This section contains information about how SQL Server data and index structures are physically placed on disk drives and how these structures apply to disk I/O performance.
SQL Server data and index pages are 8 KB each. SQL Server data pages contain all of the data associated with the rows of a table, except text and image data. For text and image data, the SQL Server data page, which contains the row associated with the text or image column, contains a pointer to a B-tree structure of one or more 8-KB pages.
SQL Server index pages contain only data from columns that comprise a particular index; therefore, an 8-KB index page contains much more information than an 8-KB data page because it compresses information associated with many more rows. If the columns picked to be part of an index form a low percentage of the row size of the table, information about more rows can be compressed in an 8-KB index page, which has performance benefits. When an SQL query requests a set of rows from a table in which columns in the query match values in the rows, SQL Server can save I/O operations by reading the index pages for the values and then accessing only the rows in the table required to satisfy the query. Therefore, SQL Server does not have to perform I/O operations to scan all rows in the table to locate the required rows.
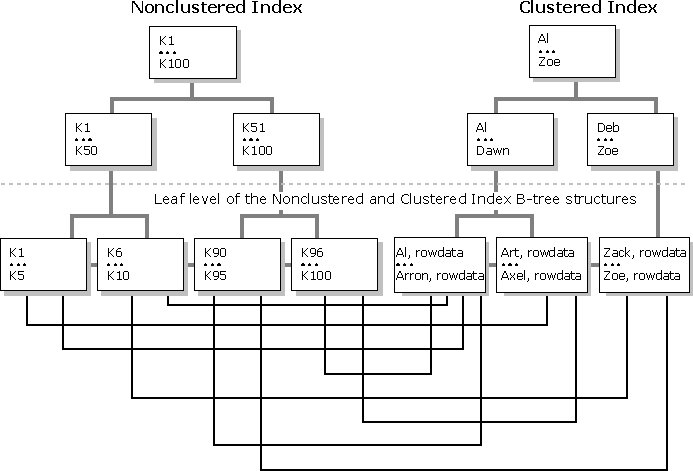
SQL Server indexes are built upon B-tree structures formed out of 8-KB index pages. The difference between clustered and nonclustered indexes is at the bottom of the B-tree structures (referred to as leaf level). The upper parts of index B-tree structures are referred to as nonleaf levels of the index. A B-tree structure is built for every single index defined on a SQL Server table.
In a nonclustered index, the leaf-level nodes contain only the data that participates in the index. In the nonclusterered index leaf-level nodes, index rows contain pointers to the remaining row data on the associated data page. At worst, each row access from the nonclustered index requires an additional nonsequential disk I/O to retrieve the row data. At best, many of the required rows will be on the same data page and thus allow retrieval of several required rows with each data page fetched.
In the clustered index, the leaf-level nodes of the index are the actual data rows for the table. Therefore, no bookmark lookups are required for retrieval of table data. Range scans based on clustered indexes perform well because the leaf level of the clustered index (and hence all rows of that table) is physically ordered on disk by the columns that comprise the clustered index, and will perform I/O in 64-KB extents. These 64-KB I/Os are physically sequential if there is not much page splitting on the clustered index B-tree (nonleaf and leaf levels). The dotted lines indicate there are other 8-KB pages present in the B-tree structures but they are not shown. The illustration shows the structural difference between nonclustered and clustered indexes.