SQL Server 6.5 uses nested loops iteration, which is excellent for row-to-row navigation such as moving from an order record to three or four order-line items. However, it is not efficient for joins of many records, such as typical data warehouse queries.
SQL Server 7.0 introduces three new techniques: merge joins, hash joins, and hash teams, the last of which is a significant innovation not available in any other relational database.
A merge join simultaneously passes over two sorted inputs to perform inner joins, outer joins, semi-joins, intersections, and unions. A merge join exploits sorted scans of B-tree indexes and is generally the method of choice if the join fields are indexed and if the columns represented in the index cover the query.
A hash join hashes input values, based on a repeatable randomizing function, and compares values in the hash table for matches. For inputs smaller than the available memory, the hash table remains in memory; for larger inputs, overflow files on disk are employed. Hashing is the method of choice for large, nonindexed tables, particularly for intermediate results.
The hashing operation can be used to process GROUP BY clauses, distincts, intersections, unions, differences, inner joins, outer joins, and semi-joins. SQL Server 7.0 implements all the well-known hashing techniques including cache-optimized in-memory hashing, large memory, recursive partitioning, hybrid hashing, bit-vector filtering, and role reversal.
The hash team is an innovation in SQL Server 7.0. Many queries consist of multiple execution phases; where possible, the query optimizer should take advantage of similar operations across multiple phases. For example, suppose you want to know how many order-line items have been entered for each part number and each supplier, as shown in this SQL code:
SELECT l_partkey, count (*)
FROM lineitem, part, partsupp
WHERE l_partkey = p_partkey and p_partkey = ps_partkey
GROUP BY l_partkey
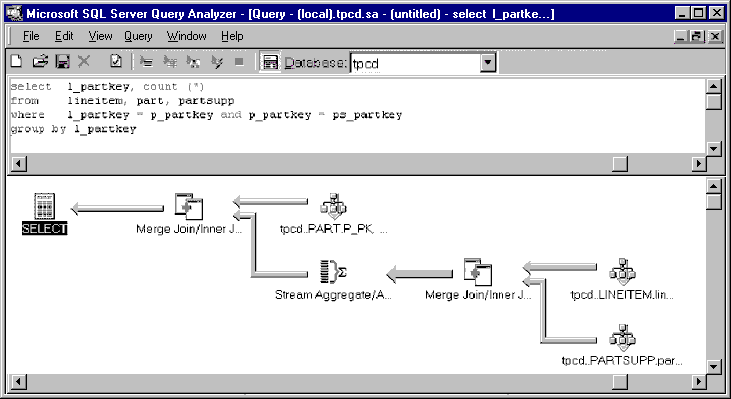
In response to this code, the query processor generates this execution plan.
This query plan performs a merge inner join between the lineitem table and the partsupp table. It calculates the count (stream aggregate), and then joins the result with the part table. This query never requires a sort operation. It begins by retrieving records in sorted order from the lineitem and partsupp tables using sorted scans over an index. This provides a sorted input into the merge join, which provides sorted input into the aggregation, which in turn provides sorted input into the final merge join.
Interesting ordering refers to avoiding sort operations by keeping track of the ordering of intermediate results that move from operator to operator. SQL Server 7.0 applies this concept to hash joins. Consider the same query, but assume that the crucial index on lineitems has been dropped, so that the previous plan would have to be augmented with an expensive sort operation on the large lineitems table.
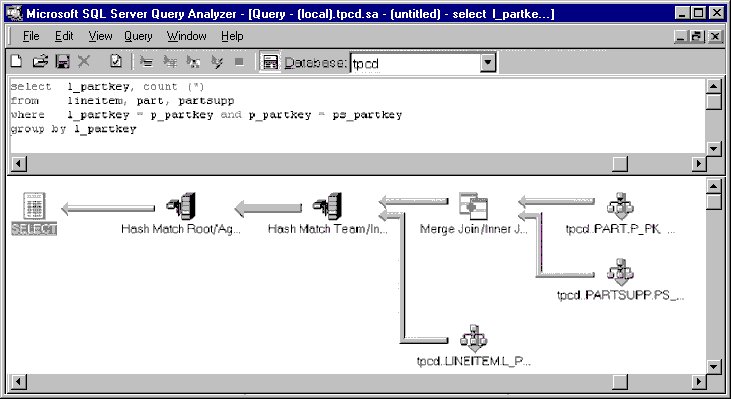
This query plan employs a hash join instead of a merge join; one of the merge joins is not affected by the dropped index and is therefore still very fast. The two hash operations are marked specially as the root and a member of a team. As data moves from the hash join to the grouping operation, work to partition rows in the hash join is exploited in the grouping operation. This eliminates overflow files for one of the inputs of the grouping operation, and thus reduces I/O costs for the query. The benefit is faster processing for complex queries.