
Steve Kirk
MSDN Content Development Group
October 1997
The effectiveness of a customer service system depends strongly on the technique used to match service requests to the personnel that serve those requests. Customers want prompt attention from the person with skills best suited to handle their request, while the service organization wants a scalable solution that optimizes the use of service personnel. In this article, I'll present a task distribution scheme, as used in the HelpDesk sample, that balances the conflicting goals of optimization and scalablity. The design performs constant optimization in that it seeks to gain the shortest possible response time and best use of personnel while it maintains the ability to scale to handle a high rate of requests. The sample is implemented in Microsoft® SQL Server™ version 6.5 using Transact-SQL. For a description of the HelpDesk system, see Robert Coleridge's article "The HelpDesk Sample: Overview of an Automated Solution."
The most important aspects of the task distribution problem in the HelpDesk application are as follows:
The response to the problem is to provide each technician with a supply of requests to resolve and to continuously adjust the supply to each technician based on the technician's current load.
Task distribution in the HelpDesk application is modeled by request entities in the request queue. Figure 1 shows the request data entity and the related technician data entity that is referenced by some of the task distribution procedures. The Request entity is uniquely identified by a primary key Id (PkId) and contains Priority (PriorityId) and Request Date (ReqDate) attributes, which are used to prioritize requests. Location (LocId) and Skill (SkillId) attributes are used to match the request with a qualified technician and the Status (StatusId) describes the state of the request toward resolution. The Technician (TechId) is the person that is responsible for resolution of the request. The Technician entity contains primary key (PkId), Location (LocId), and Skill (SkillId) attributes.
Figure 1. The HelpDesk Request and Technician entities
The request queue holds all requests that have not been resolved. Figure 2 shows the relationship between incoming requests, the request queue, and historical data. Requests are added (Insert) to the queue when customers use e-mail, voice mail, a Web application, or a traditional application to submit a request for help. The procedure that inserts the request initializes the distribution process by assigning the request to a technician. This initial distribution uses a round-robin technique that provides an even distribution of requests to matching technicians at a low computing cost. The initial distribution is then refined through a combination of action (or lack of action) by the technician and by the continuous optimizing process which shuffles unclaimed requests among technicians. While a request is in the request queue, its TechId and StatusId attributes are modified (Update) by the optimizing process and by technicians as they move the request toward resolution. Once resolved, requests are added (Insert) to historical data and removed (Delete) from the queue.
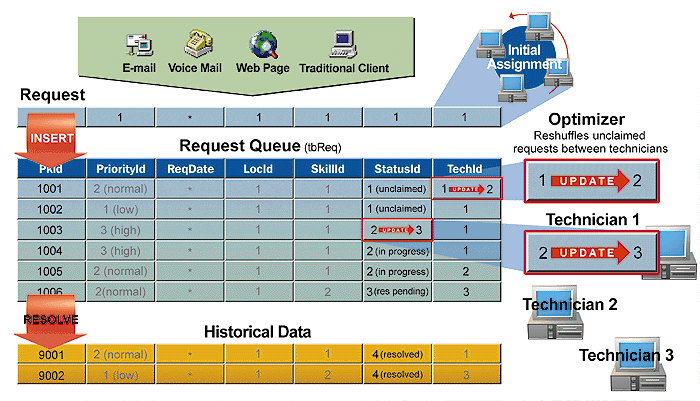
Figure 2. The HelpDesk task-distribution scheme
The initial distribution of requests to technicians happens when the request is inserted into the request queue. While it obviously doesn't make sense to spend many computing cycles making this assignment if the assignment is likely to change, the best reason for using an inexpensive algorithm here is to avoid a bottleneck in the request insertion procedure (pcIns_Req). The longer it takes pcIns_Req to execute, the more internal work SQL Server has to do to maintain data integrity.
The insert procedure, pcIns_Req, consists of the following steps:
This round-robin technique uses a table (tbCurTech) that tracks, for each combination of location (LocId) and skill (SkillId) attributes, the most recently assigned technician (TechId). When inserting a request, pcIns_Req uses this data to search for the next TechId in the technician table (tbTech) that matches the LocId and SkillId of the request. If the end of the table is reached before a matching TechId is found, the procedure returns to the beginning of the table and continues searching. If a match is still not found, the procedure drops the matching requirements and tries again. When a technician is found and assigned, his/her TechId is stored in tbCurTech according to the LocId and SkillId of the request. Here is the Transact-SQL code for pcIns_Req.
CREATE PROCEDURE pcIns_Req
@ReqDate datetime = NULL
,@LocId int
,@PriorityId int
,@SkillId int
,@EmailAlias varchar(12)
,@Description varchar(50) = NULL
AS
DECLARE @CurTechId int
DECLARE @TechId int
--Get most recently selected technician matching Location and Skill
SELECT @CurTechId=CurTechId FROM tbCurTech
WHERE (LocId = @LocId AND SkillId = @SkillId)))
--Get next TechId matching Location and Skill
SELECT @TechId = Min(TechId) FROM tbTech
WHERE (TechId > @CurTechId) AND (LocId = @LocId AND SkillId = @SkillId)
If @TechId Is NULL
--Get first TechId matching Location and Skill
SELECT @TechId = Min(TechId) FROM tbTech
WHERE LocId = @LocId AND SkillId = @SkillId
If @TechId Is NULL
--Get next TechId regardless of Location and Skill
SELECT @TechId = Min(TechId) FROM tbTech
WHERE TechId > @CurTechId
If @TechId Is NULL
--Get first TechId regardless of Location and Skill
SELECT @TechId = Min(TechId) FROM tbTech
--Store selected technician in tbCurTech
If NOT @TechId IS NULL
UPDATE tbCurTech
SET CurTechId=@TechId
WHERE LocId = @LocId AND SkillId = @SkillId
--Mark request as unclaimed
IF NOT @TechId IS NULL
SELECT @StatusId = 2
INSERT INTO tbReq
(
ReqDate
,LocId
,PriorityId
,SkillId
,StatusId
,TechId
,EmailAlias
,Descr
)
VALUES
(
@ReqDate
,@LocId
,@PriorityId
,@SkillId
,@StatusId
,@TechId
,@EmailAlias
,@Description
)
GO
Technicians see the requests that they have in progress as well as unclaimed requests that they tentatively own. Figure 3 shows the distribution of requests among technicians according to the TechId attribute in the request queue. A technician is able to browse the view and juggle multiple requests simultaneously rather than tackle requests in a strict serial (ordered by priority and date) manner. Although incoming requests are matched to technicians by skill and location attributes, the match is only a preliminary match. Technicians can refine the process by claiming requests that provide the best match and by leaving less well-matched requests to be reshuffled to other technicians by the optimizing process.
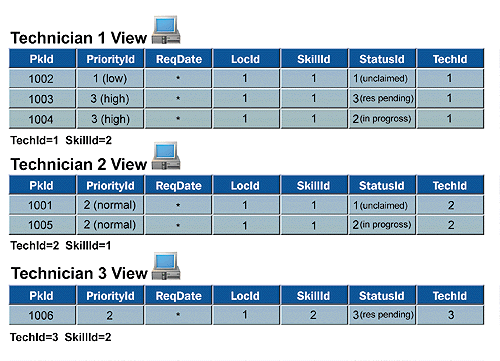
Figure 3. Request distribution—the technicians' views
The goal of the optimizing part of the system is to prevent unclaimed requests from waiting in a stalled technician's queue. The cure for the problem is to periodically stir the pot in an attempt to improve the chances for a quick resolution. The following algorithm is for a procedure called pcShuffle_Reqs that performs this optimizing.
For each unclaimed request in the request queue, attempt to reassign the request to a technician that has a lighter load of unclaimed requests.
Because pcShuffle_Reqs runs as a recurring scheduled task in Microsoft SQL Server, optimizing is a continuous process. To identify a technician that may be able to respond more quickly to a specific request, pcShuffle_Reqs uses a procedure called pcGetMostAvailableTech. The pcGetMostAvailableTech procedure works according to the following algorithm.
For the specified request, identify the technician with compatible Location and Skill attributes who has the fewest active requests.
The following code sample shows how pcGetMostAvailableTech is implemented in Transact-SQL:
CREATE PROCEDURE pcGetMostAvailableTech
@LocId int
, @SkillId int
, @TechId int OUTPUT AS
SET ROWCOUNT 1
SELECT @TechId=tbTech.TechId FROM tbTech,tbReq
WHERE tbTech.TechId <> @TechId
AND tbTech.LocId = @LocId
AND tbTech.SkillId = @SkillId
AND tbTech.TechId *= tbReq.TechId
AND tbReq.StatusId < 4
GROUP BY tbTech.TechId
ORDER BY Count(tbReq.PKid)
GO
The following code sample shows how pcShuffle_Reqs is implemented in Transact-SQL:
CREATE PROCEDURE pcShuffle_Reqs AS
DECLARE @OldId int
DECLARE @ReqId int
DECLARE @LocId int
DECLARE @SkillId int
DECLARE @TechId int
--Select the unclaimed request records
SET ROWCOUNT 1
SELECT @ReqId = PkId, @LocId = LocId,
@SkillId = Skillid, @TechId = TechId FROM tbReq
WHERE StatusId <= 2
--Process all records
WHILE NOT @ReqId IS NULL
BEGIN
SET ROWCOUNT 0
--Find the optimum for the request
EXEC pcGetMostAvailableTech @LocId, @SkillId, @TechId OUTPUT
--Reassign the request
IF NOT @TechId IS NULL
BEGIN
UPDATE tbReq
SET TechId=@TechId, StatusId=2
WHERE PkId = @ReqId
END
SELECT @OldId = @ReqId
SELECT @ReqId = NULL
SET ROWCOUNT 1
SELECT @ReqId = PkId, @LocId = LocId,
@SkillId = SkillId, @FromTechId = TechId FROM tbReq
WHERE PkId > @OldId AND StatusId <= 2
END
GO
I have not used transaction control in these procedures because they are designed to work with a COM API layer under Microsoft Transaction Server (MTS). MTS provides transaction support through the COM API, which would make internal transaction control redundant.
The phased task-distribution process (preliminary distribution followed by continuous optimization) employed here provides a way to avoid a direct conflict between the opposing requirements of query efficiency (optimization) and transaction throughput (scalability). This phasing allows each requirement to be addressed in its own context and at its own time with a minimum amount of conflict. This design is particularly appropriate for HelpDesk, where task duration is hard to predict and where tasks are not processed in a strict serial manner.
It should be fairly easy to substitute another distribution optimization procedure for the one I've provided here. When designing these procedures, consider that some problems are easier to solve in a procedural language such as Microsoft Visual Basic® than in a set-based language such as Transact-SQL. SQL Server procedures can create and control objects (written in Visual Basic or another procedural language) instantiated from automation compatible COM servers through the sp_OA series of system-stored procedures. The ability to control a COM object from SQL Server (that can in turn call back to a stored procedure in SQL Server) provides an attractive extension to Transact-SQL.