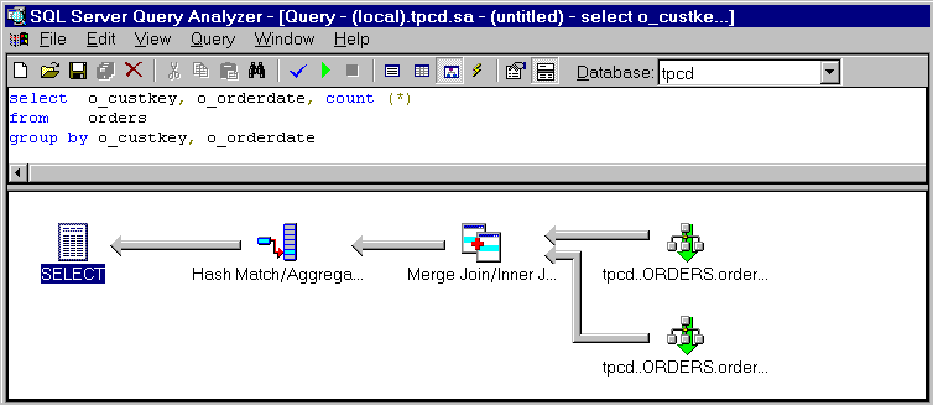
Microsoft SQL Server 6.5 selects the one best index for each table, even when a query has multiple predicates. SQL Server 7.0 takes advantage of multiple indexes, selecting small subsets of data based on each index, and then performing an intersection of the two subsets (that is, returning only those rows that meet all the criteria). For example, suppose you want to count orders for certain ranges of customers and order dates:
SELECT count (*)
FROM orders
WHERE o_orderdate between ‘9/15/1992’ and ‘10/15/1992’ and
o_custkey between 100 and 200
SQL Server 7.0 can exploit indexes on both o_custkey and o_orderdate, and then employ a join algorithm to obtain the index intersection between the two subsets. This execution plan exploits two indexes, both on the orders table.
Index joins are a variation on index intersections. When using any index, if all the columns required for a given query are available in the index itself, it is not necessary to fetch the full row. This is called a covering index because the index covers or contains all the columns needed for the query.
The covering index is a common and well-understood technique. SQL Server 7.0 takes it a step further by applying it to the index intersection. If no single index can cover a query, but multiple indexes together can cover the query, SQL Server considers joining these indexes. The alternative chosen is based on the cost prediction of the query optimizer.