Microsoft Corporation
July 11, 1998
Introduction
Replication Model
Scalable Replication Solutions
Lower Complexity
Heterogeneous Interoperability
Other Distributed Technologies
Conclusion
Replication provides a fast and reliable way to disseminate corporate information to multiple locations in a distributed business environment, enabling organizations to move their data closer to knowledge workers in corporate, branch, or mobile offices. This paper provides information about the replication capabilities of Microsoft® SQL Server™ version 7.0, and how they can empower users, improve decision-making, and increase the performance and reliability of existing systems by reducing dependencies on centralized data.
What is it that a data warehouse, a corporate intranet, and a sales force automation application have in common? Aside from relying on a database for their storage requirements, all three of these application types have the requirement to move data quickly and reliably throughout an organization. For example, a data warehouse receives sales data from an order processing system; a corporate intranet application moves financial data from a site in New York to a site in Japan; and a sales force automation system replicates customer information to the laptop computer of a local sales representative.
Today, more and more business applications are being designed to run in distributed computing environments. In addition to distributing applications across a network of workstations, servers, and legacy mainframe systems, organizations are distributing applications from centralized corporate offices, to regional offices, to satellite offices, and, increasingly, to a mobile office (an employee's laptop computer).
Distributed office locations and personnel demand 24-hour operations and elaborate tracking systems, along with higher data integrity requirements. Aggravating the issue, most organizations have acquired a mix of disparate networks and computing platforms. The ensuing challenge for today's administrator is determining the best way to distribute large amounts of data across heterogeneous systems in a timely fashion.
With replication, customers can replicate data from one SQL Server database to others throughout the enterprise. SQL Server 7.0 replication goals include:
Provide a full range of scalable replication solutions to meet the complete spectrum of application requirements.
Lowers the cost and complexity by making replication easier to build, manage, and use.
Enables bidirectional replication capabilities to heterogeneous data sources and easy integration with third-party applications.
Microsoft SQL Server version 7.0 replication builds on the "publish and subscribe" model first introduced in SQL Server version 6.0. The model consists of Publishers, Subscribers and Distributors, publications and articles, and push and pull subscriptions. Four new intelligent Agents, Snapshot Agent, Log Reader Agent, Distribution Agent, and Merge Agent, manage the SQL Server 7.0 replication process. All Agents can run under the SQL Server Agent and are fully administered using SQL Server Enterprise Manager. The Snapshot and Log Reader Agents execute on the Distributor server, while the Distribution and Merge Agents execute on the Distributor server for push subscriptions, and execute on the Subscriber server for pull subscriptions. SQL Server Replication is built on OLE DB and ODBC, the industry standards for data access, providing rich interoperability with a wide variety of relational and nonrelational data sources.
Is a server that makes data available for replication to other servers. In addition to identifying which data are to be replicated, the Publisher detects which data has changed and maintains information about all publications at that site. Any given data element that is replicated has a single Publisher, even if it may be updated by any number of Subscribers or published again by a Subscriber.
Are servers that store replicas and receive updates. In earlier versions of SQL Server 7.0, updates could typically only be performed at the Publisher. SQL Server, however, allows Subscribers to make updates to data (but a Subscriber making updates is not the same as a Publisher). A Subscriber can, in turn, also become a Publisher to other Subscribers.
Is a collection of articles, and an article is a grouping of data to be replicated. An article can be an entire table, only certain columns (using a vertical filter), or only certain rows (using a horizontal filter), or even a stored procedure (in some types of replication). A publication often has multiple articles.
Is the server that contains the distribution database. The exact role of the Distributor is different in each type of SQL Server replication.
Prepares schema and initial data files of published tables and stored procedures, stores the snapshot on the Distributor, and records information about the synchronization status in the distribution database. Each publication has its own Snapshot Agent that runs on the Distributor and connects to the Publisher.
Moves transactions marked for replication from the transaction log on the Publisher to the distribution database. Each database published using transactional replication has its own Log Reader Agent that runs on the Distributor and connects to the Publisher.
Moves the transactions and snapshot jobs held in distribution database tables to Subscribers. Transactional and snapshot publications that are set up for immediate synchronization when a new subscription is created have their own Distribution Agent that runs on the Distributor and connects to the Subscriber. Transactional and snapshot publications not set up for immediate synchronization share a Distribution Agent across the Publisher/Subscriber pair that runs on the Distributor and connects to the Subscriber. Pull subscriptions to either snapshot or transactional publications have Distribution Agents that run on the Subscriber instead of the Distributor. The Distribution Agent typically runs under SQL Server Agent and can be directly administered by using SQL Server Enterprise Manager.
Moves and reconciles incremental data changes that occurred after the initial snapshot was created. In merge replication, data moves in either both directions (first from the Subscriber to the Publisher, then from the Publisher to the Subscriber) or one direction only. Each merge publication has its own Merge Agent that connects to both the Publisher and the Subscriber and updates both. Push subscriptions to merge publications have Merge Agents that run on the Publisher, while pull subscriptions to merge publications have Merge Agents that run on the Subscriber. Snapshot and transactional publications do not have Merge Agents. The Merge Agent can also be embedded and driven in an application using the Microsoft ActiveX® control.
Is one in which the Subscriber asks for periodic updates of all changes at the Publisher. Pull subscriptions are best for publications having a large number of Subscribers (for example, Subscribers using the Internet). Pull subscriptions are also best for autonomous mobile users because it allows them to determine when the data changes are synchronized. A single publication can support a mixture of push and pull subscriptions.
Is one in which the Publisher propagates the changes to the subscriber without a specific request from the Subscriber. Push subscriptions are used to propagate changes immediately as they occur, or when the schedule must be set by the publisher.
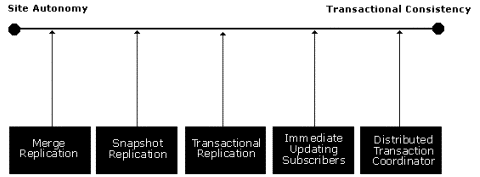
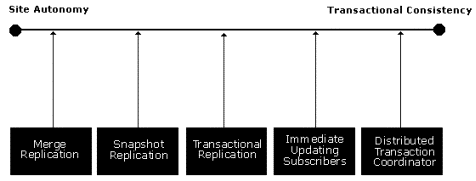
Replication is not a "one size fits all" solution. Businesses have different application requirements, and Microsoft SQL Server 7.0 delivers a broad range of replication solutions to meet them. Envision a spectrum of application requirements with site autonomy (all sites operating in a disconnected state) at one end, and transactional consistency (all sites are guaranteed to have exactly the same data values at exactly the same time) at the opposite end.
An applications position along the range of requirements will determine the selection of the appropriate replication solution. For example, contrast the requirements for a sales force automation system with an accounts receivable system. Both applications use replication for distributing data. However, the company's mobile sales force can take customer orders on laptop computers while disconnected from the central office network. The lack of a network connection (and an accurate report of inventory) must not prevent the salesperson from taking and submitting the order. Thus, the need for autonomy in the sales application outweighs the risk of taking orders for out-of-stock items (back orders are allowed). In contrast, the invoices sent out by the accounts receivable department must be completely accurate and current for auditing purposes. In this case, transactional consistency outweighs the need for employee autonomy.
SQL Server provides three types of replication to use as you design applications:
Each of these types provides different capabilities and different attributes for delivering on the goals of site autonomy and transaction consistency. However, these are not mutually exclusive technologies. It's not uncommon for the same application to use multiple replication types.
As its name implies, snapshot replication takes a picture, or snapshot, of the published data in the database at one moment in time. Snapshot replication is the simplest type of replication, and it guarantees latent consistency between the Publisher and Subscriber. Snapshot replication is most appropriate in read-only application scenarios such as look-up or code tables, or in decision support systems in which data latency requirements are not strict and data volumes are not excessive. Snapshots can be on a scheduled basis or on demand.
Snapshot replication requires less processor overhead than transactional replication because it doesn't require continuous monitoring of data changes on source servers. Instead of copying INSERT, UPDATE, and DELETE statements (characteristic of transactional replication), or data modifications (characteristic of merge replication), Subscribers are updated by a total refresh of the data set. Therefore, snapshot replication sends all the data to the Subscriber instead of sending just the changes. If the article is very large, it can require substantial network resources to transmit. In deciding if snapshot replication is appropriate, you must balance the size of the entire data set against the volatility of change to the data.
Snapshot replication offers strong site autonomy when updates are not made to subscriber data. If updates are required, snapshot replication provides little site autonomy, limiting its usefulness in a disconnected environment. The higher the update frequency, the more limited the solution. In either case, loose transactional consistency is maintained.
The second mode of replication is called transactional replication. Transactional replication monitors changes to the publishing server at the transaction level: insert, update or delete operations. Changes made to the publisher flow continuously or at scheduled intervals to one or more subscribing servers. Changes are usually propagated in near real time, typically with a latency of seconds. With transactional replication, changes must be made at the publishing site, avoiding conflicts and guaranteeing transactional consistency.
Only committed transactions are sent to subscribing servers, in the guaranteed order in which they were committed at the publisher. This guarantees loose transactional consistency: Ultimately all the subscribing sites will achieve the same values as those at the publisher. The data at any participating site will be the same as it would had all operations been performed at a single site.
If subscribers need near-real-time propagation of data changes, then they will need a network connection to the publisher. Transactional replication in a well-networked environment can provide very low latency to subscribers. Push subscribers would often receive changes within 5 or 10 seconds of when they occurred at the publisher, provided the network link remains available.
Because transactional replication relies on a given data element having only a single Publisher, it is most commonly used in application scenarios that allow for logical partitioning of data and data ownership. A branch system with centralized reporting (corporate rollup) is an appropriate use of transactional replication. In this scenario, data ownership is maintained at the branch level and is published to a centralized server for read-only reporting. Transactional replication is also an appropriate solution for periodic downloads of read-only data either in a well-connected or disconnected scenario. For example, each night a mobile salesperson, from a hotel room, pulls down only the incremental changes to a price list, which is modified only at the corporate office.
In their simplest form, both snapshot and transactional replication are based on a model of one-way replication, in which data is modified only at the Publisher and flows downstream to a Subscriber. However, some applications require the ability to update data at subscribing servers and have those changes flow upstream. The Immediate Updating Subscribers option available with either snapshot or transactional replications allows data to be updated at subscribing sites.
This option is set at when the article is created and allows a Subscriber to update the copy of its local data, as long as that update can be immediately reflected to the Publisher using the two-phase commit (2PC) protocol. If the update can be performed successfully between the Subscriber and the Publisher, then the Publisher propagates those changes to all other Subscribers at the time of the next distribution. Because the Subscriber making the update already has the data changes reflected locally, the user can continue working with the updated data secure in the guarantee that the Publisher data also reflects the change.
The Immediate Updating Subscribers option is most appropriate for use with well-connected and reliable networks where application contention for data is relatively low. For example, a distributed ticketing system maintains local replicas of the ticketing database so that available seating can be quickly accessed. However, a seat can only be sold once, so it's critical that the local transaction (for example, ticket sale) is immediately updated and committed to the central server, the Publisher. The transaction will then be replicated to all other local ticket offices in the next distribution, and any attempt to sell the same seat will be prohibited.
When a publication is enabled to support the Immediate Updating Subscribers option, a subscriber site can modify replicated data if the transaction can be performed using 2PC with the publisher. This approach provides latent guaranteed consistency to other Subscribers without requiring that updates only be done at the publishing site. The 2PC transaction back to the publisher is done automatically, so an application can be written as though it is updating just one site. This approach does not have the availability constraint of doing 2PC to all participating sites, because only the publisher needs to be available. After the change is made at the publisher under 2PC, it will eventually get published to all other subscribers to the publication, thereby maintaining latent guaranteed consistency.
This option avoids requiring that applications be written to perform data modification operations at the Publisher and read operations at the Subscriber. The application works with data at one site, and the 2PC transaction is performed automatically. The application should be equipped to deal with a failure in the transaction, just as it would in a nonreplication environment. If the transaction is successful, the Subscriber can immediately work with the changed values, and know that the update has been accepted at the Publisher without conflict and will eventually be replicated to every subscription of the publication. A subscriber performing updates does not have full autonomy, however, because the Publisher must be available at the time of the update. But autonomy is much higher than with the full 2PC case where every site must be available for any site to perform changes.
Transactional replication with the Immediate Updating Subscriber option is a good solution for applications requiring updates to replicas and transactional consistency. However, this depends on well-connected and reliable networks, which cannot always be guaranteed. Some applications require a replication solution that preserves transactional consistency during periodic disconnected times. In the release following SQL Server version 7.0, a new Queued Updating Subscriber option will be available to satisfy this requirement. (Note: All other capabilities presented in this paper are part of SQL Server 7.0.)
With the Queued Updating Subscriber option, a two-phase commit transaction is applied to the local data and to Microsoft Message Queue, a durable and reliable queue service built into Microsoft Windows NT® Server. When the site is again available, the changes are dequeued and distributed in original sequence to the publishing site. If no conflicts are detected, the changes are committed. However, if a conflict is detected the transaction and any subsequent transactions are rejected to maintain transactional consistency, and the subscriber making the change will be notified. In this way the application can guarantee transactional consistency in a disconnected network.
Merge replication provides the highest level of autonomy for any replication solution. Publishers and Subscribers can work completely independently and periodically reconnect to merge their results. If a conflict is created by changes being made to the same data element at multiple sites, those changes will be resolved automatically. These characteristics make merge replication an ideal solution for applications like sales force automation where users need full read/write access to local replicas of data in a highly disconnected environment.
When conflicts occur (more than one site updated the same data values) merge replication provides automatic conflict resolution. The winner of the conflict can be resolved based on assigned priorities, or who first submitted the change, or a combination of the two. Data values are only replicated and applied to other sites when the reconciliation processes occur, which might be hours, days or even weeks apart. Conflicts can be detected and resolved at the row level, or even at a specific column in a row.
The Snapshot Agent and Merge Agent perform merge replication. The Snapshot Agent prepares snapshot files containing schema and data of published tables, stores the files on the Distributor, and records synchronization jobs in the publication database. The Merge Agent applies the initial snapshot jobs held in the distribution database tables to the Subscriber. It also merges incremental data changes that occurred after the initial snapshot was created, and reconciles conflicts according to rules you configure or using a custom resolver you create.
When a table is published using merge replication, SQL Server makes three important changes to the schema of the database. First, SQL Server identifies a unique column for each row in the table being replicated. This allows the row to be uniquely identified across multiple copies of the table. If the base table already contains a unique identifier column with the ROWGUIDCOL property, SQL Server automatically uses that column as the row identifier for that replicated table. Otherwise, SQL Server adds the column rowguid (with the ROWGUIDCOL property) to the base table. SQL Server also adds an index on the rowguid column to the base table.
Second, SQL Server installs triggers that track changes to the data in each row or (optionally) each column. These triggers capture changes made to the base table and record these changes in merge system tables. Different triggers are generated for articles that track changes at the row level or the column level. Because SQL Server supports multiple triggers of the same type on the base table, merge replication triggers do not interfere with the application-defined triggers; that is, both application-defined and merge replication triggers can coexist.
Third, SQL Server adds several system tables to the database to support data tracking; efficient synchronization; and conflict detection, resolution and reporting. The tables msmerge_contents and msmerge_tombstone track the updates, inserts and deletes to the data within a publication. They use the unique identifier column rowguid to join to the base table. The generation column acts as a logical clock indicating when a row was last updated at a given site. Actual timestamps are not used for marking when changes occur, nor deciding conflicts, and there is no dependence on synchronized clocks between sites. At a given site, the generation numbers correspond to the order in which changes were performed by the Merge Agent or by a user at that site.
Under priority-based conflict resolution, every publication is assigned a priority number, 0 being the lowest and 100 the highest. The illustration below represents the simplest case. In this scenario all three sites agree that Site A created version one of the row, and no subsequent updates occurred. If Sites A and B both update the row, then Site A's update is the conflict winner, because it has the higher priority.
In a more complex scenario, suppose multiple changes have occurred to the same row since the last merge, then the maximum of site priorities of changes made since the common version is used to determine the conflict winner. For example, Site A makes version two and sends it to Site B, which makes version three, then sends version three back to Site A. Site C has also made a version two and reconciles with A. Choosing the maximum priority of changes that occurred since the common version is 100 (Site A's priority). Site A and B's joint changes are the priority winner, so Site A is the conflict winner.
Merge replication is designed to handle the needs for applications to have flexible conflict resolution schemes. An application can override the default, priority based resolution, by providing its own custom resolver. Custom resolvers are COM objects or stored procedures, written to the public resolver interface that will be invoked by the Merge Agent to support business rules during reconciliation.
For example, suppose multiple sites participate in monitoring a chemical process and record the low and high temperatures achieved in a test. A priority-based or first wins strategy would not deliver the "lowest low" and the "highest high" value. Design templates and code samples make it simple to create a custom resolver to solve this business case.
Merge replication is a great solution for disconnected applications requiring very high site autonomy, which either can be partitioned, or that does not need transactional consistency. Merge is not the right choice if transactional consistency is required and the application cannot supply that assurance of integrity using partitioning. Transactional consistency refers to the strict adherence to the ACID (Atomicity, Consistency, Isolation, Durability) properties, and specifically the D for durable transactions. Any replication solution allowing conflicts can by definition not achieve the ACID properties. Any time conflicts are resolved, some transaction that had been committed gets "undone," breaking the rule for durability.
One of the primary goals for Microsoft SQL Server version 7.0 replication is to make it easier to build, manage, and use. Microsoft has achieved this goal through a combination of wizards and sophisticated design and monitoring tools. SQL Server Enterprise Manager introduces several new wizards to simplify installation and maintenance of replication. From a single server or workstation that has Microsoft SQL Server installed, you can use SQL Server Enterprise Manager to set up a complete replication environment spanning as many servers as necessary across your enterprise. The Replication Monitor enables users to view and modify the replication properties and troubleshoot replication activity.
Microsoft SQL Server includes various replication wizards and numerous dialog boxes to help simplify the steps necessary to build and manage replication.
Helps you specify a server to use as a Distributor and, optionally, specify other replication components.
Helps you create a publication from the data in your database.
Helps you "push" a subscription from a publication on one server to one or more servers or server groups.
Helps you "pull" a subscription to a publication on one server into a database on another server.
Helps you disable publishing, distribution, or both on a server.
Helps you review and resolve conflicts that occurred during the merge replication process.
After you have used the wizards to initially configure replication and create publications and articles, you can change most of the initial settings through property dialog boxes.
After setting up your replication environment with the Replication Navigator, Replication Monitor is used for viewing the status of replication agents and troubleshooting potential problems at a Distributor. Replication Monitor is activated as a component of a server in SQL Server Enterprise Manager only when the server is enabled as a Distributor and the current user is a member of the sysadmin fixed server role. All replication agents must be scheduled through SQL Server Agent. Replication and Replication Monitor will not work unless SQL Server Agent is running.
You can use Replication Monitor in SQL Server Enterprise Manager to:
The Replication Monitor is a powerful tool for getting detailed information on publishers, publications and subscriptions. For example, the monitor can provide a list of all of the Publishers that use the server as a Distributor, display all of the publications for a particular Publisher or identify all subscriptions to a particular publication.
For troubleshooting purposes, the Replication Monitor provides the capability to graphically monitor the activity of all replication agents: Snapshot, Log Reader, Distribution, or Merge Agents. By first selecting a Distributor and clicking on Replication Monitor, you'll see a display of the four agents. Expanding the node for a specific agent, exposes the detailed activity of a specific agent and the task history of each replication agent.
Replication Monitor and the SQL Server Agent provide a powerful mechanism for setting up lights-out management for a replication environment. The Agent monitors the Windows NT application event log, watching for an event that qualifies as one of the defined alerts. If such an event occurs, SQL Server Agent responds automatically, either by executing a task that you have defined or by sending an e-mail or a pager message to a specified operator.
You can select a Distributor and use Replication Monitor to display a list of all of the replication-related alerts on the server.
To view the Windows NT application event log, use the Windows NT Event Viewer. If you are part of the Windows NT Administrators group, you can also view remote event logs. The event log contains SQL Server error messages as well as messages for all activities on the computer. When you use the Windows NT event log, each SQL Server session writes new events to an existing event log; you can filter the log for specific events. Unlike the SQL Server error log, a new event log is not created each time you start SQL Server; however, you can specify how long logged events will be retained.
Many distributed applications require interoperability with custom solutions and multiple data stores. SQL Server 7.0 addresses this requirement in two ways. First, all replication programming interfaces are exposed and documented, allowing software developers to integrate tightly with SQL Server replication. For example, an independent software vendor (ISV) specializing in building replication solutions can easily layer their functionality on top of SQL Server replication to support replication to and from multiple data stores. Or, using our open interfaces, a Sales Force Automation vendor could easily build SQL Server replication directly into their application, creating a seamless solution for customers. Second, SQL Server 7.0 replication is built on OLE DB and ODBC, the primary standards for data access, which provides built-in heterogeneous replication capabilities.
SQL Server supports replication to heterogeneous data sources that provide 32-bit ODBC or OLE DB drivers on the Microsoft Windows NT and Microsoft Windows® 95 operating systems. Out of the box, SQL Server supports Microsoft Access, Pocket Access, Oracle, and DB2 with Microsoft BackOffice® as heterogeneous subscribers. In addition, SQL Server 7.0 supports any other database server that complies with ODBC or OLE DB Subscriber requirements.
The simplest way to publish data to a Subscriber that is not running SQL Server is by using ODBC/OLE DB and creating a push subscription from the Publisher to the ODBC/OLE DB Subscriber. As an alternative, however, you can also create a publication and then create an application with an embedded distribution control. The embedded control implements the pull subscription from the Subscriber to the Publisher. For ODBC/OLE DB Subscribers, the subscribing database has no administrative capabilities regarding the replication being performed.
Microsoft SQL Server enables heterogeneous data sources to become Publishers within the SQL Server replication framework. Microsoft has exposed and published the replication interfaces, enabling a developer to use all the transaction replication features of SQL Server.
The replication services available to heterogeneous data sources include:
The following diagram illustrates how a heterogeneous data source is integrated into the replication framework as a Publisher.
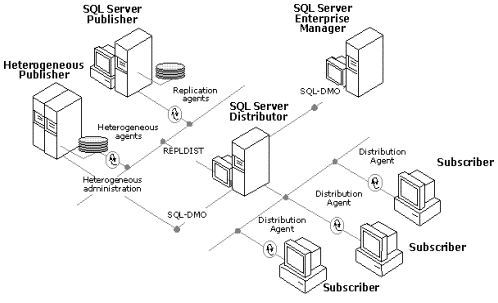
Microsoft has been actively evangelizing the Distributor Agent interfaces to the developer community to ensure that ISVs are able to tightly integrate their heterogeneous replication solutions with SQL Server 7.0. Several vendors, including Platinum and Praxis, are building to the distributor interfaces, allowing them to drop publications from third-party databases directly into the Microsoft Replication Framework. After a heterogeneous publication has been dropped into the distribution process, it can be easily monitored directly from third-party tools that support SQL-DMO replication objects.
Data replication is a complex technology, and SQL Server replication recognizes that a single solution is not right for all applications. Unlike other replication products that promote a single "update anywhere anytime" approach, SQL Server provides a variety of replication technologies that can be tailored to your application's specific requirements. Depending on your requirements, each technology provides different benefits and needs across three important dimensions:
Transactional consistency with respect to Replication means that the data at any participating site will be the same as it would if all operations had been performed at a single site. That is, the act of replicating the data does not in itself expose situations in which the data is changed in ways that would not occur if replication were not used. When working with distributed applications that modify data, there are three basic levels of transactional consistency:
With immediate guaranteed consistency (called tight consistency in SQL Server version 6.x), all participating sites are guaranteed to always see the exact same data values at the exact same time, and the data is in the state that would have been achieved had all the work been done at the publishing site. The only way to achieve immediate guaranteed consistency in a distributed update environment (in which updates can be made to the same data at any location) is with the use of a two-phase commit between all participating sites. Each site must simultaneously commit every change, or no site can commit the change. Such a solution is obviously not feasible for large numbers of sites because of unforeseen conditions, such as network outages.
With latent guaranteed consistency (called loose consistency in SQL Server version 6.x), all participating sites are guaranteed to have the same data values that were achieved at the publishing site at some point in time. But there can be a delay in the data values being reflected at the Subscriber sites, so that at any instant in time, the sites are not assured of having the exact same data values. If all data modification could be paused long enough to allow every site to catch up and have every change applied, then all sites would have the same data values. But just having the same value is not sufficient for latent guaranteed consistency. In addition, those values must also be the same that would have been achieved had all the work been done at one site. The difference between immediate and latent guaranteed consistency is whether the values are consistent at the same instant in time. If the system were allowed to catch up, then the values would ultimately be identical regardless of whether the system is based on immediate or latent guaranteed consistency.
With convergence, all the sites may end up with the same values, but not necessarily the ones that would have resulted had all the work been done at only one site. All sites may freely work in a disconnected manner, and when all the nodes have synchronized, all sites converge to the same values. Lotus NOTES is an example of a convergence product used to build useful distributed applications, yet it does not provide atomic transactions nor any model of guaranteed consistency.
Other database vendors, who support atomic transactions at a single site also, promote "update anywhere" replication solutions. Most offer the ability to resolve conflicts by discarding or changing the effects of one transaction because of another competing transaction performed at another node. These solutions are promoted as providing complete site autonomy. However, it's not well promoted that the act of conflict resolution means there is no guaranteed transactional consistency.
Three sites are participating in a replication scenario and Site 3 submits five transactions, T1, T2, T3, T4, and T5 for synchronization with the other two sites. Transactions T1 and T2 have no conflicts, and are accepted. But transaction T3 has a conflict, and the reconciliation mechanism discards this transaction. What is often not understood is that transactions T4 and T5 must also be discarded, because these transactions may have read, and depended on, data that transaction T3 had modified. Because that transaction was subsequently discarded, it logically never existed, and T4 and T5 are also in doubt. If they were accepted, this creates a situation in which results may differ from those that would have been obtained had all updates been done at a single site, breaking the rules of transactional consistency.
It should be clear that even a compensating transaction (for example, a delete if an insert had been accepted) is not sufficient to guarantee transactional consistency. The exposure is not the specific transaction, but rather in the possible changes that subsequent transactions may have applied because of the transient state of the data resulting from the transaction that was resolved away. To remain in a state where transactional consistency is guaranteed, not only must transaction T3 be discarded, but so must all subsequent work performed at that site, including T4 and T5.
Site autonomy refers to whether the operations of one site are seriously affected by those of another. There is complete site autonomy if one site's ability to do its normal work is independent of its connectivity to other sites, and the state of operations at those sites. For example, using 2PC makes every change to data dependent on whether every other participating site is able to successfully and immediately accept the transaction. If one site is unavailable, no work could proceed. At the other end of the spectrum, in merge replication every site works totally independently and can be completely disconnected from all other sites. Merge replication has high site autonomy but not guaranteed consistency. Two-phase commit has guaranteed tight consistency but a total absence of site autonomy. Other solutions are somewhere in the middle for both dimensions.
You can segregate data at multiple sites to provide your own guarantee of transactional consistency. Note that the absence of guaranteed transactional consistency does not imply guaranteed transactional inconsistency. If you can design your application so that each participating site works with data that is strictly segregated (or partitioned) from other sites, you can maintain transactional consistency. For example, to ensure that orders will never conflict, design your order entry system so that a given salesperson has a unique, known territory.
Partitioning adds a crucial third dimension to consider in designing and deploying distributed applications. While some of the SQL Server replication technologies allow for detection and resolution of conflicts, partitioning allows for avoidance of conflicts. When possible, it is better to avoid conflicts before the update rather than to resolve them afterwards. Conflict resolution always results in some site's work being overwritten or rolled back, and the loss of guaranteed transactional consistency. A high number of conflicts requires substantial processing to resolve, is more difficult to administer, and can result in data states that are entirely unpredictable and are not auditable. As a practical matter, if you choose a distributed technology that does not guarantee transactional integrity, you should be certain that your application and deployment won't produce many conflicts. Conflicts should be the exception, rather than the rule, and reconciliation can be used to resolve these exceptions.
Your requirements along and across these three dimensions will vary from one distributed application to the next. It is also possible that requirements on one dimension will conflict with another dimension. For example, it is commonly accepted that an application must use the 2PC update protocol to guarantee full transactional consistency and atomicity without conflicts when modifying the same data at multiple locations. However, 2PC requires fully available and reliable communication between all participating sites. This makes the use of 2PC inappropriate for many distributed applications because not all sites are "well-connected."
The illustration plots the SQL Server 7.0 Replication options along a linear progression with site autonomy at one end and transactional consistency at the other. This guideline combined with the individual characteristics of each option will drive the selection of the appropriate replication solution. Transactional consistency and autonomy can both be maintained if you partition your application.
Microsoft SQL Server 7.0 replication provides powerful technologies for building and supporting a wide range of distributed applications. However, there are applications for which replication may not be the best solution. For these applications, SQL Server introduces several other distributed database technologies:
These SQL Server technologies can be used either in conjunction with, or in place of replication, depending upon the requirements for your application.
Based on OLE DB, the distributed query technology for SQL Server 7.0 enables queries to heterogeneous data sources. Any data source supported by ODBC/OLE can participate in a distributed query. For example, an international company has eight regional offices, each using a different database product to store sales data (Oracle, Microsoft Access, Microsoft Excel, SQL Server, and so on). The sales manager uses distributed queries to read the data from each data source and prepare a quarterly report showing the sales, salary, and commission results for the last three years.
SQL Server allows a single SELECT statement to be issued to databases to the data sources, tapping into all the power of SQL, including heterogeneous joins and subqueries. If an application does require access to distributed data, but the use of a particular piece of data is infrequent, distributed queries may make more sense than replication.
Microsoft Distributed Transaction Coordinator supports distributed updates in an application and is the only way to guarantee tight consistency (all copies of your data always have the exact same data values at the exact same time) and that the data is in a state that would have been achieved if all the work had been done at one site. SQL Server ships with the Distributed Transaction Coordinator (DTC) service, which allows for this tight consistency, with real-time updates.
SQL Server Data Transformation Services (DTS) makes it easy to import, export, and transform data between multiple heterogeneous data sources using an OLE DB-based architecture. DTS allows you to move and transform data to and from:
Whether building a data warehouse, corporate intranet, sales force automation, or any other distributed application, replication plays the pivotal role of moving data quickly and reliably throughout the enterprise. SQL Server 7.0 makes this possible through a scalable range of replication solutions addressing the broadest spectrum of application requirements. These scalable replication solutions deliver power without the cost and complexity of competing replication technologies, making replication viable as a distributed application infrastructure. Built on industry standards, SQL Server 7.0 replication provides out-of-the-box interoperability with heterogeneous data sources, allowing businesses to easily integrate new applications and leverage their investments in other application platforms.
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.