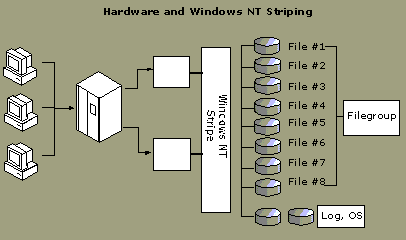
To spread the data evenly across multiple controllers requires one of three options:
Option 1: Use hardware striping only (and/or Microsoft Windows NT striping). This configuration requires a Windows NT stripe on top of a hardware stripe for each controller to make it look like one logical drive. The illustration shows this configuration.
Option 2: Use SQL Server to stripe. The capabilities of SQL Server files and filegroups allow you to spread the data evenly across all disks without hardware striping. If a physical file is created on each disk and a filegroup is assigned to each of these files, SQL Server uses proportional fill to evenly distribute the data across all of the files and all of the disks. The following illustration shows this option. Some disadvantages of this configuration are:
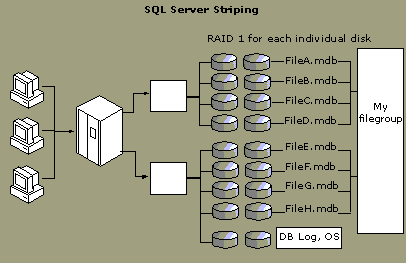
Because this configuration can be accomplished by using hardware striping with fewer disks and easier administration, this is not recommended.
Option 3: Use a combination of SQL Server and hardware striping. This configuration uses the best features of both options.
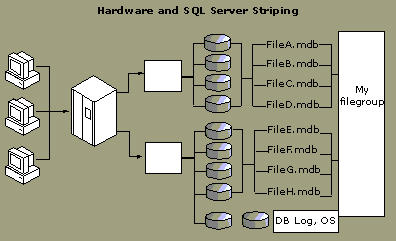
The illustration shows two controllers pointing to two hardware striped sets. An alternative to the Windows NT striping method that assigns data from all objects to all disks, a filegroup is assigned to all files on both stripe sets. This option spreads the data evenly across all disks while keeping administration simple, unlike options 1 and 2.
Recommendation:
One of the bigger challenges with SQL Server 6.5 and all other RDBMSs is the management of the physical space allocated to database objects such as tables and indexes. In SQL Server 6.5, if a database runs out of space, the database is inoperable until more space is added.
In SQL Server 7.0, files can grow automatically (autogrow) from their originally specified size. When you define a file, you can specify a growth increment. Each time the file fills, it increases its size by the growth increment set by the database creator. If there are multiple files in a filegroup, none of them grows automatically until all are full. Growth then occurs in a round-robin algorithm.
Each file can also have a specified maximum size. If a maximum size is not specified, the file continues to grow until it has used all available space on the disk. The lack of a maximum size is especially useful if a SQL Server database is embedded in an application for which no system administrator is readily accessible or if SQL Server is implemented in a distributed location without a database administrator. The files can grow automatically, reducing the administrative burden of monitoring the amount of free space in the database and of allocating additional space manually.
For example, a Sales database is created as a 50-MB data file. The autogrow feature is on, and it is set for 10 percent growth to a 500-MB maximum.
As soon as this database reaches 50 MB, 5 MB is added (50 MB + 50 MB*.10 = 55 MB). As soon as the database reaches 55 MB, 5.5 MB is added. This process continues until 500 MB is reached or until the database shrinks.
Performance degrades when a database must be altered to grow. If sufficient space is not initially assigned to a database, the database could grow continuously and performance would degrade slightly. The default autogrow setting is 10 percent of the size of the data file. For example, a database created at 1 MB with a maximum size of 500 MB requires multiple restarts of the autogrow feature if you add a large amount of new data. The database would start at 1 MB, grow to 1.1 MB, then grow to 1.22 MB, and then to 1.34 MB, and so on.
Although this method works, performance is improved if the initial file size and the percent growth are set to a reasonable size to avoid the frequent activation of the autogrow feature. In the previous example, a growth set to an increment of 5 MB would be better.
Recommendations:
You must decide whether to implement the autoshrink feature or manually shrink your data. The autoshrink feature is on by default for the Desktop Edition of SQL Server 7.0 and off by default for the Standard and Enterprise editions. The autoshrink feature can be set by using the sp_dboption stored procedure. When autoshrink is on, it executes every 30 minutes and shrinks in increments of 25-percent free space.
When sp_dboption is used to shrink the database automatically (autoshrink), shrinking occurs whenever a significant amount of free space is available in the database. However, the free space to be removed automatically cannot be configured. To remove a certain amount of free space, such as only 50 percent of the current free space in the database, you must run either the DBCC SHRINKFILE statement or DBCC SHRINKDATABASE statement manually.
For example, to manually decrease the size of the files in the UserDB database to allow 10-percent free space in the files of UserDB, use:
DBCC SHRINKDATABASE (UserDB, 10)GO
When the autoshrink feature or manual shrink is started, the best point to shrink to is calculated by using the free space setting as a guideline. The user cannot configure the point to shrink to when using the autoshrink feature. The shrinking task shrinks to the original or altered size of the created file only, although this can be overridden with the manual shrink file command. The following illustration shows the movement of each individual heap page (nonclustered index pages) row by row to create free space. B-tree nodes (for example, clustered index pages) are moved as a page to create free space. This shrinking task is a low priority background thread, but it can still affect performance on a busy system due to the movement and locking of pages. Avoid continuously autoshrinking and then autogrowing. Nonclustered index maintenance may be required to point to the new location of the data. Also, clustered indexes have the potential to fragment the clustered index pages, and you might consider reorganizing the clustered indexes periodically after shrinking.
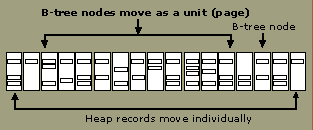
Recommendations:
A Microsoft SQL Server database has at least one data file and one transaction log file. Data and transaction log information is never mixed on the same file, and individual files are used by only one database.
SQL Server uses the transaction log of each database to recover transactions. The transaction log is a serial record of all modifications that have occurred in the database, and which transaction performed each modification. The log records the start of each transaction, the changes made to the data, and enough information to undo the modifications, if necessary. The log grows continuously as logged operations occur in the database. For some large operations, such as CREATE INDEX, the log records the fact that the operation took place. The log records the allocation and deallocation of pages, and the commit or rollback of each transaction. This allows SQL Server either to restore or to back out of each transaction:
At a checkpoint, SQL Server ensures that all log records and all database pages that have been modified are written to disk. During the recovery process of each database that occurs when SQL Server is restarted, a transaction must be rolled forward only when it is not known whether all the data modifications in the transaction were actually written from the SQL Server buffer cache to disk. Because a checkpoint forces all modified pages to disk, it represents the point at which the startup recovery must start rolling transactions forward. All pages that were modified before the checkpoint are guaranteed to be on disk, so there is no need to roll forward any transaction that was completed before the checkpoint.
Each log file is divided logically into smaller segments called virtual log files. Virtual log files are the unit of truncation for the transaction log. When a virtual log file no longer contains log records for active transactions, it can be truncated and the space becomes available to log new transactions.
The smallest size for a virtual log file is 256 KB. The minimum size for a transaction log is 512 KB, which provides two virtual log files of 256 KB each. The number and size of the virtual log files in a transaction log increase as the size of the log file increases. A small log file might have a small number of small virtual log files (for example, a 5-MB log file comprised of 5 virtual log files of 1 MB each). A very large log file has larger virtual log files (for example, a 500-MB log file comprised of 10 virtual log files of 50 MB each).
SQL Server avoids having many small virtual log files. When SQL Server recovers a database, it must read each virtual log file header. Each log file header costs one page I/O. The more virtual log files, the longer the time required for a database to start. Approximately 50 to 100 log files is acceptable; 1,000 log files may be too many. The number of virtual log files grows much more slowly than their respective sizes. If a log file grows in small increments, it tends to have many small virtual log files. If a log file grows in larger increments, SQL Server creates fewer larger virtual log files. For example, if the transaction log grows by 1-MB increments, the virtual log files are smaller and more numerous than those corresponding to a transaction log that grows at 50-MB increments.
By default, a log file automatically grows (autogrow) unless you specified otherwise when you created it. The log grows by the increment set at creation time. The increment can be a percentage of the file or a specific MB/GB value. Every time the autogrow feature activates, more virtual files are created. To avoid creating too many virtual files by preventing frequent activation of the autogrow feature, set the autogrow increment to a reasonable size. For example, if the log is 200 MB and grows to 400 MB daily, set the autogrow increment to 50 or 100 MB rather than to 1 MB.
The autogrow feature also stops the transaction log to allow for the addition of space. As a rough estimate, you can add 3 MB per second. As records are written to the log, the end of the log grows, moving from one virtual log file to the next. If there is more than one physical log file for a database, the end of the log grows, moving through each virtual log file in each physical file before it circles back to the first virtual log file in the first physical file. Only when all existing log files are full will the log begin to grow automatically.
The log can also be set to shrink automatically (autoshrink). By default, autoshrink is on for the SQL Server Desktop Edition and off for the Standard and Enterprise editions.
The autoshrink feature does not shrink logs smaller than their original sizes set by the database administrator. If the autoshrink feature is on, a calculation is performed every 30 minutes to determine how much of the log has been used. If the log size exceeds the original size, the log is marked for shrinkage, assuming available free space. The actual shrinking of the log takes place with the next log truncation or BACKUP TRANSACTION LOG statement. The shrinking of a log incurs a performance cost.
Recommendations:
In SQL Server 6.5, sp_configure options for improving the performance of the I/O subsystem include: max async IO, max lazywrite, RA cache hit limit, RA cache miss limit, RA delay, RA prefetches, RA slots, RA worker threads, recovery interval, and logwrite sleep. SQL Server 7.0 minimizes the manual tuning required of the database administrator when configuring a system. Most of the system configuration options in SQL Server 7.0 are self-tuning.
| SQL Server 6.5 | SQL Server 7.0 | |||
|---|---|---|---|---|
| Configuration options | Min. | Max | Min. | Max |
| max async IO | 1 | 1,024 | 1 | 255 |
| max lazywrite | 1 | 1,024 | N/A | N/A |
| RA cache hit limit | 1 | 255 | N/A | N/A |
| RA cache miss limit | 1 | 255 | N/A | N/A |
| RA delay | 0 | 500 | N/A | N/A |
| RA prefetches | 1 | 1,000 | N/A | N/A |
| RA slots | 1 | 255 | N/A | N/A |
| RA worker threads | 0 | 255 | N/A | N/A |
| recovery interval | 1 | 32,767 | 0 | 32,767 |
| logwrite sleep | 1 | 500 | N/A | N/A |
In SQL Server 7.0, the max lazywrite option is no longer available. The SQL Server memory manager calculates the right time to flush the data cache based on free buffers and activity.
In SQL Server 7.0, max async IO is still available but has changed to represent the maximum number of outstanding asynchronous disk input/output (I/O) requests that the entire server can issue against a file (not database). Therefore, you must know how many files are in the database. The default has changed from 8 in SQL Server 6.5 to 32 in SQL Server 7.0 because of the vast improvements in hardware speeds. As in SQL Server 6.5, you should monitor disk activity to determine if this parameter should be raised or lowered. If disk activity is low, this parameter can be raised. If there are spikes in disk activity showing 100 disk time and queue length greater than 3, consider lowering max async IO.
Recommendations:
Though read-ahead (RA), or prefetch, has been dramatically improved in SQL Server 7.0, all of its parameters have been removed. Read-ahead is tuned automatically based on data access. By using file maps, called Index Allocation Maps (IAM), each file is prefetched in parallel on sequential reads. Because the optimizer informs SQL Server when data needs to be scanned, SQL Server automatically activates read-ahead without tuning configuration parameters.
The logwrite sleep option has also been removed from SQL Server 7.0. logwrite sleep is rarely used in SQL Server 6.5, and it is recommended that the default remain unchanged. The logwrite sleep option delays the 16-KB buffer written from memory to the log to ensure that the buffer is being filled prior to writing to the log. In SQL Server 7.0, the log write operation has been improved dramatically; this configuration option is no longer necessary.
The recovery interval option controls when SQL Server issues a checkpoint to each database. Checkpoints are issued on a per database basis. At a checkpoint, SQL Server ensures all log information and all modified pages are flushed from memory to disk, reducing the time needed for recovery by limiting the number of transactions rolled forward. Modifications performed before the checkpoint must not be rolled forward because they have been flushed to disk at the checkpoint. The actual checkpoints are controlled by a combination of the recovery interval setting and how much data was written to the log during that interval. For example, if the recovery interval is set to 5 minutes and very little log activity has taken place after 5 minutes, the system checkpoint will not trigger.
In SQL Server 6.5, the default for recovery interval is 5 minutes. In SQL Server 7.0, the default is 0, which means SQL Server automatically configures the option. The recovery process is much quicker and the system checkpoint is less intrusive, therefore SQL Server may checkpoint more often to guarantee faster recovery upon a failure. Monitor the disk writes for the data to determine if this is the appropriate setting. If you see spikes of activity that is causing heavy use of the disk, you can change this parameter to checkpoint less often. If you are going to change this parameter, you may want to change it to 5 and continue monitoring.
Recommendations:
The tempdb database holds all temporary tables and work tables in queries and handles any other temporary storage needs such as sorting, joining, and aggregation of data for queries. The tempdb database is a global resource: The temporary tables and stored procedures for all users connected to the system are stored there. The tempdb database is re-created every time SQL Server starts so the system starts with a clean copy of the database. Because temporary tables and stored procedures are automatically dropped on disconnect, and no connections are active when the system is shut down, there is never anything in tempdb to be saved from one session of SQL Server to another.
Because of enhancements in the query processor, the tempdb database is used more often in SQL Server 7.0 than it is in earlier versions. As a guideline, expect the size of tempdb to be 25 to 50 percent larger, depending on the size and complexity of the queries.
Calculating an appropriate size for tempdb is challenging in SQL Server 6.5. When tempdb runs out of space, the active query requesting tempdb terminates. Therefore, you must make tempdb very large, even if only 1 to 5 percent of your activity requires a large database. SQL Server 7.0 addresses this issue with the autogrow feature of tempdb. The tempdb database automatically grows as needed. Each time the system is started, tempdb is reset to its default size. Automatically growing tempdb results in some performance degradation, just like automatically growing other user databases and logs. Set a reasonable size for tempdb and the autogrow increment to ensure that the autogrow feature is not frequently activated.
The tempdb database is on disk, therefore your disk configuration can affect performance. If tempdb is stored on a single physical disk and multiple requests are made for tempdb use, requests are quickly queued on that disk. A simple solution is to stripe tempdb across the same drives as the data and indexes. A larger stripe set with availability (either RAID 1 or RAID 5), results in adequate performance for tempdb unless the disks are already busy. The fastest performance for tempdb may result from storing tempdb alone on a separate set of RAID 0 disks. There is no contention and only one write because RAID 0 does not have a high availability feature. You can run tempdb with no availability because your current active transaction is lost only during a disk failure. tempdb is not persistent and is never recovered, therefore availability features on tempdb disks are not needed. The disadvantage is that if a physical drive fails, the whole server is inaccessible to users while you replace it. The trade-off is the availability of the server versus the performance of tempdb.
Recommendations:
In SQL Server 7.0, individual text, ntext, and image pages are not limited to holding data for only one occurrence of a text, ntext, or image column. A text, ntext, or image page can hold data from multiple rows; the page can even have a mix of text, ntext, and image data. This feature along with larger page sizes (8 KB) helps to reduce the space requirements for storing text and image data. The illustration shows potential space savings.
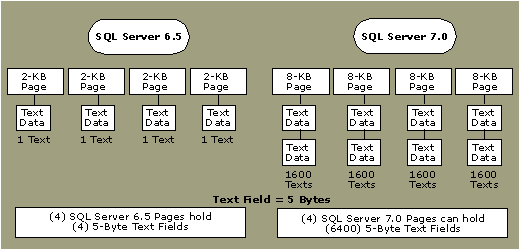
text, ntext, and image values are not stored as part of the data row but in a separate collection of pages. For each text, ntext, or image value, only a 16-byte pointer is stored in the data row. Each pointer indicates the location of the text, ntext, or image data. A row containing multiple text, ntext, or image columns has one pointer for each text, ntext, or image column.
Although you always work with text, ntext, and image data as if it were a single long string of bytes, the data is not stored in that format. The data is stored in a collection of 8-KB pages that are not necessarily located next to each other. In SQL Server 7.0, the pages are logically organized in a B-tree structure, and in earlier versions of SQL Server they are linked in a page chain. The advantage of the method used by SQL Server 7.0 is that operations starting in the middle of the string are more efficient. SQL Server 7.0 can quickly navigate the B-tree; earlier versions of SQL Server have to scan through the page chain. The structure of the B-tree differs slightly depending on whether there is less than 32 KB of data or more.
Although this B-tree storage method for text data may require more I/Os than a normal char or varchar data retrieval, it provides much faster text and content text search than in SQL Server 6.5.
Because SQL Server pages have increased from 2 KB to 8 KB, the char and varchar data types now allow up to 8,000 bytes of character data. If you have a text field with less than 8,000 bytes of data, you can use varchar instead of the text data type to improve query performance by avoiding traversing the text B-tree.
Recommendation: