20.5 The Class java.lang.Character
Here is the whole set! a character dead at every word.
—Richard Brinsley Sheridan, The School for Scandal, Act 2, scene 2
Objects of type Character represent primitive values of type char.
public final class Character {
public static final char MIN_VALUE = '\u0000';
public static final char MAX_VALUE = '\uffff';
public static final int MIN_RADIX = 2;
public static final int MAX_RADIX = 36;
public Character(char value);
public String toString();
public boolean equals(Object obj);
public int hashCode();
public char charValue();
public static boolean isDefined(char ch);
public static boolean isLowerCase(char ch);
public static boolean isUpperCase(char ch);
public static boolean isTitleCase(char ch);
public static boolean isDigit(char ch);
public static boolean isLetter(char ch);
public static boolean isLetterOrDigit(char ch);
public static boolean isJavaLetter(char ch);
public static boolean isJavaLetterOrDigit(char ch);)
public static boolean isSpace(char ch);
public static char toLowerCase(char ch);
public static char toUpperCase(char ch);
public static char toTitleCase(char ch);
public static int digit(char ch, int radix);
public static char forDigit(int digit, int radix);
}
Many of the methods of class Character are defined in terms of a "Unicode attribute table" that specifies a name for every defined Unicode character as well as other possible attributes, such as a decimal value, an uppercase equivalent, a lowercase equivalent, and/or a titlecase equivalent. Prior to Java 1.1, these methods were internal to the Java compiler and based on Unicode 1.1.5, as described here. The most recent versions of these methods should be used in Java compilers that are to run on Java systems that do not yet include these methods.
The Unicode 1.1.5 attribute table is available on the World Wide Web as:
ftp://unicode.org/pub/MappingTables/UnicodeData-1.1.5.txt
However, this file contains a few errors. The term "Unicode attribute table" in the
following sections refers to the contents of this file after the following corrections
have been applied:
- The following entries should have titlecase mappings as shown here:
03D0;GREEK BETA SYMBOL;Ll;0;L;;;;;N;GREEK SMALL LETTER CURLED BETA;;0392;;0392
03D1;GREEK THETA SYMBOL;Ll;0;L;;;;;N;GREEK SMALL LETTER SCRIPT THETA;;0398;;0398
03D5;GREEK PHI SYMBOL;Ll;0;L;;;;;N;GREEK SMALL LETTER SCRIPT PHI;;03A6;;03A6
03D6;GREEK PI SYMBOL;Ll;0;L;;;;;N;GREEK SMALL LETTER OMEGA PI;;03A0;;03A0
03F0;GREEK KAPPA SYMBOL;Ll;0;L;;;;;N;GREEK SMALL LETTER SCRIPT KAPPA;;039A;;039A
03F1;GREEK RHO SYMBOL;Ll;0;L;;;;;N;GREEK SMALL LETTER TAILED RHO;;03A1;;03A1
- The following entries should have numeric values as shown here:
FF10;FULLWIDTH DIGIT ZERO;Nd;0;EN;0030;0;0;0;N;;;;;
FF11;FULLWIDTH DIGIT ONE;Nd;0;EN;0031;1;1;1;N;;;;;
FF12;FULLWIDTH DIGIT TWO;Nd;0;EN;0032;2;2;2;N;;;;;
FF13;FULLWIDTH DIGIT THREE;Nd;0;EN;0033;3;3;3;N;;;;;
FF14;FULLWIDTH DIGIT FOUR;Nd;0;EN;0034;4;4;4;N;;;;;
FF15;FULLWIDTH DIGIT FIVE;Nd;0;EN;0035;5;5;5;N;;;;;
FF16;FULLWIDTH DIGIT SIX;Nd;0;EN;0036;6;6;6;N;;;;;
FF17;FULLWIDTH DIGIT SEVEN;Nd;0;EN;0037;7;7;7;N;;;;;
FF18;FULLWIDTH DIGIT EIGHT;Nd;0;EN;0038;8;8;8;N;;;;;
FF19;FULLWIDTH DIGIT NINE;Nd;0;EN;0039;9;9;9;N;;;;;
- The following entries should have no lowercase equivalents:
03DA;GREEK LETTER STIGMA;Lu;0;L;;;;;N;GREEK CAPITAL LETTER STIGMA;;;;
03DC;GREEK LETTER DIGAMMA;Lu;0;L;;;;;N;GREEK CAPITAL LETTER DIGAMMA;;;;
03DE;GREEK LETTER KOPPA;Lu;0;L;;;;;N;GREEK CAPITAL LETTER KOPPA;;;;
03E0;GREEK LETTER SAMPI;Lu;0;L;;;;;N;GREEK CAPITAL LETTER SAMPI;;;;
- This entry should have uppercase and titlecase equivalents as shown here:
03C2;GREEK SMALL LETTER FINAL SIGMA;Ll;0;L;;;;;N;;;03A3;;03A3
It is anticipated that these problems will be corrected for Unicode version 2.0.
Java 1.1 will include the methods defined here, either based on Unicode 1.1.5 or, we hope, updated versions of the methods that use the newer Unicode 2.0. The character attribute table for Unicode 2.0 is currently available on the World Wide Web as the file:
ftp://unicode.org/pub/MappingTables/UnicodeData-2.0.12.txt
If you are implementing a Java compiler or system, please refer to the page:
http://java.sun.com/Series/
which will be updated with information about the Unicode-dependent methods.
The biggest change in Unicode 2.0 is a complete rearrangement of the Korean Hangul characters. There are numerous smaller improvements as well.
It is our intention that Java will track Unicode as it evolves over time. Given that full Unicode support is just emerging in the marketplace, and that changes in Unicode are in areas which are not yet widely used, this should cause minimal problems and further Java's goal of worldwide language support.
20.5.1 public static final char MIN_VALUE = '\u0000';
The constant value of this field is the smallest value of type char.
[This field is scheduled for introduction in Java version 1.1.]
20.5.2 public static final char MAX_VALUE = '\uffff';
The constant value of this field is the smallest value of type char.
[This field is scheduled for introduction in Java version 1.1.]
20.5.3 public static final int MIN_RADIX = 2;
The constant value of this field is the smallest value permitted for the radix argument in radix-conversion methods such as the digit method (§20.5.23), the
forDigit method (§20.5.24), and the toString method of class Integer
(§20.7).
20.5.4 public static final int MAX_RADIX = 36;
The constant value of this field is the largest value permitted for the radix argument in radix-conversion methods such as the digit method (§20.5.23), the forDigit method (§20.5.24), and the toString method of class Integer (§20.7).
20.5.5 public Character(char value)
This constructor initializes a newly created Character object so that it represents
the primitive value that is the argument.
20.5.6 public String toString()
The result is a String whose length is 1 and whose sole component is the primitive char value represented by this Character object.
Overrides the toString method of Object (§20.1.2).
20.5.7 public boolean equals(Object obj)
The result is true if and only if the argument is not null and is a Character
object that represents the same char value as this Character object.
Overrides the equals method of Object (§20.1.3).
20.5.8 public int hashCode()
The result is the primitive char value represented by this Character object, cast
to type int.
Overrides the hashCode method of Object (§20.1.4).
20.5.9 public char charValue()
The primitive char value represented by this Character object is returned.
20.5.10 public static boolean isDefined(char ch)
The result is true if and only if the character argument is a defined Unicode character.
A character is a defined Unicode character if and only if at least one of the following is true:
- It has an entry in the Unicode attribute table.
- It is not less than
\u3040 and not greater than \u9FA5.
- It is not less than
\uF900 and not greater than \uFA2D.
It follows, then, that for Unicode 1.1.5 as corrected above, the defined Unicode characters are exactly those with codes in the following list, which contains both single codes and inclusive ranges: 0000-01F5, 01FA-0217, 0250-02A8, 02B0-02DE, 02E0-02E9, 0300-0345, 0360-0361, 0374-0375, 037A, 037E, 0384-038A, 038C, 038E-03A1, 03A3-03CE, 03D0-03D6, 03DA, 03DC, 03DE, 03E0, 03E2-03F3, 0401-040C, 040E-044F, 0451-045C, 045E-0486, 0490-04C4, 04C7-04C8, 04CB-04CC, 04D0-04EB, 04EE-04F5, 04F8-04F9, 0531-0556, 0559-055F, 0561-0587, 0589, 05B0-05B9, 05BB-05C3, 05D0-05EA, 05F0-05F4, 060C, 061B, 061F, 0621-063A, 0640-0652, 0660-066D, 0670-06B7, 06BA-06BE, 06C0-06CE, 06D0-06ED, 06F0-06F9, 0901-0903, 0905-0939, 093C-094D, 0950-0954, 0958-0970, 0981-0983, 0985-098C, 098F-0990, 0993-09A8, 09AA-09B0, 09B2, 09B6-09B9, 09BC, 09BE-09C4, 09C7-09C8, 09CB-09CD, 09D7, 09DC-09DD, 09DF-09E3, 09E6-09FA, 0A02, 0A05-0A0A, 0A0F-0A10, 0A13-0A28, 0A2A-0A30, 0A32-0A33, 0A35-0A36, 0A38-0A39, 0A3C, 0A3E-0A42, 0A47-0A48, 0A4B-0A4D, 0A59-0A5C, 0A5E, 0A66-0A74, 0A81-0A83, 0A85-0A8B, 0A8D, 0A8F-0A91, 0A93-0AA8, 0AAA-0AB0, 0AB2-0AB3, 0AB5-0AB9, 0ABC-0AC5, 0AC7-0AC9, 0ACB-0ACD, 0AD0, 0AE0, 0AE6-0AEF, 0B01-0B03, 0B05-0B0C, 0B0F-0B10, 0B13-0B28, 0B2A-0B30, 0B32-0B33, 0B36-0B39, 0B3C-0B43, 0B47-0B48, 0B4B-0B4D, 0B56-0B57, 0B5C-0B5D, 0B5F-0B61, 0B66-0B70, 0B82-0B83, 0B85-0B8A, 0B8E-0B90, 0B92-0B95, 0B99-0B9A, 0B9C, 0B9E-0B9F, 0BA3-0BA4, 0BA8-0BAA, 0BAE-0BB5, 0BB7-0BB9, 0BBE-0BC2, 0BC6-0BC8, 0BCA-0BCD, 0BD7, 0BE7-0BF2, 0C01-0C03, 0C05-0C0C, 0C0E-0C10, 0C12-0C28, 0C2A-0C33, 0C35-0C39, 0C3E-0C44, 0C46-0C48, 0C4A-0C4D, 0C55-0C56, 0C60-0C61, 0C66-0C6F, 0C82-0C83, 0C85-0C8C, 0C8E-0C90, 0C92-0CA8, 0CAA-0CB3, 0CB5-0CB9, 0CBE-0CC4, 0CC6-0CC8, 0CCA-0CCD, 0CD5-0CD6, 0CDE, 0CE0-0CE1, 0CE6-0CEF, 0D02-0D03, 0D05-0D0C, 0D0E-0D10, 0D12-0D28, 0D2A-0D39, 0D3E-0D43, 0D46-0D48, 0D4A-0D4D, 0D57, 0D60-0D61, 0D66-0D6F, 0E01-0E3A, 0E3F-0E5B, 0E81-0E82, 0E84, 0E87-0E88, 0E8A, 0E8D, 0E94-0E97, 0E99-0E9F, 0EA1-0EA3, 0EA5, 0EA7, 0EAA-0EAB, 0EAD-0EB9, 0EBB-0EBD, 0EC0-0EC4, 0EC6,
0EC8-0ECD, 0ED0-0ED9, 0EDC-0EDD, 10A0-10C5, 10D0-10F6, 10FB, 1100-1159, 115F-11A2, 11A8-11F9, 1E00-1E9A, 1EA0-1EF9, 1F00-1F15, 1F18-1F1D, 1F20-1F45, 1F48-1F4D, 1F50-1F57, 1F59, 1F5B, 1F5D, 1F5F-1F7D, 1F80-1FB4, 1FB6-1FC4, 1FC6-1FD3, 1FD6-1FDB, 1FDD-1FEF, 1FF2-1FF4, 1FF6-1FFE, 2000-202E, 2030-2046, 206A-2070, 2074-208E, 20A0-20AA, 20D0-20E1, 2100-2138, 2153-2182, 2190-21EA, 2200-22F1, 2300, 2302-237A, 2400-2424, 2440-244A, 2460-24EA, 2500-2595, 25A0-25EF, 2600-2613, 261A-266F, 2701-2704, 2706-2709, 270C-2727, 2729-274B, 274D, 274F-2752, 2756, 2758-275E, 2761-2767, 2776-2794, 2798-27AF, 27B1-27BE, 3000-3037, 303F, 3041-3094, 3099-309E, 30A1-30FE, 3105-312C, 3131-318E, 3190-319F, 3200-321C, 3220-3243, 3260-327B, 327F-32B0, 32C0-32CB, 32D0-32FE, 3300-3376, 337B-33DD, 33E0-33FE, 3400-9FA5, F900-FA2D, FB00-FB06, FB13-FB17, FB1E-FB36, FB38-FB3C, FB3E, FB40-FB41, FB43-FB44, FB46-FBB1, FBD3-FD3F, FD50-FD8F, FD92-FDC7, FDF0-FDFB, FE20-FE23, FE30-FE44, FE49-FE52, FE54-FE66, FE68-FE6B, FE70-FE72, FE74, FE76-FEFC, FEFF, FF01-FF5E, FF61-FFBE, FFC2-FFC7, FFCA-FFCF, FFD2-FFD7, FFDA-FFDC, FFE0-FFE6, FFE8-FFEE, FFFD.
[This method is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5.]
20.5.11 public static boolean isLowerCase(char ch)
The result is true if and only if the character argument is a lowercase character.
A character is considered to be lowercase if and only if all of the following are true:
- The character
ch is not in the range \u2000 through \u2FFF.
- The Unicode attribute table does not specify a mapping to lowercase for this character (the purpose of this requirement is to exclude titlecase characters).
- At least one of the following is true:
- The Unicode attribute table specifies a mapping to uppercase for this character.
- The name for the character in the Unicode attribute table contains the words
SMALL LETTER or the words SMALL LIGATURE.
It follows, then, that for Unicode 1.1.5 as corrected above, the lowercase Unicode characters are exactly those with codes in the following list, which contains both single codes and inclusive ranges: 0061-007A, 00DF-00F6, 00F8-00FF, 0101-0137 (odds only), 0138-0148 (evens only), 0149-0177 (odds only), 017A-017E (evens only), 017F-0180, 0183, 0185, 0188, 018C-018D, 0192, 0195, 0199-019B, 019E, 01A1-01A5 (odds only), 01A8, 01AB, 01AD, 01B0, 01B4, 01B6, 01B9-01BA, 01BD, 01C6, 01C9, 01CC-01DC (evens only), 01DD-01EF (odds only), 01F0, 01F3, 01F5, 01FB-0217 (odds only), 0250-0261, 0263-0269, 026B-0273, 0275, 0277-027F, 0282-028E, 0290-0293, 029A, 029D-029E, 02A0, 02A3-02A8, 0390, 03AC-03CE, 03D0-03D1, 03D5-03D6, 03E3-03EF (odds only), 03F0-03F1, 0430-044F, 0451-045C, 045E-045F, 0461-0481 (odds only), 0491-04BF (odds only), 04C2, 04C4, 04C8,
04CC, 04D1-04EB (odds only), 04EF-04F5 (odds only), 04F9, 0561-0587, 1E01-1E95 (odds only), 1E96-1E9A, 1EA1-1EF9 (odds only), 1F00-1F07, 1F10-1F15, 1F20-1F27, 1F30-1F37, 1F40-1F45, 1F50-1F57, 1F60-1F67, 1F70-1F7D, 1F80-1F87, 1F90-1F97, 1FA0-1FA7, 1FB0-1FB4, 1FB6-1FB7, 1FC2-1FC4, 1FC6-1FC7, 1FD0-1FD3, 1FD6-1FD7, 1FE0-1FE7, 1FF2-1FF4, 1FF6-1FF7, FB00-FB06, FB13-FB17, FF41-FF5A.
Of the first 128 Unicode characters, exactly 26 are considered to be lowercase:
abcdefghijklmnopqrstuvwxyz
[This specification for the method isLowerCase is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5. In previous versions of Java, this method returns false for all arguments larger than \u00FF.]
20.5.12 public static boolean isUpperCase(char ch)
The result is true if and only if the character argument is an uppercase character.
A character is considered to be uppercase if and only if all of the following are true:
- The character
ch is not in the range \u2000 through \u2FFF.
- The Unicode attribute table does not specify a mapping to uppercase for this character (the purpose of this requirement is to exclude titlecase characters).
- At least one of the following is true:
- The Unicode attribute table specifies a mapping to lowercase for this character.
- The name for the character in the Unicode attribute table contains the words
CAPITAL LETTER or the words CAPITAL LIGATURE.
It follows, then, that for Unicode 1.1.5 as corrected above, the uppercase Unicode characters are exactly those with codes in the following list, which contains both single codes and inclusive ranges: 0041-005A, 00C0-00D6, 00D8-00DE, 0100-0136 (evens only), 0139-0147 (odds only), 014A-0178 (evens only), 0179-017D (odds only), 0181-0182, 0184, 0186, 0187, 0189-018B, 018E-0191, 0193-0194, 0196-0198, 019C-019D, 019F-01A0, 01A2, 01A4, 01A7, 01A9, 01AC, 01AE, 01AF, 01B1-01B3, 01B5, 01B7, 01B8, 01BC, 01C4, 01C7, 01CA, 01CD-01DB (odds only), 01DE-01EE (evens only), 01F1, 01F4, 01FA-0216 (evens only), 0386, 0388-038A, 038C, 038E, 038F, 0391-03A1, 03A3-03AB, 03E2-03EE (evens only), 0401-040C, 040E-042F, 0460-0480 (evens only), 0490-04BE (evens only), 04C1, 04C3, 04C7, 04CB, 04D0-04EA (evens only), 04EE-04F4 (evens only), 04F8, 0531-0556, 10A0-10C5, 1E00-1E94 (evens only),
1EA0-1EF8 (evens only), 1F08-1F0F, 1F18-1F1D, 1F28-1F2F, 1F38-1F3F, 1F48-1F4D, 1F59-1F5F (odds only), 1F68-1F6F, 1F88-1F8F, 1F98-1F9F, 1FA8-1FAF, 1FB8-1FBC, 1FC8-1FCC, 1FD8-1FDB, 1FE8-1FEC, 1FF8-1FFC, FF21-FF3A.
Of the first 128 Unicode characters, exactly 26 are considered to be uppercase:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
[This specification for the method isUpperCase is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5. In previous versions of Java, this method returns false for all arguments larger than \u00FF.]
20.5.13 public static boolean isTitleCase(char ch)
The result is true if and only if the character argument is a titlecase character.
The notion of "titlecase" was introduced into Unicode to handle a peculiar situation: there are single Unicode characters whose appearance in each case looks exactly like two ordinary Latin letters. For example, there is a single Unicode character `LJ' (\u01C7) that looks just like the characters `L' and `J' put together. There is a corresponding lowercase letter `lj' (\u01C9) as well. These characters are present in Unicode primarily to allow one-to-one translations from the Cyrillic alphabet, as used in Serbia, for example, to the Latin alphabet. Now suppose the word "LJUBINJE" (which has six characters, not eight, because two of them are the single Unicode characters `LJ' and `NJ', perhaps produced by one-to-one translation from the Cyrillic) is to be written as part of a book title, in capitals and lowercase. The strategy of making the first letter uppercase and the rest lowercase results in "LJubinje"-most unfortunate. The solution is that there must be a third form, called a titlecase form. The titlecase form of `LJ' is `Lj' (\u01C8) and the titlecase form of `NJ' is `Nj'. A word for a book title is then best rendered by converting the first letter to titlecase if possible, otherwise to uppercase; the remaining letters are then converted to lowercase.
A character is considered to be titlecase if and only if both of the following are true:
- The character
ch is not in the range \u2000 through \u2FFF.
- The Unicode attribute table specifies a mapping to uppercase and a mapping to lowercase for this character.
There are exactly four Unicode 1.1.5 characters for which isTitleCase returns
true:
\u01C5 LATIN CAPITAL LETTER D WITH SMALL LETTER Z WITH CARON
\u01C8 LATIN CAPITAL LETTER L WITH SMALL LETTER J
\u01CB LATIN CAPITAL LETTER N WITH SMALL LETTER J
\u01F2 LATIN CAPITAL LETTER D WITH SMALL LETTER Z
[This method is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5.]
20.5.14 public static boolean isDigit(char ch)
The result is true if and only if the character argument is a digit.
A character is considered to be a digit if and only if both of the following are true:
- The character
ch is not in the range \u2000 through \u2FFF.
- The name for the character in the Unicode attribute table contains the word
DIGIT.
The digits are those characters with the following codes:
0030-0039 ISO-Latin-1 (and ASCII) digits ('0'-'9')
0660-0669 Arabic-Indic digits
06F0-06F9 Eastern Arabic-Indic digits
0966-096F Devanagari digits
09E6-09EF Bengali digits
0A66-0A6F Gurmukhi digits
0AE6-0AEF Gujarati digits
0B66-0B6F Oriya digits
0BE7-0BEF Tamil digits (there are only nine of these-no zero digit)
0C66-0C6F Telugu digits
0CE6-0CEF Kannada digits
0D66-0D6F Malayalam digits
0E50-0E59 Thai digits
0ED0-0ED9 Lao digits
FF10-FF19 Fullwidth digits
Of the first 128 Unicode characters, exactly 10 are considered to be digits:
0123456789
[This specification for the method isDigit is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5. In previous versions of Java, this method returns false for all arguments larger than \u00FF.]
20.5.15 public static boolean isLetter(char ch)
The result is true if and only if the character argument is a letter.
A character is considered to be a letter if and only if it is a letter or digit (§20.5.16) but is not a digit (§20.5.14).
[This method is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5.]
20.5.16 public static boolean isLetterOrDigit(char ch)
The result is true if and only if the character argument is a letter-or-digit.
A character is considered to be a letter-or-digit if and only if it is a defined Unicode character (§20.5.10) and its code lies in one of the following ranges:
0030-0039 ISO-Latin-1 (and ASCII) digits ('0'-'9')
0041-005A ISO-Latin-1 (and ASCII) uppercase Latin letters ('A'-'Z')
0061-007A ISO-Latin-1 (and ASCII) lowercase Latin letters ('a'-'z')
00C0-00D6 ISO-Latin-1 supplementary letters
00D8-00F6 ISO-Latin-1 supplementary letters
00F8-00FF ISO-Latin-1 supplementary letters
0100-1FFF Latin extended-A, Latin extended-B, IPA extensions,
spacing modifier letters, combining diacritical marks, basic
Greek, Greek symbols and Coptic, Cyrillic, Armenian,
Hebrew extended-A, Basic Hebrew, Hebrew extended-B,
Basic Arabic, Arabic extended, Devanagari, Bengali,
Gurmukhi, Gujarati, Oriya, Tamil, Telugu, Kannada,
Malayalam, Thai, Lao, Basic Georgian, Georgian extended,
Hanguljamo, Latin extended additional, Greek extended
3040-9FFF Hiragana, Katakana, Bopomofo, Hangul compatibility
Jamo, CJK miscellaneous, enclosed CJK characters and
months, CJK compatibility, Hangul, Hangul
supplementary-A, Hangul supplementary-B, CJK unified
ideographs
F900-FDFF CJK compatibility ideographs, alphabetic presentation
forms, Arabic presentation forms-A
FE70-FEFE Arabic presentation forms-B
FF10-FF19 Fullwidth digits
FF21-FF3A Fullwidth Latin uppercase
FF41-FF5A Fullwidth Latin lowercase
FF66-FFDC Halfwidth Katakana and Hangul
It follows, then, that for Unicode 1.1.5 as corrected above, the Unicode letters and digits are exactly those with codes in the following list, which contains both single codes and inclusive ranges:
0030-0039, 0041-005A, 0061-007A, 00C0-00D6, 00D8-00F6, 00F8-01F5, 01FA-0217, 0250-02A8, 02B0-02DE, 02E0-02E9, 0300-0345, 0360-0361, 0374-0375, 037A, 037E, 0384-038A, 038C, 038E, 038F-03A1, 03A3-03CE, 03D0-03D6, 03DA-03E2, 03DA, 03DC, 03DE, 03E0, 03E2-03F3, 0401-040C, 040E-044F, 0451-045C, 045E-0486, 0490-04C4, 04C7-04C8, 04CB-04CC, 04D0-04EB, 04EE-04F5, 04F8-04F9, 0531-0556, 0559-055F, 0561-0587, 0589, 05B0-05B9, 05BB-05C3, 05D0-05EA, 05F0-05F4, 060C, 061B, 061F, 0621, 0622-063A, 0640-0652, 0660-066D, 0670-06B7, 06BA-06BE, 06C0-06CE, 06D0-06ED,
06F0-06F9, 0901-0903, 0905-0939, 093C-094D, 0950-0954, 0958-0970, 0981-0983, 0985-098C, 098F-0990, 0993-09A8, 09AA-09B0, 09B2, 09B6-09B9, 09BC, 09BE, 09BF-09C4, 09C7-09C8, 09CB-09CD, 09D7, 09DC-09DD, 09DF-09E3, 09E6-09FA, 0A02, 0A05-0A0A, 0A0F-0A10, 0A13-0A28, 0A2A-0A30, 0A32-0A33, 0A35-0A36, 0A38-0A39, 0A3C, 0A3E, 0A3F-0A42, 0A47-0A48, 0A4B-0A4D, 0A59-0A5C, 0A5E, 0A66-0A74, 0A81-0A83, 0A85-0A8B, 0A8D, 0A8F, 0A90-0A91, 0A93-0AA8, 0AAA-0AB0, 0AB2-0AB3, 0AB5-0AB9, 0ABC-0AC5, 0AC7-0AC9, 0ACB-0ACD, 0AD0, 0AE0, 0AE6-0AEF, 0B01-0B03, 0B05-0B0C, 0B0F-0B10, 0B13-0B28, 0B2A-0B30, 0B32-0B33, 0B36-0B39, 0B3C-0B43,
0B47-0B48, 0B4B-0B4D, 0B56-0B57, 0B5C-0B5D, 0B5F-0B61, 0B66-0B70, 0B82-0B83, 0B85-0B8A, 0B8E-0B90, 0B92-0B95, 0B99-0B9A, 0B9C, 0B9E, 0B9F, 0BA3-0BA4, 0BA8-0BAA, 0BAE-0BB5, 0BB7-0BB9, 0BBE-0BC2, 0BC6-0BC8, 0BCA-0BCD, 0BD7, 0BE7-0BF2, 0C01-0C03, 0C05-0C0C, 0C0E-0C10, 0C12-0C28, 0C2A-0C33, 0C35-0C39, 0C3E-0C44, 0C46-0C48, 0C4A-0C4D, 0C55-0C56, 0C60-0C61, 0C66-0C6F, 0C82-0C83, 0C85-0C8C, 0C8E-0C90, 0C92-0CA8, 0CAA-0CB3, 0CB5-0CB9, 0CBE-0CC4, 0CC6-0CC8, 0CCA-0CCD, 0CD5-0CD6, 0CDE, 0CE0, 0CE1, 0CE6-0CEF, 0D02-0D03, 0D05-0D0C, 0D0E-0D10, 0D12-0D28, 0D2A-0D39, 0D3E-0D43, 0D46-0D48, 0D4A-0D4D, 0D57, 0D60-0D61,
0D66-0D6F, 0E01-0E3A, 0E3F-0E5B, 0E81-0E82, 0E84, 0E87-0E88, 0E8A, 0E8D, 0E94-0E97, 0E99-0E9F, 0EA1-0EA3, 0EA5, 0EA7, 0EAA-0EAB, 0EAD-0EB9, 0EBB-0EBD, 0EC0-0EC4, 0EC6, 0EC8, 0EC9-0ECD, 0ED0-0ED9, 0EDC-0EDD, 10A0-10C5, 10D0-10F6, 10FB, 1100-1159, 115F-11A2, 11A8-11F9, 1E00-1E9A, 1EA0-1EF9, 1F00-1F15, 1F18-1F1D, 1F20-1F45, 1F48-1F4D, 1F50-1F57, 1F59, 1F5B, 1F5D, 1F5F-1F7D, 1F80-1FB4, 1FB6-1FC4, 1FC6-1FD3, 1FD6-1FDB, 1FDD-1FEF, 1FF2-1FF4, 1FF6-1FFE, 3041-3094, 3099-309E, 30A1-30FE, 3105-312C, 3131-318E, 3190-319F, 3200-321C, 3220-3243, 3260-327B, 327F-32B0, 32C0-32CB, 32D0-32FE, 3300-3376, 337B-33DD,
33E0-33FE,
3400-9FA5, F900-FA2D, FB00-FB06, FB13-FB17, FB1E-FB36, FB38-FB3C, FB3E, FB40, FB41, FB43, FB44, FB46, FB47-FBB1, FBD3-FD3F, FD50-FD8F, FD92-FDC7, FDF0-FDFB, FE70-FE72, FE74, FE76, FE77-FEFC, FF10-FF19, FF21-FF3A, FF41-FF5A, FF66-FFBE, FFC2-FFC7, FFCA-FFCF, FFD2-FFD7, FFDA-FFDC.
[This method is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5.]
20.5.17 public static boolean isJavaLetter(char ch)
The result is true if and only if the character argument is a character that can begin
a Java identifier.
A character is considered to be a Java letter if and only if it is a letter (§20.5.15) or is the dollar sign character '$' (\u0024) or the underscore ("low line") character '_' (\u005F).
[This method is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5.]
20.5.18 public static boolean isJavaLetterOrDigit(char ch)
The result is true if and only if the character argument is a character that can occur
in a Java identifier after the first character.
A character is considered to be a Java letter-or-digit if and only if it is a letter-or-digit (§20.5.16) or is the dollar sign character '$' (\u0024) or the underscore ("low line") character '_' (\u005F).
[This method is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5.]
20.5.19 public static boolean isSpace(char ch)
The result is true if the argument ch is one of the following characters:
'\t' \u0009 HT HORIZONTAL TABULATION
'\n' \u000A LF LINE FEED (also known as NEW LINE)
'\f' \u000C FF FORM FEED
'\r' \u000D CR CARRIAGE RETURN
' ' \u0020 SP SPACE
Otherwise, the result is false.
20.5.20 public static char toLowerCase(char ch)
If the character ch has a lowercase equivalent specified in the Unicode attribute
table, then that lowercase equivalent character is returned. Otherwise, the argument ch is returned.
The lowercase equivalents specified in the Unicode attribute table, for Unicode 1.1.5 as corrected above, are as follows, where character codes to the right of arrows are the lowercase equivalents of character codes to the left of arrows: 0041-005A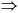 0061-007A, 00C0-00D600E0-00F6, 00D8-00DE00F8-00FE, 0100-012E0101-012F (evens to odds), 0132-01360133-0137 (evens to odds), 0139-0147013A-0148 (odds to evens), 014A-0176014B-0177 (evens to odds), 017800FF, 0179-017D017A-017E (odds to evens), 01810253, 01820183, 01840185, 01860254, 01870188, 018A0257, 018B018C, 018E0258, 018F0259, 0190025B, 01910192, 01930260,
01940263, 01960269, 01970268, 01980199, 019C026F, 019D0272, 01A0-01A401A1-01A5 (evens to odds), 01A701A8, 01A90283, 01AC01AD, 01AE0288, 01AF01B0, 01B1028A, 01B2028B, 01B301B4, 01B501B6, 01B70292, 01B801B9, 01BC01BD, 01C401C6, 01C501C6, 01C701C9, 01C801C9, 01CA01CC, 01CB-01DB01CC-01DC (odds to evens), 01DE-01EE01DF-01EF (evens to odds), 01F101F3, 01F201F3,
01F401F5,
01FA-021601FB-0217 (evens to odds), 038603AC, 0388-038A03AD-03AF, 038C03CC, 038E03CD, 038F03CE, 0391-03A103B1-03C1, 03A3-03AB03C3-03CB, 03E2-03EE03E3-03EF (evens to odds), 0401-040C0451-045C, 040E045E, 040F045F, 0410-042F0430-044F, 0460-04800461-0481 (evens to odds), 0490-04BE0491-04BF (evens to odds), 04C104C2, 04C304C4, 04C704C8, 04CB04CC, 04D0-04EA04D1-04EB (evens to odds), 04EE-04F404EF-04F5 (evens to odds), 04F804F9, 0531-05560561-0586,
10A0-10C510D0-10F5, 1E00-1E941E01-1E95 (evens to odds), 1EA0-1EF81EA1-1EF9 (evens to odds), 1F08-1F0F1F00-1F07, 1F18-1F1D1F10-1F15, 1F28-1F2F1F20-1F27, 1F38-1F3F1F30-1F37, 1F48-1F4D1F40-1F45, 1F591F51, 1F5B1F53, 1F5D1F55, 1F5F1F57, 1F68-1F6F1F60-1F67, 1F88-1F8F1F80-1F87, 1F98-1F9F1F90-1F97, 1FA8-1FAF1FA0-1FA7, 1FB81FB0, 1FB91FB1, 1FBA1F70, 1FBB1F71, 1FBC1FB3, 1FC8-1FCB1F72-1F75, 1FCC1FC3,
1FD81FD0,
1FD91FD1, 1FDA1F76, 1FDB1F77, 1FE81FE0, 1FE91FE1, 1FEA1F7A, 1FEB1F7B, 1FEC1FE5, 1FF81F78, 1FF91F79, 1FFA1F7C, 1FFB1F7D, 1FFC1FF3, 2160-216F2170-217F, 24B6-24CF24D0-24E9, FF21-FF3AFF41-FF5A.
0061-007A, 00C0-00D600E0-00F6, 00D8-00DE00F8-00FE, 0100-012E0101-012F (evens to odds), 0132-01360133-0137 (evens to odds), 0139-0147013A-0148 (odds to evens), 014A-0176014B-0177 (evens to odds), 017800FF, 0179-017D017A-017E (odds to evens), 01810253, 01820183, 01840185, 01860254, 01870188, 018A0257, 018B018C, 018E0258, 018F0259, 0190025B, 01910192, 01930260,
01940263, 01960269, 01970268, 01980199, 019C026F, 019D0272, 01A0-01A401A1-01A5 (evens to odds), 01A701A8, 01A90283, 01AC01AD, 01AE0288, 01AF01B0, 01B1028A, 01B2028B, 01B301B4, 01B501B6, 01B70292, 01B801B9, 01BC01BD, 01C401C6, 01C501C6, 01C701C9, 01C801C9, 01CA01CC, 01CB-01DB01CC-01DC (odds to evens), 01DE-01EE01DF-01EF (evens to odds), 01F101F3, 01F201F3,
01F401F5,
01FA-021601FB-0217 (evens to odds), 038603AC, 0388-038A03AD-03AF, 038C03CC, 038E03CD, 038F03CE, 0391-03A103B1-03C1, 03A3-03AB03C3-03CB, 03E2-03EE03E3-03EF (evens to odds), 0401-040C0451-045C, 040E045E, 040F045F, 0410-042F0430-044F, 0460-04800461-0481 (evens to odds), 0490-04BE0491-04BF (evens to odds), 04C104C2, 04C304C4, 04C704C8, 04CB04CC, 04D0-04EA04D1-04EB (evens to odds), 04EE-04F404EF-04F5 (evens to odds), 04F804F9, 0531-05560561-0586,
10A0-10C510D0-10F5, 1E00-1E941E01-1E95 (evens to odds), 1EA0-1EF81EA1-1EF9 (evens to odds), 1F08-1F0F1F00-1F07, 1F18-1F1D1F10-1F15, 1F28-1F2F1F20-1F27, 1F38-1F3F1F30-1F37, 1F48-1F4D1F40-1F45, 1F591F51, 1F5B1F53, 1F5D1F55, 1F5F1F57, 1F68-1F6F1F60-1F67, 1F88-1F8F1F80-1F87, 1F98-1F9F1F90-1F97, 1FA8-1FAF1FA0-1FA7, 1FB81FB0, 1FB91FB1, 1FBA1F70, 1FBB1F71, 1FBC1FB3, 1FC8-1FCB1F72-1F75, 1FCC1FC3,
1FD81FD0,
1FD91FD1, 1FDA1F76, 1FDB1F77, 1FE81FE0, 1FE91FE1, 1FEA1F7A, 1FEB1F7B, 1FEC1FE5, 1FF81F78, 1FF91F79, 1FFA1F7C, 1FFB1F7D, 1FFC1FF3, 2160-216F2170-217F, 24B6-24CF24D0-24E9, FF21-FF3AFF41-FF5A.
Note that the method isLowerCase (§20.5.11) will not necessarily return true when given the result of the toLowerCase method.
[This specification for the method toLowerCase is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5. In previous versions of Java, this method returns its argument for all arguments larger than \u00FF.]
20.5.21 public static char toUpperCase(char ch)
If the character ch has an uppercase equivalent specified in the Unicode attribute
table, then that uppercase equivalent character is returned. Otherwise, the argument ch is returned.
The uppercase equivalents specified in the Unicode attribute table for Unicode 1.1.5 as corrected above, are as follows, where character codes to the right of arrows are the uppercase equivalents of character codes to the left of arrows:
0061-007A0041-005A, 00E0-00F600C0-00D6, 00F8-00FE00D8-00DE, 00FF0178, 0101-012F0100-012E (odds to evens), 0133-01370132-0136 (odds to evens), 013A-01480139-0147 (evens to odds), 014B-0177014A-0176 (odds to evens), 017A-017E0179-017D (evens to odds), 017F0053, 0183-01850182-0184 (odds to evens), 01880187, 018C018B, 01920191, 01990198, 01A1-01A501A0-01A4 (odds to evens), 01A801A7, 01AD01AC, 01B001AF, 01B401B3,
01B601B5, 01B901B8, 01BD01BC, 01C501C4, 01C601C4, 01C801C7, 01C901C7, 01CB01CA, 01CC01CA, 01CE-01DC01CD-01DB (evens to odds), 01DF-01EF01DE-01EE (odds to evens), 01F201F1, 01F301F1, 01F501F4, 01FB-021701FA-0216 (odds to evens), 02530181, 02540186, 0257018A, 0258018E, 0259018F, 025B0190, 02600193, 02630194, 02680197, 02690196, 026F019C, 0272019D, 028301A9,
028801AE, 028A01B1, 028B01B2, 029201B7, 03AC0386, 03AD-03AF0388-038A, 03B1-03C10391-03A1, 03C203A3, 03C3-03CB03A3-03AB, 03CC038C, 03CD038E, 03CE038F, 03D00392, 03D10398, 03D503A6, 03D603A0, 03E3-03EF03E2-03EE (odds to evens), 03F0039A, 03F103A1, 0430-044F0410-042F, 0451-045C0401-040C, 045E040E, 045F040F, 0461-04810460-0480 (odds to evens), 0491-04BF0490-04BE (odds to evens),
04C204C1,
04C404C3, 04C804C7, 04CC04CB, 04D1-04EB04D0-04EA (odds to evens), 04EF-04F504EE-04F4 (odds to evens), 04F904F8, 0561-05860531-0556, 1E01-1E951E00-1E94 (odds to evens), 1EA1-1EF91EA0-1EF8 (odds to evens), 1F00-1F071F08-1F0F, 1F10-1F151F18-1F1D, 1F20-1F271F28-1F2F, 1F30-1F371F38-1F3F, 1F40-1F451F48-1F4D, 1F511F59, 1F531F5B, 1F551F5D, 1F571F5F, 1F60-1F671F68-1F6F, 1F701FBA, 1F711FBB, 1F72-1F751FC8-1FCB, 1F761FDA,
1F771FDB,
1F781FF8, 1F791FF9, 1F7A1FEA, 1F7B1FEB, 1F7C1FFA, 1F7D1FFB, 1F80-1F871F88-1F8F, 1F90-1F971F98-1F9F, 1FA0-1FA71FA8-1FAF, 1FB01FB8, 1FB11FB9, 1FB31FBC, 1FC31FCC, 1FD01FD8, 1FD11FD9, 1FE01FE8, 1FE11FE9, 1FE51FEC, 1FF31FFC, 2170-217F2160-216F, 24D0-24E924B6-24CF, FF41-FF5AFF21-FF3A.
Note that the method isUpperCase (§20.5.12) will not necessarily return true when given the result of the toUpperCase method.
[This specification for the method toUpperCase is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5. In previous versions of Java, this method returns its argument for all arguments larger than \u00FE. Note that although \u00FF is a lowercase character, its uppercase equivalent is \u0178; toUpperCase in versions of Java prior to version 1.1 simply do not consistently handle or use Unicode character codes above \u00FF.]
20.5.22 public static char toTitleCase(char ch)
If the character ch has a titlecase equivalent specified in the Unicode attribute
table, then that titlecase equivalent character is returned; otherwise, the argument
ch is returned.
Note that the method isTitleCase (§20.5.13) will not necessarily return true when given the result of the toTitleCase method. The Unicode attribute table always has the titlecase attribute equal to the uppercase attribute for characters that have uppercase equivalents but no separate titlecase form.
Example: Character.toTitleCase('a') returns 'A'
Example: Character.toTitleCase('Q') returns 'Q'
Example: Character.toTitleCase('lj') returns 'Lj' where 'lj' is the Unicode character \u01C9 and 'Lj' is its titlecase equivalent character \u01C8.
[This method is scheduled for introduction in Java version 1.1.]
20.5.23 public static int digit(char ch, int radix)
Returns the numeric value of the character ch considered as a digit in the specified
radix. If the value of radix is not a valid radix, or the character ch is not a valid
digit in the specified radix, then -1 is returned.
A radix is valid if and only if its value is not less than Character.MIN_RADIX (§20.5.3) and not greater than Character.MAX_RADIX (§20.5.4).
A character is a valid digit if and only if one of the following is true:
- The method
isDigit returns true for the character, and the decimal digit value of the character, as specified in the Unicode attribute table, is less than the specified radix. In this case, the decimal digit value is returned.
- The character is one of the uppercase Latin letters
'A'-'Z' (\u0041-\u005A) and its code is less than radix+'A'-10. In this case ch-'A'+10 is returned.
- The character is one of the lowercase Latin letters
'a'-'z' (\u0061-\u007A) and its code is less than radix+'a'-10. In this case ch-'a'+10 is returned.
[This specification for the method digit is scheduled for introduction in Java version 1.1, either as defined here, or updated for Unicode 2.0; see §20.5. In previous versions of Java, this method returns -1 for all character codes larger than \u00FF.]
20.5.24 public static char forDigit(int digit, int radix)
Returns a character that represents the given digit in the specified radix. If the
value of radix is not a valid radix, or the value of digit is not a valid digit in the
specified radix, the null character '\u0000' is returned.
A radix is valid if and only if its value is not less than Character.MIN_RADIX (§20.5.3) and not greater than Character.MAX_RADIX (§20.5.4).
A digit is valid if and only if it is nonnegative and less than the radix.
If the digit is less than 10, then the character value '0'+digit is returned; otherwise, 'a'+digit-10 is returned. Thus, the digits produced by forDigit, in increasing order of value, are the ASCII characters:
0123456789abcdefghijklmnopqrstuvwxyz
(these are '\u0030' through '\u0039' and '\u0061' through '\u007a'). If
uppercase letters are desired, the toUpperCase method may be called on the
result:
Character.toUpperCase(Character.forDigit(digit, radix))