Distributing read-only data to remote locations improves site autonomy by allowing a remote location to continue to access reference information if the central site is unavailable. Often, regional locations require only specific data. For example, a customer account management system can be divided into territories and, while a central office requires all data, each regional server needs reference information only for the accounts it manages. The application data set can be partitioned logically using a column value for the region to which a record belongs.
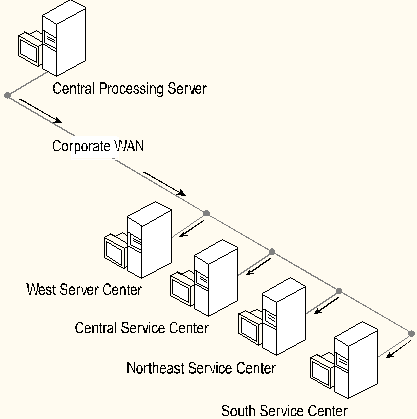
The following business problem exists for an insurance claims processor with regional customer service centers. All claims processing takes place at a single central location in the Midwest, while customer service call centers exist at contract agencies in the four regions across the U.S. in which the carrier underwrites policies. Each call center must have up-to-date data regarding claims adjudication for each customer in its region to assist callers with understanding benefits they receive after their claims have been processed.
This scenario assumes a single publisher and multiple subscribers. As claims are processed and the associated transactions are committed to the publishing database, the claims data can be moved to the distribution database quickly on the local server. A local distribution database centralizes all replication administration at the central site. If claims volumes are high and the central server becomes overworked, a second remote distributor can be added at the central site. This remote server takes on the processing of the distribution task from the main claims processing server.
Deciding on Full or Partial Replication
Because claims and customer data changes are processed nightly, each region must receive large batches of replicated data at the start of each day. While transaction volumes at the central processing facility are high, the number of new claims for each region are relatively low.
This environment is a prime candidate for partitioning data to reduce the result set targeted for each subscriber. In this case, horizontal partitions can be established so each regional call center gets only the data it needs.
Using Horizontal Partitioning
Horizontal partitions for a limited number of subscribers are reasonably easy to establish and maintain. In this scenario, we created our schema at the central location, taking care to locate a column or relationship to a table containing a regional indicator in the schema. A separate publication, which contains a clause filtering out only that region's data, is established for each region. A simple column value provides the necessary filtering criteria and no custom synchronization or filter objects need be created. Instead, the articles in the publications are set up with simple filters consisting of a where clause without the keyword WHERE and a view is generated automatically for use in automatic synchronization.
If a remote distributor is desired, set up the distributor first. Using SQL Enterprise Manager, select the server to be configured as the distributor and install replication using the command Server.Replication.Install Publishing. Set up your devices and specify the name of the distribution database you want to create on this server. If a remote distributor is being set up, you need not enable the server as a publisher or subscriber. If a local server is installed, you are given the option of moving immediately to the appropriate dialog boxes to configure the local server as a publisher or subscriber.
For a local distributor, publishers and subscribers can be added through SQL Enterprise Manager. Choose the menu item Server.Replication.Publishing and enable the server as a publisher. You must also enable for publishing all databases you want to publish data from during this process.
If a remote distributor is used, you must select the server to establish as the publisher, and then enable it for replication specifying the newly established distribution as its remote distributor.
Finally, add each of the regional servers as subscribers for this publisher. Again using the SQL Enterprise Manager, choose Server.Replication.Publishing. Enable each appropriate server as a subscriber and enable the associated target database(s) as subscription databases for replication.
Publications can also be established using SQL Enterprise Manager. First select the publisher and then select Manage.Replication.Publications to create or modify publications. To minimize the potential impact of changes to a specific region's data set needs later on, establish a separate publication for each region. We have essentially the same publication—set of published tables—for each regional server, but each article contains a region-specific filter clause to provide horizontal partitioning on the claims and customer information tables. Associated reference tables that must have all of their data distributed to each location can be put in a separate publication to which each regional site subscribes.
Include the tables you want to publish as articles and for each one modify the article options by selecting Edit on the Edit Publications dialog box. In the Manage Article dialog box you should only need to add Restriction clause to specify the horizontal partition you want to establish for the targeted regional subscriber. Restriction clauses take the form of a WHERE clause without the keyword WHERE. In the example, the restriction clause for an article that publishes the claims_header table to a remote site looks like this:
region = 'WEST'
After the necessary publications have been created, you must establish the subscriptions to these publications for each of the regional sites. In our example, we set up a single publication, claim_codes_pub, that contains common data for current claims codes relating to explanation of benefits and a separate publication for each region's customers and claims summary records, claims_eob_pub.
To set up subscriptions through the user interface, you can access Manage.Replication.Subscriptions in SQL Enterprise manager and add subscriptions, specifying the target subscription database for each subscriber. Assuming an initial installation of the application at this point, accept the default Automatic Synchronization option for the subscription so that the schema and initial data set are delivered to the regional server.
When you establish subscriptions to the publications, distribution to the regional servers begins, first with the delivery of your synchronization task and then subsequently with all transactions specific to the region's activities that occurred at the publisher following the generation of the snapshot or initial synchronization set.
Some replication configuration options can be scripted using Distributed Management Objects (DMO) or stored procedures. While SQL Server 6.5 requires SQL Enterprise Manager to enable servers for replication, most other administrative tasks for replication can be performed using stored procedures or DMO. For detailed information about using stored procedures to administer replication in SQL Server 6.5, see the Microsoft SQL Server Transact-SQL Reference. For examples of using SQL-DMO to manage replication administration, see Microsoft SQL Server Programming Distributed Management Objects provided with your SQL Server 6.5 documentation.
Scheduling Task Execution
Default task schedules are established for the log reader and distribution tasks are scheduled by the configuration processes described earlier. The log reader and distributor start when the SQL Executive is started and run continuously until the SQL Executive is stopped. This is sufficient for most applications. However, if you have known down times during which you want the majority of replication activities to occur (remembering that this means latency increases), you can schedule replication tasks at intervals. Scheduled replication tasks are modified using the SQL Enterprise Manager task scheduler.
Also, if you experience periodic network outages or any problems with replication, be aware that continuous (auto start) replication tasks that fail due to problems connecting to a remote location remain stopped until they are specifically restarted using SQL Enterprise Manager or until the publishing SQL Server service is restarted.
In our example, using noncontinuous, scheduled distribution is acceptable because most transaction processing occurs on a known schedule and not in any large volume to critical data on an ad-hoc basis.
Acquiring read-only data from remote locations is common to support warehousing activities or data aggregation at a central location. Unlike data dissemination scenarios, data roll-up implies many publishers and a single subscriber.
The following business problem exists for a retail sales application distributed across several geographical locations with their own inventories. All sales transactions must be aggregated at a central location for auditing and for planning expansion and growth corporate wide.
This business example assumes many retail outlets and a single central site. Each of the retail locations deals with a small subset of data and does not require a particularly powerful server for operations. A systems constraint is that you cannot introduce new hardware at the retail locations because data is rolled up to the corporate location.
Because the remote locations have small amounts of data, there is room for a local distributor at each location. However, it is easier to perform scheduled maintenance activities and minimize the disk space used at each retail outlet if the distributor is located at the central site. Since the retail outlets require a high degree of autonomy in their operations, you establish a series of distributors to service several retail outlets. All of the distributors are located at the central corporate office as is the target subscriber that is the central repository for all sales activities throughout the enterprise.
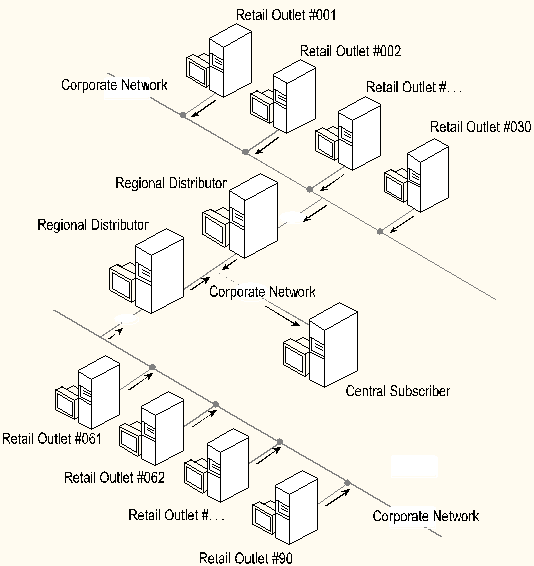
In this scenario, all sites have the same data structure and, because publications are established at the retail outlets, each server is publishing its entire data set. That is, the database design is fully replicated from the remote location to the central server.
The special case here is synchronization. The initial synchronization between each retail outlet and the central location should result in data being added to the set of data that exists at the central subscriber so the central subscriber contains all of the data from throughout the enterprise.
In this example, each of the remote servers must be configured before its corresponding publishers can be set up. The remote distributors are set up in the same manner as the remote server referenced in the section on data dissemination.
Here, you must install replication for each publisher by first selecting the publisher in the SQL Enterprise Manager and then choose the Server.Replication.Install Publishing… option. When asked to specify a distributor, choose the desired remote distributor.
Next, enable the central corporate server as a subscriber for each publisher. Since this is an action that you will do repeatedly for all servers, this part of the configuration process is a good candidate for scripting, and can be accomplished by using stored procedures that are executed on each publisher:
exec sp_addsubscriber @subscriber=<subscriber>, @description='Central Subscriber'
The name of the central subscriber is substituted for <subscriber> in the syntax example.
Then, on each publisher, establish the publication(s) that contain the data you wish to replicate to the central server. This is done using the UI as above in the section on data dissemination except there is no need to establish filters for partitioning and synchronization.
Finally, subscriptions to each publication must be established at the central subscriber. Prior to this action, however, it will be necessary to manually create the schema at the subscriber and populate it with the initial set of data available at all publishers. You can use dump, copy, and load as discussed earlier, or custom scripting of a synchronization script. Then subscriptions can be added for the subscriber specifying the No Sync option when setting up the subscriptions.
Scheduling Task Execution
In this scenario, constant replication of transactional data is desired. The publishers should each have a log reader running continuously to move data to the regional distributor. The distributors should also have an auto start task running continuously to move data to the central subscriber.
Because most of the data changes in this scenario involve sales transactions that provide inserts into the transaction tracking tables assumed to be present in the design, insert row-level locking (IRL) can be used on those tables at the subscriber to minimize the potential for blocking. Blocking can cause costly rollbacks of transactions.