 To start the logging feature (Performance Monitor)
To start the logging feature (Performance Monitor)
Windows NT Performance Monitor provides information about Windows and SQL Server operations occurring on the database server. For SQL Server specific counters, see SQL Server Books Online.
In Performance Monitor graph mode, note the Max and Min values. Do not emphasize the average because polarized data points can affect this value. Study the graph shape and compare to Min and Max to gather an accurate understanding of the behavior. Use BACKSPACE to highlight counters.
You can use Performance Monitor to log all available Windows NT and SQL Server performance monitor objects and counters in a log file and also to view Performance Monitor interactively in chart mode. Setting a sampling interval determines how quickly the log file grows. Log files can get big fast (for example, 100 MG in one hour with all counters turned on and a sampling interval of 15 seconds). The test server should have a couple of gigabytes free to store these files. But if conserving space is important, try running with a large log interval of 30 or 60 seconds. By doing so, Performance Monitor does not sample the system as often, and all of the counters are resampled with reasonable frequency, but a smaller log file size is maintained.
Performance Monitor also consumes some CPU and Disk I/O resources. If a system does not have much disk I/O and/or CPU to spare, consider running Performance Monitor from another computer to monitor the server running SQL Server over the network. This applies to Performance Monitor graph mode only. When using log mode, it is more efficient to log Performance Monitor information locally on the server running SQL Server. If you must use log mode over the network, then consider reducing the logging to only the most critical counters.
You should log all counters available during performance test runs into a file for analysis later. Configure Performance Monitor to log all counters into a log file and at the same time monitor the most interesting counters in one of the other modes, such as graph mode. This way, all of the information is recorded, but the most interesting counters are presented in an uncluttered Performance Monitor graph while the performance run is taking place.
To start the logging feature (Performance Monitor)
To stop the logging feature (Performance Monitor)
To load the logged information into Performance Monitor (Performance Monitor)
To relate Performance Monitor logged events back to a point in time
You can observe several Performance Monitor disk counters. To enable these counters, run the diskperf -y command from a Windows NT command window and restart Windows NT. The diskperf -y command consumes some resources on the database server, but it is worthwhile to run the diskperf -y command on all production SQL Server servers. As a result, disk queuing problems can be confirmed immediately and all Performance Monitor counters are immediately available to diagnose disk I/O issues. If disk I/O counters are required, the diskperf -y command must be executed, and Windows NT must be restarted before the disk I/O counters will report data in Performance Monitor.
Physical hard disk drives that experience disk queuing hold back disk I/O requests while they catch up on I/O processing. SQL Server response time is degraded for these drives, which costs query execution time.
If you use RAID, you must know how many physical hard disk drives are associated with each drive array that Windows NT interprets as a single physical drive so you can calculate disk queuing per physical drive. A hardware expert can explain the SCSI channel and physical drive distribution to help you understand how SQL Server data is held by each physical drive and how much SQL Server data is distributed on each SCSI channel.
There are several choices for viewing disk queuing in Performance Monitor. Logical disk counters are associated with the logical drive letters assigned by the Windows NT Disk Administrator, whereas physical disk counters are associated with what Windows NT Disk Administrator interprets as a single physical disk device. What looks like a single physical device to the Windows NT Disk Administrator may be either a single hard disk drive or a RAID array, which consists of several hard disk drives. The Current Disk Queue counter is an instantaneous measure of disk queuing, whereas the Average Disk Queue counter averages the disk queuing measurement over the Performance Monitor sampling period. Take note of any counter in which Logical Disk: Average Disk Queue is greater than 2, Physical Disk: Average Disk Queue is greater than 2, Logical Disk: Current Disk Queue is greater than 2, or Physical Disk: Average Disk Queue is greater than 2.
These recommended measurements are specified per physical hard disk drive. If a RAID array is associated with a disk queue measurement, the measurement must be divided by the number of physical hard disk drives in the RAID array to determine the disk queuing per physical hard disk drive.
On physical hard disk drives or RAID arrays that hold SQL Server log files, disk queuing is not a useful measure because SQL Server log manager does not queue more than a single I/O request to SQL Server log file(s).
For more information, see SQL Server Books Online.
When the System: Processor Queue Length counter is greater than 2, the server processors are receiving more work requests than they can handle as a group; therefore, Windows must place these requests in a queue.
Some processor queuing can be an indicator of good SQL Server I/O performance. If there is no processor queuing and if CPU use is low, it can be an indication of a performance bottleneck somewhere in the system, and most likely in the disk subsystem. A reasonable amount of work in the processor queue means that the CPUs are not idle and the rest of the system is keeping pace with the CPUs.
A general rule for determining an optimal processor queue number is to multiply the number of CPUs on the database server by 2.
Processor queuing significantly above 2 per CPU should be investigated. Excessive processor queuing costs query execution time. Eliminating hard and soft paging can help save CPU resources. Other methods that help reduce processor queuing include tuning SQL queries, picking better SQL indexes to reduce disk I/O (and hence CPU), or adding more CPUs (processors) to the system.
Memory: Pages/Sec greater than 0 or Memory: Page Reads/Sec greater than 5 means that Windows is going to disk to resolve memory references (hard page fault), which costs disk I/O and CPU resources. The Memory: Pages/Sec counter is a good indicator of the amount of paging that Windows is performing and the adequacy of the database server RAM configuration. A subset of the hard paging information in Performance Monitor is the number of times per second Windows had to read from the paging file to resolve memory references, which is represented by the Memory: Pages Reads/Sec counter. A value of Memory: Pages Reads/Sec greater than 5 is bad for performance.
Automatic SQL Server memory tuning adjusts SQL Server memory use dynamically so that paging is avoided. A small number of pages per second is normal but excessive paging requires corrective action.
If SQL Server is automatically tuning memory, then adding more RAM or removing other applications from the database server are options to help bring the Memory: Pages/Sec counter to a reasonable level.
If SQL Server memory is being configured manually on the database server, it may be necessary to reduce memory given to SQL Server, remove other applications from the database server, or add more RAM to the database server.
Keeping Memory: Pages/Sec at or close to 0 helps database server performance because Windows and all its applications (including SQL Server) are not going to the paging file to satisfy any data in memory requests; therefore, the amount of RAM on the server is sufficient. A Pages/Sec value slightly greater than 0 is not critical, but a relatively high performance penalty (Disk I/O) is paid every time data is retrieved from the paging file rather than from RAM.
You should understand the difference between the Memory: Pages Input/sec counter and the Memory: Pages Reads/sec counter. The Memory: Pages Input/sec counter indicates the actual number of Windows 4-KB pages being brought from disk to satisfy page faults. The Memory: Pages Reads/sec counter indicates how many disk I/O requests are made per second to satisfy page faults, which provides a slightly different point of view. A single page read can contain several Windows 4-KB pages. Disk I/O performs better as the packet size of data increases (64 KB or more), so it can be worthwhile to consider these counters at the same time. For a hard disk drive, completing a single read or write of 4 KB costs almost as much time as a single read or write of 64 KB. Consider this situation: 200 page reads consisting of eight 4-KB pages per read could finish faster than 300 page reads consisting of one 4-KB page. And we are comparing 1600 4-KB page reads finishing faster than 300 4-KB page reads. The key to all disk I/O analysis is to watch not only the number of disk bytes/sec but also the disk transfers/sec. For more information, see "Disk I/O Counters" and "The EMC Disk I/O Tuning Scenario" later in this chapter.
It is useful to compare the Memory: Page Input/sec counter to the Logical Disk: Disk Reads/sec counter across all drives associated with the Windows NT paging file, and the Memory: Page Output/sec counter to the Logical Disk: Disk Writes/sec counter across all drives associated with the Windows paging file. They provide a measure of how much disk I/O is strictly related to paging as opposed to other applications, such as SQL Server. Another way to isolate paging file I/O activity is to ensure the paging file is located on a separate set of drives from all other SQL Server files. Separating the paging file from the SQL Server files also can help disk I/O performance, because disk I/O associated with paging can be performed in parallel to disk I/O associated with SQL Server.
A Memory: Pages Faults/Sec counter greater than 2 indicates that Windows NT is paging but includes hard and soft paging within the counter. Soft paging means that there are application(s) on the database server that requests memory pages still inside RAM but outside of the application's Working Set. The Memory: Page Faults/Sec counter is helpful for deriving the amount of soft paging that occurs. There is no counter called soft faults per second. Instead, calculate the number of soft faults happening per second this way:
Memory: Pages Faults/sec - Memory: Pages Input/sec = Soft Page Faults per Second
To determine if SQL Server is causing excessive paging, monitor the Process: Page Faults/sec counter for the SQL Server process and note whether the number of page faults per second for Sqlservr.exe is similar to the number of pages per second.
Because soft faults consume CPU resources and hard faults consume disk I/O resources, soft faults are better than hard faults for performance. The best environment for performance is to have no faulting of any kind.
Until SQL Server accesses all of its data cache pages for the first time, the initial access to each page causes a soft fault, so do not be concerned if soft faulting occurs under these circumstances. For more information, see "Monitoring Processors" later in this chapter.
For more information on memory tuning, see SQL Server Books Online.
Keep all server processors busy enough to maximize performance but not so busy that processor bottlenecks occur. The performance tuning challenge is to determine the source of the bottleneck. If CPU is not the bottleneck, then a primary candidate is the disk subsystem, and the CPU is being wasted. CPU is the most difficult resource to expand above a specific configuration level, such as four or eight on many current systems, so it is a good sign when CPU utilization is above 95 percent. In addition, the response time of transactions should be monitored. Greater than 95 percent CPU use can mean that the workload is too much for the available CPU resources and either the CPU must be increased or the workload must be reduced or tuned.
Monitor the Processor: Processor Time % counter to ensure all processors are consistently below 95 percent utilization on each CPU. The System: Processor Queue counter is the processor queue for all CPUs on a Windows NT-based system. If the System: Processor Queue counter value is greater than 2 per CPU, there is a CPU bottleneck, and it is necessary to either add processors to the server or reduce the workload on the system. Reducing workload can be accomplished by query tuning or improving indexes to reduce I/O and subsequently CPU usage.
Another counter to monitor when a CPU bottleneck is suspected is System: Context Switches/sec because it indicates the number of times per second that Windows NT and SQL Server had to change from executing on one thread to executing on another. Context switching is a normal component of a multithreaded, multiprocessor environment, but excessive context switching slows down a system. Only be concerned about context switching if there is processor queuing. If processor queuing is observed, use the level of context switching as a gauge when you performance tune SQL Server. Consider using the lightweight pooling option so that SQL Server switches to a fiber-based scheduling model versus the default thread-based scheduling model. Think of fibers as lightweight threads. Use command sp_configure 'lightweight pooling', 1 to enable fiber-based scheduling. Watch processor queuing and context switching to monitor the effect.
For more information about I/O, memory, and CPU use mapped to SPID, see the DBCC SQLPERF (THREADS) statement in SQL Server Books Online.
The Disk Write Bytes/sec and Disk Read Bytes/sec counters provide the data throughput in bytes per second per logical drive. Weigh these numbers carefully along with the values of the Disk Reads/sec and Disk Writes/sec counters. Do not allow few bytes per second to lead you to believe that the disk I/O subsystem is not busy. A single hard disk drive is capable of supporting a total of 75 nonsequential and 150 sequential disk reads and disk writes per second.
Monitor the Disk Queue Length counter for all drives associated with SQL Server files and determine which files are associated with excessive disk queuing.
If Performance Monitor indicates that some drives are not as busy as others, you can move SQL Server files from drives that are bottlenecking to drives that are not as busy. This spreads disk I/O activity more evenly across hard disk drives. If one large drive pool is used for SQL Server files, the resolution to disk queuing is to make the I/O capacity of the pool bigger by adding more physical drives to the pool.
Disk queuing may be a symptom that one SCSI channel is saturated with I/O requests. Performance Monitor cannot directly detect if this is true. Hardware vendors can provide tools to detect the amount of I/O serviced by a RAID controller and whether the controller is queuing I/O requests. This is more likely to occur if many disk drives (10 or more) are attached to the SCSI channel, and they all perform I/O at full speed. To resolve this issue, take half of the disk drives and connect them to another SCSI channel or RAID controller to balance the I/O. Rebalancing drives across SCSI channels requires a rebuild of the RAID arrays and full backup and restore of the SQL Server database files.
The illustration shows typical counters that Performance Monitor uses to observe performance. The Processor Queue Length counter is being observed. Click BackSpace to highlight the current counter. This helps to distinguish the current counter from other counters being observed and can be particularly helpful when observing many counters at the same time with Performance Monitor.
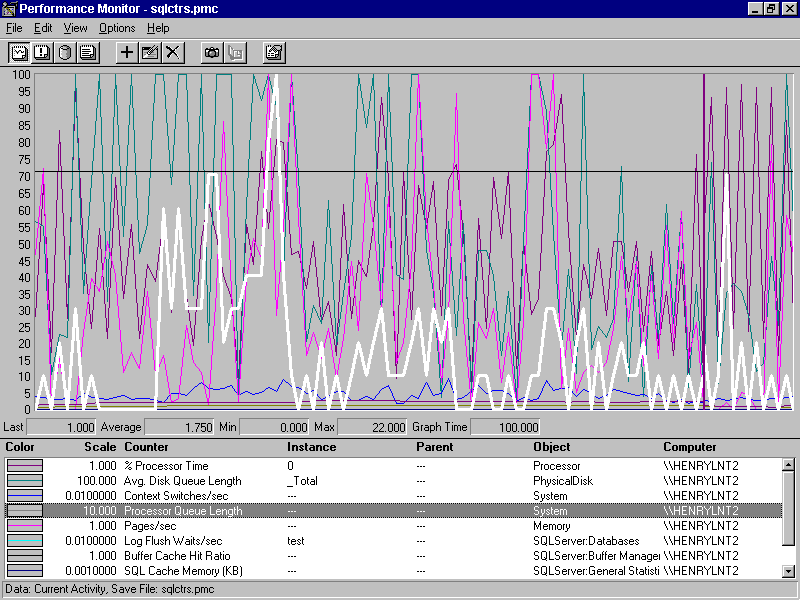
The Max value for Processor Queue Length is 22.000. The values of Max, Min, and Average for the Performance Monitor Graph cover only the current time window for the graph, as indicated by Graph Time. By default, graph time covers 100 seconds. To monitor longer periods and to ensure getting representative Max, Min, and Average values for those time periods, use the logging feature of Performance Monitor.
The shape of the Processor Queue Length graph line indicates that the Max of 22 occurred only for a short period. But there is a period preceding the 22 value when Processor Queue Length is greater than 5, 100 percent is 22. And there is a period prior to the 22 value when the graph has values above 25 percent, which is approximately 5. In this example, the database server HENRYLNT2 has only one processor and should not sustain Processor Queue Length greater than 2. Therefore, Performance Monitor indicates that the processor on this computer is being overtaxed. Further investigation should be made to reduce the load on the processor or more processors should be added to HENRYLNT2 to handle these periods of higher processor workloads.