3.3 Unicode Escapes
Java implementations first recognize Unicode escapes in their input, translating
the ASCII characters \u followed by four hexadecimal digits to the Unicode character with the indicated hexadecimal value, and passing all other characters
unchanged. This translation step results in a sequence of Unicode input characters:
UnicodeInputCharacter:
UnicodeEscape
RawInputCharacter
UnicodeEscape:
\ UnicodeMarker HexDigit HexDigit HexDigit HexDigit
UnicodeMarker:
u
UnicodeMarker u
RawInputCharacter:
any Unicode character
HexDigit: one of
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
The \, u, and hexadecimal digits here are all ASCII characters.
In addition to the processing implied by the grammar, for each raw input character that is a backslash \, input processing must consider how many other \ characters contiguously precede it, separating it from a non-\ character or the start of the input stream. If this number is even, then the \ is eligible to begin a Unicode escape; if the number is odd, then the \ is not eligible to begin a Unicode escape. For example, the raw input "\\u2297=\u2297" results in the eleven characters " \ \ u 2 2 9 7 = 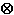
" (\u2297 is the Unicode encoding of the character "").
If an eligible \ is not followed by u, then it is treated as a RawInputCharacter and remains part of the escaped Unicode stream. If an eligible \ is followed by u, or more than one u, and the last u is not followed by four hexadecimal digits, then a compile-time error occurs.
The character produced by a Unicode escape does not participate in further Unicode escapes. For example, the raw input \u005cu005a results in the six characters \ u 0 0 5 a, because 005c is the Unicode value for \. It does not result in the character Z, which is Unicode character 005a, because the \ that resulted from the \u005c is not interpreted as the start of a further Unicode escape.
Java specifies a standard way of transforming a Unicode Java program into ASCII that changes a Java program into a form that can be processed by ASCII-based tools. The transformation involves converting any Unicode escapes in the source text of the program to ASCII by adding an extra u-for example, \uxxxx becomes \uuxxxx-while simultaneously converting non-ASCII characters in the source text to a \uxxxx escape containing a single u. This transformed version is equally acceptable to a Java compiler and represents the exact same program. The exact Unicode source can later be restored from this ASCII form by converting each escape sequence where multiple u's are present to a sequence of Unicode characters with one fewer u, while simultaneously converting each escape sequence with a single u to the corresponding single Unicode character.
Java systems should use the \uxxxx notation as an output format to display Unicode characters when a suitable font is not available.