This section details how Oracle and SQL Server use ODBC and provides information about developing applications with ODBC.
Use the following process when you convert your application code from Oracle to SQL Server:
The Microsoft Open Database Connectivity (ODBC) interface enables you to create applications that are interoperable with multiple database systems. The ODBC SQL Server driver enables you to create ODBC client/server applications that take maximum advantage of Microsoft SQL Server and Oracle.
Microsoft offers a variety of support options to help you get the most from Microsoft SQL Server and ODBC. For information about these options, see the service and support information in your Microsoft SQL Server package and the online support information in the Microsoft Developer's Network.
In addition, you can get technical support information from the Microsoft Knowledge Base (KB). Information about the Knowledge Base (including how to get KB articles, how to get the KB on CD, and how to contribute to the KB) is available in the Help file Kb_msl.hlp, located in the \Mssql\Install directory.
There are many vendors for Oracle ODBC drivers. They include Oracle, Intersolv, Visigenic, Openlink, and others. Microsoft has licensed the source to the Oracle ODBC driver version 2.0 from Visigenic. A driver based on that source, called the Microsoft ODBC Driver for Oracle, is shipped with Microsoft Visual Studio™97. Oracle is no longer producing its own ODBC drivers and has licensed the rights to develop future ODBC drivers to Intersolv.
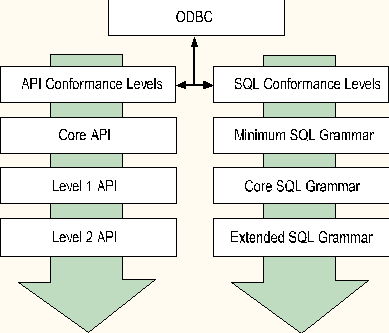
These different vendors offer varying levels of ODBC support. You must contact them directly to ensure that they support the ODBC conformance levels that your application requires. ODBC defines one set of conformance levels for the API and another set for the SQL grammar.
In order for an ODBC driver to claim conformance, it must provide support for all specified functionality at a given level. This must be done even if the DBMS does not support all of the capabilities for the specified level.
For more information about ODBC and its conformance levels, see the Microsoft ODBC 3.0 Programmer's Reference and SDK Guide.
Microsoft provides both 16-bit and 32-bit versions of its the ODBC SQL Server driver. The 32-bit ODBC SQL Server driver is thread safe. The driver serializes shared access by multiple threads to shared statement handles (hstmt), connection handles (hdbc), and environment handles (henv). However, the ODBC program is still responsible for keeping operations within statement and connection spaces in the proper sequence, even when the program uses multiple threads.
Because the ODBC driver for Oracle may be supplied by one of many possible vendors, there are many possible scenarios regarding architecture and operation. Again, you must contact the vendor to ensure that the ODBC driver meets your application requirements.
In most cases, the ODBC driver for Oracle uses SQL*Net to connect to the Oracle DBMS. SQL*Net may not be used, however, when connecting to Personal Oracle.
The illustration shows the application/driver architecture for 32-bit environments.
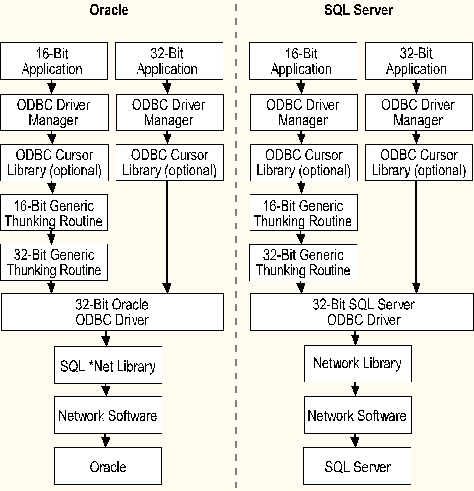
The term thunking means intercepting a function call, doing some special processing to translate between 16-bit and 32-bit code, and then transferring control to a target function. Note how the ODBC Cursor Library optionally resides between the driver manager and its driver. This library provides scrollable cursor services on top of drivers that just support forward-only cursors.
Oracle and SQL Server treat result sets and cursors differently. Understanding these differences is essential for successfully moving a client application from Oracle to SQL Server and having it perform optimally.
In Oracle, any result set from a SELECT statement is treated as a forward-only cursor when fetched in the client application. This holds true whether you are using ODBC, OCI, or Embedded SQL as your development tool.
By default, each Oracle FETCH command issued by the client program (for example, SQLFetch in ODBC) causes a round-trip across the network to the server to return one row. If a client application wishes to fetch more than one row at a time across the network, it must set up an array in its program and perform an array fetch.
Between fetches, no locks are held at the server for a read-only cursor, because of Oracle's multiversioning concurrency model. When the program specifies an updatable cursor with the FOR UPDATE clause, all of the requested rows in the SELECT statement are locked when the statement is opened. These row-level locks remain in place until the program issues a COMMIT or ROLLBACK request.
In SQL Server, a SELECT statement is not always associated with a cursor at the server. By default, SQL Server simply streams all the result set rows from a SELECT statement back to the client. This streaming starts as soon as the SELECT is executed. Result set streams can also be returned by SELECT statements within stored procedures. Additionally, a single stored procedure or batch of commands can stream back multiple result sets in response to a single EXECUTE statement.
The SQL Server client is responsible for fetching these default result sets as soon as they are available. For default result sets, fetches at the client do not result in round-trips to the server. Instead, fetches from a default result set just pull data from local network buffers into program variables. This default result set model creates an efficient mechanism to return multiple rows of data to the client in a single round-trip across this network. Minimizing network round-trips is usually the most important factor in client/server application performance.
Compared to Oracle's cursors, default result sets put some additional responsibilities on the SQL Server client application. The SQL Server client application must immediately fetch all the result set rows returned by an EXECUTE statement. If the application needs to present rows incrementally to other parts of the program, it must buffer the rows to an internal array. If it fails to fetch all result set rows, the connection to SQL Server remains busy.
If this occurs, no other work (such as UPDATE statements) can be executed on that connection until the entire result set rows are fetched, or the client cancels the request. Moreover, the server continues to hold share locks on table data pages until the fetch has completed. The fact that these share locks are held until a fetch is complete make it mandatory that you fetch all rows as quickly as possible. This technique is in direct contrast to the incremental style of fetch that is commonly found in Oracle applications.
SQL Server offers server cursors to address the need for incremental fetching of result sets across the network. Server cursors can be requested in an application by simply calling SQLSetStmtOption to set the SQL_CURSOR_TYPE option.
When a SELECT statement is executed as a server cursor, only a cursor identifier is returned by the EXECUTE statement. Subsequent fetch requests pass the cursor identifier back to the server along with a parameter specifying the number of rows to fetch at once. The server returns the number of rows requested.
Between fetch requests, the connection remains free to issue other commands, including other cursor OPEN or FETCH requests. In ODBC terms, this means that server cursors allow the SQL Server driver to support multiple active statements on a single connection.
Furthermore, server cursors don't usually hold locks between fetch requests, so you are free to pause for user input between fetches without impacting other users. Server cursors can be updated in place using either optimistic conflict detection or pessimistic scroll locking concurrency options.
While these features make programming with server cursors more familiar to Oracle developers, they don't come for free. Compared to default result sets:
For these reasons, it is wise to limit using server cursors to those parts of your application that need their features. An example illustrating the use of server cursors can be found in the LIST_STUDENTS function in the Ssdemo.cpp sample SQL Server ODBC program file.
The Oracle DBMS supports only forward-scrolling cursors. Each row is fetched to the application in the order it was specified in the query. Oracle does not accept requests to move backwards to a previously fetched row. The only way to move backwards is to close the cursor and reopen it. Unfortunately, you are repositioned back to the first row in the active query set.
Because SQL Server supports scrollable cursors, you can position a SQL Server cursor to any row location that you want. You can scroll both forward and backwards. For many applications involving a user interface, scrollability is a very useful feature. With scrollable cursors, your application can fetch a screen full of rows at a time, and only fetch additional rows as the user asks for them.
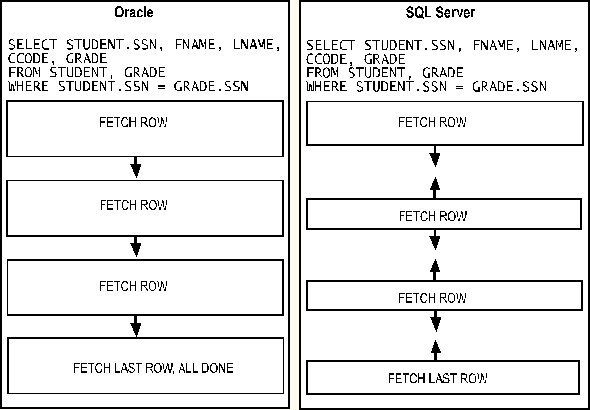
Although Oracle doesn't directly support scrollable cursors, this limitation can be minimized using one of several ODBC options. For example, some Oracle ODBC drivers, such as the one that ships with the Microsoft Developer Studio™, offer client-based scrollable cursors in the driver itself.
Alternatively, the ODBC Cursor Library supports block scrollable cursors for any ODBC driver that complies with the Level One conformance level. Both of these client cursor options support scrolling by using the DBMS for forward-only fetching, and caching result set data in memory or on disk. When data is requested, the driver retrieves it from the DBMS or its local cache as needed.
Client-based cursors also support positioned UPDATE and DELETE statements for the result sets generated by SELECT statements. The cursor library constructs an UPDATE or DELETE statement with a WHERE clause that specifies the cached value for each column in a row.
If you need scrollable cursors and are trying to maintain the same source code for both Oracle and SQL Server implementations, the ODBC Cursor Library is a useful option. To obtain more information about the OCBC Cursor Library, see the Microsoft ODBC 3.0 Programmer's Reference and SDK Guide.
With all of the options that SQL Server offers for fetching data, it's sometimes difficult to decide what to use and when. Here are some useful guidelines:
Grocery shopping provides a good analogy: Assume you purchase ten bags of groceries at the grocery store, load one bag into your car, drive home, drop it off, and return to the grocery store for the next bag. This is an unlikely scenario, but this is what you do to SQL Server and your program by making single-row fetches from a server cursor.
This strategy is not as difficult as it sounds. Most programmers know, for example, when they are issuing a singleton select that can return at most one row. For singleton fetches, using a default result set is more efficient than using a server cursor.
For an example of this technique, see the LIST_STUDENTS function in the Ssdemo.cpp sample SQL Server ODBC program file. Note how a server cursor is requested only if the SELECT statement may return more than one row. Following the execute step, the rowset size is set to a reasonable batch size. This allows the same SQLExtendedFetch loop to work efficiently in either the default result set or the server cursor case.
The ODBC driver uses a statement handle (hstmt) to track each active SQL statement within the program. The statement handle is always associated with a DBMS connection handle (hdbc). The ODBC driver manager uses the connection handle to send the requested SQL statement to the specified DBMS. Most ODBC drivers for Oracle allow multiple statement handles per connection. However, the SQL Server ODBC driver allows only one active statement handle per connection when using default result sets. The SQLGetInfo function of this SQL Server driver returns the value 1 when queried with the SQL_ACTIVE_STATEMENTS option. When statement options are set in a way that server cursors are used, multiple active statements per connection handle are supported.
For more information about how to set statement options to request server cursors, see Programming ODBC for Microsoft SQL Server.
The SQL Server ODBC driver offers a richer set of data type mappings than any available Oracle ODBC driver.
| SQL Server data type | ODBC SQL data type |
| binary | SQL_BINARY |
| bit | SQL_BIT |
| char, character | SQL_CHAR |
| datetime | SQL_TIMESTAMP |
| decimal, dec | SQL_DECIMAL |
| float, double precision, float(n) for n = 8-15 | SQL_FLOAT |
| image | SQL_LONGVARBINARY |
| int, integer | SQL_INTEGER |
| money | SQL_DECIMAL |
| numeric | SQL_NUMERIC |
| real, float(n) for n = 1-7 | SQL_REAL |
| smalldatetime | SQL_TIMESTAMP |
| smallint | SQL_SMALLINT |
| smallmoney | SQL_DECIMAL |
| sysname | SQL_VARCHAR |
| text | SQL_LONGVARCHAR |
| timestamp | SQL_BINARY |
| tinyint | SQL_TINYINT |
| varbinary | SQL_VARBINARY |
| varchar | SQL_VARCHAR |
It is important to note that the timestamp data type is converted to the SQL_BINARY data type. This is because the values in timestamp columns are not datetime data, but rather binary(8) data. They are used to indicate the sequence of SQL Server activity on the row.
The Oracle data type mappings for the Microsoft ODBC driver for Oracle are shown in the following table.
| Oracle data type | ODBC SQL data type |
| CHAR | SQL_CHAR |
| DATE | SQL_TIMESTAMP |
| LONG | SQL_LONGVARCHAR |
| LONG RAW | SQL_LONGVARBINARY |
| NUMBER | SQL_FLOAT |
| NUMBER(P) | SQL_DECIMAL |
| NUMBER(P,S) | SQL_DECIMAL |
| RAW | SQL_BINARY |
| VARCHAR2 | SQL_VARCHAR |
Note that Oracle ODBC drivers from other vendors may have alternative data type mappings.
The ODBC extended SQL standard provides SQL extensions to ODBC that support the advanced nonstandard SQL feature set offered in both Oracle and SQL Server. This standard allows the ODBC driver to convert generic SQL statements to Oracle- and SQL Server-native SQL syntax.
This standard addresses outer joins, such as predicate escape characters, scalar functions, date/time/timestamp values, and stored programs. The following syntax is used to identify these extensions:
--(*vendor(Microsoft), product(ODBC) extension *)--
OR
{extension}
The conversion takes place at run time and does not require the revision of any program code. In most application development scenarios, the best approach to take is to write one program and allow ODBC to perform the DBMS conversion process when the program is run.
The Oracle outer join syntax is not compatible with the SQL Server outer join syntax. If you use Oracle syntax when writing an outer join statement, you must revise it for SQL Server.
| Oracle | SQL Server |
| SELECT STUDENT.SSN, FNAME, LNAME, CCODE, GRADE FROM STUDENT, GRADE WHERE STUDENT.SSN = GRADE.SSN(+) |
SELECT STUDENT.SSN, FNAME, LNAME, CCODE, GRADE FROM STUDENT LEFT OUTER JOIN GRADE ON STUDENT.SSN = GRADE.SSN |
This revision could have been avoided by using the ODBC extended SQL outer join syntax. This example works with Oracle and SQL Server:
SELECT STUDENT.SSN, FNAME, LNAME, CCODE, GRADE
FROM {oj STUDENT LEFT OUTER JOIN GRADE ON STUDENT.SSN = GRADE.SSN}
ODBC provides five types of scalar functions:
Scalar functions can be used on columns of a result set and on columns that restrict rows of a result set. A good example of a scalar function is the SUBSTRING function, which returns a subset of a character string. The following ODBC scalar SUBSTRING function works with Oracle and SQL Server:
SELECT {fn SUBSTRING(LNAME,1,5)}
FROM STUDENT
If this scalar function is not used, you must write the following DBMS-specific program code for Oracle and SQL Server:
| Oracle | SQL Server |
| SELECT SUBSTR(LNAME,1,5) FROM STUDENT |
SELECT SUBSTRING(LNAME,1,5) FROM STUDENT |
ODBC provides three escape clauses for date, time, and timestamp values:
| Category | Shorthand syntax | Format |
| Date | {d 'value'} | "yyyy-mm-dd" |
| Time | {t 'value'} | "hh:mm:ss" |
| Timestamp | {Ts 'value'} | "yyyy-mm-dd hh:mm:ss[.f…]" |
This ODBC shorthand syntax can be generically applied to both Oracle and SQL Server:
SELECT SSN, FNAME, LNAME, BIRTH_DATE
FROM STUDENT WHERE BIRTH_DATE < {D '1970-07-04'}
It is worth noting that the format of dates has more of an impact on Oracle than it does on SQL Server. Oracle expects the date format 'DD-MON-YY'. If any other format is used, the TO_CHAR or TO_DATE functions must be used with a date format model to perform a format conversion.
SQL Server automatically converts most common date formats. The CONVERT function can be used for those situations where an automatic conversion cannot be performed.
This DBMS-specific syntax is required to use the date format shown in the previous example. Notice how a conversion function is not required with SQL Server.
| Oracle | SQL Server |
| SELECT SSN, FNAME, LNAME, BIRTH_DATE FROM STUDENT WHERE BIRTH_DATE < TO_DATE('1970-07-04', 'YYYY-MM-DD') |
SELECT SSN, FNAME, LNAME, BIRTH_DATE FROM STUDENT WHERE BIRTH_DATE < '1970-07-04' |
The following ODBC shorthand syntax is used for calling stored programs. It supports SQL Server procedures, and Oracle procedures, functions, and packages.
{?=} call procedure_name[(parameter(s))]}
The optional "?=" syntax is used to capture the return value for an Oracle function or a SQL Server procedure. The parameter syntax is used to pass and return values to and from the called program. In most situations, the same syntax can be generically applied to Oracle and SQL Server applications. This program code works with either DBMS:
SQLExecDirect(hstmt1,(SQLCHAR *)"{? = call DEPT_ADMIN.DELETE_DEPT(?)}",SQL_NTS);
Oracle packages introduce an exception to this rule. When calling a function or procedure that exists in a package, the package name must be placed in front of the program name.
In the following example, the SHOW_RELUCTANT_STUDENTS function is part of the Oracle package P1. This function must exist in a package because it returns multiple rows from a PL/SQL cursor. This code sample is extracted from the RELUCTANT_STUDENTS functions in the Oracle and SQL Server sample ODBC programs.
| Oracle | SQL Server |
| SQLExecDirect(hstmt1, (SQLCHAR*)"{? = call STUDENT_ADMIN.P1.SHOW_RELUCTANT _STUDENTS(?)}",SQL_NTS); |
SQLExecDirect(hstmt1, (SQLCHAR*)"{? = call STUDENT_ADMIN.SHOW_RELUCTANT _STUDENTS}",SQL_NTS); |
The SHOW_RELUCTANT_STUDENTS function in the package P1 uses a package cursor to retrieve multiple rows of data. Each row must be requested with a call to this function. If there are no more rows to retrieve, the function returns the value of 0, indicating that there are no more rows to retrieve.
Although this sample Oracle package and its function are capable of returning multiple rows of data, the resulting performance may be less than satisfactory. SQL Server procedures are much more efficient with this type of operation.
Because of the variety of ODBC drivers for both Oracle and SQL Server, you may not always get the same conversion string for the extended SQL functions. To assist with application debugging issues, you may want to consider using the SQLNativeSql function. This function returns the SQL string as translated by the driver.
The following are examples of what this function may return for the following input SQL string containing the scalar function CONVERT. The column SSN is defined as the type CHAR(9), and it is converted to a numeric value:
Original statement |
Converted Oracle statement |
Converted SQL Server statement |
| SELECT (fn CONVERT (SSN, SQL_INTEGER)} FROM STUDENT |
SELECT TO_NUMBER(SSN) FROM STUDENT |
SELECT CONVERT(INT,SSN) FROM STUDENT |
The Common.cpp sample program does not take advantage of the ODBC Extended SQL syntax. Rather, it employs a series of views and procedures to hide statements and functions that are not common between Oracle and SQL Server. This program, although written using ODBC, is intended to show how an application programmer can easily overcome any apparent hurdles when trying to write one common program.
These techniques and strategies are best employed in a non-ODBC development environment. If you are using ODBC, it is recommended that you seriously consider using the ODBC Extended SQL syntax to overcome any syntactical differences between Oracle and SQL Server.
Oracle automatically enters the transaction mode whenever a user modifies data. This must be followed by an explicit COMMIT to write the changes to the database. If a user wants to undo the changes, the user can issue the ROLLBACK statement.
By default, SQL Server automatically commits each change as it occurs. This is called autocommit mode in ODBC. If you do not want this to occur, you can use the BEGIN TRANSACTION statement to signal the start of a block of statements comprising a transaction. After this statement is issued, it is followed by an explicit COMMIT TRANSACTION or ROLLBACK TRANSACTION statement.
To ensure compatibility with your Oracle application, it is recommended that you use the SQLConnectOption function to place your SQL Server application in implicit transaction mode. The SQL_AUTOCOMMIT option must be set to SQL_AUTOCOMMIT_OFF in order to accomplish this. This code excerpt from the sample programs demonstrates this concept:
SQLSetConnectOption(hdbc1, SQL_AUTOCOMMIT,-sql_AUTOCOMMIT_OFF);
The SQL_AUTOCOMMIT_OFF option tells the driver to use implicit transactions. The default option SQL_AUTOCOMMIT_ON instructs the driver to use autocommit mode, in which each statement is committed immediately after it is executed. Changing from manual-commit mode to autocommit mode commits any open transactions on the connection.
If the SQL_AUTOCOMMIT_OFF option is set, the application must explicitly commit or roll back transactions with the SQLTransact function. This function requests a commit or rollback operation for all active operations on all statement handles associated with a connection handle. It can also request that a commit or rollback operation be performed for all connections associated with the environment handle.
SQLTransact(henv1, hdbc1, SQL_ROLLBACK);
(SQLTransact(henv1, hdbc1, SQL_COMMIT);
When autocommit mode is turned off, the driver issues SET IMPLICIT_TRANSACTIONS ON command to the server. Starting with SQL Server 6.5, DDL commands are supported in this mode.
To commit or roll back a transaction in manual-commit mode, the application must call SQLTransact. The SQL Server driver sends a COMMIT TRANSACTION statement to commit a transaction, and a ROLLBACK TRANSACTION statement to roll back a transaction.
The use of the manual commit mode may adversely affect the performance of your SQL Server application. Every COMMIT request requires a separate round-trip to the server to send the COMMIT TRANSACTION string.
If you have single atomic transactions (a single INSERT, UPDATE, or DELETE immediately followed by a COMMIT), you should use the autocommit mode, which is the SQL Server default. The only reason not to do this is to ensure absolute compatibility with Oracle and the way it handles transactions.
In the sample programs, the manual commit mode has been turned on, even for atomic transactions. The reason for this is was to demonstrate how easily a SQL Server application can be developed that closely mimics the operation of a similar application designed for the Oracle DBMS.