By Stephen Rauch
September 1997
Universal Data Access is a set of common interfaces that anyone can use to represent data kept in relational databases, spreadsheets, project and document containers, VSAM, email, or file systems. The data stores simply expose a common data access model to the data.
This article assumes you’re familiar with database programming and OLE
Stephen Rauch is a Technical Evangelist in the Developer Relations Group at Microsoft. He can be reached at srauch@microsoft.com.
If you've ever developed applications that access data from data stores, you have been exposed to a bowl of alphabet soup: ODBC, RDO, DAO, and so on. Many other APIs are used to access things like telephony, email, and file systems. They're all related to getting some kind of information—data.
The Microsoft data access strategy called Universal Data Access provides access to all types of data through a single data access model. Let's explore Universal Data Access and how the alphabet soup fits into the Microsoft strategy. First, let's take a look at a problem both users and developers face when accessing information.
The data you use to make business decisions every day is a lot more than just data stored in a relational database. It typically includes personal data in spreadsheets, project management applications, email, mainframe data such as VSAM and AS/400, computed data calculated on-the-fly, and ISAM data. Add to that information available in directory services, documents available on your hard drive or on the network, and the wealth of data in myriad forms on the Internet. Each of these types of data needs to be taken into account when making decisions, yet each is in a different format, stored in a variety of containers, and accessed in a fundamentally different way.
Suppose that I am the project manager responsible for delivering a prototype of the new space shuttle. To prepare for a status meeting, I need to collect information from a variety of sources. Microsoft® Project does a great job of managing scheduling information, so I have a number of project files that describe who is allocated to what tasks, whether they are ahead or behind schedule, and so forth.
Reviewing the project I see that the team responsible for the propulsion unit has continuously added resources to the project but is continuing to fall behind. After identifying the tasks that are causing the team to slip, I do a search on the technical documents describing those tasks. From the information obtained in the technical documents, I do a search of my email folders to find all the related mail that discusses the project and the potential cause for it falling behind. I find a message that refers to a delay in receiving some critical parts for the thruster. The millions of parts that make up the shuttle are inventoried in a SQL Server™ database, so I search for the subset of parts used for the thruster, then compare that to my invoices kept in an Access database. After finding the invoice for the missing parts, I do a Web search for information about the supplying manufacturer and discover that they were involved in a takeover two months before the invoice due date. Further searching on the Web reveals two other companies that manufacture the same components.
Now that I've collected all the information from various resources, discovered the reason for the delay, and struck a quick deal with one of the other manufacturers, I want to make some changes. Let's start by updating all of the parts from the old manufacturer to the new supplier. To make this change, I need to update information in my inventory database, the project specification, and outstanding invoices. I have to make these changes to all sources of data that are related to the project in a safe way. I don't want the changes to be applied in two places and fail in the other two. I need the same type of transactional semantics I get in a single data store even when the data is located in different containers.
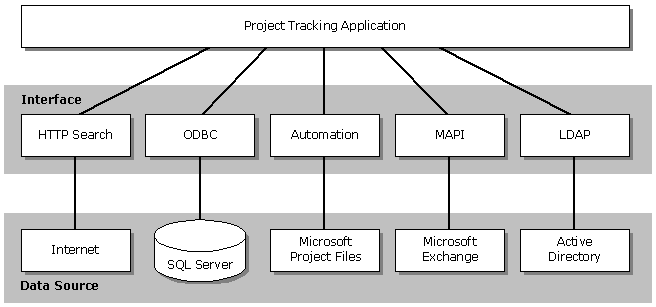
Figure 1 Project Tracking Application
So how might this work? I would probably have a project tracking application to display and analyze project information (see Figure 1). The project tracking application would use OLE automation to get to the high-level project information stored in the Microsoft Project files. Then I'd use file system interfaces to search for documents on my hard drive, MAPI to get information from the Microsoft® Exchange data store, ODBC to get information from the SQL Server, and some HTTP search protocol to find information on the Internet.
In this case, the project tracking application utilizes at least five separate APIs to access the different types of data. Some of the interfaces are COM interfaces and some of them are not; some of them expose Automation interfaces and some are procedural. In addition, transactional control does not exist, so I cannot safely make any changes to all of the information within one transaction.
What all of this means is that the developers who write the project tracking application will have to become experts in a multitude of data access methods. Is there a better way? Well, one solution is to put all of the different types of data into a single relational data store. That is, take the SQL data store and incorporate the project data, email data, directory data, and information from the Internet and move it into a single vendor's relational database. This approach solves the problem of having a single API that also gives you transactional control—but it has a number of compromises.
First, it requires moving huge amounts of data. Second, you typically don't own much of the data you need, such as the wealth of information on the Internet. The next problem with moving the data into a single data store is that tools today don't look for or store data into a single relational data store. Email applications, project management tools, spreadsheets, and other tools look into their own data stores for their data. You'd have to rewrite your tools to access the data in the single data store or duplicate the data to the single data store from where it naturally lives—then you run into problems with synchronizing the data. Another problem is that one size does not fit all. The way that relational databases deal with data is not the best way to deal with all types of data. Data (structured, semi-structured, and unstructured) is stored in different containers based on how the data is used, viewed, managed, and accessed. Finally, the performance and query requirements are going to differ by data type depending on what it is you are trying to do.
If you can't have all of your data in a single data store, what's the alternative? The Microsoft alternative is called Universal Data Access. With Universal Data Access, you get to data in different data stores through a common set of interfaces, regardless of where the data resides. Your application speaks to a common set of interfaces that generalize the concept of data. Microsoft examined what all types of data have in common, such as how you navigate, represent, bind, use, and share that data with other components. The result is a set of common interfaces that anyone can use to represent data kept in relational databases, spreadsheets, project and document containers, VSAM, email, and file systems. The data stores simply expose common interfaces—a common data access model—to the data.
The Microsoft Universal Data Access strategy is based on OLE DB. OLE DB is a set of low-level C/C++ interfaces designed to efficiently build database components. They allow an individual data store to easily expose its native functionality without having to make the data look like relational data if it isn't, and also allow generic, reusable database components to augment the functionality of simpler providers when needed. Because they are low-level interfaces that deal with pointers, structures, and explicit memory handling for optimizing how data is exposed and shared between components, they are not suitable for calling directly from Microsoft® Visual Basic® or Java. You can think of OLE DB as being to all types of data what ODBC is to SQL data.
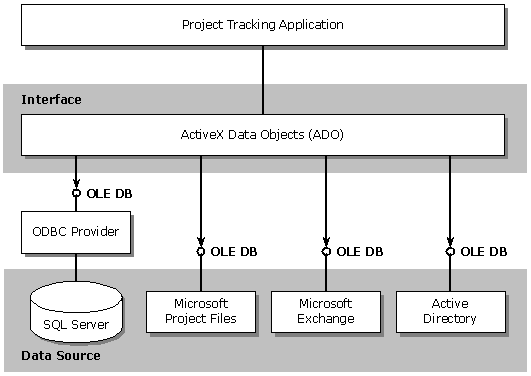
Active Data Objects (ADO) is an automation server that exposes a high-level set of database programming objects to the Visual Basic, Java, or C++ programmer on top of an OLE DB data source. Because it is a dual interface—it has no pointers, structures, explicit memory management, and so on—it is suitable for calling from scripting languages such as Visual Basic, Scripting Edition (JScript), and Microsoft® JScript™. Active Server Page (ASP) programmers use ADO methods to access and manipulate data stored in OLE DB data stores. Using ASP, programmers write code on the server to access the data and build an HTML page, which is then shipped back to the client. All of the intelligence and code for accessing and manipulating the data exists on the Internet server. Centralizing this logic on the Internet server and reducing the components downloaded to the client are ideal for many data access scenarios. Figure 2 depicts how the project tracking application discussed earlier may utilize ADO to access data from a variety of data sources.
Figure 2 Accessing Data with ADO
Microsoft ships a set of components collectively known as the Advanced Data Connector (ADC) that provide remoting of an OLE DB data object across the Internet or intranet. This allows the client to retrieve actual data rather than a textual HTML page. This is important if the client wants to use data as something other than formatted text. The client can manipulate the local data through ADO or OLE DB directly, and ADC 1.0 supports hosting standard Visual Basic-style data-bound controls into Microsoft® Internet Explorer (IE), which consume the remoted OLE DB data. The components shipped today as ADC will eventually become a core set of components that allow ADO or OLE DB applications to talk to remote data exactly as they would talk to local data. The fact that these remote data services are invoked is invisible to both the data consumer and the data provider. Let's take a look at each of the technologies in more detail.
In the July 1996 issue of Microsoft Systems Journal I covered build M6.1 of the OLE DB specification (see "Talk to Any Database the COM Way Using the OLE DB Interface"). A lot has happened to the specification since I covered it last year; version 1.0 was released last fall and followed closely by version 1.1. You can retrieve the specification from http://www.microsoft.com/oledb/ or install it from MSDN™ or the Microsoft® Visual Studio™ CDs.
In order to meet its goal of providing data access to all types of data in a COM environment, OLE DB is designed as a component technology. Data sources expose the COM interfaces that reflect their functionality, and common components can be built on top of those interfaces to expose more robust data models. OLE DB achieves this componentization by identifying common characteristics between different data providers and services, and by defining common interfaces to expose those characteristics.
An OLE DB provider exposes OLE DB interfaces over some type of data. Examples of providers include everything from a full SQL DBMS to an ISAM file, text file, or data stream. Obviously, these data providers have different functionality, and it's important not to limit that functionality. But at the same time it's not reasonable to expect all providers that expose simple tabular data to implement a full-blown query engine. Instead of looking at the differences between providers, OLE DB looks at the similarities and defines common interfaces used to expose those similarities. At a minimum, a simple OLE DB provider must implement and support the object types and functionality listed in Figure 3.
Figure 3 Provider Object Types and Functionality
The DataSource object represents a connection to a data store, such as a file or DBMS, through which consumers can operate on the data in the data store. Through the DataSource object, a consumer establishes a connection with the data store. Sessions provide a context for transactions that can be implicitly or explicitly transacted. A DataSource object can support multiple sessions within a single connection. Through the Session object, a consumer can open a Rowset of data. Rowsets expose data in tabular format.
Additional object types include enumerators, which search for available data sources. If a consumer is not customized for a specific data source, it would use an enumerator to search for a data source to use. A transactions object type is used when committing or aborting nested transactions. Command objects execute a textual command such as a SQL statement. The final object type is called errors; errors can be created on any interface on any OLE DB object type and can contain additional information about an error.
By implementing this simple set of objects and minimum set of behaviors, an OLE DB provider is capable of providing a very generic set of functionality to consumers. The functionality will probably be boring, but a generic consumer will be able to display data from the data store.
Well, it's great to have a common way to represent data, but if the data you are talking to has additional functionality such as being able to execute a SQL query, you want a common way to access that extended functionality. So the OLE DB specification, as well as specifying the base interfaces and objects that everyone implements, defines some interesting common extensions to expose additional functionality that specific data stores might have. The key concept to OLE DB is componentization. Rather than say that you must support everything or you can't support anything, Microsoft split the interfaces into groups: some are supported by everyone, and some are extensions for different areas, such as SQL data, ISAM data, and so on.
Componentization lets an OLE DB provider expose exactly its native functionality; then a separate component can be added on to implement the additional incremental functionality required by a consumer. For example, say you implemented just the minimum set of object types and behavior described above in your OLE DB provider. You don't support querying, sorting, or filtering; you just allow consumers to read through your data. Now let's say that a consumer wants to execute a SQL query on data exposed by your OLE DB provider. Instead of your having to write that code, a service component that will execute a query over anyone's simple data can be utilized to query your data. Now when a consumer wants to read through your data, they can talk directly to your OLE DB provider. When the consumer wants to do a query, the query processor can be invoked without the consumer's knowledge to add that incremental functionality. So what you have is a world of cooperating components, where every component natively exposes and consumes OLE DB interfaces, and individual database components can be incrementally added on to a native data store in order to add functionality.
If you have interesting data that you want everyone to have access to through a standard set of interfaces, you should write an OLE DB provider. An example of an OLE DB provider includes OLE DB for the Active Directory. Active Directory Service Interfaces (ADSI) abstracts the capabilities of directory services from different network providers into a single set of interfaces for managing network resources. ADSI makes it easy for the administrator and ISV to access and manipulate LDAP version 2, NetWare 3 and 4, and Windows NT® directories. ADSI includes an OLE DB provider for rich querying of the directory namespaces from OLE DB directly or through ADO. Throughout this article I am going to describe how your data can be accessed and utilized by other technologies that are part of the Microsoft Universal Data Access strategy.
The majority of consumers are going to write to ADO because it is easier to use, provides high performance, and exposes a rich set of functionality. Certain consumers may decide to write to OLE DB interfaces. Again, OLE DB is designed to make these cooperating database components work well together so you have ultimate control in things like memory allocation, sharing memory, freeing memory, using other people's memory, and so forth. Write to OLE DB using C++ for ultimate performance and functionality.
I covered OLE DB very briefly, but I can't do justice to such an important technology in the space I have available. The one thing to remember is that OLE DB is the foundation. OLE DB consumers consume OLE DB interfaces and interact with OLE DB service components and OLE DB providers. ADO is an OLE DB consumer.
ADO looks very similar to Data Access Objects (DAO) and Remote Data Objects (RDO) because Microsoft took the best features of both models and put them together in a common programming model. The most important points I can make here are that ADO is easy to use, language-independent, and provides extensible interfaces for programmatic access to all types of data.
Since ADO consumes OLE DB interfaces, whose sole purpose is to expose native functionality from diverse types of data stores, you can get to all types of data through ADO. ADO was designed as a set of interfaces that would be common for any high-level data access library that is going to supply a common programming model. And it really is easy to use. Language-independent means that ADO is an automation server that supports dual interfaces. Dual interfaces means that ADO supports an IDispatch as well as a VTBL interface, so that applications written in Visual Basic, C++, and Java can bind directly to the VTBL interface and get fast performance. Scripting languages can use the same objects through IDispatch.
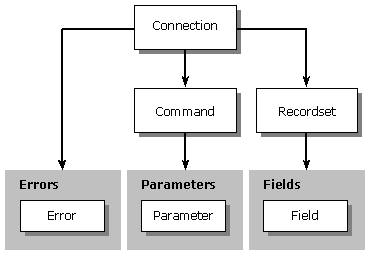
All objects in ADO (see Figure 4) can be instantiated on their own, except the Error and Field objects. The hierarchy of objects found in previous models like DAO and RDO is de-emphasized in the ADO model to allow greater flexibility in reusing objects in different contexts. For example, you can create a Command object, associate and execute it against one connection, then associate it with a different connection and re-execute it. This approach also paves the way for you to create specialized objects (defined at design time) and temporary, unattached recordsets.
Figure 4 ADO Object Model
Imagine a specialized Recordset object that's made to handle any results returned from a data store. It can basically determine, through metadata calls, all of the column information and all the columns that are there, build a recordset, and hand it to you. But those metadata calls can take a little time during runtime. This is where ADO comes in. Because objects in ADO can be instantiated on their own, you can use it to do things like design a Recordset object that is specialized for a certain query against your back-end database at design time. Thus, at design time a tool can capture information about the metadata of all of the columns, and at runtime a Recordset can be opened and immediately bind and start fetching, eliminating metadata calls during runtime.
The Connection object represents a unique session with a data source. In the case of a client/server database system, it may be equivalent to an actual network connection to the server. It's probably the object that you start with when working with any database management system. It allows for things like customization of connection options (such as your isolation level) and starting and ending transactions. The Connection object also allows you to execute commands such as a query or SQL statement. To execute any kind of command, you use the Execute method of the Connection object. If the command returns rows, a default Recordset object is created and returned.
The Command object is analogous to QueryDef in the DAO model and the prepared statement in the RDO model. It represents a command (also known as a query or statement) that can be processed by the data source. You use Command objects to obtain records and create a Recordset object, to execute a bulk operation, or to manipulate the structure of a database. Depending on the capabilities of the OLE DB provider, it can also handle parameters. The Command interface is actually optional in ADO since some OLE DB providers will not implement command execution functionality. Note that the Command data type is not a required object type to implement a generic OLE DB provider. The Command object is implemented in ADO; it doesn't do anything if it's communicating with an OLE DB provider that does not support command functionality.
Commands can be simple SQL statements (or some other language the OLE DB provider recognizes) or calls to stored procedures in the database. Commands can then be executed using the Command's Execute method, or you can create a Recordset object and associate it with the Command object when opening a cursor.
The Command object includes a collection of Parameter objects. If the provider can support commands with parameters, the parameters collection will contain one Parameter object for each parameter in the command. Unlike in DAO and RDO, you can create Parameter objects and explicitly add them to the parameters collection. This allows you to use well-known parameterized commands so you can avoid the sometimes very expensive operation of having the OLE DB provider populate the parameters collection automatically based on the retrieval of information from system catalogs.
Parameter objects represent parameters associated with parameterized queries, or the in/out arguments or return values of stored procedures on a Command object. The Parameter object is intended as a sort of parameter marker in a command for when you are working with things like output arguments or a command that you want to prepare. Command objects have a prepared property because, if you are going to execute something a whole bunch of times, even if you are just changing part of the where clause, it's better for you to create a Command object and prepare it. The OLE DB provider will make sure that it is very efficient.
The Recordset object is your cursor of data. The big difference in ADO is that the Recordset can be used as a data buffer. Traditionally, a Recordset was a way of issuing a query, getting a resultset, and reiterating over the resultset. With ADO, once you have the results, there is no reason why you can't treat it as a data buffer, separating it from the connection to the database, and passing it around safely to other applications or within different areas in an application. This means that the Recordset object manages changes to the recordset, buffering rows that have changed and those that have not, maintaining the old values with the new values. When you're ready to commit the changes, you can re-associate the Recordset with a Connection and use the automated method call UpdateBatch. UpdateBatch packages, inserts, and deletes the updates and sends them to the data store.
If you're more of a stored procedure type of person and don't like the idea of exposing your base tables, you can still work with the enhancements made to the Recordset because Microsoft exposed varying types of status, such as which rows have changed and which rows haven't. When an application hands a data buffer back to you, you can take a look through it and call your own stored procedure calls. You get a nice way of encapsulating a set of data and moving it around your system (regardless if it is distributed, across a network, or around a bunch of DLLs) without having to worry about connections or exposing your data directly.
Additional changes to the Recordset object include improvements for removing unnecessary things, adding optional arguments that reduce the number of lines of code for common scenarios, and changing defaults that don't make sense in today's technologies.
The Field object represents a column in a recordset that you can use to obtain values, modify values, and learn about column metadata.
The Error object contains details about data access errors pertaining to a single operation involving ADO. For those instances where an OLE DB provider returns more than one error, ADO will raise the most descriptive error as a runtime error in Visual Basic or an OLE exception.
The code below shows how to use the Connection object:
Dim con As New Connection
con.Open "dsn", "usr", "pwd"
con.Execute "<sql>"The first line is how you would typically instantiate a Connection object in Visual Basic. If you are using a scripting language, just replace it with a CreateObject call. In the ADO model you will notice Open and Close metaphors for objects that have an Open and Close state like a Connection object. To open a connection to a data source, just call the Open method and pass a data source name, user, and password as separate arguments. To execute a random statement, use the Execute method.
Those of you who remember DAO and RDO will remember there used to be a separate execute from OpenRecordSet, and you always had to know if you were going to get results or not to use one or the other. In the ADO model, Microsoft cleaned that up. All you really need is one Execute method—you don't need to know which one or whether you are going to get results or not. If there are results returned from the query, the Execute method will return a Recordset object. If there are no results returned from the query, it will return nothing. Microsoft has eliminated a lot of the bulk from the model.
The Recordset object is just as easy to do a simple Open on. Notice that, instead of using the Connection object and opening the Recordset, I am actually creating the Recordset by itself.
Dim rs As New Recordset
rs.MaxRows = 100
rs.Open "<sql>", "<con.string>", adOpenKeyset
While Not rs.EOF
·
·
·
rs.MoveNext
WEndIn the earlier models, you had to go through a hierarchy of objects and set certain properties of a cursor before the cursor was open and before the query was executed. For example, MaxRows had to be set before the query was executed because the data source needed to know when to chop off the results. In the older model, you had to have a tree of instances and you had to put those things on higher-level objects, even though they didn't belong there. There was always confusion as to which object inherited from which, and which one was used when you didn't set one. What Microsoft has done in the ADO model is eliminate the problem by placing the properties affecting the recordset and the cursor on the Recordset object. Now you can do things like set MaxRows = 100, open the database, or execute a statement by just calling the Open method on the Recordset, just as you call Open on the Connection object.
In the above code sample I show the Open statement taking some optional arguments. These arguments are optional because there are properties on the Recordset that are equivalent to them. What Microsoft did is give you some shorthand. Using the shorthand is a definite performance gain, especially when used with scripting languages. In this example, I am passing in a generic SQL statement, a source that is represented as a Connection object, and a constant informing the Recordset object that when it is opened I want to use a Keyset cursor.
Like the Recordset object, the Command object can be instantiated without having to go through a hierarchy of objects. You can associate it with any Connection object. Commands live on their own, so you can use a Command with a Connection object and execute over here, then associate the Command with another Connection object and execute it over there. The Command object is not tied to one Connection object for its entire lifetime and it can travel with different connections.
In the following code sample, I have set the ActiveConnection property to a connection string; again, it could be set to a Connection object as well. Then I set the CommandText, which is just a SQL string if I am accessing a SQL database. Remember, since OLE DB providers can be built to provide data from nonrelational data stores, the CommandText can be any text that an OLE DB provider can understand.
Dim cmd As New Command
cmd.ActiveConnection = "<con.string>"
cmd.CommandText = "<sql>"
cmd.Parameters(0) = <value>
cmd.Execute
cmd.Parameters(0) = <value>
cmd.ExecuteAs the example shows, if I had a parameter marker in the SQL statement, I would set the parameters by using this type of syntax, just like QueryDefs and prepared statements. Next I would set its value, and finally call Execute. Parameter objects are also a way to capture output parameters and can be marked as a direction of I/O. If the Parameter object is an output argument and the Command object is a stored procedure call, the result would be in the Parameter object.
That's it for code. For more information on ADO you can visit http://www.microsoft.com/ado/. ADO is also distributed with ASP for use with the Microsoft® Internet Information Server (IIS) and the OLE DB Software Development Kit.
Now that you have a brief understanding of OLE DB and ADO and how they work with each other, let's move on to ODBC. A lot of data is accessible from ODBC that I don't want to forget in this Universal Data Access model. It is important to understand ODBC's critical role in the world of Universal Data Access. ODBC is the standard interface to SQL relational data. There is an ANSI/ISO specification that is an extension to ANSI SQL92, ISO's SQL specification for a Call-Level Interface based on ODBC. In fact, the new ODBC 3.0 is a fully compliant superset of that international standard.
There is a great deal of incentive for relational database programmers to write to ODBC. But ODBC does require that your data look like a relational database, so it's not always the best way to expose data. ODBC's greatest strength is that it closely follows the embedded SQL model. So if you have a SQL relational database, ODBC is almost trivial for you to implement. If you don't have a SQL database, it can be very difficult to write an ODBC driver to your data because you basically have to write a relational engine on top of your data.
To integrate ODBC into the Universal Data Access strategy, Microsoft built an OLE DB-ODBC provider. What the ODBC provider does is ensure that anybody's existing ODBC data works well in the world of Universal Data Access. In other words, it implements the OLE DB object types that share component data objects on top of any ODBC driver. It does so in a very efficient manner; you can access the data through OLE DB with the same performance that you would get if you accessed it through ODBC.
Without losing your investment in ODBC, you can communicate with ODBC data stores directly through OLE DB interfaces or ADO since ADO consumes OLE DB interfaces.
Before moving on to ADC, let's take a look at how OLE DB and ADO would be used in an existing application. Today, your typical monolithic application contains a number of different things. It generally contains a user interface and a set of business rules that govern how to access different types of data. It might have a client/cursor component in the application if it's talking to SQL data (and that SQL data doesn't support going backwards but your user interface does). The application may have a query processor for talking to a type of data that does not have a query processor in it. It probably has a number of different proprietary interfaces to get to various different data stores. In short, the application is hard to write, maintain, and extend due to the number of proprietary interfaces needed and the code necessary to fill in functionality not provided by the different types of data stores.
Suppose that the application is getting some data from an ISAM data store and some data from a SQL database. It has two different proprietary interfaces: one is the Btrieve interface and the other is OCI to talk to Oracle. I have a monolithic application that has multiple interfaces tied to specific APIs. If I want to point this application at Microsoft SQL Server, I have to add another interface. If the development group writing the application was smart enough to use ODBC to get to Oracle and Microsoft SQL Server, then at least I have one interface to get to relational databases, but I still need to add a new interface to get to, say, spreadsheet data.
The first step is to replace those proprietary APIs with ADO. Because ADO will consume any OLE DB provider, once I write to it I can get to not just ISAM and SQL data, but also things like HTML pages, email data, spreadsheet data, log file data, and a host of other information through a single interface. I can access new types of data without having to add anything to the application. The application is simpler to write because I only have to learn one interface, and it is more versatile because it can talk to more types of data.
What I'm left with is an application that has a user interface and business rules. It still has the client cursor component because it is still talking to some types of data, like SQL data, that may not be able to support scrolling backwards, and the application still has a query processor for doing queries over HTML or email data.
The next step is to add a query processor, which in this case is a common OLE DB service component. When the application talks to a data provider that supports querying, such as a relational database, the application can talk directly to that SQL data through ADO. When the application talks to ISAM data, which doesn't have a SQL query processor, it still talks through ADO, but a query processor is invoked on the application's behalf in order to implement those queries. That's important for a couple of reasons. Putting that query processor anywhere else would mean that every application or every data store would have to write a query processor, which doesn't make sense—there only needs to be one. Also, it allows different query processors to be inserted to support different query syntaxes or functionality.
So now the application has a user interface, business rules, and a client cursor for when it talks to the relational data. Again, one client cursor can be written as a service component that can talk to data regardless of where it comes from, and can be invoked only when it is needed. It can also do all of the cursoring for any application that wants it. The application still talks to ADO; it just has less code in it.
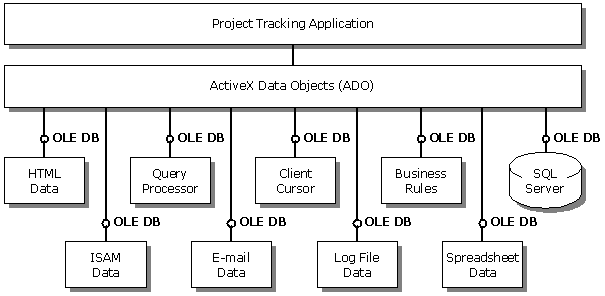
Figure 5 Even business rules can be a component
Now the application has just a user interface and business rules. Why not go for broke and take the business rules out of the application? Business rules generally don't vary from application to application. Rather than implement similar business rules in each application, I should be able to implement them as components that sit and watch the data and make sure that the ways I use the data are correct regardless of the application. Again, the model of OLE DB is that those business rules don't have to sit between the application and the data. They can sit off to the side and, through notifications that OLE DB supports in order to coordinate different users, it can let the business rules component know when something has happened. Ultimately I get an application that looks very similar to Figure 5.
The Internet imposed a new problem for accessing data. In a typical client/server model you have an application called the client, which talks to a database on a server. Typically you have a persistent connection between the two that works like this: you make a connection, query to retrieve metadata, prepare a statement, provide some parameters, execute it, and read through five or six rows. Typically the client permits the user to update, insert, and delete new rows of information. All this time, the server maintains the client's cursors and state. Well, that worked great up until a couple of years ago when somebody got this idea to make the Internet popular.
The problem with the Internet, of course, is that it is a fundamentally disconnected model. When you have hundreds of thousands of people accessing your Web site, you don't want to keep state for those hundreds of thousands of users that may never complete the operations they start. You need a model in which your client can continue working with data even though your server has forgotten about the client. You need the server to be able to process the request and then forget about the client. Well, it turns out that the Rowset defined by OLE DB works very well. It's a self-contained object that can live on the server or the client.
In the case of working with data on the client, what you need is a copy of the data. As a result, there are two models for accessing data across the Internet. One model uses scripting on the server with ASP. ASP solves an important problem by allowing a Web server to intelligently interact with data and build HTML for the client dynamically. In many cases, this is the model that you want to use. The second model uses client-side scripting for when you want to provide the client with the capability to manipulate and update data.
Microsoft today ships a set of components known collectively as ADC that provides the infrastructure for moving data from the server to the client, allowing developers to create data-centric applications within ActiveX®-enabled browsers such as Internet Explorer. ADC erects a framework through a set of components that provides the remoting of an OLE DB Rowset object through HTTP or DCOM on corporate intranets and over the Internet.
ADC 1.0 provides Visual Basic-like data binding for ActiveX data-aware controls within IE. This means that you can take those data-bound controls that you are used to using in Visual Basic and build data-centric applications for the Internet or intranet. ADC also enables application partitioning with server objects. A generic mechanism for creating business objects on the server is provided with ADC so that you can encapsulate data and business rules on the server away from your clients.
ADC also provides a transparent caching architecture. One thing that is prevalent today on the Internet is displaying data in an HTML document. It's cached locally but it's static, and the data that you have isn't really live. You can work on it and then later send it back and say "update it," but it is not interactive like traditional client/server applications. By transparently caching data locally at the client side, ADC minimizes round-trips to the server. ADC brings the metadata and the data to the client so that a user can work on it at the client. When the client application is finished updating the data, ADC will worry about the plumbing, getting the data to the server, and ensuring data integrity through optimistic concurrence. Let's take a look at the architecture and see how ADC utilizes ADO and OLE DB.
The components shipped today as ADC will become part of a generic remoting architecture that will allow ADO and OLE DB consumers to access remote data exactly as they would talk to local data. The fact that these remote data services are invoked is invisible to both the data consumer and the data provider. In the meantime, it's important to understand how the components that make up ADC work together with OLE DB providers and ADO consumers to provide data remoting.
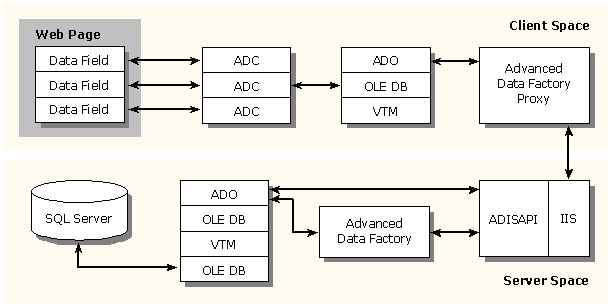
In an ADC implementation, assume the data space is partitioned into two spaces, the client space and the server space. The client space is the domain of the user. Within this space, the client interacts with the data within Internet Explorer. The server space is where the business logic resides. This is where you can separate and hide from the user what is really happening with the data and how the data is being packaged. The server space also contains the OLE DB providers and any OLE DB service components that expose data from various data sources.
In the client space is the Advanced Data Control, a data source control compatible with IE, as well as a data binding manager for IE-based applications. It allows for Visual Basic-style data access programming within VBScript and HTML Web pages. The Advanced Data Control is a nonvisual drop-in control that is embedded in Web pages to enable database access and updates to Web applications using the ADC framework. It is this control that data-aware controls, like those found in Visual Basic, bind to.
Another part of the ADC framework is an Advanced Data Factory Proxy. It is used in the framework as a proxy for making requests to the Advanced Data Factory on the server. It basically packages up the method requests and places those requests over HTTP to IIS, which fulfills the requests via the Advanced Data Factory.
In this scenario, there are two very similar stacks, one on each side. One of the reasons there are two stacks is that Microsoft wants to provide a consistent paradigm within the architecture that will work today, and that will also work in the future as more OLE DB providers are written. If you are used to programming in ADO, you can build objects in the server spaces that use ADO, or you can use scripting languages on the client space and access ADO Recordsets on the client.
One of the key components in the stack is the Virtual Table Manager (VTM). The VTM is an in-memory relational data cache exposing OLE DB interfaces for data access and manipulation. The VTM supports state marshaling of its contents through IMarshal and IPersistStream interfaces among multiple server tiers while providing client-side, disconnected cursor models over its cache elements. It also maintains relational data, client updates, and record status information. The VTM consumes as well as exposes OLE DB interfaces.
The Advanced Data Internet Server API (ADISAPI) is responsible for breaking up the MIME packets that come through IIS and invoking the methods on the Advanced Data Factory. The Advanced Data Factory is the actual object that will instantiate ADO, create a connection object, perform the query, and receive the resultset. One of the things I want to mention is that the Advanced Data Factory is just a simple business object. Its sole purpose in life is to accept a query, perform the query, return a resultset, receive data, or perform updates. You don't have to be tied to the Advanced Data Factory; you can create your own business objects to handle things like data validation and hiding.
ADO is the data access API. Once you write to ADO, you can take advantage of writing with it on both the client and the server. The primary difference between the server and the client version of ADO today is that, since the Advanced Data Control handles making the query requests to the server, the client's version supports just the Recordset object. In the next version of ADO, you will be able to use exactly the same model for accessing data locally or on a server, and the ADC components will be invoked for you under the covers. For more information about ADC you should visit http://www.microsoft.com/adc/.
I've described the Microsoft vision for Universal Data Access, the problems that it solves, and a brief overview of the technologies that are part of the Universal Data Access vision. But what should you do now? What about the rest of the data access APIs? Well, the current version of ADO does not provide all of the functionality of RDO (it doesn't have the rich automatic batch cursor model), nor does it include all of the Jet-specific extensions of DAO (such as compaction). This year, ADO will be extended to support a superset of RDO and DAO functionality.
If you are writing new code to access data in Visual Basic today, take a look at the functionality of ADO. If it does everything that you need, use it. If you are accessing ODBC data and require RDO-specific features, then use RDO. RDO will continue to be supported in the future, and Microsoft will have tools available to help programmers migrate to ADO.
Special thanks to Michael Pizzo for his help with this article.
From the September 1997 issue of Microsoft Systems Journal.