SQL Server 7.0 offers three types of replication:
The replication agent copies an entire view of data to another computer. The destination database view is overwritten with the new version.
Transactions (INSERT, UPDATE, or DELETE statements) executed on one computer are replicated to another computer.
Updates on any computer are replicated to another computer at a later time.
For applications with disconnected users, merge replication is the most frequently used form of replication. Merge replication maintains consistency between mobile clients and the central server. It supports bidirectional updates, meaning that during the synchronization process, new or updated records on the mobile client are copied to the server, and vice versa, to ensure that both copies remain synchronized. If two mobile clients change the same data, SQL Server applies criteria that you established to resolve the conflict on the central database automatically.
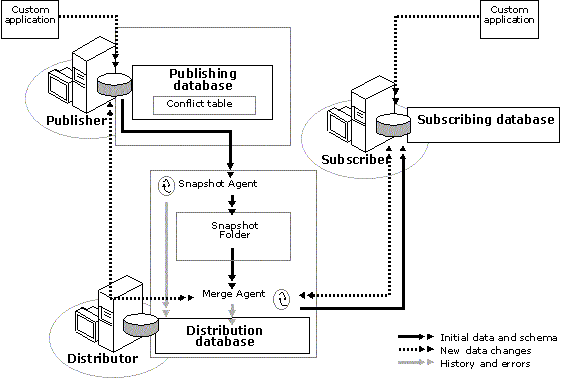
SQL Server 7.0 uses a publish and subscribe metaphor to set up and administer replication. A Publisher offers publications, which contain articles (tables or views), to which other SQL Server databases or Open Database Connectivity (ODBC) data sources can subscribe. A Subscriber receives publications. A distributor retrieves and stores modified data from the Publisher and sends the data to the Subscriber. In the case of merge replication, the Subscriber can be either another SQL Server database or a Microsoft Access 2000 database.
When a subscription is initiated, the Publisher sends the Subscriber an initial snapshot of the publication. This creates the necessary database objects (schemas and data) for the Subscriber. This customizable script is generated automatically by SQL Server.
After the initial snapshot is set up, only changes made on the Publisher (not the entire publication) are sent to the Subscriber. Each time a record is added, modified, or deleted, SQL Server detects the changes and sends the appropriate Transact-SQL statement to a distribution server. If many clients are subscribing to a single SQL Server database, an administrator may assign the role of distribution server to another instance of SQL Server to improve performance. The distribution engine can send updates to Subscribers, either on demand or as scheduled. The Subscriber also can initiate merge replication.
SQL Server 7.0 allows you to publish a subset of rows and columns from a table. For example, sales representatives typically cover a specific geographic territory. In this case, you would replicate only the data relevant to each sales representative. SQL Server allows you pass parameters to publications, which simplifies the process of supporting many subscribers. For example, an administrator may want to pass the username and computer name to a publication as a parameter so that each sales representative receives data about their sales region only.
The architecture required to support merge replication may vary significantly depending on these factors:
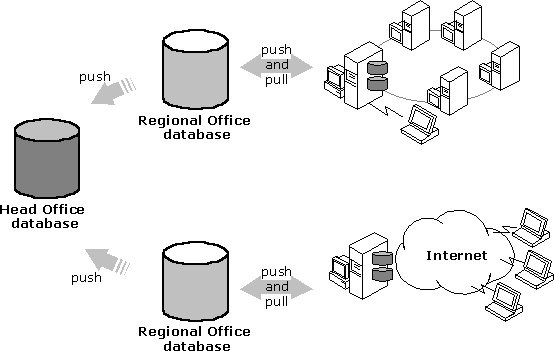
A carefully considered architecture and rigorous operational procedures are key to the successful implementation of a mobile application. For example, it is not practical to have multiple clients simultaneously trying to synchronize with a single database. This not only strains the physical resources of the network, but it also means that updates to the central database occur so frequently that nobody has an up-to-date version of the data.
To solve this problem, the central database should be partitioned over several servers that are located as geographically close as possible to the mobile client. The following diagram demonstrates how a database might be partitioned to support multiple clients.
Performance and scalability of merge replication can be greatly enhanced by:
SQL Server 7.0 uses a variety of communication methods to synchronize updates:
SQL Server 7.0 assures delivery of updates regardless of the communication protocol. For more information about network library support, see SQL Server Books Online.
Sybase Adaptive Server Anywhere 6.0 uses a message-based replication system called SQL Remote to synchronize updates between a client and the server. Sybase SQL Remote uses the File, FTP, MAPI, SMTP, and VIM message-based protocols.
There are several problems inherent to relying on message-based protocols: