Merge replication provides the highest level of autonomy for any replication solution. Publishers and Subscribers can work independently and reconnect periodically to merge their results. If a conflict is created by changes being made to the same data element at multiple sites, those changes are resolved automatically. These characteristics make merge replication an ideal solution for applications, such as sales force automation, in which users need full read/write access to local replicas of data in a highly disconnected environment.
When conflicts occur (more than one site updated the same data values), merge replication provides automatic conflict resolution. The winner of the conflict can be resolved based on assigned priorities, who first submitted the change, or a combination of the two. Data values are replicated and applied to other sites only when the reconciliation process occurs, which might be hours, days, or even weeks apart. Conflicts can be detected and resolved at the row level, or at a specific column in a row.
The Snapshot Agent and Merge Agent perform merge replication. The Snapshot Agent prepares snapshot files containing schema and data of published tables, stores the files on the Distributor, and records synchronization jobs in the publication database. The Merge Agent applies to the Subscriber the initial snapshot jobs held in the distribution database tables. It also merges incremental data changes that occurred after the initial snapshot was created, and reconciles conflicts according to rules you configure, or using a custom resolver you create.
When a table is published with merge replication, SQL Server makes three important changes to the schema of the database. First, SQL Server identifies a unique column for each row in the table being replicated. This allows the row to be uniquely identified across multiple copies of the table. If the base table already contains a unique identifier column (rowguid) with the ROWGUIDCOL property, SQL Server uses that column as the row identifier for that replicated table automatically. Otherwise, SQL Server adds the column rowguid (with the ROWGUIDCOL property) to the base table. SQL Server also adds an index on the rowguid column to the base table.
Second, SQL Server installs triggers that track changes to the data in each row or (optionally) each column. These triggers capture changes made to the base table and record these changes in merge system tables. Different triggers are generated for articles that track changes at the row level or the column level. Because SQL Server supports multiple triggers of the same type on the base table, merge replication triggers do not interfere with the application-defined triggers; that is, application-defined triggers and merge replication triggers can coexist.
Third, SQL Server adds several system tables to the database to support data tracking; efficient synchronization; and conflict detection, resolution, and reporting. The msmerge_contents and msmerge_tombstone tables track the updates, inserts, and deletes to the data within a publication. They use the unique identifier column rowguid to join to the base table. The generation column acts as a logical clock indicating when a row was last updated at a given site. Actual timestamps are not used for marking when changes occur, or for deciding conflicts, and there is no dependence on synchronized clocks between sites. At a given site, the generation numbers correspond to the order in which changes were performed by the Merge Agent or by a user at that site.
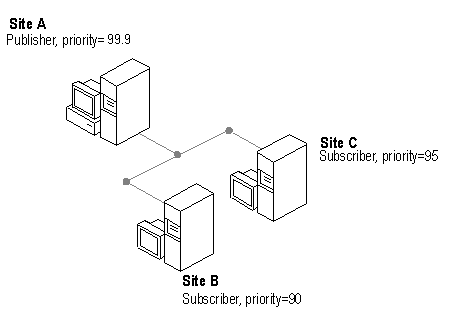
Under priority-based conflict resolution, every publication is assigned a priority number, 0 being the lowest and 100 the highest. The following diagram represents the simplest case. In this scenario, all three sites agree that Site A created version one of the row, and no subsequent updates occurred. If Sites A and B both update the row, the Site A update is the conflict winner because it has the higher priority.
In a more complex scenario, if multiple changes have occurred to the same row since the last merge, the maximum site priority for a change that was made to the common version is used to determine the conflict winner. For example, Site A makes version two, and sends it to Site B, which makes version three. Site B then sends version three back to Site A. In the meantime, Site C also made a version two and attempts to reconcile it with A. The maximum site priority for the changes that occurred to the common version is 100 (Site A's priority). Site A and B's joint changes are thus the priority winner, so Site A is the conflict winner.
Merge replication is designed to handle an application's need for flexible conflict resolution schemes. An application can override the default, priority-based resolution by providing its own custom resolver. Custom resolvers are COM-objects or stored procedures that are written to the public resolver interface and invoked during reconciliation by the Merge Agent to support business rules.
For example, suppose multiple sites participate in monitoring a chemical process and record the low and high temperatures achieved in a test. A priority-based or first-wins strategy would not deliver the "lowest low" and the "highest high" values. Design templates and code samples help you create a custom resolver to solve such a business case.
Merge replication is a great solution for disconnected applications that require very high site autonomy, can be partitioned, or do not need transactional consistency. Merge replication is not the right choice for applications that require transactional consistency and cannot supply an assurance of integrity by using partitioning. Transactional consistency refers to strict adherence to the ACID (Atomicity, Consistency, Isolation, Durability) properties, specifically durability. Any replication solution that allows conflicts cannot, by definition, achieve the ACID properties. Any time conflicts are resolved, a transaction that had been committed is undone, breaking the rule for durability.