optimal SQL Server solution with respect to performance. In fact, it is usually a poor design that is the culprit behind many poorly performing SQL Server solutions. This section discusses critical design factors that must be considered in order to produce an efficient, logical database design. It is assumed you are familiar with relational database design concepts such as entity relationship modeling and normalization, because it is not within the scope of this paper to thoroughly address such topics.
Designing an optimal relational database is typically accomplished via the use of Entity-Relationship Modeling and Normalization. These two processes or methodologies aid in defining the logical data model.
Entity-Relationship Modeling is the identification of data entities or objects and the relationships between these entities. The Entity-Relationship Modeling process usually progresses in the following manner:
When you have completed this process, the resulting Entity-Relationship Model represents a logical view of the data entities and associated relationships upon which the physical database design will be based. Furthermore, it is during this modeling process that normalization commonly occurs.
Generally, a logical database design will satisfy the first three levels of normalization, as follows:
In essence, a design based on these rules will yield a greater number of narrow tables, thereby reducing data redundancy and decreasing the number of pages required to store the data. Consequently, table relationships may need to be resolved via complex joins. However, the SQL Server optimizer is designed to take advantage of normalized logical database designs, as long as efficient indexes have been derived from the identified primary key/foreign key relationships. Nonetheless, it should be realized that there are tradeoffs between a highly normalized database design and an intelligently denormalized design (defined below). It is this strategy of selective and intelligent denormalization that will most often result in the greatest performance gains as related to the logical database design.
Denormalization is the act of pulling back from a previously normalized database model for the purpose of improving performance. Denormalization may take place at the entity or attribute level, and thus requires a knowledge, as previously discussed, of how the data will be used and/or accessed. Denormalization may be accomplished in many different ways, based on myriad performance considerations. However, the following tactics have proven useful for improving performance:
Tactic: If the normalized design results in many four-way or greater join relationships, consider introducing redundancy at the attribute (column) or entity (table) level by way of the following:
Tactic: Redefine attributes in order to reduce data width of an entity by way of the following:
Tactic: Redefine entities (tables) in order to reduce the overhead of extraneous attribute (column) data or row data. Appropriate types of associated denormalization are:
The goal is to develop as optimal a logical database design as possible, before physically implementing the database, thereby resulting in less tuning during latter stages of the SQL Server solution process. To attain this goal, one must apply knowledge of the user and application requirements in order to efficiently balance between a normalized and denormalized data model. The end result is to save space and time with regard to performance. Hence, keep the following guideline in mind when creating physical tables:
The data type associated with each table column should reflect the smallest storage necessary for the required data. This will result in more data rows fitting on a single data page, and therefore fewer I/Os.
Understanding the internal storage structures associated with SQL Server databases, possessing knowledge of the user and application performance requirements, and having designed an optimal logical database design, you should now consider the optimal hardware platform, based on this information. It is the goal of this section to provide information that will help to determine the best possible hardware configuration for your database environment. In addition, SQL Server configuration parameters are addressed, because they influence the performance of the hardware platform. Characteristics of the Windows NT operating system are also discussed from a hardware performance point of view.
Hardware planning as it relates to SQL Server is primarily concerned with system processors, memory, disk subsystems, and the network. These four areas constitute the bulk of all relevant hardware platforms on which Windows NT and SQL Server operate. Therefore, this paper addresses planning considerations that are generic to all platforms and useful for scaling and implementing optimal SQL Server solutions.
In trying to determine which initial CPU architecture is right for your particular needs, you are attempting to estimate the level of CPU-bound work that will be occurring on the hardware platform. As far as SQL Server is concerned, CPU-bound work can occur when a large cache is available and is being optimally used, or when a small cache is available with a great deal of disk I/O activity (aside from that generated by transaction log writes). The type of questions that must be answered at this point are as follows:
The answer to these questions may have already come from the requirements as discussed previously. If not, you should be able to make some reasonable estimates. The bottom line is: Purchase the most powerful CPU architecture you can justify. This justification should be based on your estimates, user requirements, and the logical database design. However, based on experience, it is suggested that the minimum CPU configuration consist of at least a single 80486/50 processor.
Determining the optimal memory configuration for a SQL Server solution is crucial to achieving stellar performance. SQL Server uses memory for its procedure cache, data and index page caching, static server overhead, and configurable overhead. SQL Server can use up to 2 GB of virtual memory, this being the maximum configurable value. In addition, it should not be forgotten that Windows NT and all of its associated services also require memory.
Windows NT provides each Win32® application with a virtual address space of 4 GB. This address space is mapped by the Windows NT Virtual Memory Manager (VMM) to physical memory, and can be 4 GB in size, depending on the hardware platform. The SQL Server application only knows about virtual addresses, and thus can not access physical memory directly. Physical memory is controlled by the VMM. In addition, Windows NT allows for the creation of virtual address space that exceeds the available physical memory. Therefore, it is possible to adversely affect SQL Server performance by allocating more virtual memory than there is available physical memory. The following table contains rule-of-thumb recommendations for different SQL Server memory configurations, based on available physical memory.
| Machine Memory (MB) | SQL Server Memory (MB) |
| 16 | 4 |
| 24 | 6 |
| 32 | 16 |
| 48 | 28 |
| 64 | 40 |
| 128 | 100 |
| 256 | 216 |
| 512 | 464 |
These memory configurations are made for dedicated SQL Server systems, and should be appropriately adjusted if other activities (such as file and print sharing, or application services) will be running on the same platform as SQL Server. However, in most cases it is recommended that a minimum physical memory configuration of 32 MB be installed. Such a configuration will reserve at least 16 MB for Windows NT. Again, these memory configuration recommendations are only guidelines for initial configuration estimates, and will most likely require appropriate tuning. Nevertheless, it is possible to make a more accurate and optimal estimate for SQL Server memory requirements based on the previous knowledge gained from user and application performance requirements.
In order to make a more accurate estimate for an optimal memory configuration, refer to the following table for SQL Server for Windows NT configurable and static overhead memory requirements.
| Resource | Configurable | Default Value | Bytes per resource | Space (MB) |
| User Connections | Yes | 25 | 18,000 | 0.43 |
| Open Databases | Yes | 10 | 650 | 0.01 |
| Open Objects | Yes | 500 | 72 | 0.04 |
| Locks | Yes | 5,000 | 28 | 0.13 |
| Devices | No | 256 | 300 | 0.07 |
| Static server overhead | No | N/A | 2,000,000 | 2.0 |
| Total Overhead | 2.68 |
You can use this information to calculate a more exact memory configuration estimate with respect to actual memory usage. This is done by taking the calculated Total Overhead (above) and applying it to the following formula:
SQL Server Physical Memory - TOTAL Overhead = SQL Server Memory Cache
The SQL Server memory cache is the amount of memory that is dedicated to the procedure cache and the data cache.
The procedure cache is the amount of the SQL Server memory cache that is dedicated to the caching of stored procedures, triggers, views, rules, and defaults. Consequently, if your system will take advantage of these data objects, and the stored procedures are to be used by many users, this value should be proportional to such requirements. Furthermore, these objects are stored in the procedure cache based on the frequency of their use. Thus, you want the most-used data objects to be accessed in cache rather than retrieved from disk. The system default is 20 percent of the available memory cache.
The data or buffer cache is the amount of the SQL Server memory cache that is dedicated to caching data and index pages. These pages are stored to the data cache based on the frequency of their use. Therefore, you want the data cache to be large enough to accommodate the most-used data and index pages without having to read them from disk. The system default is 80 percent of the available memory cache.
Accordingly, the following table illustrates a more accurate estimate of SQL Server memory requirements for a dedicated SQL Server.
| Resource | Estimated Value | Bytes per Resource | Space (MB) |
| User Connections | 50 | 18,000 | 0.9 |
| Open Databases | 10 - Default | 650 | 0.01 |
| Open Objects | 500 - Default | 72 | 0.04 |
| Locks | 15,000 | 28 | 0.42 |
| Devices | 256 | 300 | 0.07 |
| Static server overhead | N/A | 2,000,000 | 2.0 |
| Total Overhead | 3.44 |
As a result of these overhead requirements, you will have approximately 28 MB to work with on the SQL Server. As overhead requirements (such as user connections and locks) grow, this value will be reduced and may subsequently lead to performance problems that will require tuning.
Achieving optimal disk I/O is the most important aspect of designing an optimal SQL Server solution. The disk subsystem configuration addressed here consists of at least one disk controller device and one or more hard disk units, as well as consideration for disk configuration and associated file systems. The goal is to select a combination of these components and technologies that complements the performance characteristics of the SQL Server. Hence, disk subsystem I/O as it relates to reads, writes, and caching defines the performance characteristics that are most important to SQL Server.
The disk subsystem components and features you should look for are as follows:
The determination of how many drives, of what size, of what configuration, and of what level of fault tolerance, is made by looking back to the user and application performance requirements, understanding the logical database design and the associated data, and understanding the interplay between system memory and disk I/O with respect to Windows NT and SQL Server. Although it is beyond the scope of this paper to thoroughly cover this topic in-depth, there are several key concepts and guidelines that can aid you in selecting an appropriate disk subsystem components.
These concepts should be used as guidelines and not as absolutes. Each SQL Server environment is unique, thereby requiring experimentation and tuning appropriate to the conditions and requirements.
As with intelligent disk controllers, the goal is to select an intelligent network interface card (NIC) that will not rob CPU or memory resources from the SQL Server system. This network card should meet the following minimum recommendations:
When building an optimal SQL Server solution the choice of hardware should be based on:
All too often, SQL Server solutions are made to fit generically configured hardware platforms, resulting in poorly performing systems. Consideration needs to be given to proper hardware configuration before the physical implementation of the database. This strategy will initially mean less tuning and augmentation of the hardware components, and ultimately result in better performance, saving time and potentially money.
Implementing SQL Server on an optimized hardware platform entails configuring the system to take advantage of CPU, memory, disk subsystem, and network performance features. Accordingly, this section discusses in detail the performance-oriented installation options, as well as performance-oriented configuration options and the effects of their use on SQL Server. In addition, some Windows NT options and considerations are discussed, because they also affect SQL Server performance.
The following Windows NT options affect SQL Server performance and should be configured before installation of SQL Server.
Each application (as well as each thread) in the system has a set priority. You can control the priority systemwide by changing the Tasking dialog box, using the System applet in the Control Panel.
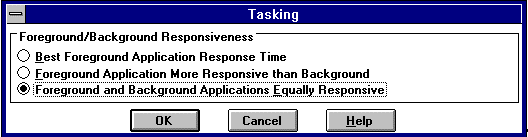
Setting the Tasking entry to "Foreground and Background Applications Equally Responsive" affords SQL Server the best level of tasking, because it ensures that another application will not dominate the system.
You can configure the server's resource allocation (and associated non-paged memory pool usage) by using the Network applet in the Control Panel. When you use the Network applet to configure the server service software, you will see the following Server Optimization Level dialog:
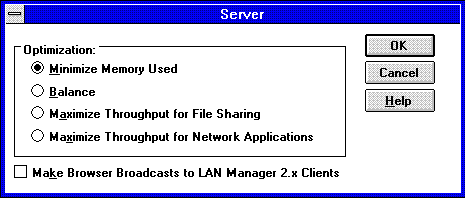
The "Maximize Throughput for Network Applications" setting is optimal for a SQL Server system. With this option set, network applications access has priority over file cache access to memory (4 MB of memory is allocated to available memory for starting up and running local applications). In addition, the amount of memory allocated to the server service (for such resources as InitWorkItems, MaxWorkItems, RawWorkItems, MaxPagedMemory, MaxNonPagedMem, ThreadCountAdd, BlockingThreads, MinFreeConnections and MaxFreeConnection) is appropriately optimized for this choice.
The following Windows NT Server performance considerations should be addressed before installing SQL Server.
As previously stated, Windows NT memory management is handled by the Virtual Memory Manager, or VMM. The VMM uses a system file, PAGEFILE.SYS, for storing virtual memory pages. This file is typically located in the root directory of a Windows NT system on the boot disk unit. This file may also be segmented as multiple files, stored on multiple disk units as an operating system performance enhancement.
With respect to SQL Server performance, this file should be stored on a physical disk unit that is segregated from the SQL Server disk units. Moreover, it is better if the physical disk units are on separate intelligent controller units. This is especially true for non-dedicated SQL Server systems that are likely to experience moderate to heavy page faulting due to file and print sharing, or application execution. However, you should recall it was recommended that only physical memory be allocated to SQL Server uses. Hence, if you cannot map PAGEFILE.SYS away from the SQL Server disk units, there should be little page faulting on dedicated systems as long as the memory allocation to Windows NT is sufficient (16 MB).
Microsoft's internal testing has shown that there is very little difference in SQL Server performance between New Technology file systems (NTFS) and file allocation table (FAT) file systems. In general, NTFS is faster than FAT for reads, and slightly slower for writes (because it performs transaction logging for recoverability). The SQL Server TPC-B benchmarks published by COMPAQ hardware used NTFS for the database devices and FAT for the log, because logging is write-intensive.
Note Both NTFS and FAT support Windows NT–based striping.
You may turn off any unused services via the Services Control Panel applet. These services use valuable system resources, thus potentially limiting SQL Server performance. Candidates for disabling are Computer Browser, Messenger, Network DDE, ClipBook Server, Schedule, Alerter, Network DDE DSDM, and any others not required for operation. SQL Server, SQL Monitor, Server, Workstation, and EventLog services should remain enabled in most cases.
Remove unused network protocols; their presence will affect SQL Server performance.
The following installation options affect SQL Server performance based on their values.
The SQL Server Installation Path is where all the operational directories and files for the SQL Server system are written. The path defaults to the C: drive and directory \SQL. Because this drive location is also where Windows NT Server is installed, it should not affect SQL Server performance. However, for a marginal performance enhancement, it is recommended that the SQL Server files as well as the operating system not be placed on a disk unit or disk volume that will be subject to heavy database reading and writing.
The location of the master device file, MASTER.DAT, can be changed from the default path, C:\SQL\DATA, to any other system location. Consideration should be given to changing the location of this file to a dedicated physical disk unit or disk volume. This location will help to isolate database I/O away from system I/O. In addition, by default, the tempdb database, which is 2 MB in size, takes its initial space allocation from the master device. Hence, any database activities that use the tempdb database will cause I/O to occur.
The master database device defaults to 15 MB in size. It is recommended that this be increased to 25 MB in order to account for growth in the master database.
The choice of character set has no effect on SQL Server performance. However, if the character set differs between the client and the SQL Server, query results and or execution can be unpredictable. The default is "Code page 850 (Multilingual)". For more information, please refer to the Microsoft SQL Server for Windows NT Configuration Guide.
Binary sort order is the fastest sort order option. The following table shows the approximate decrease in sort order performance, relative to binary order, for each sort order. The operation evaluated involved string comparisons on character fields.
| Sort Order | Percent Slower |
| Dictionary order, case sensitive | 20% |
| Dictionary order, case-insensitive, uppercase preference | 20% |
| Dictionary order, case-insensitive (no uppercase preference) | 20% |
| Dictionary order, case-insensitive, accent-insensitive | 35% |
The percentages in the table are approximate. The overall performance difference between sort orders varies significantly depending on the types of operations and the types of data used. For more information, please refer to the Microsoft SQL Server for Windows NT Configuration Guide.
The SQL Server Setup program allows for the selection of two options that affect the priority at which SQL Server runs, thereby influencing system performance. These options can be found under the "Set Server Options" selection of the Setup program.
Because these options affect the priority at which SQL Server threads run, the following definitions are necessary for basic understanding of Windows NT thread scheduling.
Boosting SQL Server priority can improve performance and throughput on single and multiple processor hardware platforms. By default this option is turned off and SQL Server runs at a priority of 7. When selected on a single processor platform, SQL Server runs at priority 13. When selected on a SMP platform, SQL Server runs at priority 24. The significance is, of course, that the Windows NT thread scheduler will favor SQL Server threads over threads of other processes.
If this option is turned on, it may degrade the performance of other processes. Therefore, this option should only be turned on for dedicated SQL Server machines, or if slower performance of other processes is tolerable.
SQL Server can take advantage of symmetric multiprocessing (SMP) platforms without this option being turned on. In the off state, SQL Server runs at a priority level of 7. When this option is turned on, the priority is increased to 13, thus increasing the scalability improvement multiple CPU's have on SQL Server performance.
As with the "Boost SQL Server Priority" option, "Dedicated Multiprocessor Performance," if turned on, may degrade the performance of other processes. Therefore, this option should only be turned on for dedicated SQL Server machines.
If both options are turned on for SMP platforms, SQL Server runs at a priority of 24.
The following SQL Server configuration parameters affect performance or performance-related resources. Each configuration parameter is defined with respect to its function and its impact on performance.
As a general rule, on machines with 32 MB or less, you should allocate at least 8 to 16 MB of memory to Windows NT, and configure SQL Server to use the rest. When you have more than 32 MB in your machine, allocate 16 to 20 MB to Windows NT, and allocate the rest of the memory to SQL Server.
Performance Impact: Physical memory is used by SQL Server for server operation overhead, data (buffer) cache, and procedure cache. Hence, in order to reduce SQL Server page faults, an appropriate amount of memory should be configured. Please refer to the previous discussion in this paper concerning memory.
The "max async IO" parameter controls the number of outstanding asynchronous batch writes performed by checkpoint and Lazywriter. The default is 8, and this is likely to be sufficient in most cases. However, you may wish to experiment with this number to try to improve performance. Increasing the parameter will allow more asynchronous batch writes to be done, effectively shortening the period that the system is checkpointing or doing Lazywriting. However, if your I/O subsystem cannot sustain the increased write activity, the increased writes will flood the I/O systems and can interfere with the ability of SQL Server (or other processes) to read from the disk, resulting in decreased throughput. The behavior of this parameter is thus dependent to a large degree on the underlying I/O subsystem.
Performance Impact: SQL Server for Windows NT uses the asynchronous I/O capability of the Windows NT operating system. Examples of these are the Win32 API ReadFile(), ReadFileEx(), WriteFile(), and WriteFileEx() calls. See the Win32 SDK for more information. Asynchronous, or overlapped, I/O refers to the ability of a calling program to issue an I/O request and, without waiting for completion, to continue with another activity. When the I/O finishes, the operating system will notify the program via a callback or other Win32 synchronization mechanism.
This has two main advantages. The first is it makes implementation easier for an application designer, because the operating system can be used to perform asynchronous I/O rather than having to simulate this capability in the application. The second advantage is that the multiple outstanding I/O requests can drive certain high-performance disk subsystems at greater performance levels than would be otherwise possible.
This is generally only possible with very-high-performance intelligent disk subsystems. Examples include but are not limited to the COMPAQ SMART SCSI-2 Array Controller, Mylex DAC960 Disk Array Subsystem, and the Tricord and Sequent SCSI Intelligent Storage Subsystems. Contact your hardware vendor for more information on how a particular disk subsystem handles Windows NT asynchronous disk I/O.
The reason is that only these types of systems have the specific features necessary to rapidly accept multiple asynchronous I/O requests from a Win32 application such as SQL Server. On these systems, increasing the "max async IO" parameter of SQL Server can result in performance improvements during very disk-intensive operations. The actual setting used for this parameter and the resultant performance increase will vary depending on the exact hardware and database I/O profile. It should not be set arbitrarily high, because inordinate asynchronous I/O consumes system resources. Please see Knowledge Base article Q98893, "Limit on the Number of Bytes Written Asynchronously" (MSDN Library, Knowledge Base) for more information.
By default, 20 percent of available memory is reserved for the procedure cache. In systems with large amounts of memory, this is often excessive.
Performance Impact: Having a properly sized procedure cache will result in fewer page faults with respect to use of stored procedures, triggers, rules and defaults. Please refer to the previous discussion in this paper concerning memory.
This parameter sets the maximum number of simultaneous connections to SQL Server. The actual number of connections may be less, depending on your database environment. The maximum value for this parameter is 32,767 (theoretical). However, this value is based on available memory and application requirements.
Performance Impact: Each user connection requires 18K of memory. Therefore, increasing user connections will increase the amount of memory needed for SQL Server overhead, thereby reducing the memory available for the data (buffer) and procedure caches. In addition, this value, along with "max worker threads," is used to determine if SQL Server uses thread pooling. Consequently, more physical memory may be required in order to maintain cache performance levels.
This value sets the maximum number of databases that can be open at one time on SQL Server. The default is 20 and can be set as high as 100.
Performance Impact: Each open database resource consumes 650 bytes of memory. Therefore, increasing the number of open databases increases the amount of memory needed for SQL Server overhead, reducing the memory available for the data (buffer) and procedure caches. Consequently, more physical memory may be required in order to maintain cache performance levels.
The locks parameter sets the number of available locks for SQL Server. Locks are used for concurrency control. The default value is set at 5000 locks.
Performance Impact: Each lock consumes 28 bytes of memory. Increasing the number of locks increases the amount of memory needed for SQL Server overhead, thereby reducing the memory available for the data (buffer) and procedure caches. Consequently, more physical memory may be required in order to maintain cache performance levels.
The open objects parameter sets the number of database objects that can be open at one time on SQL Server. The default is 500.
Performance Impact: Each open object requires 72 bytes of memory. Increasing the number of open objects increases the amount of memory needed for SQL Server overhead, thereby reducing the memory available for the data (buffer) and procedure caches. Consequently, more physical memory may be required in order to maintain cache performance levels.
The fill factor determines how full SQL Server will make each index page when creating new indexes. The default value is 0.
Performance Impact: The fill factor percentage affects SQL Server performance because SQL Server must split an index page when it becomes full. Thus, based on the previous discussion concerning index page storage structures, maintaining a small fill factor on an index that is associated with a very dynamic table will result in fewer page splits, fewer index entries per page, and a longer index page chain. Conversely, a high fill factor on a read-only table is perfectly acceptable, and results in full index pages and a shorter index page chain.
The time slice sets the number of times a user process is allowed to pass through a yield point without voluntarily yielding to the next process.
Performance Impact: If the time slice is set too low, SQL Server will spend too much time switching between processes. Conversely, if the time slice is set too high, waiting processes can experience long response time. The default of 100 is generally adequate and should seldom be changed.
The "max worker threads" parameter allows you to control the number of threads allocated to the pool of user threads. This can be useful when you have hundreds, or thousands, of user connections to SQL Server, and the overhead of managing hundreds or thousands of operating system threads would impair performance. When you limit the number of SQL Server working threads, user requests are executed on the next available worker thread. This parameter defaults to 255 and may be increased to 1024.
Performance Impact: When SQL Server starts, it checks the number of configured user connections against the configured maximum number of worker threads. If the number of configured user connections exceeds the value for max worker threads, SQL Server is configured for thread pooling. Otherwise, SQL Server is configured to use one thread per connection.
This option can improve performance when processing involves sorting, group by, or joins without supporting indexes. Allocating memory to tempdb effectively reduces the amount of memory available to allocate to the SQL Server data cache. Accordingly, you need enough physical memory to store the entire tempdb in RAM without affecting the memory required for Windows NT Server, SQL Server, and applications. Thus you should only consider using tempdb in RAM when you have large amounts of memory available. The default is off (0).
Performance Impact: Forcing tempdb into RAM may result in increased performance if a significant amount of processing involves the creation and use of "WORKTABLES" by the SQL Server optimizer. Execution of such processing in RAM is inherently faster than corresponding disk I/O from paging.
This parameter sets the maximum number of minutes per database that SQL Server needs in order to complete its recovery procedures in case of a system failure. In addition, this value is used along with the amount of activity on each database to calculate when to perform a checkpoint on each database.
Performance Impact: With the Lazywriter process available in SQL Server version 4.21a, it is no longer necessary to tune the checkpoint interval for optimum performance. In fact, you can set the recovery interval very high, to ensure that checkpointing occurs infrequently, when performance is important. Remember, however, that increasing the period between checkpoints also increases the time SQL Server takes to perform automatic recovery when the database is shutdown ungracefully (power failure, hardware failure, and so on).
See the SQL Server Configuration Guide for more details on sp_configure settings. It is recommended that you start with the default values, then experiment with changing parameter values once you have obtained a baseline of performance. When adjusting parameters to tune performance, adjust one parameter at a time and measure the difference in performance; changing multiple parameters in an ad-hoc fashion is generally not productive.
The following database options and SQL Server performance considerations are vitally important with respect to optimal SQL Server operation.
Don't use "trunc. log on checkpoint"—it causes a checkpoint and transaction log dump to occur every minute, and will adversely affect performance.
The Lazywriter's main task is to flush out batches of dirty, aged buffers (buffers that contain changes that must be written back to disk before the buffer can be reused for a different page) and make them available to user processes. The batch I/O size used by Lazywriter can be set by the "max async IO" parameter using the sp_configure stored procedure. This parameter controls both the checkpoint's and Lazywriter's batch I/O size, and can be tuned to maximize the I/O throughput for specific hardware platforms and I/O subsystems.
The Lazywriter process automatically starts flushing buffers when the number of available free buffers falls below a certain threshold, and stops flushing them when this number goes approximately 5 to 6 percent above the threshold. This threshold value is specified as a percentage of total number of buffers in the buffer cache. The default threshold is set to 3 percent of the buffers in the data cache, and should be sufficient in most situations. However, if necessary, the Lazywriter threshold can be modified using the bldmastr utility with the -y switch, as follows:
bldmastr -dc:\sql\data\master.dat -yLRUThreshold=<x>,
where x is a percentage of the size of the data cache (values between 1 and 40 are valid).
The physical database design is the physical manifestation of the logical database design that has been intelligently denormalized. This database design is then implemented on an optimally designed hardware platform. Accordingly, this section covers performance strategies associated with mapping the database design to the hardware resources.
When implementing the database design on the hardware platform, there are two basic performance strategies:
The selection of the appropriate strategy requires an understanding of database access patterns and the operational characteristics of the hardware resources, mainly memory and disk subsystem I/O. However, the following performance guidelines should help in selecting the appropriate physical implementation strategy:
Now that you have a solid database design implemented on the chosen hardware platform and knowledge of user expectations and applications, it is time to design queries and indexes. There are two critical aspects to achieving query and index performance goals on SQL Server: The first is to create queries and indexes based on knowledge of the SQL Server optimizer; the second is to use SQL Server performance features that enhance data access operations.
As stated, before you can design efficient queries and indexes, it is necessary that you understand the characteristics and operation of the SQL Server optimizer. The knowledge gained from this understanding will lead to the formulation of rules or guidelines for the construction of efficient queries and indexes.
The Microsoft SQL Server database engine uses a cost-based query optimizer to automatically optimize data manipulation queries that are submitted using SQL. (A data manipulation query is any query that supports the WHERE or HAVING keywords in SQL; for example, SELECT, DELETE, and UPDATE.) The cost-based query optimizer produces cost estimates for a clause based on statistical information.
This optimization is accomplished in three phases:
In the query analysis phase, the SQL Server optimizer looks at each clause represented by the canonical query tree and determines whether it can be optimized. SQL Server attempts to optimize clauses that limit a scan; for example, search or join clauses. However, not all valid SQL syntax can be broken into optimizable clauses; for example, clauses containing the SQL relational operator <> (not equal). Because <> is an exclusive rather than an inclusive operator, the selectivity of the clause cannot be determined before scanning the entire underlying table. When a relational query contains non-optimizable clauses, the execution plan accesses these portions of the query using table scans. If the query tree contains any optimizable SQL syntax, the optimizer performs index selection for each of these clauses.
For each optimizable clause, the optimizer checks the database system tables to see if there is an associated index useful for accessing the data. An index is considered useful only if a prefix of the columns contained in the index exactly matches the columns in the clause of the query. This must be an exact match, because an index is built based on the column order presented at creation time. For a clustered index, the underlying data is also sorted based on this index column order. Attempting to use only a secondary column of an index to access data would be similar to attempting to use a phone book to look up all the entries with a particular first name: The ordering would be of little use because you would still have to check every row to find all of the qualifying entries. If a useful index exists for a clause, the optimizer then attempts to determine the clause's selectivity.
In the earlier discussion on cost-based optimization, it was stated that a cost-based optimizer produces cost estimates for a clause based on statistical information. This statistical information is used to estimate a clause's selectivity (the percentage of tuples in a table that are returned for the clause). Microsoft SQL Server stores this statistical information in a specialized data distribution page associated with each index. This statistical information is updated only at the following two times:
To provide SQL Server with accurate statistics that reflect the actual tuple distribution of a populated table, the database system administrator must keep current the statistical information for the table indexes. If no statistical information is available for the index, a heuristic based on the relational operator of the clause is used to produce an estimate of selectivity.
Information about the selectivity of the clause and the type of available index is used to calculate a cost estimate for the clause. SQL Server estimates the amount of physical disk I/O that occurs if the index is used to retrieve the result set from the table. If this estimate is lower than the physical I/O cost of scanning the entire table, an access plan that employs the index is created.
When index selection is complete and all clauses have an associated processing cost that is based on their access plan, the optimizer performs join selection. Join selection is used to find an efficient order for combining the clause access plans. To accomplish this, the optimizer compares various orderings of the clauses and selects the join plan with the lowest estimated processing costs in terms of physical disk I/O. Because the number of clause combinations can grow combinatorially as the complexity of a query increases, the SQL Server query optimizer uses tree pruning techniques to minimize the overhead associated with these comparisons. When this join selection phase is complete, the SQL Server query optimizer provides a cost-based query execution plan that takes advantage of available indexes when they are useful and accesses the underlying data in an order that minimizes system overhead and improves performance.
Based on the information regarding the three phases of query optimization, it is obvious that designing queries that minimize physical and logical I/O, as well as balancing processor and I/O time, is the goal of efficient query design. In essence, this means you want to design queries that result in the use of indexes, result in the fewest disk reads and writes, and make the most efficient use of memory and CPU resources.
The following guidelines, which are derived from the optimization strategies of the SQL Server optimizer, will aid in the design of efficient queries. However, before we can discuss the query design guidelines, a couple of definitions are necessary:
Table Scan. A Table Scan occurs when the SQL Server optimizer can find no efficient index to satisfy a clause, or when a clause is non-optimizable. When the Table Scan method is used, execution begins with the first row in the table; each row is then retrieved and compared with the conditions in the WHERE clause, and returned to the front-end if it meets the given criteria. Regardless of how many rows qualify, every row in the table must be looked at, so for very large tables, a table scan can be very costly in terms of page I/Os.
Worktable. For some types of queries, such as those that require the results to be ordered or displayed in groups, the SQL Server query optimizer might determine that it is necessary to create its own temporary worktable. The worktable holds the intermediate results of the query, at which time the result rows can be ordered or grouped, and then the final results selected from that worktable. When all results have been returned, the worktable is automatically dropped.
The worktables are always created in the tempdb database, so it is possible that the system administrator might have to increase the size of tempdb to accommodate queries that require very large worktables. Because the query optimizer creates these worktables for its own internal use, the names of the worktables will not be listed in the tempdb.sysobjects table.
WHERE clauses that direct index selection should be of the following form:
<column> <operator> <constant> AND ...
or
<constant> <operator> <column> AND ...
where the operators are =, >, =, <, or = and all columns are in the same table.
A WHERE clause with BETWEEN is treated as a closed interval in the form:
<column> BETWEEN <constant> AND <constant>
generates
(<column> = <constant> AND <column> = <constant>)
A WHERE clause with LIKE and a trailing wild card is treated as a closed interval in the form:
<column> LIKE <constant%>
generates
(<column> = <constant> AND <column> < <constant>)
Expressions or data conversions in a WHERE clause are not likely to result in an index selection by the optimizer. Examples:
paycheck * 12 > 36000 or substring(city,1,1) = "C"
WHERE clauses with the "=" operator result in the best performance if a unique index is available. Closed intervals (ranges) are next best, while open intervals follow.
WHERE clauses that contain disjunctions (OR or IN) do not generally result in the best performance from a data access perspective. Thus, the optimizer may elect to use the "OR strategy." This results in the creation of a worktable that contains row IDs for each possible matching row. The optimizer considers these row IDs (page number and row number) to be a "dynamic index" pointing to a tables matching rows. Accordingly, the optimizer simply scans through the worktable, getting each row ID, and retrieving the corresponding rows from the data table. Consequently, the cost of the "OR strategy" is the creation of the worktable.
The SQL Server elects to use the "OR strategy" based on the following conditions:
If any other access plan will result in fewer I/Os (less cost), it will be used.
A WHERE clause containing NOT, <>, or != is not useful to the optimizer for index selection. This is due to the exclusive rather than inclusive nature of such clauses. Consequently, the selectivity of the clause can not be determined before scanning the entire underlying table.
Local variables in WHERE clauses are considered to be unknown and are not considered by the optimizer. The exception to this are variables defined as the input parameters of Stored Procedures.
Limit data conversions and string manipulations, as these are resource-intensive, especially when applied to large data sets.
Worktables are created by the SQL Server optimizer as follows:
Thus, except for SELECT INTO, attention must be paid to the size of the tempdb database, whether in RAM or on disk. In addition, if these types of operations are common, placing tempdb in RAM may be very beneficial to performance.
The importance of understanding concurrency issues is paramount to the efficient execution of queries on multi-user SQL Server systems. Dealing with concurrency and consistency issues in database queries and applications is an example of needing to understand and balance conflicting objectives.
These are competing requirements that need to be balanced against each other. SQL Server provides the means to ensure transaction consistency, or serializability, through locking. The most important concurrency guidelines to remember when designing efficient queries are as follows:
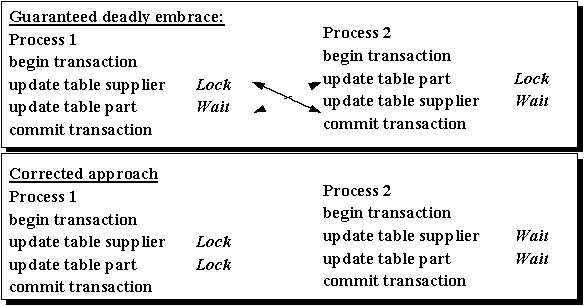
The diagram below illustrates how deadlocks can be unnecessarily introduced into an application when resources are not acquired in the same order.
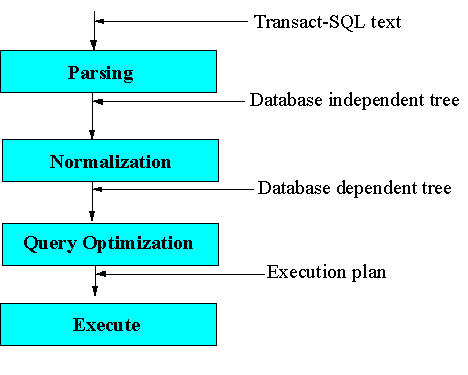
The diagram below gives a high-level overview of how stored procedures and Transact-SQL queries are handled by SQL Server.
Efficient index design is based on the understanding of the SQL Server optimizer, as well as the internal index storage structures and the queries that will access the data. Therefore, the following guidelines should be applied to the design of optimal indexes.
The following guidelines apply to the design of clustered indexes:
The following guidelines apply to the design of nonclustered indexes:
Efficiency of design is the key. Such a design philosophy is based on the following:
Basing query and index design on this knowledge will yield optimal performance of the queries used by user applications and the system.
Tuning the SQL Server solution should be much less difficult at this point because we have applied optimization guidelines throughout the solution development process. However, reality dictates that no implementation is performance-perfect. Consequently, the following section consists of tuning strategies for each of the SQL Server performance categories addressed in this paper. A prior understanding of the Windows NT Performance Monitor is required in order to apply some of the tuning strategies presented. Moreover, it is beyond the scope of this paper to address every possible tuning situation. Therefore, only those scenarios that have the greatest impact on performance are discussed.
All monitoring requires the use of the Windows NT Performance Monitor unless otherwise specified. In addition, all guidelines apply to dedicated SQL Server systems. However, these techniques can be applied to non-dedicated SQL Server systems with only slight modification. Please refer to Appendix A for further performance tuning references that may be of use.
The tuning of hardware resources typically involves the discovery of "bottlenecks." A bottleneck is the single resource that consumes the most time during a task's execution. In the case of SQL Server, such resource bottlenecks adversely affect the performance of normal relational database operations. The following information pertains to the detection of SQL Server resource bottlenecks and the subsequent adjustment of the resource in order to relieve the demand and increase performance.
Processor tuning involves the detection of CPU-bound operations. The following processor bottleneck monitoring guidelines can aid in determining such problems.
Symptoms and Actions
Symptom: If Processor: % Processor Time consistently registers in the range of 80% to 100%, the processor(s) may be the bottleneck. (System: % Total Processor Time can be viewed for multiprocessor systems.)
Action: If this occurs, you need to determine which SQL Server User process is consuming resources of the CPU. To determine which process is doing this, monitor the SQLServer-Users: CPUtime for all of the process instances (spid). One or more will appear as using the greatest cumulative time. Having determined the offending process instance, examine the query for inefficient design. In addition, examine indexes and database design for inefficiencies with respect to excessive I/O that consumes CPU cycles. (Wide tables and indexes cause more I/Os to occur than do table scans.)
Symptom: If Processor: % Privileged Time is consistently over 20% and Processor: % User Time is consistently low (below 80%), SQL Server is likely generating excessive I/O requests to the system.
Action: Examine the disk controller card and the network interface card. (See the section titled "General Actions," below.) In addition, if this is not a dedicated SQL Server system, look for other processes that meet the above criteria via Process: % Privileged Time and Process: % User Time. If you find such processes, eliminate them or schedule them to run at more convenient times.
General Actions for Processor Tuning
Memory tuning involves the detection of memory-constrained operations. The following memory bottleneck monitoring guidelines will aid in determining such problems.
Symptoms and Actions
Symptom: If the SQLServer: Cache Hit Ratio is less than 80%, memory may be a bottleneck.
Action: Either allocate more memory to SQL Server or increase the amount of system memory.
Symptom: If the SQLServer: I/O - Lazy Writes/sec counter indicates a great deal of activity over a long interval of time, a memory bottleneck may be the culprit. Typically this counter should be zero until the LRUthreshold (default 3%) is reached with respect to free buffer pages. However, frequent activity may indicate not enough memory is available for data page caching.
Action: Compare the SQLServer: Cache - Number of Free Buffers value against the LRUthreshold value. This value is derived by obtaining the total number of buffers allocated via the DBCC MEMUSAGE command, and multiplying this value by the LRUthreshold percentage (default 0.03). If the number of free buffers is close to the derived value, either allocate more memory to SQL Server or increase the amount of system memory.
If Memory: Page Faults/sec is consistently high (other than during SQL Server initialization), not enough memory is dedicated to Windows NT or possibly the system as a whole.
Action: Increase the system memory or increase the memory dedicated to Windows NT, by decreasing the memory allocated to SQL Server or other processes. You might also eliminate noncritical processes because these also use memory resources.
If SQLServer: I/O - Page Reads/sec is consistently high, it may indicate a memory bottleneck. Typically, if enough memory is available for database activities during normal operations, this counter will generally reach an equilibrium point. However, if this counter remains high over a long time interval, lack of sufficient memory may be causing excessive SQL Server page faults. This may be due to a less-than-adequate data cache, poor index design, or poor database design.
Action: Increase the memory allocated to SQL Server or decrease the procedure cache percentage, thereby increasing the data cache. If indexes are not being used, design intelligent indexes. If database tables are too wide, thus resulting in fewer data rows per data page, redesign the tables to be narrower.
If SQLServer: Cache - Ave. Free Page Scan or SQLServer: Cache - Max. Free Page Scan are over 10, a memory bottleneck due to excessive buffer scanning while searching for a free page may be indicated.
Action: Increase the data cache size or the frequency of checkpoints. Checkpoints can be increased via the recovery interval value or by manual execution.
General Actions for Memory Tuning
Disk subsystem tuning involves the detection of disk I/O constrained operations. Such bottleneck constraints may be caused by the disk controller, the physical disk drives, or lack of some other resource that results in excessive disk I/O-generating activity. Furthermore, poor disk subsystem performance may also be caused by poor index or database design. The goal is to operate the SQL Server with as few physical I/Os and associated interrupts as possible. The following disk I/O bottleneck monitoring guidelines will aid in achieving this goal.
Note In order to monitor low-level disk activity with respect to the PhysicalDisk Performance Monitor counters, it is necessary to enable the diskperf option. This can be accomplished by issuing the following command from the system prompt: diskperf -y. Running with this option enabled may result in a slight (0.1%-1.5%) degradation in performance, so disable it when it is not required for use (diskperf -n).
When performance-tuning the SQL Server disk subsystem, you should first attempt to isolate the disk I/O bottleneck with the SQLServer counters, using the PhysicalDisk and LogicalDisk counters for more detailed monitoring and refinement of an action plan.
Symptoms and Actions
Symptom: If SQLServer: I/O - Lazy Writes/sec is active for extended intervals, this may indicate that the disk subsystem is not adequate with respect to the current I/O demands. (Also see "Memory Bottleneck Symptoms.")
Action: Observing either LogicalDisk: Disk Queue Length or PhysicalDisk: Disk Queue Length can reveal significant disk congestion. Typically, a value over 2 indicates disk congestion. Increasing the number of disk drives or obtaining faster drives will help performance.
Symptom: If SQLServer: I/O Outstanding Reads and/or I/O Outstanding Writes are high for extended intervals of time, the disk subsystem may be a bottleneck.
Action: Observing either LogicalDisk: Disk Queue Length or PhysicalDisk: Disk Queue Length can reveal significant disk congestion. Typically, a value over 2 indicates disk congestion. Increasing the number of disk drives or obtaining faster drives will help performance.
Symptom: If SQLServer: Log Writes/sec seems to reach a maximum level, you may have encountered the maximum sequential write capability of the disk drives in the system. You will see this occur most frequently on systems that have a dedicated disk drive for logging. On systems without a dedicated log disk drive, you will observe a greater number of outstanding I/O requests, as discussed previously.
Action: Obtaining faster disk drives or disk controllers will help to improve this value.
General Actions for Disk I/O Tuning
Network tuning with respect to SQL Server performance is affected by the following:
Issues related to the throughput of the LAN or WAN are beyond the scope of this paper and are not critical to the tuning of a specific SQL Server. However, when considering remote procedure calls between SQL Servers or data replication, LAN and or WAN throughput will be an important concern. Thus, this section deals with tuning issues related to the network interface card and system or SQL Server resources that affect the SQL Server's network performance. The following network bottleneck monitoring guidelines deal with these issues.
Symptoms and Actions
Symptom: On a dedicated SQL Server system, if SQLServer: Network Reads/sec is substantially lower than Server: Bytes Received/sec, this may indicate network activity outside that generated by SQL Server. This may also be caused by periodic Windows NT administrative processes if the system also serves as a Primary Domain Controller or Backup Domain Controller.
Action: Determine if any processes or protocols extraneous to the operation of SQL Server are running. If so, eliminate them.
Symptom: On a dedicated SQL Server system, if SQLServer: Network Writes/sec is substantially lower than Server: Bytes Transmitted/sec, this may indicate network activity outside that generated by SQL Server. This may also be caused by periodic Windows NT administrative processes if the system also serves as a Primary Domain Controller or Backup Domain Controller.
Action: Determine if any processes or protocols extraneous to the operation of SQL Server are running. If so, eliminate them.
Symptom: If SQLServer: Network Reads/sec or SQLServer: Network Writes/sec is high, this indicates a great deal of network traffic.
Action: Look at the number of SQLServer: User Connections and the SQLServer: Network Command Queue Length. If these values are also high, especially Network Command Queue Length, consider increasing the number of available worker threads via sp_configure and/or increase memory allocated to SQL Server. However, you may wish to restrict user connections via sp_configure in order to decrease the workload on the SQL Server. Remember, user connections and worker threads are counted as overhead against the SQL Server memory allocation. Plan accordingly when adjusting these values.
General Actions for Network Tuning
Tabular data stream (TDS) is the application protocol used by SQL Server for the transfer of requests and request results between clients and servers. TDS data is sent in fixed-size chunks, called packets. TDS packets have a default size of 512 bytes. If an application does bulk copy operations, or sends or receives large amounts of text or image data, a packet size larger than 512 bytes may improve network performance, since it results in fewer reads and writes. For large data transfers, a packet size between 4092 and 8192 is usually best. Any larger size packet may degrade performance.
An application can change the packet size by using the DB-Library DBSETLOACKET() call. The packet size can also be changed while using the BCP and ISQL utilities, using the [/a packetsize] parameter. Increasing the packet size will only work for named pipes clients to Windows NT SQL Server.
You can monitor the improvement in network read and write efficiency by viewing the SQLServer: Network Reads/sec and SQLServer: Network Writes/sec counters before and after changing the TDS packet size. Fewer reads and writes should occur after increasing the packet size.
Make sure the server throughput is set to "Maximize Throughput for Network Applications"; this is the default for SQL Server. However, with this option set, users' applications access has priority over file cache access to memory (4 MB of memory is allocated to available memory for starting up and running local applications).
Increase Netlogon service update notice periods on the SQL Server if your SQL Server is a Primary Domain Controller (PDC). Also increase the server announcement period if you are concerned with the amount of maintenance traffic the Windows NT Server is creating and the load on the primary domain controller.
| Value Name | Default Value | Minimum Value | Maximum Value |
| PulseConcurrency | 20 | 1 | 500 |
| Pulse | 300 (5 minutes) | 60 (1 minute) | 3600 (1 hour) |
| Randomize | 1 (1 second) | 0 (0 seconds) | 120 (2 minutes) |
Pulse defines the typical pulse frequency (in seconds). All security accounts manager (SAM) and local security authority (LSA) (User/Security account database) changes made within this time are collected together. After this time, a pulse is sent to each Backup Domain Controller (BDC) needing the changes. No pulse is sent to a BDC that is up to date.
PulseConcurrency defines the maximum number of simultaneous pulses the PDC will send to BDCs.
Netlogon sends pulses to individual BDCs. The BDCs respond by asking for any database changes. To control the maximum load these responses place on the PDC, the PDC will only have PulseConcurrency pulses "pending" at once. The PDC should be sufficiently powerful to support this many concurrent replication remote procedure calls (RPCs) (related directly to Server service tuning as well as the amount of memory in the machine).
Increasing PulseConcurrency increases the load on the PDC. Decreasing PulseConcurrency increases the time it takes for a domain with a large number of BDCs to get a SAM/LSA change to all of the BDCs. Consider that the time to replicate a SAM/LSA change to all the BDCs in a domain will be greater than: (Randomize/2) * NumberOfBdcsInDomain) / PulseConcurrency.
If you need to transfer huge amounts of data between different computer systems, Ethernet may not be the appropriate medium to use because the basic Ethernet cable is limited to 10 MB per second (considerably less when you include network overhead). Other media are now available that offer significantly higher sustained transfer rates (FDDI, ATM, and others).
The Network Monitor (provided with Microsoft Systems Management Server) is a very good tool to use to monitor the general network performance. It offers additional Performance Monitor counters as well as a few unique statistics from within the application.
Match the network interface card to the system bus. If you have a 16-bit bus, use a 16-bit network adapter; if you have a 32-bit bus, use a 32-bit network adapter. In addition, the card should be a bus-master card in order to minimize the processing overhead associated with network interrupts.
Tuning the SQL Server involves appropriately adjusting the SQL Server configuration, options, and setup values based on observed operational characteristics. Typically these observations are made during peak work cycles in order to optimize for the heaviest work loads. The following tuning recommendations generally have the greatest impact on SQL Server performance. However, application of these recommendations may result in different outcomes, depending on your particular SQL Server environment.
As previously discussed, SQL Server memory is divided between SQL Server overhead, the procedure cache, and the data cache. The primary goal is to cover SQL Server overhead while effectively distributing the remaining memory between the procedure and data cache via the procedure cache configuration parameter. The distribution of the remaining memory between these caches is an exercise in making sure the most-used objects are cached in their respective caches. Hence, the most-used stored procedures should be in the procedure cache, while the majority of frequently-used indexes and tables should be in the data cache.
The best way to determine how memory is being used by SQL Server is to execute DBCC MEMUSAGE. This command will indicate the amount of memory allocated to SQL Server at startup, the 12 largest objects in the procedure cache, and the 20 largest objects in the data cache. The following recommendations are based on the use of this data and will aid in determining the optimal size for these caches.
Tuning the Procedure Cache
When tuning the procedure cache, your goal is to determine the optimal size for the purpose of holding the most active stored procedures as well as the other procedure cache data objects. In essence, you want to prevent reading stored procedures from the disk, because this is very costly. Moreover, if the procedure cache is large enough, it will prevent the displacement of procedures in the cache by procedures not yet in the cache. (Remember that the SQL Server will store a duplicate copy of each stored procedure execution plan, which is accessed by more than one user.) By default SQL Server distributes 20% of available memory to the procedure cache after SQL Server overhead has been allocated. The task is to determine if 20% is sufficient, not enough, or too much, based on the size of procedure cache objects.
You can determine if the procedure cache is large enough by executing the most-frequently-used stored procedures, and then running the DBCC MEMUSAGE command. The 12 largest stored procedures in the procedure cache will be displayed. If you have more than 12 stored procedures, you can continue to execute the other procedures, checking each time with the DBCC MEMUSAGE command to see if one of the previously executed procedures has remained cached. You can also execute each stored procedure, obtaining its execution plan size by using the DBCC MEMUSAGE command. Once you have executed all high-frequency procedures and obtained their sizes, add these size values to derive the total cache size necessary for all procedures.
Tuning the Data Cache
The data cache is composed of the memory left after SQL Server overhead and the procedure cache memory requirements have been satisfied. The goal is to have enough cache space to hold the majority of all indexes used, and a respectable percentage of the most-frequently-accessed tables, thus reducing physical I/Os.
You can also use the DBCC MEMUSAGE command to view the 20 largest objects in the data cache. Again, you can use this data in order to determine a respectable size for the data cache, based on the sizes indicated for these 20 database objects. You can also determine the size of the most-frequently-accessed tables and indexes, by applying the size formulas given in Appendix A of the SQL Server System Administrators Guide. Having calculated these sizes, you may elect to allocate enough memory to SQL Server in order to contain the entirety of these database objects in the data cache.
If the queries being executed against the SQL Server are using temporary workspace for sort operations, GROUP BY, temporary tables, multitable join operations, and so on, it will be beneficial to move tempdb to RAM. However, in order to make this move, you must have available enough memory over that which is already required by and allocated to Windows NT Server and SQL Server. Consequently, if the tempdb is currently 25 MB in size, then the total memory required on for the system is: 16 MB for Windows NTS + total SQL Server memory + 25 MB for tempdb.
Dedicated Multiprocessor Performance
If the hardware platform possesses multiple processors and the system will be dedicated to SQL Server, consider enabling the "Dedicated Multiprocessor Performance" option. This will increase SQL Server's performance substantially.
Boost SQL Server Priority
If you have not enabled the "Boost SQL Server Priority" option, doing so will allow SQL Server threads to run in the real-time priority class (16 - 31). Running at this priority level, SQL Server threads will be executed before all other process threads running in the lower variable priority class (1 - 15). This means that on single-processor machines under heavy load and not dedicated to SQL Server, other processes may be starved. However, if the system is dedicated to SQL Server and disk I/O activity tends to be heavy, enabling this option may result in substantial performance gains.
The database tuning process is based on performance observations gathered during normal SQL Server operations, typically at the time of peak work cycles. The symptoms that indicate possible database tuning is necessary usually consist of excessive disk I/O and/or excessive cache flushes. Both of these symptoms have been addressed earlier with respect to memory and disk I/O tuning. However, assuming that these SQL Server resources have been sufficiently tuned, it is now time to examine the database design and the mapping of the physical database to physical disk devices. (For more information, see the previous section on "Database Design and Performance.")
The following conditions indicate a need for table redesign:
Condition: The tables are very wide, resulting in fewer data rows fitting on a data page, so the data page chain is very long and requires a larger data cache to hold all required data. In addition, this circumstance may cause excessive physical page reads due to data cache limitations.
Action: Such tables are candidates for normalization or vertical segmentation. This will result in smaller tables and a greater number of data rows per data page, so data retrieval performance should improve, provided the data cache is sufficient. If this action is taken, be careful to account for the new design with respect to updates, inserts, and deletes. (See the previous section concerning logical database design for more information.)
Condition: The tables are huge, containing many rows of data, therefore not all relevant data may fit into the available data cache, resulting in excessive physical page reads from disk.
Action: Such tables are candidates for horizontal segmentation. Horizontal segmentation is most beneficial when only a subset of the data is normally accessed. In addition, fewer rows per table will result in faster retrievals when a table scan is involved. If this action is taken, be careful to account for the new design with respect to updates, inserts, and deletes. (See the previous section concerning logical database design for more information.)
Condition: The tables may contain variable length columns, thus increasing the table size due to the storage overhead associated with such data types.
Action: Look at all variable-length columns in order to determine if the data can be held by a smaller fixed-length data type. You can determine the table size differences by using the formulas in Appendix A of the SQL Server System Administrators Guide.
Condition: The tables may contain NULL columns, thus increasing the table size due to the storage overhead associated with such column types.
Action: Determine if the table columns that allow NULL values are necessary, or if a suitable data value can replace the NULL value. You can determine the table size differences by using the formulas in Appendix A of the SQL Server System Administrators Guide.
The following conditions should lead you to consider remapping the database to take advantage of more efficient disk I/O. However, such remapping means the physical rebuilding of the database. Therefore, the recommended actions should be considered carefully before proceeding.
Condition: Queries against a table that is very large and resides on the same physical device(s) or default segment as other frequently accessed tables is experiencing slow retrieval due to disk I/O congestion.
Action: Placing the table on a SQL Server segment that is mapped to a database device on one or more dedicated physical drives may improve performance. In fact, if the database device is mapped to a RAID 0 or RAID 5 partition that is controlled via a dedicated intelligent array controller, performance may be substantially increased. However, the creation of segments carries with it the potential for high administrative costs. It may be more cost-effective to simply enhance the disk subsystem components.
Condition: Queries against a very large table that resides on the same physical device(s) or default segment as its most-frequently-used index is experiencing slow retrieval due to disk I/O congestion.
Action: Placing the index and table on separate SQL Server segments that are mapped to separate database devices on one or more dedicated physical drives may improve performance. Furthermore, if the database devices are mapped to RAID 0 or RAID 5 partitions that are controlled by dedicated intelligent array controllers, performance may be substantially increased. However, the creation of segments carries with it the potential for high administrative costs. It may be more cost-effective to simply enhance the disk subsystem components.
Under most circumstances, if an efficient database design has been implemented on a suitable hardware platform, the SQL Server query optimizer will efficiently optimize most queries without concern for the structure of such queries, thereby resulting in exceptional performance. However, if a particular query is performing poorly and performance monitoring of critical system resources indicates no bottleneck problems, query and/or index tuning may be necessary. The following information consists of recommendations for tuning slow queries and inefficient indexes.
Analyzing a query is a process of elimination. Before you begin to dissect the structure of the SQL query, it is prudent to eliminate other contributing factors that may influence SQL query performance. Having eliminated these other factors, you can then analyze the structure of the query.
Views
SQL queries that access views may seem relatively simple in structure. Nonetheless, the actual view may be very complex in structure. Consequently, the view may need to be analyzed for poor performance before any queries that access it can be analyzed. Therefore, analyze the underlying SQL statement that constitutes the view, following the same recommendations for analysis and design as discussed in this paper.
Triggers
Slow query performance may also be attributed to the fact that a trigger may be defined for a table associated with the query. Accordingly, it may be the trigger that is performing slowly and not the query. However, trigger overhead is usually very low. The time involved in running a trigger is spent mostly in referencing other tables, which may be in the data cache or on the disk. In fact, the deleted and inserted tables are always in memory because they are logical tables. Hence, it is the location of other tables that may be causing physical page reads from disk that is the cause of slow performance.
Stored Procedures
The optimization of the search clause by the Query Optimizer is based on the set of values that are given when the stored procedure is first executed. The stored procedure then remains in cache and the query is not re-optimized each time it is executed. An assumption is therefore made that the first set of values used with the stored procedure is representative. If this is not the case, it is necessary to force a recompilation of the stored procedure. This can be done by executing WITH RECOMPILE, restarting SQL Server, or by executing the sp_recompile stored procedure.
Because stored procedures are not reentrant, if two processes execute a stored procedure concurrently, two copies of the stored procedure are compiled, optimized, and stored in cache. Multiple copies of the same stored procedure may have different query plans if parameter values passed to the stored procedure are very different. The copies stored in cache remain there until they are aged out of cache or until they are forced to recompile, either explicitly, by executing sp_recompile or restarting SQL Server, or implicitly, by dropping an index or table that is referenced by the stored procedure. (Stored procedures are automatically recompiled when objects or indexes on any of the tables used by the query plan are dropped. They are not recompiled when you add indexes or run UPDATE STATISTICS.)
Concurrency
A query may be performing slowly due to concurrency conflicts with other queries. In order to determine if concurrency problems do exist, observe if the query runs efficiently during some periods of the normal work cycle and slowly during others. If this behavior is exhibited, you should check the locking levels of other active SQL Server processes.
You can accomplish this by running the sp_who stored procedure in order to determine if the query being analyzed is being blocked by another process. You can then execute the sp_lock stored procedure to obtain more detail on the state of process locks with respect to the identified queries. There are also SQLServer-Locks performance monitor counters that are useful for determining the types of locks held systemwide. The most useful for determining if sever concurrency problems exist are Total Blocking Locks, Total Demand Locks, and any locks that are "Exclusive." If any of these values is high with respect to the number of executing query processes, a concurrency problem probably exists. (For more information on concurrency and consistency with regard to efficient query design, see the previous section, "Query and Index Design for Performance.")
SQL Query Structure Analysis
Other performance-limiting factors having been eliminated, you should now examine the structure of the SQL query. In addition, it is also appropriate to analyze if intelligent indexes are available for selection by the query optimizer. The following sequence of steps will aid in analyzing and fine-tuning the query and available indexes. (For more information on efficient query and index design, see the previous section, "Query and Index Design for Performance.")
Are There Unmatched Data Types?
Unmatched data types are an important consideration in evaluating slow queries to determine whether or not join clauses are comparing values of the same data type. A common problem is a join clause involving two character columns, where one column is defined as CHAR NOT NULL and the other as CHAR NULL defined internally as VARCHAR. The optimizer considers the two columns being joined as separate data types and therefore may not consider the clause as an optimizable one.
Are There Many String Operations or Data Conversions?
If there are a significant number of string operations or data conversions in the SQL statement, consider if they are more appropriate in the calling application. Extensive string manipulation and data conversions consume processor resources. On a heavily loaded SQL Server, this resource consumption may cause queries to execute more slowly.
Are Efficient Indexes Being Used?
Look at the table(s) being accessed by the query being analyzed, to determine if any indexes exist. You can access this information via the SQL Server Object Manager interface or by executing the sp_help stored procedure. If indexes do exist, do they meet the index selection and efficient design criteria discussed previously in the "Query and Index Design for Performance" section? Remember, the index must be considered "useful" by the optimizer before it can be selected.
Are the Existing Indexes Useful?
Is the query optimizer selecting any of the available indexes? To determine this, set the following Transact-SQL options on via the SQL Server Object Manager:
Once the query execution plan is available for viewing, check for references to "Using Clustered Index" or "Index: index name." If either of these is evident, the associated clustered or nonclustered index will be used for that portion of the query. If Table Scan is displayed, the query optimizer found it necessary to conduct a row-by-row sequential scan of the table due to lack of a useful index, or because such a scan is cheaper in terms of I/O processing than using an index.
Why Isn't the Optimizer Choosing an Index?
If the optimizer has indexes to choose from but does not select one, one of the following may be the cause:
Addressing these problems will generally result in more efficient queries. Nonetheless, if the distribution statistics are up-to-date and it appears that an index was appropriate, further investigation of the optimizer selection process is warranted.
What Is the Query Optimizer Thinking?
To obtain a more detailed description of the index selection criteria and join plan associated with a query, perform the following steps via ISQL/w or the SQL Server Object Manager interface:
The output from these steps will reveal the selection criteria for indexes, joins, and the number of plans considered for the query.
The Query Is Slow Even with an Index!
If the optimizer chooses an index and the query is still slow, the problem may be resource-oriented. Use the memory monitoring techniques discussed earlier to determine if excessive paging is occurring. If this is the case, you will need to review the size and makeup of the index. Remember, the smaller the index the better. Moreover, you may want to change the FILLFACTOR to pack more indexes into an index page. However, this may result in more frequent page splits, further decreasing performance.
Tune the Query
If after examining all the query execution plan data you come to the conclusion that the optimizer has chosen the best plan, you should now consider changing the query in order to generate a more efficient query execution plan. This may be accomplished by applying many of the techniques and strategies discussed in this paper. In addition, using the following commands will also help in tuning the query. These can be executed from the SQL Server Object Manager interface or ISQL/w.
If the query is still running slowly after query and index tuning, you should contact the appropriate support personnel to determine if a more serious problem exists. However, as a last resort you may want to try to force the order of a join via the SET FORCEPLAN ON command. This will force the optimizer to join the tables in the order dictated by the query.
The information in this document can be used to design and implement an optimal SQL Server solution. The primary goal, as presented, is to design as optimal a solution as possible early on in the solution development process, in order to decrease the level of tuning necessary during implementation. Accordingly, this paper has addressed the SQL Server optimization and tuning processes from a design and development point of view. It is now up to you to effectively apply this information to your own SQL Server environment, achieving the performance goals particular to your business needs.
For more information concerning optimization and performance tuning for Microsoft Windows NT and Microsoft SQL Server, please refer to the following sources:
Administrators Guide for Microsoft SQL Server for Windows NT, Microsoft Corporation
Configuration Guide for Microsoft SQL Server for Windows NT, Microsoft Corporation
Inside Windows NT, Helen Custer, Microsoft Press
Microsoft Developer Network Library (CD-ROM), Microsoft Corporation
Microsoft TechNet—Technical Information Network, Microsoft Corporation
Optimizing and Tuning Windows NT, Tech·Ed 95, NT301, Scott Suhy, Microsoft Corporation
Optimizing Windows NT, Windows NT Resource Kit, Volume 3, Russ Blake, Microsoft Press
Transact-SQL Reference for Microsoft SQL Server for Windows NT, Microsoft Corporation
Troubleshooting Guide for Microsoft SQL Server for Windows NT, Microsoft Corporation