This section explains the differences between how Oracle and SQL Server handle replication.
If your Oracle application uses replicated data, you should understand the fundamental differences between Oracle and SQL Server replication architecture.
The Oracle DBMS offers the following replication models:
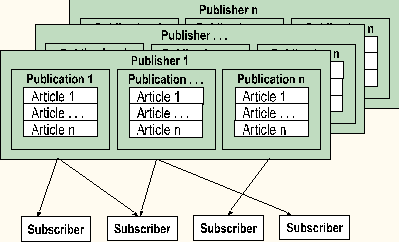
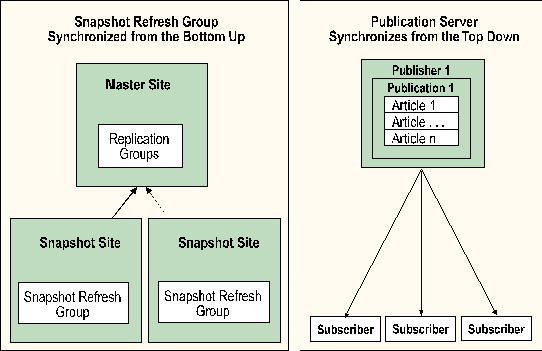
SQL Server offers a replication model that is analogous to publishing a magazine, filling it with articles, and mailing it out to registered subscription holders. Those receiving this publication have the option of receiving all of the articles, or they can selectively choose only those articles that they want to see. Potentially, there can be many publishers, each creating many publications.
SQL Server allows you to automatically distribute copies of transactional data from a single source server to one or more destination servers at one or more remote locations.
From an Oracle perspective, SQL Server offers the read-only snapshot model. It does not offer snapshot (subscriber) updates or multi-master table replication. However, subscriber updates can be performed in most applications by using table partitioning. This eliminates the danger of conflicts that can cause inconsistent data. Synchronous table replication can also be achieved by using remote stored procedures.
The SQL Server model offers the advantages of:
SQL Server replication has these fundamental characteristics:
SQL Enterprise Manager is used to manage the replicated SQL Server environment. A user can configure and manage a complete replicated environment spanning as many servers as necessary from a single location. The Oracle counterpart is the Oracle Replication Manager.
A publication server is a server that has made data available for replication. A publication server maintains publication databases, makes published data from those databases available for replication, and sends copies of all changes to the published data to the distribution server. It is also referred to as a publisher. A publication server is similar to an Oracle master site.
When a server is configured as a publisher, publication options must be set. The server publication options determine:
One or more publications can be created from each user database on a publication server. Tables, which are termed articles, are included as part of the publication. An article can include all of the rows and columns in a table, or it can include only a subset of columns and/or rows from the table. This is referred to as horizontal and/or vertical partitioning.
A publication can reside on only one server, and can contain articles from only one database. An article must always reside within the context of a publication. A given article cannot be placed into multiple publications, although multiple articles can be defined in such a way that the same base table can participate in multiple publications.
Subscribers are not allowed to modify the contents of an article. The contents of an article can only be modified at the publication site. This is not so limiting as it may sound, because a server can act as both subscriber and a publisher and secondary copies of data can be locally processed on the subscriber.
For example, a single table may be partitioned across multiple servers. The table can be horizontally partitioned, so that each server is the publisher of the data for particular rows and the subscriber to data for the remaining rows. Each server controls its own data and has a view of the other data. Remote stored procedures can be used to allow updates to remotely owned data only.
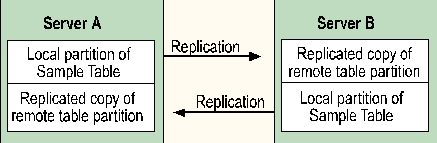
This replication configuration may be useful, for example, for maintaining common information at regionally dispersed centers, such as warehouses or divisional offices. It can also support regional order processing.
If you create an article that replicates only selected columns or rows of the base table, subscription servers receive only that partitioned subset of the data. If vertical partitioning is performed, the replicated columns must include the primary key columns.
The illustration shows the replication of the vertical and horizontal partitioning of the CLASS table. The replicated table displays only the CCODE and CNAME columns (vertical partitioning) for classes that are part of the business department (horizontal partitioning).
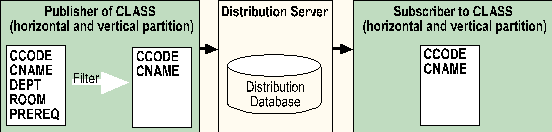
An article resembles a simple Oracle read-only snapshot. It is important to note that an article can support text and image columns, while an Oracle snapshot does not allow LONG or LONG RAW columns. An Oracle snapshot must be individually created and maintained at each snapshot site, while an article is centrally created and maintained at the publication site.
All of the articles within a publication are synchronized as a single logical unit. This helps to maintain integrity relationships originating from the underlying tables. One or more subscribers to a given publication always see the same data in the publication articles.
In Oracle, two identical snapshots (from the same master site table) at two separate snapshot sites may not contain the same data. This occurs because each snapshot site independently determines the initial load time and refresh interval for each snapshot. It is difficult to obtain an exact synchronization among multiple snapshot sites.
By default, an Oracle snapshot is refreshed independently of any other snapshot. An optional snapshot refresh group can be used to synchronize groups of snapshots and their data. The fundamental difference between a publication and a refresh group is that a publication and its articles are synchronized at the publication server, while in Oracle each snapshot refresh group synchronizes at the snapshot site.
The best way to describe the difference in approach is that SQL Server synchronizes from the top down, ensuring that all subscribers see the same data. Oracle snapshots are refreshed from the bottom up; this can cause variances in snapshot data as seen from each snapshot site.
In SQL Server, a distribution server is the server containing the distribution database. The distribution server receives all changes to published data, stores the changes in its distribution database, and, when appropriate, transmits them to subscription servers. It is also referred to as a distributor. There is no equivalent mechanism in Oracle.
The combination of the log-based mechanism and the capability to place a distribution database on a separate server allows SQL Server replication to scale extremely well to multiple subscribers. Additionally, the separate distribution database can substantially reduce the impact of multiple subscribers on the publishing site.
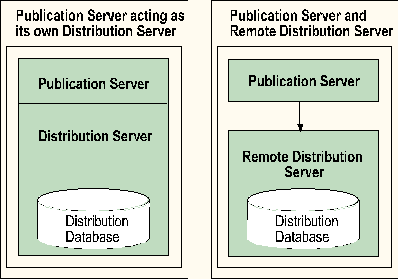
If a server participates in replication as a publisher, before any other replication options are set, you must define whether that publication server acts as its own distribution server or uses a remote distribution server. If it acts as its own distribution server, a distribution database must be installed. This is the most common scenario.
If a server acts as a remote distribution server for other publication servers, it must also have a distribution database installed. This must be set up before any dependent publication servers are set up. The server publication options must also be configured to define which publication servers are authorized to use it as a remote distribution server.
Using a separate distribution server reduces local processing and disk usage on the publication server, although it somewhat increases overall network traffic. Using a separate distribution server requires two SQL Server licenses, one for the publication server and one for the distribution server.
When a server requests a publication, it becomes a subscription server or subscriber. A subscriber can subscribe to some or all publications and to some or all articles within a publication.
An Oracle snapshot site is similar to a SQL Server subscriber. However, it is important to note the differences between Oracle and SQL Server. An Oracle snapshot must be defined at the snapshot site, while a SQL Server subscriber only needs to request a predefined published object.
Replicated data moves in one direction from the publication server to the subscription server. It is important to realize that this means the data should be treated as read-only for the users of the subscription databases. You must not set the read only database option, or the subscription database cannot receive replicated data.
Server subscription options must be set to determine which publication servers are permitted to replicate to the subscription server, and the destination databases on the subscription server that are permitted to subscribe to publications.
The illustration shows the flow of a publication (Publication 1) from the publication server to a subscription server. Notice how the publication flows through the distribution server.

The publishing and subscribing roles are not exclusive. A server can simultaneously perform both roles. For example, suppose Server A publishes Publication 1, and Server B publishes Publication 2. In this case, Server A could act as both a publication server (of Publication 1) and a subscription server (to Publication 2).

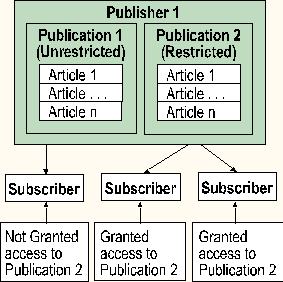
SQL Server replication offers great flexibility in determining exactly what sets of replicated data each subscriber receives. A subscriber can receive a selective subscription to publications. A subscription server can subscribe to none, some, or all of the publications offered by a publication server. A subscription server can also receive selective subscription to articles. It can subscribe to some or all of the articles within a publication.
Each publication has a security status of unrestricted (the default) or restricted. A publication marked as unrestricted is visible to and can be subscribed to by any registered subscription server. A publication marked as restricted is visible to and can be subscribed to by only those subscription servers that have been granted access.
The Oracle snapshot is synchronized when it is first created. The following objects are defined to support both initial and continued synchronization with the master table:
An Oracle snapshot process establishes a connection between the master site and the snapshot site. It performs a query against the master table and fills the snapshot table. The snapshot is then synchronized to the master site.
The SQL Server transaction log provides the same functionality as the combination of the snapshot trigger and snapshot log in Oracle. It is important to note that the performance of transactions at the Oracle master site can be substantially degraded by snapshot log triggers. In SQL Server there is no degradation because it already uses the log to track changes.
In SQL Server, each subscriber must be initially synchronized to a publication before receiving replicated data. This process ensures that the table schema and the table data in the publication and subscriber databases are identical. Replication ensures that updates are applied to a subscriber only after the subscriber is synchronized. Initial synchronization affects new subscribers only.
When a publication is first created a copy of the table schema is written to a file for transfer. If an index is requested, the index is defined as part of this schema. When synchronization begins, a snapshot is taken of the table data of the published article, and that snapshot is written to a file.
It is important that you do not confuse the SQL Server and Oracle terminology for a snapshot. An Oracle snapshot is an object that resides within the Oracle DBMS, while a SQL Server snapshot is simply a dump of table data written to an operating-system file.
The table schema is written to a file with a .sch extension, and the table data is written to a file with a .tmp extension. These files are stored in the working directory of the distribution database. The .sch and .tmp files are a synchronization set that represent a snapshot in time of that article. A synchronization set is created for each article within a publication.
After the synchronization set is created, any subsequent changes to the published data are captured but are not replicated to the subscriber until initial synchronization is complete. This ensures that updates are applied to a subscriber only after the subscriber has a current snapshot of the table schema and data.
When synchronization sets are distributed and applied to subscribers, only those subscribers waiting for initial synchronization are affected. Any other subscribers to that publication or related articles are unaffected. All the articles of a publication are synchronized simultaneously, preserving referential integrity between the underlying tables.
Initial synchronization can be performed automatically or manually. Automatic synchronization occurs on a scheduled basis. When a scheduled initial synchronization time arrives, synchronization occurs only for those subscribers that have requested synchronization since the last sync event occurred. This minimizes the impact on the publication server.
Manual synchronization is performed by the user. The publication server produces files containing a snapshot of the table schema and data from the published table, which are then applied to the subscriber database by a user. After manual synchronization is accomplished, the user must inform SQL Server that the synchronization is complete. Manual synchronization is particularly useful when the publication and subscription servers are connected by slow network connections or published tables are very large.
As an option, when setting up a subscription, you can specify that SQL Server will not synchronize the published articles with the destination tables. SQL Server assumes that they are already synchronized, and inserts, updates, deletes, or modifications to the published data are replicated to each subscriber as soon as the subscriptions are established.
In this case, it is the responsibility of the user setting up replication to ensure that the table schema and data are identical for the published article and the destination table. The advantage of this option is that it allows changes to replicated data to be immediately distributed to subscribers, without incurring the system overhead associated with synchronization. It is intended for advanced users who are implementing a custom replication solution.
The log reader copies transactions marked for replication from the publication server transaction log into the distribution database, where the transactions wait for distribution to subscription servers. Compare this to the Oracle snapshot process, which is used to copy data from the master site tables to the snapshot site snapshot tables.
The distribution database is a store-and-forward database that holds all transactions waiting to be distributed to subscription servers. It receives transactions sent to it from the publication server by the log reader process and holds them until the distribution process moves them to the subscription servers. The distribution process applies transactions and initial synchronization jobs held in the distribution database tables to the subscription servers. They are applied at the subscribers to the destination tables in the destination databases.
The log reader process, the synchronization process, and the distribution database all exist on the distribution server. They are subsystems of SQL Executive, and are not started or directly administered by users.
The illustration provides a functional overview of the replication components. It shows the publication and distribution servers as separate servers; however, one server can perform both roles.
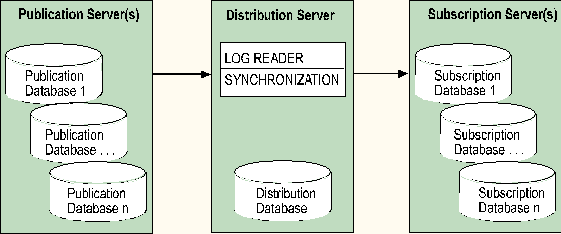
In a typical replication situation, the log reader process, the synchronization process, the distribution process, and the distribution database are installed on the publication server. However, these components can be installed on a separate server, which in some configurations can improve performance.
After the servers have been configured for replication and the source and destination data tables have been synchronized, a replication process (the log reader) monitors the transaction log of each database set up for replication. When a transaction occurs on a published table, it is marked for replication. When the log reader finds transactions marked for replication, it applies them to the distribution database. The transactions are held in the distribution database until they can be distributed to the appropriate destination servers and applied to the destination databases.
Only committed transactions are sent to destination servers. Replicated changes to a table are sent to the destination servers in the order in which they are committed. This ensures the subscribers receive transactions in the same order in which they were applied at the publisher. Because this is a log-based solution, maximum concurrent access to data is maintained. Replication does not exclude user access to destination tables during the associated inserts, deletes, and updates.
During normal operation, transactions marked for replication are preserved in a publication database's transaction log until they have been moved into the distribution database by the log reader. After this occurs, the transaction log of the publication database can be truncated using normal procedures. Records still waiting to be replicated are not truncated. The transaction log on the publisher can be dumped without interfering with replication, because only transactions not marked for replication are purged.
When setting up a subscription, you can specify that SQL Server synchronizes the published articles with the destination tables, and that the synchronization repeats at defined intervals. Incremental updates to the published data are not provided to the subscribers. This is called a scheduled table refresh. In effect, it is a repeating automatic synchronization, with replication of subsequent transactions turned off. This is similar in function to the refresh interval specified for Oracle snapshots and snapshot refresh groups. If you are seeking to closely duplicate an Oracle application that uses a single master site with multiple read-only snapshot sites, it is recommended that you consider this option.
A subscription server can be configured to accept push or pull subscriptions. The type of subscription is determined by the administrative focus, that is, on whether you are administering the publication server or the subscription server. Contrast this with an Oracle snapshot, which can only pull from the master site.
A push subscription is carried out when administrative focus is set on the publication server. As part of the process of creating or managing a publication, subscriptions are created by pushing out a publication or an article to one or more subscription servers. A push subscription helps to simplify and centralize subscription administration. The act of publishing is combined with the act of subscribing, and one person can perform both in the same administrative session. The need to separately administer each subscriber is eliminated. Another advantage is that for each publication, many subscribers can be set up at once.
A pull subscription is carried out when administrative focus is set on the subscription server. A subscription is created by pulling in a publication or an article from a publication server. One advantage of using pull subscriptions is that they provide a degree of replication autonomy for a subscription server. The SA or DBO of the subscription server can decide which publications are to be received. The subscriber avoids receiving unwanted data from a publication server. Another advantage is that for each subscription server, subscriptions from many publication servers can be set up during one administrative session.
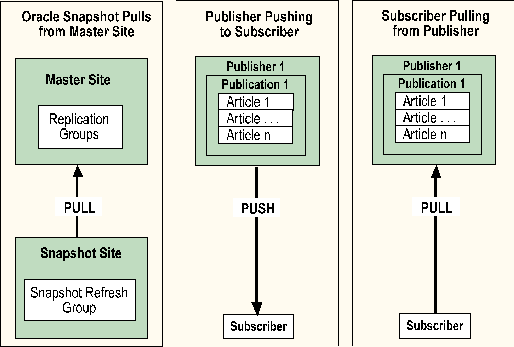
With pull subscriptions, the act of publishing is separate from the act of subscribing, and the user administering the subscription server need not be the same person who administers the publication server.
The NOT FOR REPLICATION option associated with column-level, foreign key, and check constraints prevents the specified constraint from being enforced for the distribution process used by replication. However, these constraints will be enforced for all other users, including the system administrator.
This option is used to protect horizontally partitioned tables that receive source data from a publishing server of data modifications to the replicated data. When replication is in effect, any modifications to the data that is replicated should be made on the publishing server and not on any of the subscribing servers.
The NOT FOR REPLICATION option is applied to both the before and after image of an updated record to prevent records from being added to or deleted from the replicated range. All deletes and inserts are checked; and if they fall within the replicated range, they are rejected.
Usually, when the log reader process encounters an INSERT, UPDATE, or DELETE statement that is in the transaction log of a publication database and is marked for replication, a single-row SQL statement is reconstructed from the recorded data changes. The replication processes then send that reconstructed SQL statement to each server that is subscribed to that article and apply the statement to the destination table in each destination database.
This is the default replication mechanism used by SQL Server. In most cases, it is the appropriate replication method. However, you have the option of customizing this process to meet specific replication requirements. You can specify custom processing for each type of statement (INSERT, UPDATE, or DELETE). If you specify custom processing, you must define a stored procedure that is called when the specified action takes place.
This performance-based feature adds a significant amount of flexibility. These replication stored procedures can be programmed to perform virtually any type of processing.
When the log reader encounters one of these statements in a transaction marked for replication, it constructs a stored procedure call. It passes the column values from the associated statement to the referenced stored procedure.
The capability to call a stored procedure makes SQL Server replication extremely flexible. The stored procedure can be programmed to do virtually anything. For example, a stored procedure can be used to maintain an aggregate summary table, rather than replicating all the detail rows of a published table. There is no comparable capability in Oracle.
A distribution server connects to all subscription servers as an Open Database Connectivity (ODBC) client. Replication requires that the ODBC 32-bit driver be installed on all distribution servers. The SQL Server Setup program automatically installs the necessary driver on Windows NT-based computers.
You do not need to preconfigure ODBC Data Sources for SQL Server subscription servers, because the distribution process simply uses the subscriber's network name to establish the connection.
SQL Server also includes an ODBC driver that supports Oracle subscriptions to SQL Server. The driver exists only for Intel-based computers. To replicate to Oracle ODBC subscribers, you must also obtain the appropriate Oracle SQL*Net driver from Oracle or from your software vendor.
If a password is provided in the NT Registry, then the Oracle ODBC driver connects to Oracle without requesting a password. If a password is not provided in the NT Registry, you must enter a username and a password for the Oracle ODBC data source when specifying the DSN in the New ODBC Subscriber dialog box of SQL Enterprise Manager.
ODBC drivers for Oracle are included on the SQL Server CD-ROM. Microsoft technical support supports problems encountered when using these drivers for replication. For information about Microsoft technical support options, see the service and support card included in your SQL Server package.
The table shows the data type mappings for replication to Oracle subscribers.
| SQL Server data type | Oracle data type |
| bit | NUMBER |
| tinyint | NUMBER |
| image | LONG RAW |
| varbinary | RAW |
| binary | RAW |
| timestamp | RAW |
| text | LONG |
| char | CHAR |
| numeric | NUMBER |
| decimal | NUMBER |
| money | NUMBER |
| smallmoney | NUMBER |
| int | NUMBER |
| smallint | NUMBER |
| float | FLOAT |
| real | FLOAT |
| datetime | CHAR(4) |
| smalldatetime | DATE |
| varchar | VARCHAR2 |
The following restrictions apply to replication to an Oracle ODBC subscriber:
Drivers for other ODBC subscriber types must conform to the Microsoft SQL Server replication requirements for generic ODBC subscribers. The ODBC driver: