Microsoft Corporation
May 1998
Summary: Describes two key aspects of the Universal Data Access platform: ADO and the service component architecture. (23 printed pages) Includes:
Microsoft® Universal Data Access is a platform for developing multitier enterprise applications that require access to diverse relational or nonrelational data sources across intranets or the Internet. Universal Data Access consists of a collection of software components that interact with each other using a common set of system-level interfaces defined by OLE DB. Universal Data Access components consist of data providers, which contain and expose data; data consumers, which use data; and service components, which provide common services that extend the native functionality of the data store.
After reviewing the Universal Data Access platform, this paper describes two key aspects of the platform. First, it presents an overview of ActiveX® Data Objects (ADO), a provider-neutral, application-level data access object model that can be used from languages such as Visual Basic®, Java, C++, Visual Basic Scripting Edition (VBScript), and JScript™. Second, it describes a service component architecture that enables you to compose services transparently to consumers and providers. Four services in the Universal Data Access platform work with each other via the service component architecture. A cursor service provides an efficient, client-side cache with local scrolling, filtering, and sorting capabilities. A synchronization service provides batch updating and synchronizing of data cached in the client or middle tier. A shape service allows the construction of hierarchically organized data with dynamic behavior under updates. Finally, a remote data service provides efficient marshaling of data in multitier environments over connected or disconnected networking scenarios.
Introduction
Universal Data Access Overview
ActiveX Data Objects
Service Components
The Cursor Service
The Synchronization Service
The Shape Service
Remote Data Service
Summary
Modern data-intensive applications require the integration of information stored not only in traditional database management systems, but also in file systems, indexed-sequential files, desktop databases, spreadsheets, project management tools, electronic mail, directory services, multimedia data stores, spatial data stores, and more. Several database companies are pursuing a traditional database-centric approach, which this paper refers to as the universal database. In this approach, the database vendor extends the database engine and programming interface to support new data types, including text, spatial, video, and audio. The vendor requires customers to move all data needed by the application, which can be distributed in diverse sources across a corporation, into the vendor's database system. This process can be expensive and wasteful.
Universal Data Access is an effective alternative to the universal database approach. However, it also can be implemented in a complementary fashion with the universal database approach. The premise of Universal Data Access is to allow applications to efficiently access data where it resides without replication, transformation, or conversion. Open interfaces allow connectivity among all data sources. Independent services provide for distributed queries, caching, update, data marshaling, distributed transactions, and content indexing among sources.
Vaskevitch outlined the initial motivation and goals for OLE DB and the Microsoft component database approach in the paper "Database in Crisis and Transition: A Technical Agenda for the Year 2001." Blakeley, in "Data Access for the Masses through OLE DB," presented an overview of the architecture, objects, and key interfaces for OLE DB. This paper continues the theme of these two previous papers, detailing key components that are making Universal Data Access a reality and describing how the OLE DB service component architecture works to provide run-time extensibility of database functionality to applications.
OLE DB is the Microsoft system-level programming interface to diverse sources of data. OLE DB specifies a set of Microsoft Component Object Model (COM) interfaces that encapsulate various database management system services. These interfaces enable you to create software components that comprise the Universal Data Access platform.
Whereas OLE DB is a system-level programming interface, ADO is an application-level programming interface. ADO, based on Automation, is a database-programming model that allows enterprise programmers to write applications over OLE DB data from any language including Visual Basic, Java, VBScript, JScript, and C/C++.
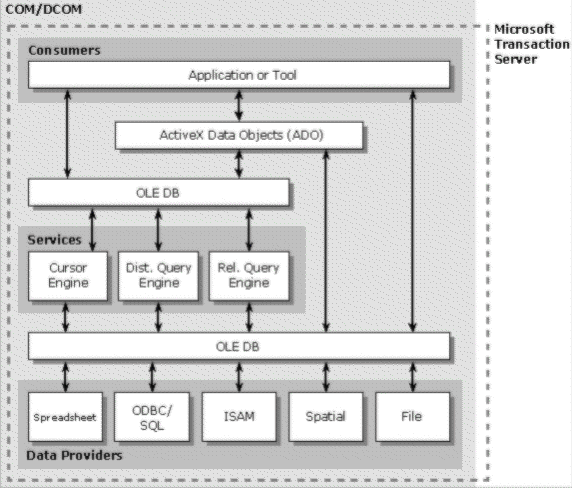
The following figure illustrates the Universal Data Access architecture. There are three general kinds of database components: data providers, services, and consumers.
Data providers are components that represent diverse sources of data such as SQL databases, indexed-sequential files, spreadsheets, document stores, and mail files. Providers expose data uniformly using a common abstraction called the rowset.
Services are components that extend the functionality of data providers by implementing extended interfaces where not natively supported by the data store. For example, a cursor engine is a service component that can consume data from a sequential, forward-only data source to produce scrollable data. A relational query engine is an example of a service over OLE DB data that produces rowsets satisfying a Boolean predicate.
Consumers are components that consume OLE DB data. Examples of consumers include high-level data access models such as ADO; business applications written in languages like Visual Basic, C++, or Java; and development tools themselves.
All interactions among components in the previous figure, indicated by bidirectional arrows, can occur across process and machine boundaries through network protocols such as Microsoft Distributed COM (DCOM) or HTTP. Transacted interactions among components are possible via a distributed transaction coordination service such as the one included in Microsoft Transaction Server.
OLE DB defines a hierarchy of four main objects as illustrated in the following figure.
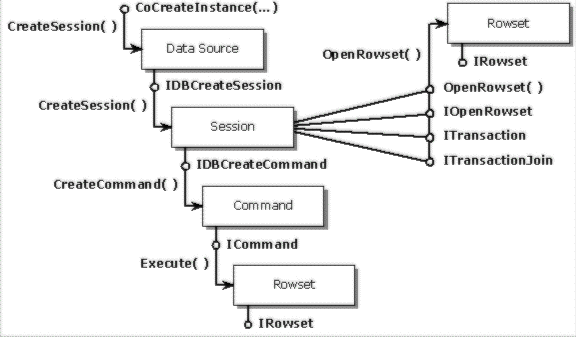
The Data Source object encapsulates functions that identify a particular data provider, verify that the user has the appropriate permissions to connect to the provider, and initialize the connection to a particular data source (for example, a file name or database name).
The Session object defines the transactional scope of work done within a connection.
The Command object encapsulates the functions that enable a consumer to invoke the execution of data-definition or data-manipulation commands such as queries.
Rowset objects provide a common representation of data. They are typically created either directly from a session or as a result of a command execution, but may be generated as the result of other methods that return data or metadata.
Before each OLE DB object is created, the caller has the opportunity to request the capabilities or behavior of the data source that need to be surfaced by the object through its interfaces. This is an important aspect to remember when reading the section titled "Service Components."
ActiveX Data Objects (ADO) is a set of high-level Automation interfaces over OLE DB data. Although OLE DB is a powerful interface for manipulating data, most application developers do not need the low level of control that OLE DB gives over the data-access process. Most developers are not interested in managing memory resources, manually aggregating components, and other low-level operations. Additionally, developers often use high-level languages that do not support function pointers and other C++ call mechanisms. ADO provides the following advantages to programmers:
ADO is made up of seven objects as described in the following figure.
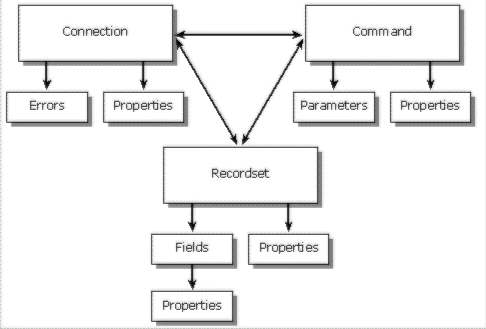
The Connection, Command, and Recordset objects are top-level objects that you can create and destroy independently of each of the other objects. Though you can create the Parameter object independently of a Command object, it must be associated with a command before you can use it. The Field, Error, and Property objects each exist only within the context of their parent objects, and can't be separately created.
The ADO Connection object encapsulates the OLE DB Data Source and Session objects. It represents a single session with the data source. The Connection object defines properties of the connection, assigns the scope of local transactions, provides a central location for retrieving errors, and provides a point for executing schema queries.
The ADO Command object encapsulates the OLE DB Command object. The Command specifies the data-definition or data-manipulation statement to be executed. In the case of a relational provider, this is an SQL statement. The Command object allows you to specify parameters and customize the behavior of the statement to be executed. A collection of Parameter objects exposes the parameters.
The ADO Recordset object encapsulates the OLE DB Rowset object. The Recordset object is the actual interface to the data, whether it is the result of a query or was generated in some other fashion. The Recordset object provides control over the locking mechanism used, the type of cursor to be used, the number of rows to access at a time, and so on. The Recordset object exposes a collection of Field objects that contain the metadata about the columns in the recordset, such as the name, type, length, and precision, as well as the actual data values themselves. Use the Recordset object to navigate through records and change data (assuming the underlying provider is updatable).
Each of the top-level ADO objects contains a collection of Property objects. The Property object allows ADO to dynamically expose the capabilities of a specific provider. Because not all data providers have the same functionality, it is important for the ADO model to allow you to access provider-specific settings in a dynamic way. This also prevents the ADO model from being cluttered with properties that are available only in certain circumstances.
ADO is provider neutral. That is, although it allows you to access the full range of OLE DB data, it does not implement its features specific to any one provider or data source. In addition, ADO itself does not add functionality on top of the provider. Augmenting the functionality of providers, such as the ability to scroll or update, is the job of service components. One benefit is that you can take any piece of code that can manufacture an OLE DB Rowset and wrap that object in an ADO Recordset object, thereby enabling scripting of that data. Because the Recordset object isn't needed to connect to the data source or execute the command, it needs only the core rowset interfaces (that is, IAccessor, IColumnsInfo, IConvertType, IRowset, and IRowsetInfo) to provide access to the data.
Automation implements the ADO interface. Automation defines Variants as its data types. Variants work well in languages such as Visual Basic, which are not strongly typed. If you are writing in C++ or in Java, most operations in the code will require native data types to support the standard library features of the language. In these cases, with ADO you can convert data between the Variant and native data types when passing arguments.
ADO has extensions designed specifically to support both Java and C++. For C++, a set of interfaces that directly retrieve and set native C types from the underlying OLE DB provider improve performance and decrease the lines of code required to interact with the ADO interface.
For Java, ADO extensions include a set of Java classes that extend the ADO interfaces and create notifications interesting to the Java programmer. These extensions expose functions that return Java types. In addition, the extensions are optimized to improve performance. The Java class directly accesses the native data types in the OLE DB Rowset object and returns them to the Java programmer as Java types without first converting them to and from a Variant.
Below are two samples, one written using VBScript in the Active Server Pages (ASP) environment (which embeds script code within HTML), and one written in Java.
<html>
<body>
<% Set cn = Server.CreateObject("ADODB.Connection")
Dim rs As ADODB.Recordset
cn.Open "dsn=pubs;uid=sa;pwd="
set rs = cn.Execute("SELECT * FROM authors") %>
<table border=1>
<% while rs.EOF <> True %>
<tr>
import com.ms.ado.*;
class test
{
public static void main(String args[])
{
Connection cn = new Connection();
Recordset rs = new Recordset();
cn.open("dsn=pubs", "sa", "");
rs = cn.execute("SELECT * FROM authors");
while( !rs.getEOF() )
{
for( int ii=0; ii<
Providing a common interface to diverse data stores containing mission-critical data is not an easy task. Each data store supports different sets of functionality, making it difficult to define a useful level of interaction between a generic application and diverse stores. Defining the level of interaction to be only the common functionality among all stores does not provide a useful set of functionality for the application. Further, this approach limits the ability of the data store to expose innovative extensions. On the other hand, requiring a rich level of functionality would force a simple data store to implement, in full or in part, a relational engine on top of its data. Such barriers prevent many types of simple data from participating in data access.
The Microsoft Universal Data Access solution is to define a rich set of functionality, but to factor that functionality so that data stores are able to expose only the subset that makes sense for their data. Thus, the data store is not limited in the functionality it can expose, but at the same time is not forced to implement extended database features in order to provide common access to its data.
This makes OLE DB attractive for the data store, but to stop there would be near to defining a least-common-denominator approach for the application. In order to be generic, the application would have to be filled with extensive conditional code to verify whether a particular set of functionality was supported. In many cases, the application would be forced to implement extensions internally to compensate for data stores that could not support extended functionality natively.
To solve this problem, Universal Data Access provides a component architecture that allows individual, specialized components to implement discrete sets of database functionality, or "services," on top of less capable stores. Thus, rather than forcing each data store to provide its own implementation of extended functionality, or forcing generic applications to implement database functionality internally, service components provide a common implementation that any application can use when accessing any data store. The fact that some functionality is implemented natively by the data store, and some through generic components, is transparent to the application. In order to understand how OLE DB components are combined to guarantee a rich functionality, it is necessary to understand COM interface factoring and aggregation.
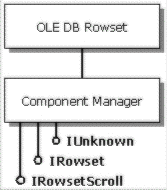
In COM, a single object exposes one or more interfaces. Each interface exposed by the object represents a fixed set of functionality, such that the total functionality of the object is factored among the various interfaces. Each interface inherits functionality directly or indirectly from a common interface on the object called IUnknown, such that the IUnknown interface is the "super parent" of every other interface supported by the object. IUnknown contains AddRef and Release methods, which control the lifetime of the object through reference counting, and a QueryInterface method for navigating between the different interfaces on the object. The following diagram shows a single COM object that implements two interfaces, IRowset and IRowsetScroll, in addition to IUnknown.
The full set of functionality defined in the OLE DB specification is factored into multiple discrete interfaces that group related levels of functionality for each object. This interface factoring is what makes OLE DB so accessible to simple data stores. Rather than forcing every data store to implement a full relational engine in order to be accessible through common tools, the data store implements an object comprised of only those interfaces that represent native functionality for that data store. At a minimum, this includes core interfaces that provide a simple forward-only, read-only view of the data.
A COM object can be created using another object's IUnknown interface, in which case each interface exposed by the newly created object inherits functionality from this existing "Controlling Unknown." The controlling object then manages the navigation between sets of functionality supported by interfaces implemented on the inner object and sets of functionality supported by interfaces on the controlling object.
The following diagram shows a COM object that supports the IRowset interface, and a controlling object that implements the IRowsetScroll interface. The IUnknown interface exposed by the controlling object navigates between the interfaces supported by the two different objects. To the application, this appears as a single object that implements both IRowset and IRowsetScroll.
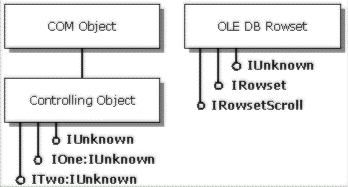
In OLE DB, a service is implemented as a controlling object that aggregates the native object exposed by the data store. When the application requests an interface that represents some set of functionality natively supported by the data store, the service returns the data store's native interface and the application interacts with the data store directly. When the application requests some set of functionality not supported by a native interface on the data store, the service can provide a standard implementation of that functionality, interacting with the data store through the same native interfaces exposed to the application. In this manner, the application always gets the most direct, efficient path to the data. Whether the functionality is implemented natively by the data store or through an external service is completely transparent to the application.
To maximize performance and minimize overhead, the services themselves are factored into multiple components—only those services needed at any one time are loaded into memory. Thus, if a particular data store requires multiple services to satisfy the requirements of the application, multiple service components may be invoked.
The next problem is the actual invocation of the individual service components. Putting the logic for invoking service components within the application complicates the application code, forcing it to know the particular capabilities of the data store and the available services. Putting the logic within the data store complicates the code for the data store, limiting the ability to extend the functionality of the data store to those services known to the data store at the time its OLE DB interface was written. Furthermore, a growing number of data stores are exposing OLE DB interfaces today without any knowledge of existing services. To work with those existing data stores, the logic must live outside the data store.
The commonly held belief that any problem can be solved given enough levels of indirection proves true in this case, where the dynamic invocation of multiple services at run time is handled through thin controlling objects called component managers. Component managers aggregate each of the primary OLE DB objects exposed by the data store and ensure that the proper services are invoked to provide required functionality. Each interface supported by the data store's native object, as well as the interfaces supported by each of the individual service components, inherit from this Component Manager's IUnknown interface. Thus, all interface navigation goes through the Component Manager, which intercepts interfaces at any time and invokes additional services as needed. All of the logic for invoking services can be localized in this Component Manager, and new components can be added that make existing applications more functional without adding any additional code to either the application or the data store.
The following diagram shows a simple OLE DB Rowset object that exposes forward-only data retrieval through IRowset, aggregated by a Service Component that exposes scrollbar support through IRowsetScroll. Even though the Component Manager is present, calls to IRowsetScroll go directly to the Service Component while calls to IRowset go directly to the OLE DB Rowset object.
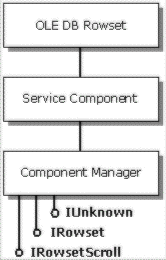
The Component Manager's ability to intercept interfaces comes into play particularly in the creation of one object from another. The following diagram shows the Data Source Component Manager (DCM) aggregating the Data Source Object.
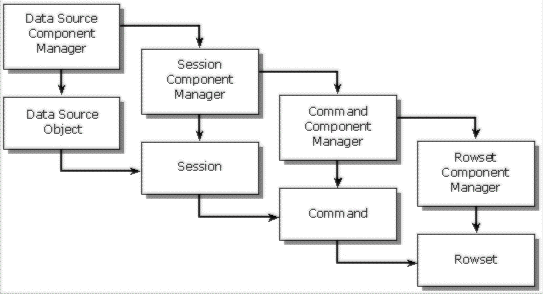
When the application creates a Session, the DCM intercepts the call and first creates a Session Component Manager (SCM), then creates a Session aggregated by the SCM. Similarly, when the application creates a Command from the Session, the SCM first creates a Command Component Manager (CCM), then creates a Command aggregated by the CCM. Finally, when the application creates a Rowset, the CCM first creates a Rowset Component Manager (RCM), then creates a Rowset aggregated by the RCM. At any step along the way, the individual component managers can invoke additional services to add additional functionality on top of the data store's Data Source, Session, Command, or Rowset objects. Thus, once a Data Source Component Manager correctly aggregates the initial Data Source object, the remaining objects are automatically aggregated with their own instances of Component Managers.
At this point, the only remaining problem involves ensuring that a Data Source Component Manager correctly aggregates the initial Data Source object. OLE DB 2.0 provides a common entry point through the IDataInitialize or IDBPromptInitialize interfaces. These interfaces are exposed by a Data Initialization component distributed as part of the core OLE DB services for version 2.0. Generating a Data Source object from either of these interfaces will return the provider's Data Source aggregated by a Data Source Component Manager. Once the Component Manager aggregates the initial Data Source object, neither the application nor the data store needs any knowledge of extended services or the components that support them. The Component Managers invoke the specialized, highly optimized services necessary to provide the application a rich data model when accessing any type of data.
As explained in the previous sections, Universal Data Access enables the data flow between a data consumer and any kind of data provider. Frequently, as the data moves through each tier of the application architecture, it has to be cached, filtered, or reshaped, and needs to be synchronized with the original data in the provider. However, many providers deliver their data as forward-only, read-only rowsets. The gap between the rich functionality demanded by a typical data application and that offered by most data providers is filled by services. The following sections describe four specific services that you can combine using the service component architecture just presented.
An important challenge for a multitier, distributed application is to find a balance between keeping data current, or live, and reducing network traffic. Live data produces high network traffic and is impractical for most applications. It requires every change at the application level to be immediately propagated to the data source, and concurrent changes to the data source to be immediately pushed to the client application. In addition, every time the application scrolls beyond its local buffer, new data must be fetched to ensure dynamic membership of the data set. Another side effect of using live data is that it virtually kills application scalability. An Internet application where thousands of client requests need to be served from a data source simply does not work with live data.
A Cursor Service proves a good solution for this challenge. It provides a client cache for data sets (or cursors) and a service that implements smart synchronization mechanisms (see "The Synchronization Service"). Using these services dramatically reduces network traffic while giving you full control over data synchronization. The Cursor Service can be installed on each tier of a multitier application, providing a great solution for scalability.
The Cursor Service consumes data from a rowset, stores the data locally, and exposes the data along with rich data-manipulation functionality through rowset interfaces. The Cursor Service can provide a local instance of virtually any rowset produced by an application.
The Cursor Service is typically invoked when the consumer requests a local copy of a remote rowset, or when the consumer requests rowset functionality not supported by the provider's native rowset.
All rowsets are handled independently by the Cursor Service. Rowsets don't share common data, and no integrity constraints are enforced. The Cursor Service doesn't try to replicate the provider data model, its integrity restrictions, or its data. It rather manipulates independent data sets as defined and required by the application.
The Cursor Service provides the following functions: data fetching, data manipulation, local updates, and local rowsets.
When the consumer requests functionality that requires the Cursor Service, the Cursor Service component is invoked to fetch the data and cache it locally. The data is stored in memory buffers and, if needed, written to temporary files on disk. The data fetch can be performed synchronously or asynchronously. The fetch of large data fields, such as BLOBs, can be delayed until the data is actually required by the application.
The rowset is accessible to you via ADO/OLE DB interfaces. In ADO, use the Recordset object to maintain currency and manipulate the data (see "ActiveX Data Objects"). The Recordset exposes methods implemented by the Cursor Service to position on a row, get field values, and filter and sort the rows based on one or more fields. A Recordset can be cloned, which produces a second Recordset based on the same underlying rowset data. Clones have their own currency, filter, and sort order. The Cursor Service also generates events exposed by the associated rowset and used to bind rowset data to visual controls. Rowsets can be persisted in an internal binary format or in XML. A client rowset can be remoted between two processes or machines over DCOM or HTTP (see "Remote Data Service"), enabling distributed data access for multitier architectures over intranets and the Internet.
You can make any changes to the local data: modify data fields, delete existing rows, and insert new rows into the rowset. The changes are immediately committed to the cache and are visible from all the cloned Recordset objects on that rowset. Local changes can be committed to the data provider row by row or once for the entire rowset via the Synchronization Service.
The Cursor Service allows you to create a stand-alone rowset, by first defining the column information associated with the rowset and then opening it. Local rowsets can be used as data buffers or to hold and share local temporary data in an application. Indexes can be created on local rowsets to support sort, filter, and find operations. All data-manipulation operations are available on local rowsets.
For applications using client rowsets over SQL data, the Synchronization Service component provides the ability to send changes back to the provider and to refresh the data in local rowsets with current data from the provider. Both the update and refresh operations can be applied to one or more rows simultaneously and can be coupled together in a single user command. Both operations ensure consistency of multitable rowsets if the structure of the join relation between the participating tables is known.
The Synchronization Service has two distinct components: the Metadata Gatherer, which provides metadata information such as base table names, base column names, primary keys, and timestamp columns; and the Update/Resync component, which sends changes to the provider and returns data changes to the client. The Synchronization Service operates in conjunction with the Cursor Service, which is responsible for gathering and storing the metadata and for storing the data copies of each changed row necessary for optimistic conflict resolution. The following figure illustrates the interaction of the Synchronization components (indicated by the labeled bracket).
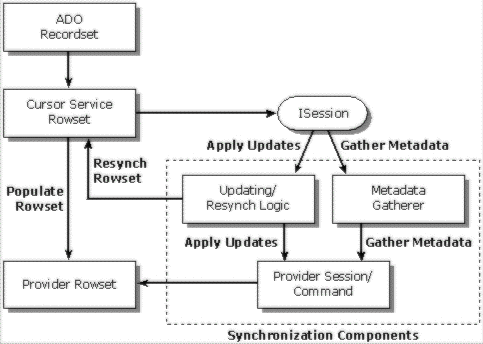
The synchronization process has the following stages:
First, the Cursor Service reads all the data from the underlying provider rowset and populates the local rowset. In this process, it collects and stores the basic metadata information for the rowset such as number of columns; column name, type, and precision; base table and column names; primary key columns; and timestamp/version columns.
If some metadata information is not available from the rowset provider, the Cursor Service calls the Metadata Gatherer to obtain this information. If the Metadata Gatherer still cannot obtain the metadata information, the client application can explicitly set it.
After the rowset data has been modified, the client requests to propagate the changes to the data source. The rows to be updated are passed to the Update/Resync component of the Synchronization Service with a flag stating whether the original rowset needs to be refreshed after the update. This component reads the updated metadata from the Cursor Service rowset and submits the updates to the data source. It then sets the update status on each row in the rowset participating in the update.
Depending on the flags set when the update was submitted, the Synchronization Service could update the conflicting rows in the rowset with new values inserted by concurrent users of the data store.
All the update information available for a rowset is considered an integral part of the rowset. The Cursor Service can disconnect the rowset from the underlying data source, persist it in the local file system, or remote it across process/machine boundaries. At a later stage, the updated rowset may be reconnected to the same session that originally created it (if it is still alive) or to a new session. After the reconnection, all the update information is available and the rowset can be updated via the Synchronization component.
The Synchronization Service performs the following functions: propagates updates to the data source, refreshes the data from the data source, and coordinates conflicting updates.
The Update Service has two modes of sending the updates back to the data provider: immediate and deferred. In immediate mode, changes are committed to the provider on a row-by-row basis. In deferred mode, the changes made to the rowset are buffered locally and the row's state is marked as changed. When the application decides to commit the changes, it calls the batch update method on the rowset and all buffered changes are sent to the data source.
Using a local static rowset with deferred updates is a common application scenario, offering the following three benefits. First, it provides fast data navigation because after the data is fetched, most operations are local. Second, it eliminates heavy concurrency in accessing data on the server. Optimistic conflict resolution allows you to resolve any conflicts. Finally, it reduces the overall network traffic associated with propagating changes to the data source by grouping multiple individual updates in a single request.
The Refresh function updates the rowset with the most recent data available from the provider. The scope of the Refresh command could be a large data field, a row, a set of rows, or the entire rowset. To perform a refresh, the Update Service requires information about the base tables used to produce the rowset and their primary keys.
For each row that has changed in a rowset, the Cursor Service maintains a copy of the original row fetched from the provider. When the updates are sent to the server, the Synchronization Service compares original values with the current values on the server to verify whether the row has changed since the data was fetched. The Synchronization Service compares the values using a combination of key columns, row timestamps, changed fields, and sometimes the entire row.
If a conflict is detected, the status for that row changes to indicate an update conflict. You have the option to get the current values for the conflicting row and compare them with the original row values and the changed values in the rowset. After you resolve the conflict, the update can be submitted again, this time using the current values to detect new update conflicts. The update service has the option to get current data for all conflicting rows in a batch. It also allows you to control how the local data is updated when conflicts are detected, to match the transaction model implemented by the application.
The Shape Service provides a hierarchical view of data and the reshaping capabilities that user interfaces and reporting tools require. This service works on top of the Cursor Service; it can create new hierarchical rowsets or aggregate existing rowsets into hierarchies. It implements three types of hierarchies, based on relation, parameters, and grouping. Hierarchical rowsets offer a flexible view of data. For example, an application could initially display the top level of a hierarchy, then let the user drill down into one or more levels of detail. Also, the same hierarchy can then be reshaped locally to offer a different perspective on the data.
To implement hierarchical results, the Shape Service adds a special column in the parent rowset for each of its children in the hierarchy. For each parent row, this column contains a reference to the corresponding child rowset. This reference is called a chapter handle in OLE DB and a recordset reference in ADO. A shape command defines a hierarchical result with clauses for each type of parent-child link (relation, parameter, and grouping).
Each type has a well-defined semantic, which governs the way the component results are created and related to each other. A hierarchical result can be arbitrarily complex and can include relations of any type among its components. More specifically, relation and group hierarchies can have as building blocks flat results and any type of hierarchical results. Parameterized hierarchies can have any rowset as parent but not as child, because the child is built dynamically upon accessing the data.
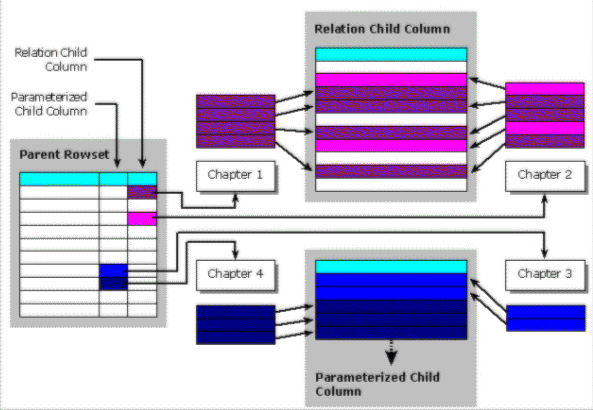
The previous diagram shows the implementation of hierarchical rowsets. When a hierarchy is created, the provider adds a column to the parent rowset to provide, for each row, a reference to its child rowset. When the value of a child column is requested, the Shape Service evaluates the parent-child relation for that row, then applies the corresponding filter to the child rowset and returns the resulting chapter handle. If the call is made from ADO, a recordset based on that chapter handle is returned. Different child rowsets of a relation hierarchy may share common rows. Child rowsets of a parameterized hierarchy are fetched dynamically and are always considered to have distinct rows. All data-manipulation and synchronization methods available for flat rowsets are also available for hierarchies. Similarly, events are available for hierarchical results. The following sections briefly define the three hierarchy types.
Two source rowsets, a parent and a child, create the relation hierarchy, and it usually models a one-to-many relationship between the two rowsets. The definition specifies the relation between the parent and the child via an equality predicate between two fields. When a child reference is requested, the child is filtered for the fields that match the corresponding field in the parent, and the resulting chapter or rowset is returned. Unlike hierarchical snapshots produced by a data source, the relation hierarchy is dynamic. For example, if the controlling parent field changes, the corresponding child rowset will change as well.
The parameterized hierarchy is similar to the relation hierarchy. The parent rowset is static and fetched up front. But the child rowset is defined using a parameterized command, having parent fields as command parameters. Initially the child contains no data. When a child reference is required, the shape provider executes the command and fetches the child data that matches the current parameter fields in the parent row. The child data for each row can either be saved locally and subsequently treated as static data or refetched each time a child reference is required. Because the child is dynamic, parameterized hierarchies can only be leaves in a multilevel hierarchy.
This hierarchy requires only one input rowset that will become the child of the group hierarchy. The shape provider performs a grouping on this rowset and stores the result in a new local rowset, the parent of the group hierarchy. The parent has a column to hold the group details for each row. Group hierarchies are static and can be created on top of any other hierarchy.
The Shape Service, based on the Cursor Service, provides the following functions:
The hierarchy syntax aggregates a result, as defined by a command or a name, and constructs a new hierarchy. A command is a cursor definition native to the data provider. Commands can contain parameters, which customize the hierarchy when it is created. A name refers to existing local results already built by the shape provider. The Shape Service can add columns to a new result. The new columns can be an aggregation function over child rowsets, an expression, or just a new user-defined column.
The value of the child reference column is by default different for each row because the Shape Service creates a new chapter every time. The provider can optionally return a unique child reference for a given child, and update the membership of the respective child chapter on row changes to contain the child rows for the current parent row.
The Shape Service applies the requery method called on the root rowset of a hierarchy to the entire hierarchy. All other functions such as navigation and synchronization are associated with each component rowset and should be called as needed on each component of a hierarchy.
The Microsoft Remote Data Service (RDS) component delivers the promise of Universal Data Access to "stateless" environments such as the Internet and the World Wide Web. RDS creates a framework that permits easy and efficient interaction with OLE DB data sources on corporate intranets and over the Internet. RDS provides the advantages of client-side caching of data results, updatability, and support for data-aware ActiveX controls. It provides the rich OLE DB/ADO programming model for manipulating data to browser-hosted applications.
Remote Data Service transports the rich client experience, implemented by the Cursor Service component, to applications connecting over the Internet or other networks where it is difficult or expensive to maintain a consistent connection. The following are the typical features of distributed applications running over disconnected networks such as the Internet.
Scalability of Web or application servers is tested every day by users accessing applications over the Internet. Even when the servers can scale to handle large numbers of Internet users, network bandwidths often cannot. Client computers must be able to accomplish more with less support from the server, and at times without even a server connection. Server resources need to be handled judiciously by new brands of applications.
To solve the scalability problem, RDS moves the application logic (that is, the user interface and client-side data manipulation) and data to the client. It implements a "stateless" model, in which client and server can be disconnected between data access operations. RDS marshals data efficiently between the middle tier or server and the client; it provides support for batch updates via an efficient client-side Cursor Service component that can process data locally without constant server requests. The work done at the client can be saved locally and later uploaded to the server when a connection is available.
Some of the most important tasks that Web and application server administrators handle are data integration, security, and application management. Organizations deploy business components that run on the application servers behind the Web servers and control complete access to underlying enterprise data. These components implement business rules and validation logic, allowing client applications to read and update data. The client applications make requests to the components that are under central control of the system administrator. RDS makes it easy to invoke these components over DCOM and HTTP and efficiently marshals input/output parameters, enabling effective distributed computing.
Remote Data Service is designed as an OLE DB service component. It builds on the foundation laid by the Cursor Service component and utilizes its services on the client machine as a data buffer. Consumers (that is, applications running on client machines) can use the RDS OLE DB provider to open OLE DB Rowset or ADO Recordset objects—these recordsets are originally created on middle tiers or servers where OLE DB data sources reside and then remoted (marshaled by value) to client machines. The following code snippets show how a remote, disconnected Recordset object is opened in ADO:
Dim rs as new ADODB.Recordset
rs.Open "Select * from Customers", "Provider=MS Remote; Remote Server=http://www.mysite.com; Remote provider = MSDASQL; DSN=pubs"
The only difference between the code shown here and that required to open a recordset when direct access to an OLE DB data source is available, is the format of the connection string. In the direct-access scenario, the code looks like this:
Dim rs as new ADODB.Recordset
rs.Open "Select * from Customers", "Provider=MSDASQL; DSN=pubs"
In the remoted case, the connection string identifies the server where the data source resides, the OLE DB provider to be used there to open the rowset, and any other information (such as a server name) needed to open the rowset.
The MS Remote provider is a standard OLE DB provider that supports standard OLE DB objects like Data Source, Session, and Command objects, and acts as a front end for providers across the network. For the Rowset object, it uses the Cursor Service component's rowset implementation. It buffers user requests on the Data Source, Session, and Command objects and processes them one after the other, as singular requests, across the network.
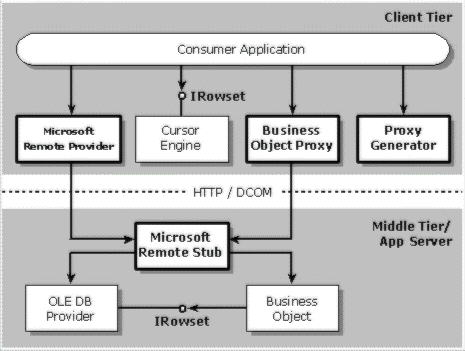
As shown in the previous figure, RDS enables two powerful scenarios for client-side applications. A consumer application can either specify the command and connection strings needed to open a rowset directly through an OLE DB provider, or it can invoke a business object on the server and marshal input and output parameters efficiently over HTTP and DCOM networks. Server administrators configure the server stub of the Remote provider where they can specify commands that can be executed or business components that can be invoked on behalf of remote clients.
Compare the two scenarios. Boxes with boldface labels represent objects implemented by the remoting service component.
In the OLE DB provider scenario, when a request is made to execute a command or open a rowset (step 1), all the settings are streamed across the network to a Remote provider stub on the server (step 2). The stub opens the rowset at the server by executing consumer requests (step 3). The OLE DB provider creates a rowset as the result of the request. This rowset is then streamed out on the wire in an efficient and compact format, and reconstructed using the Cursor Service component at the client by the Remote provider (step 4). An ADO recordset is handed back to the consumer application (step 5).
In an HTTP or DCOM network scenario, when a request is made to invoke an object (steps a and b), all the settings are streamed across the network to a Remote provider stub on the server (step c). The stub invokes the required component by executing consumer requests (step d). The invoked business component creates a rowset and returns it as an out-parameter (step e). This rowset is then streamed out on the wire in an efficient and compact format, and reconstructed using the Cursor Service component at the client by the Remote provider (step f). A client-side rowset is handed back to the consumer application (step g).
No proprietary network protocols are needed to work with RDS. It works over standard protocols like HTTP and DCOM. DCOM is now available on all Win32 platforms, Macintosh, and UNIX platforms. Here is a code snippet that shows how client applications can invoke business objects on the server:
Dim ProxyGen as new RDS.DataSpace
Dim BusProxy as object
Dim rsCust as ADODB.Recordset
Set CustProxy = ProxyGen.CreateObject("OrderEntry.Customer", "http://www.mysite.com")
Set rsCust = CustProxy.GetCustomer
RDS also allows local persistence of remoted data. The original values read by the server, along with changes made by the client, are persisted. A client can go offline and transmit the changes to the server at convenient times without losing valuable changes. Data persistence does not require any sophisticated data store or personal database on the client machine. The following code snippet shows how a recordset can be saved and reopened.
Dim rs as new ADODB.Recordset
rs.Open "Select * from Customer", "Provider=MS Remote;Remote Server="http://www.mysite.com";DSN=pubs"
…
rs("Cust_Status") = "Preferred" // Update customer records.
…
rs.movenext
rs("zip_code") = 98052
…
rs.save "c:\ADO\recordsets\customer.rs" // Persist the recordset in a local file.
rs.close
…
Dim rs1 as new ADODB.Recordset
rs1.open "c:\ADO\recordsets\customer.rs" // Reopen the recordset.
rs1.updatebatch // Propagate the changes back to the server
…
When a client requests updates to be propagated back to the server or middle tier, the Remote provider streams the rowset, including all changes and original values, back to the application server. At the server, the Cursor Service component reconstructs it. The Cursor Service component and the Synchronization component work together to update and resynchronize the rowset, as explained in the previous sections. Once the rowset has been updated and resynchronized, it can be remoted back to the client, where the consumer application can check the status of updates or read new values obtained from the server.
OLE DB Rowsets are self-describing objects that contain data and metadata, created by executing commands against data stores. Because of its self-describing nature, rowset information can be easily represented in a descriptive and flexible language such as XML. XML is, therefore, supported as a streaming and persisting format for rowsets. This opens up the use of rowsets to non-COM platforms—if XML representing structured data can be generated from there, it can be translated into rowsets on other machines and vice versa. This also allows Recordset objects to be transmitted over HTTP as part of standard HTML text. The following is a subsection of an XML stream representing rowsets:
<?XML version="1.0" encoding="UTF-8" ?>
<orders>
<schema id="rss">
<elementType id="Customer" occurs="ONEORMORE">
<element href="#NameEntry" occurs="ONEORMORE"></>
<element href="#Order" occurs="ONEORMORE"></>
<element href="#Date"></>
</elementType>
<elementType id="Date"> <pcdata></> </elementType>
<elementType id="NameEntry">
<element href="#FirstName"></>
<element href="#LastName"></>
</elementType>
<elementType id="LastName"> <pcdata></> </elementType>
<elementType id="FirstName"> <pcdata></> </elementType>
…
</schema>
<Customer>
<NameEntry>
<FirstName>Pierce</>
<LastName>Bronson</>
</NameEntry>
<Order>
<Name>Where the Sidewalk Ends</>
<Author>Shel Silverstein</>
<Price>$5.95</>
<Detail>
<Carrier>United Airlines</>
<SKU>411AAA</>
</Detail>
</Order>
…
<Date>7/7/97</>
</Customer>
…
</orders>
The Universal Data Access architecture is designed to provide uniform access to the variety of data sources available in a corporation. In this platform, ADO, a provider-neutral and language-independent data access object model, works in conjunction with OLE DB and its service component architecture, which extends a provider's native functionality transparently to the application and the provider. This architecture represents a new approach to extending database functionality dynamically at run time by aggregating OLE DB services using standard COM aggregation.
To date, there are OLE DB providers for most commercial relational DBMSs including Oracle, Microsoft SQL Server™, IBM DB2, Sybase, Informix, CA-Ingres, and ODBC sources. In addition, there are providers for VSAM, AS-400 files, IMS/DB, and Windows NT® files via a content search engine. OLE DB has recently been extended to other domains such as OLAP, and spatial data. There are distributed query processors over OLE DB data from International Software Group, B2Systems, Intersolv, and Microsoft SQL Server. OLE DB, ADO, and all services described here are part of the Microsoft Data Access 2.0 Components.