In an age of information overload, client/server computing emerged as the method of choice for culling the ever-growing mountain of data. Relational database engines such as Microsoft SQL Server and Oracle continued to give more and more control over how we viewed and manipulated this data. However, as this newfound power to manipulate data from a PC increased, so did the power necessary to drive these engines.
The client/server architecture seemed to provide the answer. Building on the concepts of modular programming, in which the fundamental assumption is the separation of a large piece of software into its constituent parts (“modules”), engineers developing client/server applications recognized that these modules need not all be executed within the same memory space or even on the same device. In a client/server application, the client module requests a service and the server module provides it.
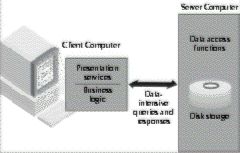
Two-tier client/server The predominant architecture today, two-tier client/server (shown in Figure 2-3) divides applications into two parts. The presentation services and the business logic functions execute at the client PC, while data access functions are handled by a database server on the network. Because two-tier client/server applications are not optimized for dial-up or WAN connections, response times are often unacceptable for remote users. Application upgrades require software and often hardware upgrades to all client PCs, resulting in potential version control problems.
Client devices still require powerful computers.
FIGURE 2-3
The traditional two-tier client/server environment