The SQL standards require processing a query in the following order:
However, any plan that produces the same result is also correct. Therefore, in some queries, you can evaluate the GROUP BY clause earlier, before one or more join operations required for the WHERE clause, thus reducing the join input and the join cost, for example:
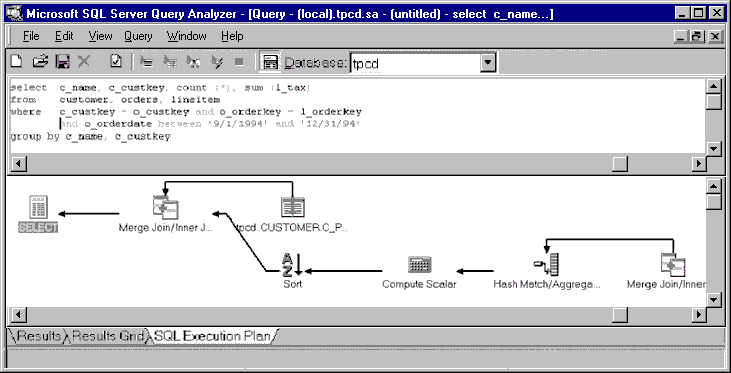
SELECT c_name, c_custkey, count (*), sum (l_tax)
FROM customer, orders, lineitem
WHERE c_custkey = o_custkey and o_orderkey = l_orderkey and
o_orderdate between ‘9/1/1994’ and ‘12/31/1994’
GROUP BY c_name, c_custkey
The query processor looks at the GROUP BY clause and determines that the primary key c_custkey determines c_name, so there is no need to group on c_name in addition to c_custkey. The query optimizer then determines that grouping on c_custkey and o_custkey produces the same result. Because the orders table has a customer key (o_custkey), the query processor can group by customer key as soon as it has the records for the orders table and before it joins to the customer table. This becomes evident in this execution plan.
The query processor first uses a merge join of the orders table (within the specified date range) and the lineitem table to get all order-line items. The second step is a hash aggregation, that is, the grouping operation. In this step, SQL Server aggregates the order-line items at the customer key level, counting them and calculating a sum of l_tax. SQL Server then sorts the output of the hash join and joins it to the customer table to produce the requested result. The advantage of this query plan is that the input into the final join is substantially reduced due to the earlier grouping operation.