This section explains how transactions are executed in both Oracle and SQL Server and discusses the difference between the locking process and concurrency issues in both database types.
In the Oracle DBMS, a transaction is automatically started whenever an INSERT, UPDATE, or DELETE operation is performed. An application must issue a COMMIT to save all changes to data. If a COMMIT is not performed, all changes are automatically rolled back or undone.
By default, SQL Server automatically performs a COMMIT after every INSERT, UPDATE, or DELETE operation. Because the data is automatically saved, you are unable to roll back any changes. This default operation can be changed by using implicit or explicit transaction modes. The implicit transaction mode allows SQL Server to behave like Oracle. This is activated using the SET IMPLICIT_TRANSACTIONS ON statement. When this option is turned on and if there are no outstanding transactions already, every SQL statement automatically starts a transaction.
If there is an open transaction, no new transaction is started. The open transaction has to be explicitly committed by the user with the COMMIT TRANSACTION statement for the changes to take effect, and for all locks to be released.
An explicit transaction is a grouping of SQL statements surrounded by the following transaction delimiters:
In the following example, the English department is changed to the Literature department. Note the use of the BEGIN TRANSACTION and COMMIT TRANSACTION statements.
| Oracle | SQL Server |
| INSERT INTO DEPT_ADMIN.DEPT (DEPT, DNAME) VALUES ('LIT', 'Literature') / UPDATE DEPT_ADMIN.CLASS SET MAJOR = 'LIT' WHERE MAJOR = 'ENG' / UPDATE STUDENT_ADMIN.STUDENT SET MAJOR = 'LIT' WHERE MAJOR = 'ENG' / DELETE FROM DEPT_ADMIN.DEPT WHERE DEPT = 'ENG' / COMMIT / |
BEGIN TRANSACTION INSERT INTO DEPT_ADMIN.DEPT (DEPT, DNAME) VALUES ('LIT', 'Literature') UPDATE DEPT_ADMIN.CLASS SET DEPT = 'LIT' WHERE DEPT = 'ENG' UPDATE STUDENT_ADMIN.STUDENT SET MAJOR = 'LIT' WHERE MAJOR = 'ENG' DELETE FROM DEPT_ADMIN.DEPT WHERE DEPT = 'ENG' COMMIT TRANSACTION GO |
All explicit transactions must be enclosed within BEGIN TRANSACTION...COMMIT TRANSACTION statements. The SAVE TRANSACTION statement functions in the same way as the Oracle SAVEPOINT command. It sets a savepoint in the transaction, allowing partial rollbacks.
Transactions can be nested one within another. If this occurs, the outermost pair actually creates and commits the transaction, while the inner pairs track the nesting level. When a nested transaction is encountered, the global variable @@trancount is incremented. Usually, this apparent transaction nesting occurs as stored procedures or triggers with BEGIN…COMMIT pairs calling each other.
Although transactions can be nested, they have little effect on the behavior of ROLLBACK TRANSACTION statements. In stored procedures and triggers, the number of BEGIN TRANSACTION statements must match the number of COMMIT TRANSACTION statements.
A procedure or trigger that contains unpaired BEGIN TRANSACTION and COMMIT TRANSACTION statements produces an error message when executed. The syntax allows stored procedures and triggers to be called from within transactions if they contain BEGIN TRANSACTION and COMMIT TRANSACTION statements.
Grouping a large number of Transact-SQL statements into one long-running transaction can negatively affect recovery time and cause concurrency problems. If SQL Server fails during such a transaction, recovery time can increase because SQL Server must first undo the transaction. Wherever possible, it is wise to break transactions into smaller transactions. Make sure each transaction is well defined within a single batch. To minimize possible concurrency conflicts, transactions should not span multiple batches nor wait for user input.
When programming with ODBC, you can select either the implicit or explicit transaction mode by using the SQLSetConnectOption function. For an ODBC program to select one or the other is just dependent on the AUTOCOMMIT connect option. If AUTOCOMMIT is turned on (the default), you are in explicit mode. If AUTOCOMMIT is turned off, you are in implicit mode.
If you are issuing a script through ISQL/w or other query tools, you can either include the explicit BEGIN TRANSACTION statement shown previously, or start the script with the SET IMPLICIT_TRANSACTIONS ON statement. The BEGIN TRANSACTION approach is a little more flexible, while the implicit approach is more compatible with Oracle.
One of the key functions of a DBMS is to ensure that multiple users can read and write records in the database without reading inconsistent sets of records due to in-progress changes and without inadvertently overwriting each other's changes. Oracle and SQL Server approach this task with very different locking and isolation strategies. You must consider these differences when you convert an application from Oracle to SQL Server, or the resulting application may scale poorly to high numbers of users.
Oracle uses a multiversion consistency model for all SQL statements that read data, either explicitly or implicitly. In this model, data readers by default neither acquire locks nor wait for other locks to be released before reading rows of data. When a reader requests data that has been changed by other writers, but not yet committed, Oracle re-creates the old data. It uses its rollback segments to reconstruct a snapshot of rows for the reader as of the start of the reader's statement or transaction.
Data writers in Oracle do request locks on data that is updated, deleted, or inserted. These locks are held until the end of a transaction, and they prevent other users from overwriting uncommitted changes.
SQL Server, in contrast, uses shared locks to ensure that data readers only see committed data. These readers take and release shared locks as they read data. These shared locks do not affect other readers. A reader waits for a writer to commit the changes before reading a record. A reader holding shared locks also blocks a writer trying to update the same data.
Based on these differences alone, it is clear that releasing locks quickly for applications that support high numbers of users is much more important in SQL Server than in Oracle. Releasing locks quickly is usually a matter of keeping transactions short. If possible, a transaction should not span multiple round-trips to the server, nor include user "think" time. You also need to code your application to fetch data as quickly as possible, because unfetched data scans can hold share locks at the server and thus block updaters. (For more information, see the "ODBC" section later in this paper).
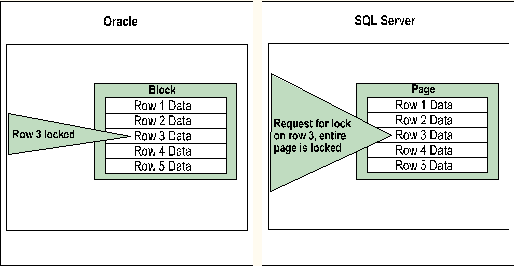
The impact of long transactions (and thus long lock duration's) is further magnified because the Oracle DBMS locks data at the row level, while SQL Server defaults to locking data at the page level. The following illustration shows this difference. When an Oracle transaction requests a lock on row 3, only that row is locked. When a SQL Server transaction requests a lock on row 3, the entire page is locked. All five rows on the page remain locked until the transaction releases the lock.
Both SQL Server and Oracle allow the developer to request non-default locking and isolation behavior. In Oracle, the most common mechanisms for this are the FOR UPDATE clause on a SELECT statement, the SET TRANSACTION READ ONLY statement, and explicit LOCK TABLE command.
Because their overall locking and isolation strategies are so different, it is difficult to map these locking options directly between Oracle and SQL Server. To obtain a better understanding of this process, the options that SQL Server provides for changing its default behavior must be examined.
In SQL Server, the most common mechanisms are the SET TRANSACTION ISOLATION LEVEL statement and the locking hints that are supported in SELECT and UPDATE statements. The SQL Server SET TRANSACTION ISOLATION LEVEL statement is used to set transaction isolation levels for the duration of a user's session. This becomes the default behavior for the session unless a locking hint is specified at the table level in the FROM clause of an SQL statement.
The default isolation level for SQL Server is READ COMMITTED (SET TRANSACTION ISOLATION LEVEL READ COMMITTED). When using this option, your application cannot read data that has not yet been committed by other transactions. In this mode, however, shared locks are released as soon as the data has been read from a page. If the application goes to reread the same data range within the same transaction, it may see other users' changes.
If you must prevent this from occurring in your application, you can use set the transaction isolation level to SERIALIZABLE. This option directs SQL Server to hold all shared locks until the end of a transaction. You can achieve the same effect on a more granular level by using the HOLDLOCK hint after the table name in SELECT statement. Either of these options represents a trade-off of concurrency for strict consistency, and should only be used when necessary.
The READ UNCOMMITTED option (SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED) implements dirty reads, which means that no shared locks are issued and no exclusive locks are honored by readers. With this option set, SQL Server readers are nonblocking, as in Oracle. When this option is set, however, an application can read data that has not yet been committed by another user. For some applications, such as statistical reporting summaries, this may not present a problem at all. For other applications, such as a database queuing table, this may be a big problem.
Use READ UNCOMMITTED isolation only after you thoroughly analyze how it may affect the correctness of your application.
SQL Server does not directly support the READ ONLY transaction level offered by Oracle. If some transactions in an application require repeatable read behavior, you may need to use the SERIALIZABLE isolation level offered by SQL Server. If all of the database access is read only, you can improve performance by setting the SQL Server database option to READ ONLY.
The SELECT…FOR UPDATE statement in Oracle is usually used when an application needs to issue a positioned update or delete on a cursor using the WHERE CURRENT OF syntax. In this case, optionally remove the FOR UDPATE clause, because SQL Server cursors are updatable by default.
SQL server cursors usually do not hold locks under the fetched row. Rather, they use an optimistic concurrency strategy to prevent updates from overwriting each other. If one user attempts to update or delete a row that has been changed since it was read into the cursor, SQL Server detects the problem and issues an error message. The application can trap this error message and retry the update or delete as appropriate.
The optimistic technique supports higher concurrency in the normal case where collisions between updaters are rare. If your application really needs to ensure that a row cannot be changed after it is fetched, you can use the UPDLOCK hint in your SELECT statement to achieve this effect.
This hint does not block other readers, but it prevents any other potential writers from also obtaining an update lock on the data. When using ODBC, you can also achieve a similar effect using SQLSETSTMTOPTION (…,SQL_CONCURRENCY)= SQL_CONCUR_LOCK. Either of these options reduces concurrency, however.
SQL Server can be directed to lock an entire table using the SELECT…table_name (TABLOCK) statement. This performs the same operation as the Oracle LOCK TABLE…IN SHARE MODE statement. This lock allows others to read a table, but prevents them from updating it. By default, this lock is held until the end of the statement. If you also add the eyword HOLDLOCK (SELECT…table_name (TABLOCK HOLDLOCK)), the table lock is held until the end of the transaction.
An exclusive lock can be placed on a SQL Server table using the SELECT…table_name (TABLOCKX) statement. This statement requests an exclusive lock on a table. It is used to prevent others from reading or updating the table and is held until the end of the command or transaction. It is similar in function to the Oracle LOCK TABLE…IN EXCLUSIVE MODE statement.
It is important to note that SQL Server does not offer a NOWAIT option for any of its explicit lock requests.
The default locking granularity in SQL Server is the page. The lock manager can also provide insert row-level locking (IRL) for most INSERT operations. IRL improves performance in situations when many users try to insert records into the same region of a table or index, creating hotspots.
While row-level locking is not a substitute for a well-designed application, there are specific scenarios in which it is especially useful. Row-level locking is useful when a hotspot develops on tables structured as a sequential file. With SQL Server, hotspots can occur when records are inserted at the end of a table and one of the following conditions exists:
To alleviate these performance bottlenecks, the lock manager provides row-level concurrency for INSERT operations. Properly implemented IRL increases the speed of multiuser INSERT operations.
If a clustered index exists on a table, it must be a unique clustered index to take advantage of IRL. Typically, a unique clustered index is created by default on the column or columns that form the primary key when the primary key is defined.
The IRL option is set to off by default. It can be enabled on individual tables or on an entire database by using the sp_tableoption stored procedure. This example shows how the database owner can turn on the insert row lock option for all tables in the current database:
EXECUTE sp_tableoption 'student', 'insert row lock', 'true'
For more information, see Microsoft SQL Server What's New in SQL Server 6.5.
IRL is not always a good way to achieve higher concurrency. If a multiuser application inserts a data row and later updates the same or nearby rows in the same transaction, turning on IRL can increase the incidence of application deadlock. For more information, see "Deadlocks" later in this paper.
When a query requests rows from a table, SQL Server automatically generates page-level locks. However, if the query requests a large percentage of the table's rows, then SQL Server escalates the locking from page level to table level. This process is called lock escalation.
Lock escalation makes table scans and operations against a large result set more efficient because it reduces locking overhead. SQL statements that lack WHERE clauses typically cause lock escalation.
A shared table lock (TABLOCK) is applied when a shared page lock is escalated to a table lock during a read operation. Shared table locks are applied when:
The escalation threshold defaults to 200 pages in a table, but this can be customized to be based on a percentage of table size with minimum and maximum bounds. A shared table locks is also used when building a nonclustered index. For more information about escalation threshold, see the Microsoft SQL Server Transact-SQL Reference.
An exclusive table lock (TABLOCKX) is applied when an UPDATE lock has escalated to a table lock during a write operation. Exclusive table locks are applied when:
Oracle's inability to escalate row level locks can cause problems in poorly worded queries that include the FOR UPDATE clause. For example, assume that the STUDENT table has 100,000 rows of data. The following statement is issued by an Oracle user:
SELECT * FROM STUDENT FOR UPDATE
This statement forces the Oracle DBMS to lock the STUDENT table one row at a time (this may take quite a while). It never escalates the request to lock the entire table.
The same query in SQL Server is:
[SELECT * FROM student (UPDLOCK)]
When this query is run, page-level locking escalates to table-level locking, which is much more efficient and significantly faster.
A deadlock occurs when one process locks a page or table and another process needs it, and the second process has a lock that the first process needs. A deadlock is also known as a deadly embrace. SQL Server automatically detects and resolves deadlocks. If a deadlock is found, the server terminates the user process that has completed the deadly embrace.
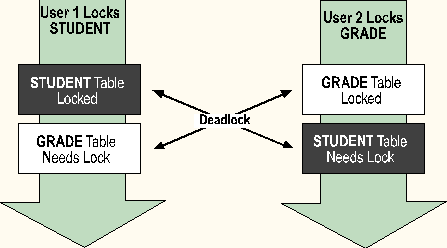
After every data modification, your program code should check for message number 1205, which indicates a deadlock situation. If this message number is returned, a deadlock has occurred and the transaction was rolled back. In this situation, your application must restart the transaction.
Deadlocks can usually be avoided by using a few simple techniques:
For more information, see the Microsoft Knowledge Base article, "Detecting and Avoiding Deadlocks in Microsoft SQL Server."
To perform remote transactions in Oracle, you must have access to a remote database node with a database link. In SQL Server, you must have access to a remote server. A remote server is a SQL Server on the network that users can access by using their local server. When a server is set up as a remote server, users can use the system procedures and the stored procedures on it without explicitly logging in to it.
The remote servers are set up in pairs. You must configure both servers to recognize each other as remote servers. The name of the remote server must be added to the local server. On the remote server, you must add the server name of the local server. To do this, you use the sp_addserver system stored procedure or SQL Enterprise Manager.
After you set up a remote server, you can set up remote login IDs for the users who need to access that remote server. To do this, use the sp_addremotelogin system stored procedure or SQL Enterprise Manager. After this step is completed, you must grant permissions to execute the stored procedures.
The EXECUTE statement is then used to run procedures on the remote server. This example executes the validate_student stored procedure on the remote server STUDSVR1 and stores the return status indicating success or failure in @retvalue1:
DECLARE @retvalue1 int
EXECUTE @retvalue = STUDSVR1.student_db.student_admin.validate_student '111111111'
For more information, see the Microsoft SQL Server Administrator's Companion.
Oracle automatically initiates a distributed transaction if changes are made to tables in two or more networked database nodes. SQL Server distributed transactions use the two-phase commit services of the Microsoft Distributed Transaction Coordinator (MS DTC), included with SQL Server.
By default, SQL Server must be instructed to participate in a distributed transaction. SQL Server's participation in an MS DTC transaction can be started by any of the following:
In the example, notice the distributed update to both the local table GRADE and the remote table CLASS (using a class_name procedure):
BEGIN DISTRIBUTED TRANSACTION
UPDATE STUDENT_ADMIN.GRADE
SET GRADE = 'B+' WHERE SSN = '111111111' AND CCODE = '1234'
DECLARE @retvalue1 int
EXECUTE @retvalue1 = CLASS_SVR1.dept_db.dept_admin.class_name '1234', 'Basketweaving'
COMMIT TRANSACTION
GO
If the application cannot complete the transaction, the application program aborts it by using the ROLLBACK TRANSACTION statement. If the application fails or a participating resource manager fails, then MS DTC aborts the transaction. MS DTC does not support distributed savepoints or the SAVE TRANSACTION statement. If an MS DTC transaction is aborted or rolled back, the entire transaction is rolled back to the beginning of the distributed transaction, regardless of any savepoints.
The Oracle and MS DTC two-phase commit mechanisms are similar in operation. In the first phase, the transaction manager requests each enlisted resource manager (SQL Server in this case) to prepare to commit. If any resource manager cannot prepare, the transaction manager broadcasts an abort decision to everyone involved in the transaction.
If all resource managers can successfully prepare, then the transaction manager broadcasts the commit decision. This is the second phase of the commit process. While a resource manager is prepared, it is in doubt about whether the transaction is committed or aborted. MS DTC keeps a sequential log so that its commit or abort decisions are durable. If a resource manager or transaction manager fails, they reconcile in-doubt transactions when they reconnect.