
APE models remote deployment using two separate components working closely together: a worker and a service. This is good component-based design, separating the execution context (worker) from the actual computational routines or business services (service). Since remote components are most efficiently packaged as in-process servers, they need a process space on the remote machine in which to execute. The worker component provides this process space and execution thread, while the service encapsulates the application-specific functionality.
As with all remote components, the resource capacity of the remote machine often limits the amount of work that can be done. In order to use remote components as part of a high-performance enterprise application, you must understand APE's three basic remote deployment models and how they affect your application's performance. These are:
The following sections will acquaint you with the important remote deployment design concepts that you can configure and test using Application Performance Explorer.
The Application Performance Explorer implements synchronous connections as a direct request from a client application to an object that lives on a remote network server. Because the connection is synchronous, the client application waits for the task to be completed and is blocked until the server returns.
In step 1 of the preceding illustration, the client creates a worker, which in turn creates a service that performs the work. When the service is finished, both the worker and service are destroyed. In step 2, additional clients create additional workers and services, never sharing them with other clients.
Direct object instantiation and executing repeated calls on a method is most useful for exploring network latency. Changing calling parameters and return value sizes can help determine network throughput, which can be useful in deciding which components should be run across a network on remote computers and which should remain together on a single machine.
One of the limitations of the synchronous approach is the overhead involved in starting the worker and service objects. When a client is done with a worker, both the worker and service are destroyed.
Without queuing, when a burst of requests comes in the object pool starts growing, the objects can't recycle fast enough, and the new object allocations rapidly degrade the server into a thrashing state. Without queuing, you must have sufficient memory on the server to deal with the absolute peak load, which is often many times more than the hardware needed for normal processing loads.
The asynchronous communication model keeps workers "alive" and reduces the overhead of initializing them. There are a number of approaches to this, including pool manager and queue manager scenarios. APE implements a queue manager as shown below.

In the simplest case, in step 1 the queue manager creates a given number of workers, all of them initially having a "not busy" status. In step 2, when a client request comes in, the queue manager allocates a worker and marks it as "busy." In step 3, the queue manager uses the worker to perform the service until it is completed, and changes its status back to "not busy." In step 4, the queue manager accepts all requests and allocates workers on a first-come, first-served basis.
Because the queue manager maintains its queue internally, client requests are never refused. If all pre-allocated workers are busy, the queue manager simply waits until one becomes available and assigns it to the next waiting client in turn. In distributed solutions, such a queue can be used to keep workers busy. This results in servers running at their optimum performance level — that is, fully loaded.
The choice to communicate asynchronously has another particular advantage: if the receiver is not running at the same time as the server, synchronous communication attempts will always fail; asynchronous communications can still succeed.
The performance value of queuing is that it allows your hardware to work at capacity without mismanagement or inefficient use. A side benefit of queuing is that, during peak workloads, the application's throughput degrades gracefully. Queuing is an important design concept required for high-performance, robust applications.
It's important to notice that this asynchronous deployment model has no provision for either returning status information to the client or logging transaction information for administrative purposes.
Note Although the current implementation of APE does not directly use Microsoft Message Queue Server (MSMQ) during performance test runs, APE does have a configurable Job Manager queue that can be adjusted to realistically model your application as if it were actually using MSMQ.
For More Information For more information on why queuing is an important design concept, see Performance Value Of Service Queuing with MSMQ. Microsoft Message Queue Server (MSMQ) is available in the Windows NT Service Pack 4. For more information on installing and using Microsoft Message Queue Server, see information about Windows NT Server at the Microsoft Web site at http://www.microsoft.com/ntserver/.
The queued objects model with callbacks has provision for either returning status information to the client or logging transaction information for administrative purposes.
In general, return information can be conveyed in one of two ways: either synchronously through a return value, or asynchronously through an indirect notification mechanism. The synchronous (direct) method results in the client program being blocked waiting for the return to complete. For asynchronous operations, a separate notification mechanism is required. Callbacks, available in Visual Basic, provide such a mechanism. Callbacks allow the client to continue processing and be notified asynchronously when the server side has something relevant to report.
To use callbacks in the queue model, an additional component, the expediter, is used to queue return information back to the client.
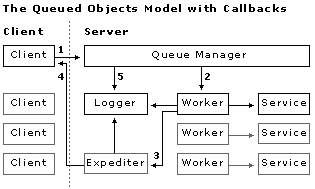
In operation, the client implements an internal Callback class with a predefined method. In step 1, the client then creates an instance of that callback object and passes a pointer to it to the queue manager, along with its work request. In step 2, the queue manager in turn calls the worker, passing the callback object pointer. In step 3, when the task is completed, the worker returns information to the queuing manager, once again passing along the pointer to the callback object. In step 4, the expediter calls back asynchronously into the client object.
Notice that this diagram also illustrates the queue manager, worker, and expediter all feeding into a logger.