This section highlights the significant differences between the Oracle and SQL Server database management systems.
Oracle database objects (tables, views, and indexes) can be migrated to SQL Server quite easily because each DBMS closely follows the ANSI standard regarding object definitions. To convert Oracle SQL table, index, and view definitions to SQL Server table, index, and view definitions requires relatively simple syntax changes.
However, it is recommended that you understand the advantages SQL Server has to offer.
| Category | SQL Server | Oracle |
| Number of columns | 250 | 254 |
| Row size | 1962 bytes (this does not include text or image columns) | Unlimited (only one long or long raw allowed per row) |
| Maximum number of rows | Unlimited | Unlimited |
| Blob type storage | Any number of image or text columns per row, only 16-byte pointer stored with row, data stored on other data pages | One long or long raw per table, must be at end of row, data stored on same block(s) with row |
| Clustered table indexes | 1 per table | 0 |
| Nonclustered table indexes | 249 per table | Unlimited |
| Maximum number of indexed columns in single index | 16 | 16 |
| Table naming convention | [[database.]owner.]table_name | [schema.]table_name |
| View naming convention | [[database.]owner.]table_name | [schema.]table_name |
| Index naming convention | [[database.]owner.]table_name | [schema.]table_name |
It is assumed that you are starting with an Oracle SQL script or program that is used to create your database objects. Simply copy this script or program and make the following modifications. Each change is discussed throughout the rest of this section. The examples have been taken from the sample application scripts Oratable.sql and Sstable.sql.
This process is performed as follows:
The object naming conventions are similar for each DBMS.
| Oracle | SQL Server |
| 1-30 characters in length (Oracle database names can be a maximum of 8 characters, database link names can be a maximum of 128 characters.) | 1-30 characters in length (temporary objects names should not exceed 13 characters in length.) |
| Identifier names must begin with an alphabetic character and contain alphanumeric characters, or the characters _, $, and #. | Identifier names must begin with an alphabetic character or one of three symbols (_, @, #), and contain alphanumeric characters, or the characters _, $, and #. Additionally, an object beginning with @ is defined as a local variable; an object beginning with a single # defines a local temporary object, and an object beginning with two ## defines a global temporary object. |
| Tablespace names must be unique. | Database names must be unique. |
| Identifier names must be unique within user accounts (schemas), and column names must be unique within tables and views. | Identifier names must be unique within database user accounts, and column names must be unique within tables and views. |
| Index names must be unique within a users schema. | Index names must be unique within database table names. |
In most cases, you do not need to change the names of your objects when migrating to SQL Server. SQL Server indexes are the exception (unlike Oracle, the index name is associated directly with the table).
| Oracle | SQL Server |
| CREATE INDEX STUDENT_ADMIN.STUDENT_ MAJOR_IDX ON STUDENT_ADMIN.STUDENT(MAJOR) |
CREATE NONCLUSTERED INDEX STUDENT_ MAJOR_IDX ON STUDENT_ADMIN.STUDENT (MAJOR) |
When accessing tables that exist in your Oracle user account, the table can be simply selected by its unqualified name (for example, SELECT * FROM STUDENT). When accessing tables that exist in other schemas, the schema name must be prefixed to the table name with a single period (SELECT * FROM STUDENT_ADMIN.STUDENT).
A public or private synonym is often used to eliminate the need to specify a username when requesting a table in another schema. Synonyms, however, can slow the performance of a query, because Oracle must perform additional queries against the data dictionary to resolve the table name.
Synonyms cause additional problems. If you own a table called STUDENT in your account, and there is a public synonym for the STUDENT table owned by another schema, you may not get the data you expect. If you request the table by its unqualified name (SELECT * FROM STUDENT) you get data from your own table. It is often necessary to fully qualify a requested table name even when a public synonym exists.
It is also important to note that SQL Server does not provide public or private synonyms. SQL Server uses a slightly different convention when it references tables. Keep in mind that one SQL Server login account can create a table by the same name in multiple databases. Therefore, the following convention is required when requesting access to tables:
[[database_name.]owner_name.]table_name
This is an example of the syntax:
SELECT * FROM USER_DB.STUDENT_ADMIN.STUDENT
Using the database name and username is optional. When a table is referenced only by name (for example, STUDENT), SQL Server searches for that table in the current users account in the current database.
Every connection to SQL Server has a current database context, set at login time and changed using the USE statement. For example, if the ENDUSER1 account is currently logged into the USER_DB database, SQL Server searches for the table ENDUSER1.STUDENT. If SQL Server finds the table STUDENT in the ENDUSER1 account, it returns data from the table (USER_DB.ENDUSER1.STUDENT). If the table is not found in the ENDUSER1 database account, SQL Server searches for the table in the DBO account for that database. If it is found, data is returned from that table (USER_DB.DBO.STUDENT).
If the table is not found in either of these accounts, SQL Server returns an error message indicating the table does not exist. If the table was created in another user's account in the USER_DB database, (for example, DEPT_ADMIN), the table name must be prefixed with the database user's name (DEPT_ADMIN.STUDENT).
If the referenced table exists in another database, the database name must be used as part of the reference. For example, if the ENDUSER1 account owned the table STUDENT in the OTHER_DB database, the database name must be included as part of the request (OTHER_DB.ENDUSER1.STUDENT).
When this type of reference is used, SQL Server looks for the table STUDENT in the ENDUSER1 account in the DEPT_DB database. If it finds it, data is returned from the table. Note the syntax and its usage. The database and usernames are optional. If the database name and table names are provided separated by two periods (STUDENT_DB..STUDENT), SQL Server first searches the database user's account corresponding to the current login ID, and the DBO account second.
It is important to note that table names must be unique within a user's account within a database. The same SQL Server login account can potentially use the same object name across multiple databases. For example, the ENDUSER1 account may own the following database objects:
At the same time, other users in these databases may own objects by the same name:
Therefore, when an object name is referenced, it is recommended that you include the owner name as part of the reference. If the application involves multiple separate databases, the database name should also be included as part of the reference.
If the application involves only a single database, omitting the database name from an object reference makes it easy to migrate the application to another database with a different name. This is useful when you want to maintain a test database and a production database on the same server.
The CREATE TABLE syntax for each DBMS is similar. Both Oracle and SQL Server support ANSI-standard naming conventions for identifying DBMS objects.
| Oracle | SQL Server |
| CREATE TABLE [schema.]table_name ( {col_name column_properties [default_expression] [constraint [constraint [...constraint]]]| [[,] constraint]} [[,] {next_col_name | next_constraint}...] ) [Oracle Specific Data Storage Parameters] |
CREATE TABLE [database.[owner].]table_name ( {col_name column_properties[constraint [constraint [...constraint]]]| [[,] constraint]} [[,] {next_col_name | next_constraint}...] ) [ON segment_name] |
When referring to objects in Oracle, the use of case is not important. This can cause potential problems when converting Oracle applications. In SQL Server, table and column names can be case sensitive, depending on the character sort order that is installed. When SQL Server is first set up, the default sort order is dictionary order, case-insensitive. (This can be configured differently using SQL Server Setup.)
In SQL Server, the case (upper- or lowercase) of letters can influence object names and should be considered when developing applications. It is recommended that you capitalize all table and column names in both Oracle and SQL Server to avoid problems.
The primary difference between Oracle and SQL Server is how each uses data storage parameters when creating tables and indexes. The parameters used by Oracle are not supported by SQL Server, and vice versa. However, in SQL Server, using RAID usually simplifies the table- and index-definition process. The SQL Server table simply uses RAID to control its placement. Note that a clustered index is integrated into the structure of the table. A separate, nonclustered index is also defined for the table.
| Oracle | SQL Server |
| CREATE TABLE DEPT_ADMIN.DEPT ( DEPT VARCHAR2(4) NOT NULL, DNAME VARCHAR2(30) NOT NULL, CONSTRAINT DEPT_DEPT_PK PRIMARY KEY (DEPT) USING INDEX TABLESPACE USER_DATA PCTFREE 0 STORAGE (INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED), CONSTRAINT DEPT_DNAME_UNIQUE UNIQUE (DNAME) USING INDEX TABLESPACE USER_DATA PCTFREE 0 STORAGE (INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED) ) PCTFREE 10 PCTUSED 40 TABLESPACE USER_DATA STORAGE (INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED FREELISTS 1) |
CREATE TABLE USER_DB.DEPT_ADMIN.DEPT ( DEPT VARCHAR(4) NOT NULL, DNAME VARCHAR(30) NOT NULL, CONSTRAINT DEPT_DEPT_PK PRIMARY KEY CLUSTERED (DEPT), CONSTRAINT DEPT_DNAME_UNIQUE UNIQUE NONCLUSTERED (DNAME) ) |
The table provides a comparison of the syntax used to define referential integrity constraints.
| Constraint | Oracle | SQL Server |
| PRIMARY KEY | [CONSTRAINT constraint_name] PRIMARY KEY (col_name [, col_name2 [..., col_name16]]) [USING INDEX storage_parameters] |
[CONSTRAINT constraint_name] PRIMARY KEY [CLUSTERED | NONCLUSTERED] (col_name [, col_name2 [..., col_name16]]) [ON segment_name] [NOT FOR REPLICATION] |
| UNIQUE | [CONSTRAINT constraint_name] UNIQUE (col_name [, col_name2 [..., col_name16]]) [USING INDEX storage_parameters] |
[CONSTRAINT constraint_name] UNIQUE [CLUSTERED | NONCLUSTERED](col_name [, col_name2 [..., col_name16]]) [ON segment_name] [NOT FOR REPLICATION] |
| FOREIGN KEY | [CONSTRAINT constraint_name] [FOREIGN KEY (col_name [, col_name2 [..., col_name16]])] REFERENCES [owner.]ref_table [(ref_col [, ref_col2 [..., ref_col16]])] [ON DELETE CASCADE] |
[CONSTRAINT constraint_name] [FOREIGN KEY (col_name [, col_name2 [..., col_name16]])] REFERENCES [owner.]ref_table [(ref_col [, ref_col2 [..., ref_col16]])] [NOT FOR REPLICATION] |
| DEFAULT | Column property, not a constraint DEFAULT (constant_expression) |
[CONSTRAINT constraint_name] DEFAULT {constant_expression | niladic-function | NULL} [FOR col_name] [NOT FOR REPLICATION] |
| CHECK | [CONSTRAINT constraint_name] CHECK (expression) |
[CONSTRAINT constraint_name] CHECK [NOT FOR REPLICATION] (expression) |
| NULL, NOT NULL |
[CONSTRAINT constraint_name] NULL | NOT NULL |
Column property, not a constraint |
The NOT FOR REPLICATION clause is used to suspend column-level, FOREIGN KEY, and CHECK constraints during replication. For more information, see "SQL Server Replication" later in this paper.
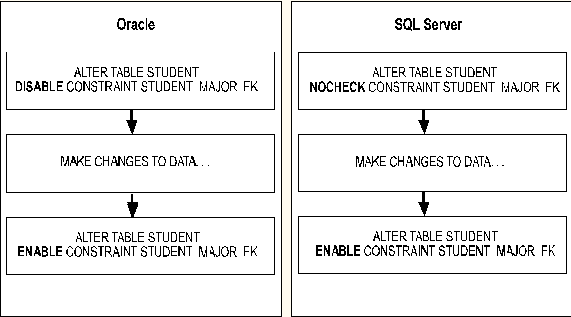
Disabling constraints can improve performance and streamline the data replication processes. For example, when you rebuild or replicate table data at a remote site, you do not have to repeat constraint checks, because the integrity of the data was checked when it was originally entered into the table. If your Oracle application currently disables and enables constraints (except for PRIMARY KEYand UNIQUE), this process can be easily duplicated in SQL Server using the CHECK and WITH NOCHECK options with the ALTER TABLE statement.
This illustration shows a comparison of this process.
You can defer all constraints for the table, including the CHECK and FOREIGN KEY constraints, by using the ALL keyword. However, you cannot defer PRIMARY KEY and UNIQUE constraints because these constraints must be dropped.
If your Oracle application disables or drops PRIMARY KEYor UNIQUE constraints using the CASCADE option, you may need to rewrite some of your program code. This is because the CASCADE option disables or drops both the parent and any related child integrity constraints.
This is an example of the syntax:
DROP CONSTRAINT DEPT_DEPT_PK CASCADE
SQL Server does not support this cascading capability. The SQL Server application must be modified to first drop the child constraints followed by the parent constraints. For example, in order to drop the PRIMARY KEY constraint on the DEPT table, the foreign keys for the columns STUDENT.MAJOR and CLASS.DEPT must be dropped. This is an example of the syntax:
ALTER TABLE STUDENT
DROP CONSTRAINT STUDENT_MAJOR_FK
ALTER TABLE CLASS
DROP CONSTRAINT CLASS_DEPT_FK
ALTER TABLE DEPT
DROP CONSTRAINT DEPT_DEPT_PK
The ALTER TABLE syntax that is used to add and drop constraints is almost identical for Oracle and SQL Server. If care is taken, you can write program code that works with both Oracle and SQL Server and requires minimal modification.
Regardless of the DBMS you are using, it is recommended that you always name your constraints. The constraint naming convention is the same for Oracle and SQL Server:
CONSTRAINT constraint_name
If you do not name your constraints, each DBMS names them for you. Because Oracle and SQL Server use different default naming conventions, the differences can unnecessarily complicate your migration process. The discrepancy would appear when dropping or disabling constraints, because they must be dropped by name (see the previous section, "Adding and Removing Constraints").
The ANSI standard requires that all values in a primary key are unique and that it does not allow null values. Both Oracle and SQL Server enforce uniqueness by automatically creating unique indexes whenever a PRIMARY KEY or UNIQUE constraint is defined. Additionally, primary key columns are automatically defined as NOT NULL. Only one primary key is allowed per table.
A SQL Server clustered index is created by default for a primary key. A nonclustered index can also be requested. The Oracle index can be removed by either dropping or disabling the constraint, whereas the SQL Server index can only be removed by dropping the constraint.
In either DBMS, alternate keys can be defined using a UNIQUE constraint. Multiple UNIQUE constraints can be defined on any table. UNIQUE constraint columns can be nullable. In SQL Server, a nonclustered index is created by default, unless specified otherwise.
When migrating your application, it is important to note that SQL Server allows only one row to contain the value NULL for the complete unique key (single or multiple column index), while Oracle allows any number of rows to contain the value NULL for the complete unique key.
| Oracle | SQL Server |
| CREATE TABLE DEPT_ADMIN.DEPT (DEPT VARCHAR2(4) NOT NULL, DNAME VARCHAR2(30) NOT NULL, CONSTRAINT DEPT_DEPT_PK PRIMARY KEY (DEPT) USING INDEX TABLESPACE USER_DATA PCTFREE 0 STORAGE ( INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED), CONSTRAINT DEPT_DNAME_UNIQUE UNIQUE (DNAME) USING INDEX TABLESPACE USER_DATA PCTFREE 0 STORAGE ( INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED) ) |
CREATE TABLE USER_DB.DEPT_ADMIN.DEPT (DEPT VARCHAR(4) NOT NULL, DNAME VARCHAR(30) NOT NULL, CONSTRAINT DEPT_DEPT_PK PRIMARY KEY CLUSTERED (DEPT), CONSTRAINT DEPT_DNAME_UNIQUE UNIQUE NONCLUSTERED (DNAME) ) |
Oracle treats a default as a column property, while SQL Server treats a default as a constraint. The SQL Server DEFAULT constraint can contain constant values, built-in functions that do not take arguments (niladic-functions), or NULL.
Because you cannot apply a constraint name to the Oracle DEFAULT column property, it is recommended that you define DEFAULT constraints at the column level in SQL Server and do not apply constraint names to them. SQL Server simply generates a unique name for each DEFAULT constraint.
The syntax used to define CHECK constraints is the same in Oracle and SQL Server. The search condition must evaluate to a Boolean expression and cannot contain subqueries. A column-level CHECK constraint can reference only the constrained column, and a table-level check constraint can reference only columns of the constrained table.
Multiple CHECK constraints can be defined for a table. Unlike Oracle, SQL Server can define only one column-level CHECK constraint per column per CREATE TABLE statement (although each column constraint can have multiple conditions).
Converting the DBMS-specific syntax is the fundamental issue in migrating these constraints.
| Oracle | SQL Server |
| CREATE TABLE STUDENT_ADMIN.STUDENT ( SSN CHAR(9) NOT NULL, FNAME VARCHAR2(12) NULL, LNAME VARCHAR2(20) NOT NULL, GENDER CHAR(1) NOT NULL CONSTRAINT STUDENT_GENDER_CK CHECK (GENDER IN ('M','F')), MAJOR VARCHAR2(4) DEFAULT 'Undc' NOT NULL, BIRTH_DATE DATE NULL, TUITION_PAID NUMBER(12,2) NULL, TUITION_TOTAL NUMBER(12,2) NULL, START_DATE DATE NULL, GRAD_DATE DATE NULL, LOAN_AMOUNT NUMBER(12,2) NULL, DEGREE_PROGRAM CHAR(1) DEFAULT 'U' NOT NULL CONSTRAINT STUDENT_DEGREE_CK CHECK (DEGREE_PROGRAM IN ('U', 'M', 'P', 'D')), ... |
CREATE TABLE USER_DB.STUDENT _ADMIN.STUDENT ( SSN CHAR(9) NOT NULL, FNAME VARCHAR(12) NULL, LNAME VARCHAR(20) NOT NULL, GENDER CHAR(1) NOT NULL CONSTRAINT STUDENT_GENDER_CK CHECK (GENDER IN ('M','F')), MAJOR VARCHAR(4) DEFAULT 'Undc' NOT NULL, BIRTH_DATE DATETIME NULL, TUITION_PAID NUMERIC(12,2) NULL, TUITION_TOTAL NUMERIC(12,2) NULL, START_DATE DATETIME NULL, GRAD_DATE DATETIME NULL, LOAN_AMOUNT NUMERIC(12,2) NULL, DEGREE_PROGRAM CHAR(1) DEFAULT 'U' NOT NULL CONSTRAINT STUDENT_DEGREE_CK CHECK (DEGREE_PROGRAM IN ('U', 'M', 'P', 'D')), ... |
SQL Server considers NULL and NOT NULL to be column properties, while Oracle considers them to be column constraints. You cannot duplicate the Oracle NULL/NOT NULL constraint names in your migrated SQL Server application.
An Oracle table column always defaults to NULL, unless specified in the CREATE TABLE or ALTER TABLE statements. In SQL Server, database and session settings can influence and possibly override the nullability of the data type used in a column definition. When not explicitly specified, column nullability follows these rules:
| Null Setting | Description |
| Column is defined with a user-defined data type | SQL Server uses the nullability specified when the data type was created. Use the sp_help system stored procedure to get the data type's default nullability. |
| Column is defined with a system-supplied data type | If the system-supplied data type has only one option, it takes precedence. Currently, the bit data type can be defined only as NOT NULL. If any session settings are ON (turned on with the SET), then: If ANSI_NULL_DFLT_ON is ON, NULL is assigned. If ANSI_NULL_DFLT_OFF is ON, NOT NULL is assigned. If any database settings are configured (changed with the sp_dboption system stored procedure), then: If ANSI null default is true, NULL is assigned. If ANSI null default is false, NOT NULL is assigned. |
| NULL/NOT NULL Not Defined |
When not explicitly defined (neither of the ANSI_NULL_DFLT options are set), the session has not been changed and the database is set to the default (ANSI null default is false), then the SQL Server default of NOT NULL is assigned. |
To avoid possible confusion when migrating between each DBMS, it is recommended that all of your SQL scripts (whether Oracle or SQL Server) explicitly define both NULL and NOT NULL. To see how this strategy is implemented, see Oratable.sql and Sstable.sql, the sample table creation scripts included with this paper.
The rules for defining foreign keys are similar in each DBMS. The number of columns and data types of each column specified in the foreign key clause must identically match the references clause. A non-null value entered in this column(s) must exist in the table and column(s) defined in the references clause, and the referenced table's columns must have a PRIMARY KEY or UNIQUE constraint.
It is important to note the SQL Server constraints can reference only tables within the same database. Table-based triggers must be used to simulate referential integrity across databases.
Both Oracle and SQL Server support self-referenced tables. These are tables in which a reference (foreign key) can be placed against one or more columns on the very same table. For example, the column PREREQ in the CLASS table may make a reference to the column CCODE in the CLASS table. This can be done to ensure that a valid course code is entered as a course prerequisite.
Regardless of DBMS, foreign key constraints do not create an index. For performance reasons, it is recommended that you index all of your foreign keys. This allows for quicker execution times when a referenced key is modified or used for join purposes.
The Oracle CASCADE DELETE references option is not available with SQL Server. This option is used in situations where both the parent and child values are deleted when a parent row is deleted. In SQL Server, this option must be enforced with table triggers. For an example, see the "SQL Language Support" section later in this paper.
This is syntax for both the Oracle and SQL Server CREATE INDEX statement.
| Oracle | SQL Server |
| CREATE [UNIQUE] INDEX [schema].index_name ON [schema.]table_name (column_name [, column_name]...) [INITRANS n] [MAXTRANS n] [TABLESPACE tablespace_name] [STORAGE storage_parameters] [PCTFREE n] [NOSORT] |
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX index_name ON [[database.]owner.]table_name (column_name [,column_name]...) [WITH [PAD_INDEX] [FILLFACTOR = x] [[,] IGNORE_DUP_KEY] [[,]{SORTED_DATA | SORTED_DATA_REORG}] [[,]{IGNORE_DUP_ROW | ALLOW_DUP_ROW}]] [ON segment_name] |
SQL Server offers both clustered and nonclustered index structures. These indexes are made up of pages that form a branching structure known as a B-tree (similar to the Oracle B-tree index structure). The starting page (root level) specifies ranges of values within the table. Each range on the root level page points to another page (decision node) which contains a more limited range of values for the table. In turn, these decision nodes can point to other decision nodes, further narrowing the search range. The final level in the branching structure is called the leaf level.
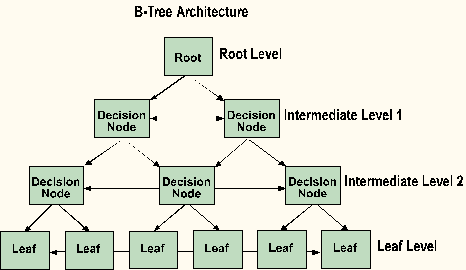
Nonclustered indexes resemble Oracle indexes. The index and the table are physically separated from each other, and each are considered separate database objects. Because these objects are separate, the physical order of the table rows is not the same as their indexed order. The leaf pages on nonclustered indexes contain the indexed value and the row address for the row within the table. A table can have up to 249 nonclustered indexes. Each index can provide access to the data in a table in different sorted order.
Because of the similarity in design, you can translate Oracle index definitions to SQL Server nonclustered index definitions (as shown in the following example). For performance reasons, however, you may want to consider using clustered indexes.
| Oracle | SQL Server |
| CREATE INDEX STUDENT_ADMIN.STUDENT_MAJOR_IDX ON STUDENT_ADMIN.STUDENT (MAJOR) TABLESPACE USER_DATA PCTFREE 0 STORAGE (INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED) |
CREATE NONCLUSTERED INDEX STUDENT_MAJOR_IDX ON USER_DB.STUDENT_ADMIN.STUDENT (MAJOR) |
A clustered index is an index that has been physically merged with a table. The table and index share the same storage area. The clustered index physically rearranges the rows of data in indexed order, forming the intermediate decision nodes. The leaf pages of the index contain the actual table data. This type of architecture permits only one clustered index per table.
Clustered indexes can be useful for:
SELECT * FROM STUDENT WHERE GRAD_DATE
BETWEEN '1/1/97' AND '12/31/97'SELECT * FROM STUDENT WHERE LNAME = 'SMITH'For example, on the STUDENT table, it might be helpful to include a nonclustered index on the primary key of SSN, while the clustered index could be created on lname, fname, (last name, first name), because this is how students are often grouped.
To avoid hot spots, clustered indexes can sometimes be used to spread out update activity in a table. The common cause of hot spots is multiple users inserting into a table with an ascending key. This application scenario, however, is best addressed by the new insert row-lock table option in SQL Server 6.5 (see the "Insert Row-level Locking (IRL)" section later in this paper) rather than attempting to spread out the inserts with a clustered index on a non-key column.
Dropping and re-creating a clustered index is a common technique for reorganizing a table in SQL Server. It is an easy way to ensure that data pages are contiguous on disk and to reestablish some free space in the table. This is similar to exporting, dropping, and importing a table in Oracle.
A SQL Server clustered index is not at all like an Oracle cluster. An Oracle cluster is a physical grouping of two or more tables that share the same data blocks and use common columns as a cluster key. SQL Server does not have a structure that is similar to an Oracle cluster.
As a rule, you should always have a clustered index defined on a table. Doing so improves SQL Server performance and space management. If you don't know the query or update patterns for a given table, you can default to using the clustered index on the primary key. Later analysis of application bottlenecks may lead you to change the clustered index on specific tables to better support frequently used range queries.
An excerpt from the sample application source code is shown. Note the use of the SQL Server clustered index.
| Oracle | SQL Server |
| CREATE TABLE STUDENT_ADMIN.GRADE ( SSN CHAR(9) NOT NULL, CCODE VARCHAR2(4) NOT NULL, GRADE VARCHAR2(2) NULL, CONSTRAINT GRADE_SSN_CCODE_PK PRIMARY KEY (SSN, CCODE) CONSTRAINT GRADE_SSN_FK FOREIGN KEY (SSN) REFERENCES STUDENT_ADMIN.STUDENT (SSN), CONSTRAINT GRADE_CCODE_FK FOREIGN KEY (CCODE) REFERENCES DEPT_ADMIN.CLASS (CCODE) ) |
CREATE TABLE STUDENT_ADMIN.GRADE ( SSN CHAR(9) NOT NULL, CCODE VARCHAR(4) NOT NULL, GRADE VARCHAR(2) NULL, CONSTRAINT GRADE_SSN_CCODE_PK PRIMARY KEY CLUSTERED (SSN, CCODE), CONSTRAINT GRADE_SSN_FK FOREIGN KEY (SSN) REFERENCES STUDENT_ADMIN.STUDENT (SSN), CONSTRAINT GRADE_CCODE_FK FOREIGN KEY (CCODE) REFERENCES DEPT_ADMIN.CLASS (CCODE) ) |
The FILLFACTOR option functions in much the same way as the PCTFREE variable does in Oracle. As tables grow in size, index pages split to accommodate new data. The index must reorganize itself to accommodate new data values.
The FILLFACTOR option (values are 1 through 100) controls how much space is left on an index page when the index is initially created. The default fill factor of 0 completely fills index leaf pages and leaves space on each decision node page for at least one entry (two for non-unique clustered indexes). Note that the fill factor percentage is only used when the index is created, and is not maintained afterwards.
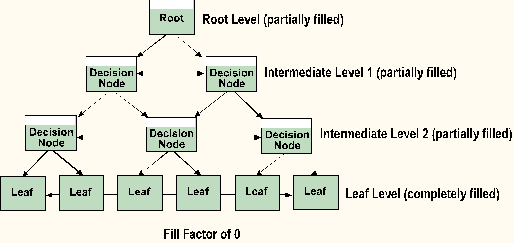
A lower fill factor value initially reduces the splitting of index pages and increases the number of levels in the B-tree index structure. A higher fill factor uses index page space more efficiently, requires fewer disk I/O's to access index data, and reduces the number of levels in the B-tree index structure.
The PAD_INDEX option specifies that the fill factor setting be applied to the decision node pages as well as to the data pages in the index.
While it may be necessary to adjust the PCTFREE parameter for optimal performance in Oracle, it is seldom necessary to include the FILLFACTOR option in a CREATE INDEX statement. The fill factor is provided for fine-tuning performance. It is useful only when creating a new index on a table with existing data, and then it is useful only when you can accurately predict future changes in that data.
If you have set the PCTFREE parameter to 0 for Oracle indexes, consider using a fill factor of 100. This is used when there will be no inserts or updates occurring in the table (a read-only table). When fill factor is set to 100, SQL Server creates indexes with each page 100 percent full.
The default operation of a unique index in Oracle and SQL Server is virtually identical. You cannot insert duplicate values for a uniquely indexed column or columns. An attempt to do so generates an error message.
This default operation can be changed when the IGNORE_DUP_KEY option is set when the index is created. In this case, when an INSERT or UPDATE attempts to duplicate a currently existing indexed value, the statement is ignored and no error message is returned.
The purpose of IGNORE_DUP_KEY (and of the IGNORE_DUP_ROW option) is to allow a transaction to proceed although duplicates are present. In order to ensure maximum compatibility with your Oracle applications, do not set these options when you create indexes. For more information about these options, see the Microsoft SQL Server Transact-SQL Reference or Microsoft SQL Server Books Online.
Oracle and SQL Server allow up to 16 columns to be defined in an index. However, the sum of the lengths of the columns that make up a SQL Server composite index cannot exceed 900 bytes (versus approximately one-half the block size in Oracle).
In Oracle, an index name must be unique within a user account. In SQL Server, an index name must be unique within a table name, but it does not have to be unique within a user account or database. For example:
CREATE INDEX DEMO_IDX ON USER_DB.STUDENT_ADMIN.STUDENT (LNAME)
If these same statements are issued in Oracle, you receive this error message: "ORA-00955: name is already used by an existing object."
When dropping an index in SQL Server, you must specify both the table name and the index name. Additionally, the DROP INDEX statement can be used to drop multiple indexes at one time:
DROP INDEX USER_DB.STUDENT.DEMO_IDX, USER_DB.GRADE.DEMO_IDX
For more information about managing indexes, see the Microsoft SQL Server Transact-SQL Reference.
SQL Server has a much more robust selection of data types than Oracle. There are many possible conversions between the Oracle and SQL Server data types.
| Oracle | SQL Server |
| CHAR | char is recommended. char type columns are accessed somewhat faster than varchar columns because they use a fixed storage length. |
| VARCHAR2 and LONG |
varchar or text. (If the length of the data values in your Oracle column is 255 bytes of less, use varchar; otherwise, you must use text.) |
| RAW and LONG RAW |
varbinary or image. (If the length of the data values in your Oracle column is 255 bytes of less, use varbinary; otherwise, you must use image.) |
| NUMBER | If integer between 1 and 255, use tinyint. If integer between -32768 and 32767, use smallint. If integer between -2,147,483,648 and 2,147,483,647 use int. If you require a float type number, use numeric (has precision and scale). Note: Do not use float or real, because rounding may occur (Oracle NUMBER and SQL Server numeric do not round). If you are not sure, use numeric; it most closely resembles Oracle NUMBER data type. |
| DATE | datetime. |
| ROWID | Use the identity column type. |
| CURRVAL, NEXTVAL | Use the identity column type, and @@identity global variable, IDENT_SEED() and IDENT_INCR() functions. |
| SYSDATE | GETDATE() |
| USER | USER |
For more information about SQL Server data types, see the Microsoft SQL Server Transact-SQL Reference.
The timestamp columns enable BROWSE-mode updates and make cursor update operations more efficient. The timestamp is a data type that is automatically updated every time a row containing a timestamp column is inserted or updated.
Values in timestamp columns are not datetime data, but binary(8) or varbinary(8) data, indicating the sequence of SQL Server activity on the row. A table can have only one timestamp column. The timestamp data type is not related to the system time. It is a sequentially increasing counter whose values are always unique within a database.
For more information, see Microsoft SQL Server Programming DB-Library for C.
If your Oracle application currently uses sequences to generate sequential numeric values, it can be easily altered to take advantage of the SQL Server IDENTITY property. The primary difference between SQL Server and Oracle is that the IDENTITY property is actually part of the column, while a sequence is independent of any tables or columns.
The SQL Server IDENTITY property generates incremental values for new rows based on IDENT_SEED and IDENT_INCR parameters. The IDENT_SEED parameter, which is similar to the sequence START WITH parameter, specifies the starting number. The IDENT_INCR parameter, which is similar to the sequence INCREMENT BY parameter, specifies the interval that will be applied to each subsequent value. By default, both IDENT_SEED and IDENT_INCR default to the value of 1.
The IDENTITY property must be assigned to a tinyint, smallint, int, decimal(p,0), or numeric(p,0) column that does not allow null values. Only one column per table can be defined as an IDENTITY column. Defaults and DEFAULT constraints cannot be bound to an IDENTITY column, and an identity value cannot be updated.
The keyword IDENTITYCOL can be used in place of a column name when referencing a column that has the IDENTITY property. The IDENTITYCOL keyword can be used with SELECT, INSERT, UPDATE, and DELETE statements.
Two system functions return identity information for an object containing an IDENTITY column.
| Function | Description |
| IDENT_SEED('table_name') | This returns the seed value specified during creation of an identity column. |
| IDENT_INCR('table_name') | This returns the increment value specified during creation of an identity column. |
The global variable @@IDENTITY contains the value of the IDENTITY column for the most recently inserted row for a user connection.
The syntax used to create views in SQL Server is similar to the syntax used in Oracle.
| Oracle | SQL Server |
| CREATE [OR REPLACE] [FORCE | NOFORCE] VIEW [schema.]view_name [(column_name [, column_name]...)] AS select_statement [WITH CHECK OPTION [CONSTRAINT name]] [WITH READ ONLY] |
CREATE VIEW [owner.]view_name [(column_name [, column_name]...)] [WITH ENCRYPTION] AS select_statement [WITH CHECK OPTION] |
SQL Server views require that the tables exist and that the view owner has privileges to access the requested tables(s) specified in the SELECT statement. This performs the same as the Oracle FORCE option.
By default, data modification statements on views are not checked to determine whether the rows affected are within the scope of the view. If all modifications should be checked, use the WITH CHECK OPTION. The primary difference between the WITH CHECK OPTION is that Oracle defines it as a constraint, while SQL Server does not. Otherwise, it functions the same in both.
SQL Server does not offer the WITH READ ONLY option when defining views. The same result can be obtained, however, by granting only SELECT permission to all users of the view.
Both SQL Server and Oracle views support derived columns, using arithmetic expressions, functions, and constant expressions. Some of the specific SQL Server differences are:
If you define a SQL Server view with an outer join and then query the view with a qualification on a column from the inner table of the outer join, the results can differ from what is expected. All rows from the inner table are returned. Rows that do not meet the qualification show a null value in the appropriate columns for those rows.
In most cases, Oracle views are easily translated into SQL Server views.
| Oracle | SQL Server |
| CREATE VIEW STUDENT_ADMIN.STUDENT_GPA (SSN, GPA) AS SELECT SSN, ROUND(AVG(DECODE(grade ,'A', 4 ,'A+', 4.3 ,'A-', 3.7 ,'B', 3 ,'B+', 3.3 ,'B-', 2.7 ,'C', 2 ,'C+', 2.3 ,'C-', 1.7 ,'D', 1 ,'D+', 1.3 ,'D-', 0.7 ,0)),2) FROM STUDENT_ADMIN.GRADE GROUP BY SSN |
CREATE VIEW STUDENT_ADMIN.STUDENT_GPA (SSN, GPA) AS SELECT SSN, ROUND(AVG(CASE grade WHEN 'A' THEN 4 WHEN 'A+' THEN 4.3 WHEN 'A-' THEN 3.7 WHEN 'B' THEN 3 WHEN 'B+' THEN 3.3 WHEN 'B-' THEN 2.7 WHEN 'C' THEN 2 WHEN 'C+' THEN 2.3 WHEN 'C-' THEN 1.7 WHEN 'D' THEN 1 WHEN 'D+' THEN 1.3 WHEN 'D-' THEN 0.7 ELSE 0 END),2) FROM STUDENT_ADMIN.GRADE GROUP BY SSN |
An Oracle application may have to create tables that exist for short periods. The application must ensure that all tables that are created for this purpose are dropped at some point. If the application fails to do this, tablespaces can quickly become cluttered and unmanageable.
This is not the case in SQL Server. SQL Server allows temporary tables to be created for just such a purpose. Regardless of the user, these tables are created in the tempdb database. The naming convention used with these tables controls how long they reside within the tempdb database.
| Table name | Description |
| #table_name | This local temporary table only exists for the duration of a user session or the procedure that created it. It is automatically dropped when the user logs off or the procedure that created the table completes. These tables cannot be shared between multiple users. No other database users can access this table. Permissions cannot be granted or revoked on this table. |
| ##table_name | This global temporary table also typically exists for the duration of a user session or procedure that created it. This table can be shared among multiple users. It is automatically dropped when the last user session referencing it disconnects. All other database users can access this table. Permissions cannot be granted or revoked on this table. |
| tempdb..table_name | This table will continue to exist until it is dropped or SQL Server is restarted. Permissions can be granted and revoked against this table. To create this table, the database user must have CREATE TABLE permission in the tempdb database. |
Indexes can be defined for temporary tables. Views can only be defined on tables explicitly created in tempdb without the # or ## prefix. The following example shows the creation of a temporary table and its associated index. When the user exits, the table and index are automatically dropped.
SELECT SUM(ISNULL(TUITION_PAID,0)) SUM_PAID, MAJOR INTO #SUM_STUDENT
FROM USER_DB.STUDENT_ADMIN.STUDENT GROUP BY MAJOR
CREATE UNIQUE INDEX SUM STUDENT IDX ON #SUM STUDENT (MAJOR)
To ensure complete compatibility with an Oracle application, you may not want to use temporary tables. However, you may find that the benefits associated with using them justify a slight revision in program code.
In Oracle, a table can be created using any valid SELECT statement. For example, the following syntax is used to create the table student_backup:
create table student_backup as select * from student_admin.student
SQL Server allows you to do the same thing. However, the syntax is slightly changed:
select * into student_backup from ser_db.student_admin.student
It is important to note that a SELECT…INTO does not work unless the database in which this is done has the select into/bulkcopy option set to true. Only the DBO can set this option using SQL Enterprise Manager or the sp_dboption system stored procedure.
The sp_helpdb system stored procedure can be used to check the status of the database. If select into/bulkcopy is not set to true, you can still use a SELECT statement to copy into a temporary table:
select * into #student_backup from user_db.student_admin.student
As in Oracle, when a table is copied in SQL Server, the referential integrity definitions are not copied to the new table.
The need to have the select into/bulkcopy set to true may complicate the migration process. If you need to copy data into tables using a SELECT statement, consider creating the table first and then using the insert INTO…SELECT statement to load the table. This method is compatible between Oracle and SQL Server, and does not require that any database option be set. However, this method is slower in SQL Server because every row is logged.
SQL Server offers three database objects that do not exist in Oracle: user-defined data types, rules, and defaults. If you require strict compatibility between your SQL Server and Oracle applications, do not use these objects. However, they are extremely useful and provide a level of extensibility that is simply not available in Oracle.
Use system data types (supplied by SQL Server) and user-defined data types (custom data types based on system data types) to enforce data integrity.
User-defined data types are created with the sp_addtype system stored procedure. When creating user-defined data types, supply three parameters: the name of the data type, the system data type upon which the new data type is based, and the data type's nullability (whether it allows null values: if defined explicitly, NULL or NOT NULL). When nullability is not explicitly defined, it is assigned based on the ANSI null default setting for the database or connection.
After a user data type is created, use it in the CREATE TABLE and ALTER TABLE statements, as well as bind defaults and rules to it. If nullability is explicitly defined when the user-defined data type is used during table creation, it takes precedence over the defined nullability. For more information, see the Microsoft SQL Server Transact-SQL Reference.
This example shows how to create a user-defined data type:
sp_addtype gender_type, 'varchar(1)', 'not null'
go
This capability may initially appear to solve the problem of migrating Oracle table creation scripts to SQL Server. For example, it is quite easy to add the Oracle DATE data type:
sp_addtype date, datetime
This does not work with data types that require variable sizes, for example the Oracle data type NUMBER. An error message is returned indicating that a length must also be specified:
sp_addtype varchar2, varchar
Go
Msg 15091, Level 16, State 1
You must specify a length with this physical type.
User-defined rules are database objects that specify the acceptable values that can be inserted into a column. They are created with the CREATE RULE statement. A rule must be bound to a column or a user-defined data type using the sp_bindrule system stored procedure. When a rule is bound to a column, it does not apply itself to data already within the table (this is similar in operation to a trigger). Rules can only be defined within the context of one database.
When bound directly to a column, rules provide much of the same function as a CHECK constraint. The use of CHECK constraints to restrict column data is preferred because CHECK constraints follow ANSI standard SQL. Additionally, multiple CHECK constraints can be defined on a column or on multiple columns, whereas a column can have only one rule associated with it.
However, rules are especially useful when bound to user-defined data types. A rule bound to a user-defined data type is automatically inherited by any table that includes a column of that type. The rule can be changed in one place, and the change applies to all instances of the data type.
How to create and bind a rule to a user-defined data type is shown in this example:
create rule gender_rule as @gender in ('M','F')
go
sp_bindrule gender_rule, gender_type
go
For more information about the CREATE RULE statement, see the Microsoft SQL Server Transact-SQL Reference.
The CREATE DEFAULT statement creates a user-defined default. The DEFAULT constraint is the recommended method for restricting column data because the constraint definition is expressed in the ANSI-standard CREATE TABLE and ALTER TABLE statements. Like rules, however, a user-defined default is especially useful when bound to a user-defined data type and used in multiple tables.
The sp_binddefault system stored procedure is used to bound a user-defined default to either a column in a table or a user-defined data type. This example shows how to create and bind a user-defined default on a user-defined data type:
create default gender_dflt as 'F'
go
sp_bindefault gender_dflt, gender_type
go
For more information about the CREATE DEFAULT statement, see the Microsoft SQL Server Transact-SQL Reference.
The syntax of the GRANT statement is identical in Oracle and SQL Server.
| Oracle | SQL Server |
| GRANT {ALL [PRIVILEGES][column_list] | permission_list [column_list]} ON {table_name [(column_list)] | view_name [(column_list)] | stored_procedure_name} TO {PUBLIC | name_list } [WITH GRANT OPTION] |
GRANT {ALL [PRIVILEGES][column_list] | permission_list [column_list]} ON {table_name [(column_list)] | view_name [(column_list)] | stored_procedure_name} TO {PUBLIC | name_list } [WITH GRANT OPTION] |
SQL Server object privileges can be granted to other database users, database groups, and the public group. SQL Server does not allow an object owner to grant ALTER TABLE and CREATE INDEX privileges for the object as Oracle does. Those privileges must remain with the object owner.
In Oracle, the REFERENCES privilege can only be granted to a user. SQL Server allows the REFERENCES privilege to be granted to both database users and database groups. The INSERT, UPDATE, DELETE, and SELECT privileges are granted the same way in each DBMS.